Hantera modelllivscykeln med hjälp av arbetsytemodellregistret (äldre)
Viktigt!
Den här dokumentationen beskriver arbetsytans modellregister. Om din arbetsyta är aktiverad för Unity Catalog ska du inte använda procedurerna på den här sidan. Titta istället på modeller i Unity Catalog.
Information om hur du uppgraderar från Arbetsytemodellregistret till Unity Catalog finns i Migrera arbetsflöden och modeller till Unity Catalog.
Om din arbetsytas standardkatalog finns i Unity Catalog (i stället för hive_metastore) och du kör ett kluster med Databricks Runtime 13.3 LTS eller senare, skapas modeller automatiskt i och läses in från standardkatalogen för arbetsytan, utan att någon konfiguration krävs. Om du vill använda arbetsytemodellregistret i det här fallet måste du uttryckligen rikta in dig på det genom att köra import mlflow; mlflow.set_registry_uri("databricks") det i början av arbetsbelastningen. Ett litet antal arbetsytor där både standardkatalogen konfigurerades till en katalog i Unity Catalog före januari 2024 och arbetsytemodellregistret användes före januari 2024 är undantagna från det här beteendet och fortsätter att använda arbetsytemodellregistret som standard.
Den här artikeln beskriver hur du använder arbetsytemodellregistret som en del av ditt maskininlärningsarbetsflöde för att hantera hela livscykeln för ML-modeller. Arbetsytans modellregister är en Databricks-tillhandahållen, värdbaserad version av MLflow Model Registry.
Arbetsytans modellregister tillhandahåller:
- Kronologisk modell härkomst (som MLflow experimenterar och kör producerade modellen vid en viss tidpunkt).
- Modellservering.
- Versionshantering av modeller.
- Fasövergångar (till exempel från mellanlagring till produktion eller arkiverad).
- Webhooks så att du automatiskt kan utlösa åtgärder baserat på registerhändelser.
- E-postaviseringar om modellhändelser.
Du kan också skapa och visa modellbeskrivningar och lämna kommentarer.
Den här artikeln innehåller instruktioner för både arbetsytemodellregistrets användargränssnitt och API:et för arbetsytemodellens register.
En översikt över arbetsytemodellregisterbegrepp finns i MLflow för gen AI-agent och ML-modelllivscykel.
Skapa eller registrera en modell
Du kan skapa eller registrera en modell med hjälp av användargränssnittet eller registrera en modell med hjälp av API:et.
Skapa eller registrera en modell med hjälp av användargränssnittet
Det finns två sätt att registrera en modell i arbetsytemodellregistret. Du kan registrera en befintlig modell som har loggats till MLflow, eller så kan du skapa och registrera en ny tom modell och sedan tilldela en tidigare loggad modell till den.
Registrera en befintlig loggad modell från en notebook-fil
På arbetsytan identifierar du MLflow-körningen som innehåller den modell som du vill registrera.
Klicka på experimentikonen
 i anteckningsbokens högra sidofält.
i anteckningsbokens högra sidofält.
I sidofältet Experimentkörningar klickar du på
 ikonen bredvid datumet för körningen. Sidan för MLflow-körning visas. Den här sidan visar information om körningen, inklusive parametrar, mått, taggar och lista över artefakter.
ikonen bredvid datumet för körningen. Sidan för MLflow-körning visas. Den här sidan visar information om körningen, inklusive parametrar, mått, taggar och lista över artefakter.
I avsnittet Artifacts (Artefakter) klickar du på katalogen med namnet xxx-model.
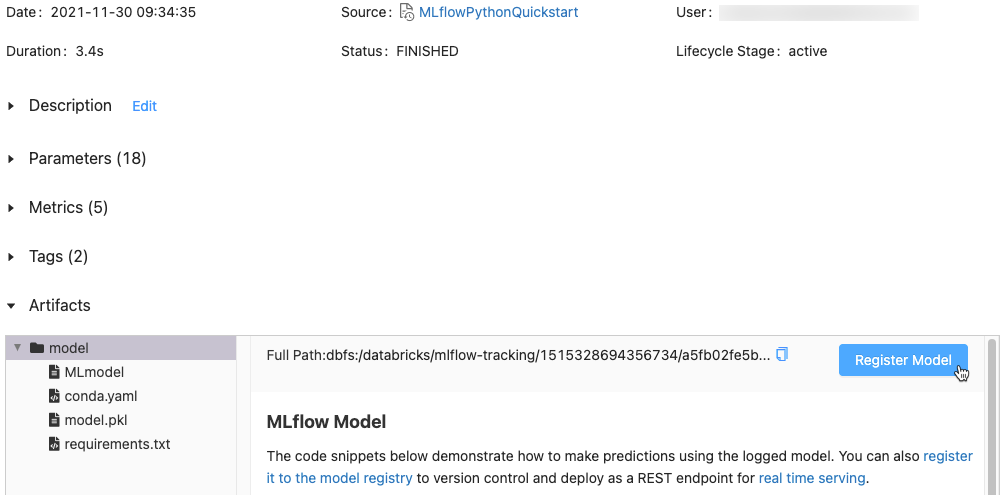
Klicka på knappen Register Model (Registrera modell) längst till höger.
I dialogrutan klickar du i rutan Modell och gör något av följande:
- Välj Skapa ny modell i den nedrullningsbara menyn. Fältet Modellnamn visas. Ange ett modellnamn, till exempel
scikit-learn-power-forecasting. - Välj en befintlig modell i den nedrullningsbara menyn.
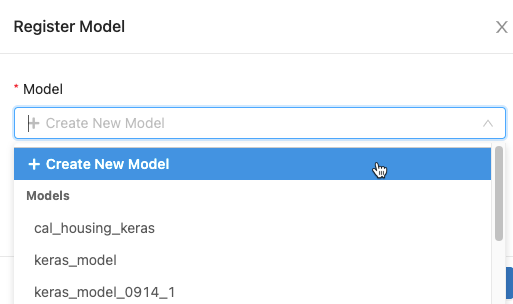
- Välj Skapa ny modell i den nedrullningsbara menyn. Fältet Modellnamn visas. Ange ett modellnamn, till exempel
Klicka på Registrera.
- Om du har valt Skapa ny modell registreras en modell med namnet
scikit-learn-power-forecasting, kopierar modellen till en säker plats som hanteras av arbetsytemodellregistret och skapar en ny version av modellen. - Om du har valt en befintlig modell registreras en ny version av den valda modellen.
Efter en liten stund ändras knappen Registrera modell till en länk till den nya registrerade modellversionen.
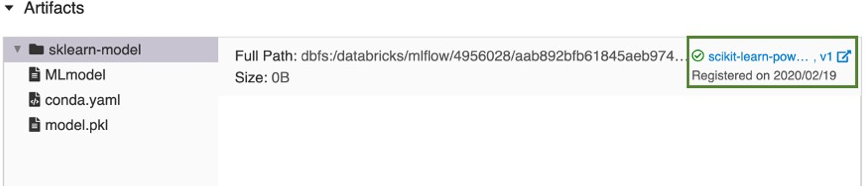
- Om du har valt Skapa ny modell registreras en modell med namnet
Klicka på länken för att öppna den nya modellversionen i arbetsytans modellregistergränssnitt. Du kan också hitta modellen i arbetsytans modellregister genom att
 klicka på Modeller i sidofältet.
klicka på Modeller i sidofältet.
Skapa en ny registrerad modell och tilldela en loggad modell till den
Med knappen Skapa modell på sidan med registrerade modeller kan du skapa en ny tom modell och sedan tilldela en loggad modell till den. Följ de här stegen:
Klicka på Create Model (Skapa modell) på sidan med registrerade modeller. Ange ett namn på modellen och klicka på Create (Skapa).
Följ steg 1 till 3 i Registrera en befintlig loggad modell från en notebook-fil.
I dialogrutan Registrera modell väljer du namnet på den modell som du skapade i steg 1 och klickar på Registrera. Detta registrerar en modell med det namn som du skapade, kopierar modellen till en säker plats som hanteras av arbetsytans modellregister och skapar en modellversion:
Version 1.Efter en stund ersätts knappen Register Model (Registrera modell) i användargränssnittet med en länk till den nya registrerade modellversionen. Nu kan du välja modellen från listrutan Modell i dialogrutan Registrera modell på sidan Experimentkörningar. Du kan också registrera nya versioner av modellen genom att ange dess namn i API-kommandon som Create ModelVersion.
Registrera en modell med hjälp av API:et
Det finns tre programmatiska sätt att registrera en modell i arbetsytemodellregistret. Alla metoder kopierar modellen till en säker plats som hanteras av arbetsytemodellregistret.
Om du vill logga en modell och registrera den med det angivna namnet under ett MLflow-experiment, använder du metoden
mlflow.<model-flavor>.log_model(...). Om det inte finns någon registrerad modell med det namnet registreras en ny modell och version 1 skapas och ett MLflow-objekt,ModelVersion, returneras. Om det redan finns en registrerad modell med det namnet skapar metoden en ny modellversion och returnerar versionsobjektet.with mlflow.start_run(run_name=<run-name>) as run: ... mlflow.<model-flavor>.log_model(<model-flavor>=<model>, artifact_path="<model-path>", registered_model_name="<model-name>" )Om du vill registrera en modell med det angivna namnet när alla experiment har körts klart och du har bestämt vilken modell som är mest lämplig att lägga till i registret, använder du metoden
mlflow.register_model(). För den här metoden behöver du körnings-ID:t för argumentetmlruns:URI. Om det inte finns någon registrerad modell med det namnet registreras en ny modell och version 1 skapas och ett MLflow-objekt,ModelVersion, returneras. Om det redan finns en registrerad modell med det namnet skapar metoden en ny modellversion och returnerar versionsobjektet.result=mlflow.register_model("runs:<model-path>", "<model-name>")Om du vill skapa en ny registrerad modell med det angivna namnet använder du metoden
create_registered_model()för MLflow-klient-API:et. Om modellnamnet redan finns genererar den här metoden ettMLflowException.client = MlflowClient() result = client.create_registered_model("<model-name>")
Du kan också registrera en modell med Databricks Terraform-providern och databricks_mlflow_model.
Kvotgränser
Från och med maj 2024 för alla Databricks-arbetsytor inför Arbetsytemodellregistret kvotgränser för det totala antalet registrerade modeller och modellversioner per arbetsyta. Se Resursbegränsningar. Om du överskrider registerkvoterna rekommenderar Databricks att du tar bort registrerade modeller och modellversioner som du inte längre behöver. Databricks rekommenderar också att du justerar din strategi för modellregistrering och kvarhållning för att hålla dig under gränsen. Om du behöver en ökning av dina arbetsytegränser kontaktar du databricks-kontoteamet.
Följande notebook-fil visar hur du inventar och tar bort dina modellregisterentiteter.
Notebook-fil för lagerarbetsytans modellregisterentiteter
Visa modeller i användargränssnittet
Sidan Registrerade modeller
Sidan registrerade modeller visas när du klickar på ![]() Modeller i sidopanelen. Den här sidan visar alla modeller i registret.
Modeller i sidopanelen. Den här sidan visar alla modeller i registret.
Du kan skapa en ny modell från den här sidan.
Från den här sidan kan arbetsyteadministratörer också ange behörigheter för alla modeller i arbetsytans modellregister.

Sidan Registrerad modell
Om du vill visa den registrerade modellsidan för en modell klickar du på ett modellnamn på sidan registrerade modeller. Den registrerade modellsidan visar information om den valda modellen och en tabell med information om varje version av modellen. På den här sidan kan du också:
- Konfigurera modell som betjänar.
- Generera automatiskt en notebook-fil för att använda modellen för slutsatsdragning.
- Konfigurera e-postaviseringar.
- Jämför modellversioner.
- Ange behörigheter för modellen.
- Ta bort en modell.
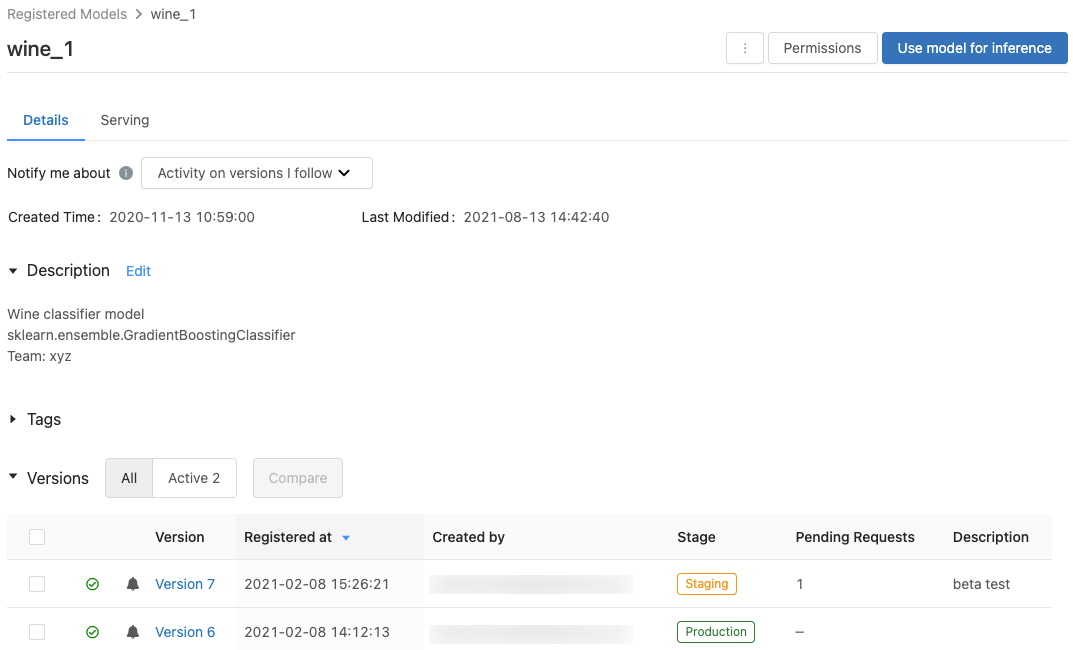
Modellversionssida
Om du vill visa modellversionssidan gör du något av följande:
- Klicka på ett versionsnamn i kolumnen senaste version på sidan registrerade modeller.
- Klicka på ett versionsnamn i kolumnen Version på den registrerade modellsidan.
På den här sidan visas information om en specifik version av en registrerad modell och en länk till källkörningen (den version av notebook-filen som kördes för att skapa modellen). På den här sidan kan du också:
- Generera automatiskt en notebook-fil för att använda modellen för slutsatsdragning.
- Ta bort en modell.
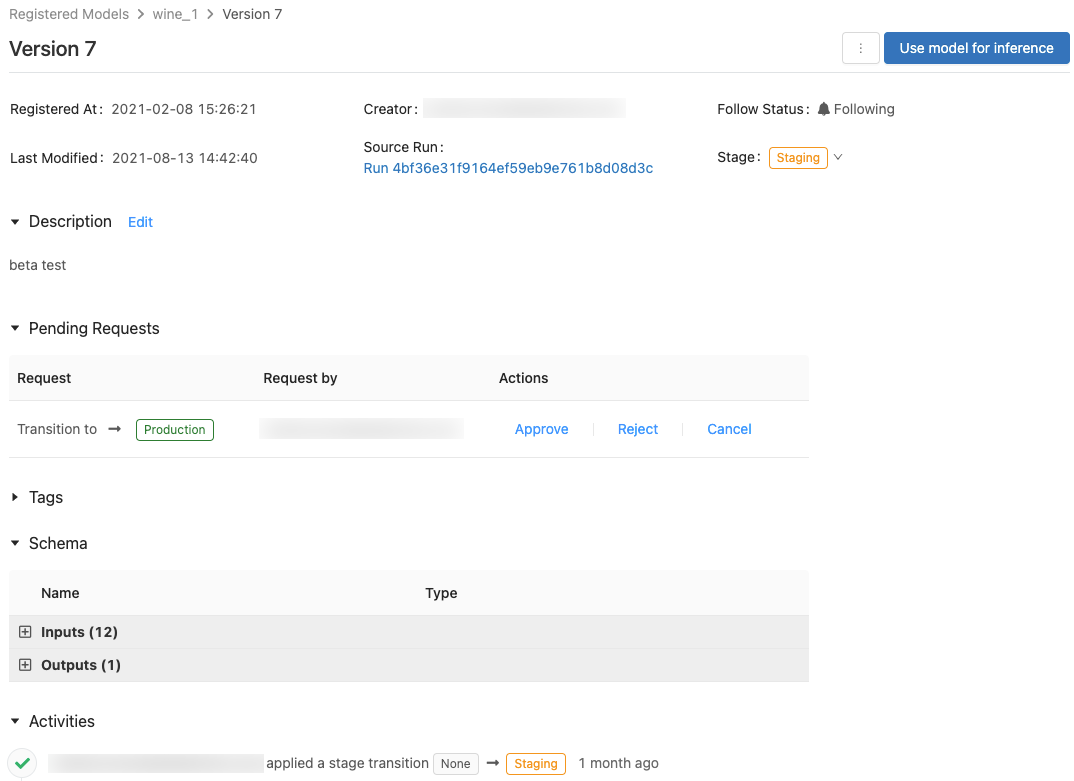
Kontrollera åtkomsten till modeller
Du måste ha minst behörigheten KAN HANTERA för att konfigurera behörigheter för en modell. Information om modellbehörighetsnivåer finns i ACL:er för MLflow-modell. En modellversion ärver behörigheter från den överordnade modellen. Du kan inte ange behörigheter för modellversioner.
Klicka på
Modeller i sidopanelen.Välj ett modellnamn.
Klicka på Behörigheter. Dialogrutan Behörighetsinställningar öppnas

I dialogrutan väljer du listrutan Välj användare, grupp eller tjänsthuvudnamn... och väljer en användare, grupp eller tjänstens huvudnamn.
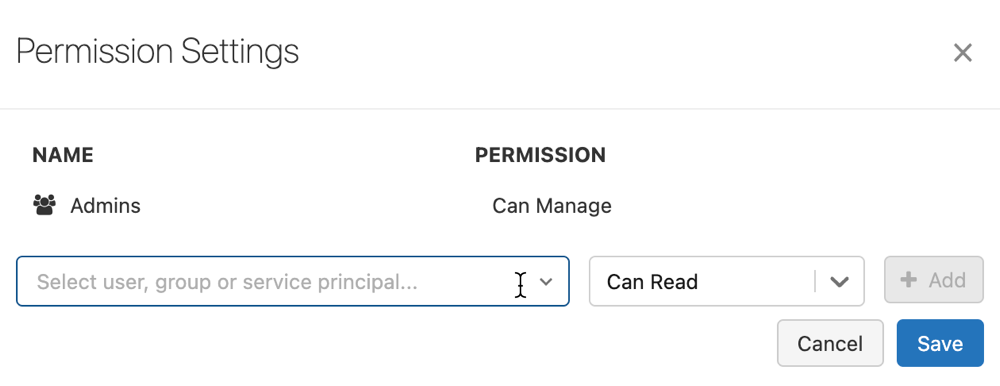
Välj en behörighet från behörighetslistrutan.
Klicka på Lägg till och klicka på Spara.
Arbetsyteadministratörer och användare med CAN MANAGE-behörighet på registeromfattande nivå kan ange behörighetsnivåer för alla modeller på arbetsytan genom att klicka på Behörigheter på sidan Modeller.
Övergå till en modellfas
En modellversion har något av följande steg: Ingen, Mellanlagring, Produktion eller Arkiverad. Mellanlagringsfasen är avsedd för testning och validering av modellen och produktionsfasen är avsedd för modellversioner som har slutfört testnings- eller granskningsprocesserna och har distribuerats till program för livebedömning. En arkiverad modellversion anses vara inaktiv, och du kan därmed överväga om du vill ta bort den. Olika versioner av en modell kan befinna sig i olika faser.
En användare med rätt behörighet kan flytta en modellversion mellan olika faser. Om du har behörighet att flytta en modellversion till en viss fas kan du utföra övergången direkt. Om du inte har behörighet kan du begära en fasövergång och sedan kan en användare som har behörighet att flytta modellversioner godkänna, avslå eller avbryta din begäran.
Du kan överföra en modellfas med hjälp av användargränssnittet eller med hjälp av API:et.
Övergå från en modellfas till en annan med hjälp av användargränssnittet
Följ de här anvisningarna om du vill flytta en modell till en annan fas.
Om du vill visa listan över tillgängliga modellfaser och tillgängliga alternativ klickar du på listrutan bredvid Stage: och begär eller väljer en övergång till en annan fas.
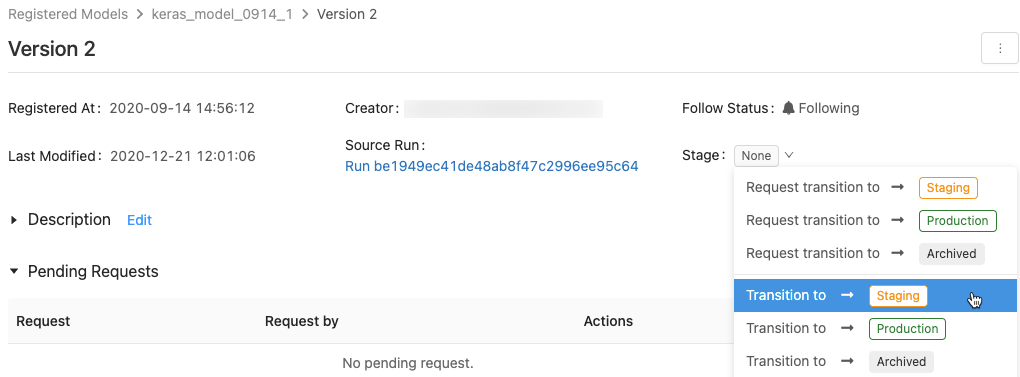
Ange en valfri kommentar och klicka på OK.
Flytta en modellversion till produktionsfasen
Efter testning och validering kan du flytta eller begära en övergång till produktionsfasen.
Arbetsytemodellregistret tillåter mer än en version av den registrerade modellen i varje steg. Om du bara vill ha en version i produktionsfasen kan du flytta alla versioner av modellen som är i Produktion till Arkiverad genom att markera Transition existing Production model versions to Archived (Flytta befintliga modellversioner i Produktion till Arkiverad).
Godkänna, avvisa eller avbryta en begäran om modellversionsstegövergång
Användare som saknar behörighet kan begära en fasövergång. Begäran visas i avsnittet Pending Requests (Väntande begäranden) på modellversionssidan:

Om du vill godkänna, avslå eller avbryta en begäran om fasövergång kan du klicka på länken Approve (Godkänn), Reject (Avslå) eller Cancel (Avbryt).
Den som skapar en begäran om fasövergång kan också avbryta begäran.
Visa modellversionsaktiviteter
Om du vill visa alla övergångar som har begärts, godkänts, väntar på godkännande och tillämpats för en modellversion kan du gå till avsnittet Activities (Aktiviteter). Denna aktivitetsvy visar härkomst för modellens livscykel för granskning eller inspektion.
Övergå till en modellfas med hjälp av API:et
En användare med rätt behörighet kan flytta en modellversion till en annan fas.
Om du vill uppdatera en modellversionsfas till en ny fas använder du MLflow Client API transition_model_version_stage()-metoden:
client = MlflowClient()
client.transition_model_version_stage(
name="<model-name>",
version=<model-version>,
stage="<stage>",
description="<description>"
)
De godkända värdena för <stage> är: "Staging"|"staging", "Archived"|"archived", "Production"|"production", "None"|"none".
Använda modell för slutsatsdragning
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
När en modell har registrerats i arbetsytans modellregister kan du automatiskt generera en notebook-fil för att använda modellen för batch- eller strömningsinferens. Du kan också skapa en slutpunkt för att använda modellen för realtidsservering med modellservering.
I det övre högra hörnet på den registrerade modellsidan eller modellversionssidan klickar du på  . Dialogrutan Konfigurera modellinferens visas, vilket gör att du kan konfigurera batch-, direktuppspelnings- eller realtidsinferens.
. Dialogrutan Konfigurera modellinferens visas, vilket gör att du kan konfigurera batch-, direktuppspelnings- eller realtidsinferens.
Viktigt!
Anaconda Inc. uppdaterade sina tjänstvillkor för anaconda.org kanaler. Baserat på de nya tjänstvillkoren kan du kräva en kommersiell licens om du förlitar dig på Anacondas paketering och distribution. Mer information finns i Vanliga frågor och svar om Anaconda Commercial Edition. Din användning av Anaconda-kanaler styrs av deras användarvillkor.
MLflow-modeller som loggades före v1.18 (Databricks Runtime 8.3 ML eller tidigare) loggades som standard med conda-kanalen defaults (https://repo.anaconda.com/pkgs/) som ett beroende. På grund av den här licensändringen defaults har Databricks stoppat användningen av kanalen för modeller som loggats med MLflow v1.18 och senare. Standardkanalen som loggas är nu conda-forge, som pekar på den communityhanterade https://conda-forge.org/.
Om du loggade en modell före MLflow v1.18 utan att utesluta defaults kanalen från conda-miljön för modellen, kan den modellen ha ett beroende av den defaults kanal som du kanske inte har tänkt dig.
För att manuellt bekräfta om en modell har det här beroendet kan du undersöka channel värdet i conda.yaml filen som är paketerad med den loggade modellen. En modell med conda.yaml ett defaults kanalberoende kan till exempel se ut så här:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Eftersom Databricks inte kan avgöra om din användning av Anaconda-lagringsplatsen för att interagera med dina modeller är tillåten under din relation med Anaconda, tvingar Databricks inte sina kunder att göra några ändringar. Om din användning av Anaconda.com lagringsplats genom användning av Databricks är tillåten enligt Anacondas villkor behöver du inte vidta några åtgärder.
Om du vill ändra den kanal som används i en modells miljö kan du registrera om modellen till arbetsytans modellregister med en ny conda.yaml. Du kan göra detta genom att ange kanalen i parametern conda_envlog_model()för .
Mer information om API:et finns i log_model() MLflow-dokumentationen för modellsmaken som du arbetar med, till exempel log_model för scikit-learn.
Mer information om conda.yaml filer finns i MLflow-dokumentationen.
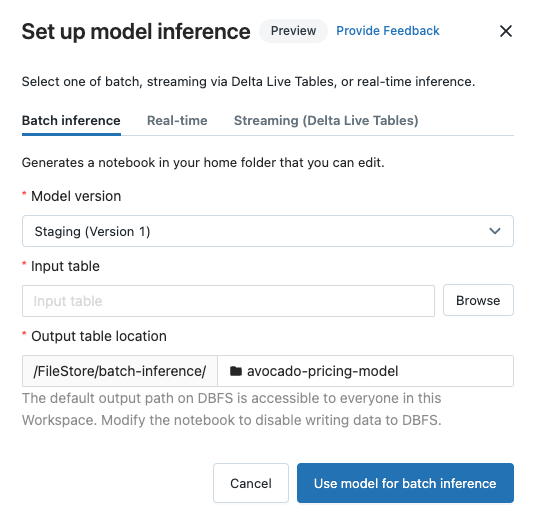
Konfigurera batchinferens
När du följer de här stegen för att skapa en notebook-fil för batchinferens sparas anteckningsboken i användarmappen Batch-Inference under mappen i en mapp med modellens namn. Du kan redigera anteckningsboken efter behov.
Klicka på fliken Batch-slutsatsdragning .
I listrutan Modellversion väljer du den modellversion som ska användas. De första två objekten i listrutan är den aktuella produktions- och mellanlagringsversionen av modellen (om de finns). När du väljer något av de här alternativen använder notebook-filen automatiskt produktions- eller mellanlagringsversionen när den körs. Du behöver inte uppdatera anteckningsboken när du fortsätter att utveckla modellen.
Klicka på knappen Bläddra bredvid indatatabell. Dialogrutan Välj indata visas. Om det behövs kan du ändra klustret i listrutan Beräkning .
Kommentar
För Unity Catalog-aktiverade arbetsytor kan du i dialogrutan Välj indata välja mellan tre nivåer
<catalog-name>.<database-name>.<table-name>.Välj den tabell som innehåller indata för modellen och klicka på Välj. Den genererade notebook-filen importerar automatiskt dessa data och skickar dem till modellen. Du kan redigera den genererade notebook-filen om data kräver några transformeringar innan de matas in till modellen.
Förutsägelser sparas i en mapp i katalogen
dbfs:/FileStore/batch-inference. Som standard sparas förutsägelser i en mapp med samma namn som modellen. Varje körning av den genererade notebook-filen skriver en ny fil till den här katalogen med tidsstämpeln som läggs till i namnet. Du kan också välja att inte inkludera tidsstämpeln och skriva över filen med efterföljande körningar av notebook-filen. instruktioner finns i den genererade notebook-filen.Du kan ändra mappen där förutsägelserna sparas genom att skriva ett nytt mappnamn i tabellplats för utdata fält eller genom att klicka på mappikonen för att bläddra i katalogen och välja en annan mapp.
Om du vill spara förutsägelser på en plats i Unity Catalog måste du redigera anteckningsboken. Ett exempel på en notebook-fil som visar hur du tränar en maskininlärningsmodell som använder data i Unity Catalog och skriver resultaten tillbaka till Unity Catalog finns i Självstudie om maskininlärning.
Konfigurera direktuppspelningsslutsats med Delta Live Tables
När du följer de här stegen för att skapa en notebook-fil för direktuppspelning sparas anteckningsboken i användarmappen DLT-Inference under mappen i en mapp med modellens namn. Du kan redigera anteckningsboken efter behov.
Klicka på fliken Streaming (Delta Live Tables).
I listrutan Modellversion väljer du den modellversion som ska användas. De första två objekten i listrutan är den aktuella produktions- och mellanlagringsversionen av modellen (om de finns). När du väljer något av de här alternativen använder notebook-filen automatiskt produktions- eller mellanlagringsversionen när den körs. Du behöver inte uppdatera anteckningsboken när du fortsätter att utveckla modellen.
Klicka på knappen Bläddra bredvid indatatabell. Dialogrutan Välj indata visas. Om det behövs kan du ändra klustret i listrutan Beräkning .
Kommentar
För Unity Catalog-aktiverade arbetsytor kan du i dialogrutan Välj indata välja mellan tre nivåer
<catalog-name>.<database-name>.<table-name>.Välj den tabell som innehåller indata för modellen och klicka på Välj. Den genererade notebook-filen skapar en datatransformering som använder indatatabellen som källa och integrerar MLflow-PySpark-slutsatsdragningen UDF- för att utföra modellförutsägelser. Du kan redigera den genererade notebook-filen om data kräver ytterligare transformeringar före eller efter att modellen har tillämpats.
Ange utdatanamnet för Delta Live Table. Notebook-filen skapar en dynamisk tabell med det angivna namnet och använder den för att lagra modellens förutsägelser. Du kan ändra den genererade notebook-filen för att anpassa måldatauppsättningen efter behov, till exempel: definiera en livetabell för direktuppspelning som utdata, lägga till schemainformation eller datakvalitetsbegränsningar.
Du kan sedan antingen skapa en ny Delta Live Tables-pipeline med den här notebook-filen eller lägga till den i en befintlig pipeline som ytterligare ett notebook-bibliotek.
Konfigurera slutsatsdragning i realtid
Modellservern exponerar dina MLflow-maskininlärningsmodeller som skalbara REST API-slutpunkter. Information om hur du skapar en modellserverslutpunkt finns i Skapa anpassade modell som betjänar slutpunkter.
Ge feedback
Den här funktionen är en förhandsversion och vi vill gärna få din feedback. Om du vill ge feedback klickar du Provide Feedback i dialogrutan Konfigurera modellinferens.
Jämföra modellversioner
Du kan jämföra modellversioner i arbetsytans modellregister.
- På sidan registrerad modellväljer du två eller flera modellversioner genom att klicka i kryssrutan till vänster om modellversionen.
- Klicka på Jämför.
- Skärmen Jämföra
<N>versioner visas och visar en tabell som jämför parametrar, schema och mått för de valda modellversionerna. Längst ned på skärmen kan du välja typ av diagram (punktdiagram, kontur eller parallella koordinater) och de parametrar eller mått som ska ritas.
Kontrollera meddelandeinställningar
Du kan konfigurera Arbetsytemodellregistret så att du meddelas via e-post om aktivitet i registrerade modeller och modellversioner som du anger.
På den registrerade modellsidan visar menyn Meddela mig om tre alternativ:
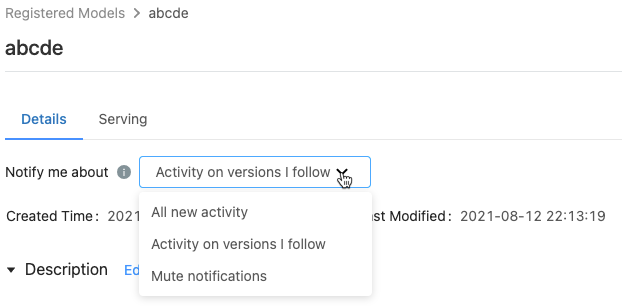
- All ny aktivitet: Skicka e-postaviseringar om all aktivitet i alla modellversioner av den här modellen. Om du har skapat den registrerade modellen är den här inställningen standardinställningen.
- Aktivitet i versioner som jag följer: Skicka e-postaviseringar endast om modellversioner som du följer. Med det här valet får du meddelanden för alla modellversioner som du följer. Du kan inte inaktivera meddelanden för en viss modellversion.
- Stäng av aviseringar: Skicka inte e-postaviseringar om aktivitet i den här registrerade modellen.
Följande händelser utlöser ett e-postmeddelande:
- Skapa en ny modellversion
- Begäran om en fasövergång
- Fasövergång
- Nya kommentarer
Du prenumererar automatiskt på modellmeddelanden när du gör något av följande:
- Kommentera den modellversionen
- Överföra en modellversionssteg
- Gör en övergångsbegäran för modellens fas
Om du vill se om du följer en modellversion, titta på Följ-statusfältet på sidan för modellversion eller i tabellen över modellversioner på sidan för den registrerade modellen .
Inaktivera alla e-postaviseringar
Du kan inaktivera e-postaviseringar på fliken Registerinställningar för arbetsytemodell i menyn Användarinställningar:
- Klicka på ditt användarnamn i det övre högra hörnet på Azure Databricks-arbetsytan och välj Inställningar i den nedrullningsbara menyn.
- I sidofältet Inställningar väljer du Meddelanden.
- Inaktivera e-postaviseringar för Model Registry.
En kontoadministratör kan inaktivera e-postaviseringar för hela organisationen på sidan administratörsinställningar.
Maximalt antal e-postmeddelanden som skickas
Arbetsytans modellregister begränsar antalet e-postmeddelanden som skickas till varje användare per dag per aktivitet. Om du till exempel får 20 e-postmeddelanden på en dag om nya modellversioner som skapats för en registrerad modell skickar Arbetsytemodellregistret ett e-postmeddelande som anger att den dagliga gränsen har nåtts och inga ytterligare e-postmeddelanden om händelsen skickas förrän nästa dag.
Om du vill öka gränsen för antalet tillåtna e-postmeddelanden kontaktar du ditt Azure Databricks-kontoteam.
Webhook
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Med webhooks kan du lyssna efter händelser i Arbetsytans modellregister så att dina integreringar automatiskt kan utlösa åtgärder. Du kan använda webhooks för att automatisera och integrera din maskininlärningspipeline med befintliga CI/CD-verktyg och arbetsflöden. Du kan till exempel utlösa CI-versioner när en ny modellversion skapas eller meddela dina teammedlemmar via Slack varje gång en modellövergång till produktion begärs.
Kommentera en modell eller modellversion
Du kan ange information om en modell eller modellversion genom att skriva en kommentar. Du kanske till exempel vill ta med en översikt över problemet eller information om den metod och algoritm som används.
Kommentera en modell eller modellversion med hjälp av användargränssnittet
Användargränssnittet för Azure Databricks innehåller flera sätt att kommentera modeller och modellversioner. Du kan lägga till textinformation med hjälp av en beskrivning eller kommentarer och du kan lägga till sökbara nyckel/värde-taggar. Beskrivningar och taggar är tillgängliga för modeller och modellversioner. kommentarer är endast tillgängliga för modellversioner.
- Beskrivningar är avsedda att ge information om modellen.
- Kommentarer är ett sätt att upprätthålla en pågående diskussion om aktiviteter i en modellversion.
- Med taggar kan du anpassa modellmetadata så att det blir enklare att hitta specifika modeller.
Lägga till eller uppdatera beskrivningen för en modell eller modellversion
På sidan registrerad modell eller modellversion klickar du på Redigera bredvid Beskrivning. Ett redigeringsfönster visas.
Ange eller redigera beskrivningen i redigeringsfönstret.
Klicka på Spara om du vill spara ändringarna eller Avbryt för att stänga fönstret.
Om du har angett en beskrivning av en modellversion visas beskrivningen i kolumnen Description i tabellen på registrerade modellsidan. Kolumnen visar högst 32 tecken eller en textrad, beroende på vilket som är kortare.
Lägga till kommentarer för en modellversion
- Rulla nedåt på modellversionssidan och klicka på nedåtpilen bredvid Aktiviteter.
- Skriv kommentaren i redigeringsfönstret och klicka på Lägg till kommentar.
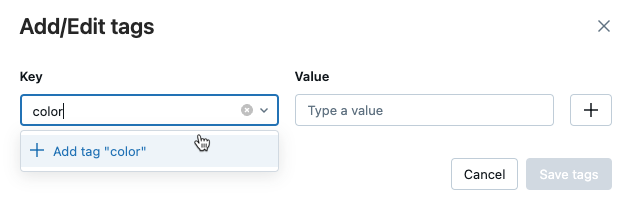
Lägga till taggar för en modell eller modellversion
Från sidan registrerad modell eller modellversion klickar du på
 om den inte redan är öppen. Tabellen taggar visas.
om den inte redan är öppen. Tabellen taggar visas.
Klicka i fälten Namn och Värde och ange nyckeln och värdet för taggen.
Klicka på Lägg till.
Redigera eller ta bort taggar för en modell eller modellversion
Om du vill redigera eller ta bort en befintlig tagg använder du ikonerna i kolumnen Actions.

Kommentera en modellversion med hjälp av API:et
Om du vill uppdatera en modellversionsbeskrivning använder du MLflow-klient-API:et update_model_version()-metoden:
client = MlflowClient()
client.update_model_version(
name="<model-name>",
version=<model-version>,
description="<description>"
)
Om du vill ange eller uppdatera en tagg för en registrerad modell eller modellversion använder du MLflow-klient-API:et set_registered_model_tag()) eller set_model_version_tag()-metoden:
client = MlflowClient()
client.set_registered_model_tag()(
name="<model-name>",
key="<key-value>",
tag="<tag-value>"
)
client = MlflowClient()
client.set_model_version_tag()(
name="<model-name>",
version=<model-version>,
key="<key-value>",
tag="<tag-value>"
)
Byta namn på en modell (endast API)
Om du vill byta namn på en registrerad modell använder du metoden rename_registered_model() för MLflow-klient-API:et:
client=MlflowClient()
client.rename_registered_model("<model-name>", "<new-model-name>")
Kommentar
Du kan bara byta namn på en registrerad modell om den inte har någon version, eller om alla versioner är i fasen None (Ingen) eller Archived (Arkiverad).
Söka efter en modell
Du kan söka efter modeller i arbetsytans modellregister med hjälp av användargränssnittet eller API:et.
Kommentar
När du söker efter en modell returneras endast modeller som du har behörighet att läsa minst för.
Söka efter en modell med hjälp av användargränssnittet
Om du vill visa registrerade modeller klickar du på ![]() Modeller i sidofältet.
Modeller i sidofältet.
Om du vill söka efter en specifik modell anger du text i sökrutan. Du kan ange namnet på en modell eller någon del av namnet:
Du kan också söka efter taggar. Ange taggar i det här formatet: tags.<key>=<value>. Om du vill söka efter flera taggar använder du operatorn AND .

Du kan söka efter både modellnamnet och taggarna med hjälp av MLflow-söksyntaxen. Till exempel:

Söka efter en modell med hjälp av API:et
Du kan söka efter registrerade modeller i arbetsytemodellregistret med MLflow Client API-metoden search_registered_models()
Om du har ange taggar på dina modeller kan du också söka efter taggarna med search_registered_models().
print(f"Find registered models with a specific tag value")
for m in client.search_registered_models(f"tags.`<key-value>`='<tag-value>'"):
pprint(dict(m), indent=4)
Du kan också söka efter ett specifikt modellnamn och visa dess versionsinformation med hjälp av MLflow-klient-API:et search_model_versions() metod:
from pprint import pprint
client=MlflowClient()
[pprint(mv) for mv in client.search_model_versions("name='<model-name>'")]
Detta ger följande utdata:
{ 'creation_timestamp': 1582671933246,
'current_stage': 'Production',
'description': 'A random forest model containing 100 decision trees '
'trained in scikit-learn',
'last_updated_timestamp': 1582671960712,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'ae2cc01346de45f79a44a320aab1797b',
'source': './mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 1 }
{ 'creation_timestamp': 1582671960628,
'current_stage': 'None',
'description': None,
'last_updated_timestamp': 1582671960628,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'd994f18d09c64c148e62a785052e6723',
'source': './mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 2 }
Ta bort en modell eller modellversion
Du kan ta bort en modell med hjälp av användargränssnittet eller API:et.
Ta bort en modellversion eller modell med hjälp av användargränssnittet
Varning
Du kan inte ångra den här åtgärden. Du kan flytta en modellversion till fasen Archived (Arkiverad) i stället för att ta bort den från registret. När du tar bort en modell tas alla modellartefakter som lagras av arbetsytans modellregister och alla metadata som är associerade med den registrerade modellen bort.
Kommentar
Du kan bara ta bort modeller och modellversioner som är i fasen None (Ingen) eller Archived (Arkiverad). Om en registrerad modell har versioner i mellanlagrings -eller produktionsfasen måste du flytta dem till antingen fasen Ingen eller Arkiverad innan du tar bort modellen.
Så här tar du bort en modellversion:
- Klicka på Modeller i sidopanelen.
- Klicka på ett modellnamn.
- Klicka på en modellversion.
- Klicka på menyn för kebab
 längst upp till höger på skärmen och välj Ta bort från den nedrullningsbara menyn.
längst upp till höger på skärmen och välj Ta bort från den nedrullningsbara menyn.
Så här tar du bort en modell:
- Klicka på Modeller i sidopanelen.
- Klicka på ett modellnamn.
- Klicka på menyn för kebab längst upp till höger på skärmen och välj Ta bort från den nedrullningsbara menyn.
Ta bort en modellversion eller modell med hjälp av API:et
Varning
Du kan inte ångra den här åtgärden. Du kan flytta en modellversion till fasen Archived (Arkiverad) i stället för att ta bort den från registret. När du tar bort en modell tas alla modellartefakter som lagras av arbetsytans modellregister och alla metadata som är associerade med den registrerade modellen bort.
Kommentar
Du kan bara ta bort modeller och modellversioner som är i fasen None (Ingen) eller Archived (Arkiverad). Om en registrerad modell har versioner i mellanlagrings -eller produktionsfasen måste du flytta dem till antingen fasen Ingen eller Arkiverad innan du tar bort modellen.
Ta bort en modellversion
Om du vill tar bort en modellversion använder du metoden delete_model_version() för MLflow-klient-API:et:
# Delete versions 1,2, and 3 of the model
client = MlflowClient()
versions=[1, 2, 3]
for version in versions:
client.delete_model_version(name="<model-name>", version=version)
Ta bort modellen
Om du vill tar bort en modell använder du metoden delete_registered_model() för MLflow-klient-API:et:
client = MlflowClient()
client.delete_registered_model(name="<model-name>")
Dela modeller mellan arbetsytor
Databricks rekommenderar att du använder -modeller i Unity Catalog för att dela modeller mellan arbetsytor. Unity Catalog tillhandahåller färdigt stöd för åtkomst, styrning och granskningsloggning av modeller mellan arbetsytor.
Men om du använder arbetsytans modellregister kan du också dela modeller över flera arbetsytor med viss konfiguration. Du kan till exempel utveckla och logga en modell på din egen arbetsyta och sedan komma åt den från en annan arbetsyta med hjälp av ett fjärranslutet arbetsytemodellregister. Detta är användbart när flera team har delad åtkomst till modeller. Du kan skapa flera arbetsytor och använda och hantera modeller i dessa miljöer.
Kopiera MLflow-objekt mellan arbetsytor
Om du vill importera eller exportera MLflow-objekt till eller från din Azure Databricks-arbetsyta kan du använda det communitydrivna öppen källkod projektet MLflow Export-Import för att migrera MLflow-experiment, modeller och körningar mellan arbetsytor.
Med de här verktygen kan du:
- Dela och samarbeta med andra dataexperter på samma eller en annan spårningsserver. Du kan till exempel klona ett experiment från en annan användare till din arbetsyta.
- Kopiera en modell från en arbetsyta till en annan, till exempel från en utveckling till en produktionsarbetsyta.
- Kopiera MLflow-experiment och körs från din lokala spårningsserver till databricks-arbetsytan.
- Säkerhetskopiera verksamhetskritiska experiment och modeller till en annan Databricks-arbetsyta.
Exempel
Det här exemplet visar hur du använder arbetsytemodellregistret för att skapa ett maskininlärningsprogram.