Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln visar hur du distribuerar modeller med Foundation Model API:er och tilldelad genomströmning. Databricks rekommenderar etablerat dataflöde för produktionsarbetsbelastningar och ger optimerad slutsatsdragning för grundmodeller med prestandagarantier.
Vad är tilldelad överföringskapacitet?
Allokerad genomflödeskapacitet hänvisar till hur många tokens motsvarande förfrågningar du kan skicka till en ändpunkt samtidigt. Förbestämda dataflödesgenomströmningsslutpunkter är dedikerade slutpunkter som är konfigurerade med ett antal tokens per sekund som du kan skicka till slutpunkten.
Mer information finns i följande resurser:
- Vad innebär tokens per sekund-spann i tilldelad genomströmning?
- Genomför din egen LLM-slutpunktsmätning
Se Etablerat dataflöde för en lista över modellarkitekturer som stöds för etablerade dataflödesslutpunkter.
Krav
Se krav. Information om hur du distribuerar finjusterade grundmodeller finns i Distribuera finjusterade grundmodeller.
[Rekommenderas] Distribuera grundmodeller från Unity Catalog
Viktig
Den här funktionen finns i offentlig förhandsversion.
Databricks rekommenderar att du använder grundmodellerna som är förinstallerade i Unity Catalog. Du hittar dessa modeller under katalogen system i schemat ai (system.ai).
För att implementera en grundmodell:
- Gå till
system.aii Katalogutforskaren. - Klicka på namnet på modellen som ska distribueras.
- På modellsidan klickar du på knappen Servera den här modellen.
- Sidan Skapa tjänstslutpunkt visas. Se Skapa din etablerade dataflödesslutpunkt med hjälp av användargränssnittet.
Obs
Om du vill distribuera en Meta Llama-modell från system.ai i Unity Catalog måste du välja tillämplig Instruera version. Basversioner av Meta Llama-modeller stöds inte för distribution från system.ai i Unity Catalog. Se Etablerade dataflödesgränser.
Distribuera grundmodeller från Databricks Marketplace
Du kan också installera grundmodeller i Unity Catalog från Databricks Marketplace.
Du kan söka efter en modellfamilj och från modellsidan kan du välja Få åtkomst och ange inloggningsuppgifter för att installera modellen i Unity Catalog.
När modellen har installerats i Unity Catalog kan du skapa en modell som betjänar slutpunkten med hjälp av användargränssnittet för servering.
Distribuera finjusterade grundmodeller
Om du inte kan använda modellerna i system.ai-schemat eller installera modeller från Databricks Marketplace kan du distribuera en finjusterad grundmodell genom att logga den till Unity Catalog. Det här avsnittet och följande avsnitt visar hur du konfigurerar koden för att logga en MLflow-modell till Unity Catalog och skapa din etablerade dataflödesslutpunkt med hjälp av antingen användargränssnittet eller REST-API:et.
Se Tilldelade genomströmningsgränser för de stödda Meta Llama 3.1, 3.2 och 3.3 fintrimmade modellerna och deras tillgänglighet i regioner.
Krav
- Distribution av finjusterade grundmodeller stöds endast av MLflow 2.11 eller senare. Databricks Runtime 15.0 ML och senare förinstallerar den kompatibla MLflow-versionen.
- Databricks rekommenderar att du använder modeller i Unity Catalog för snabbare uppladdning och nedladdning av stora modeller.
Definiera katalog-, schema- och modellnamn
Om du vill distribuera en finjusterad grundmodell definierar du målkatalogen för Unity Catalog, schemat och det modellnamn du väljer.
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Logga din modell
För att aktivera förberedd genomströmning för din modellslutpunkt måste du logga din modell med hjälp av MLflow transformers flavor och ange argumentet task med lämpligt modelltypgränssnitt från följande alternativ:
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
Dessa argument anger API-signaturen som används för modellens serverdelsslutpunkt. Mer information om dessa uppgifter och motsvarande indata-/utdatascheman finns i MLflow-dokumentationen.
Följande är ett exempel på hur du loggar en textkompletteringsspråkmodell som loggats med MLflow:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mixtral-8x7b-instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mixtral-8x7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency.
save_pretrained=False
)
Obs
Om du använder MLflow tidigare än 2.12 måste du ange uppgiften i metadata parametern för samma mlflow.transformer.log_model() funktion i stället.
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
Etablerat dataflöde stöder även både bas- och stora GTE-inbäddningsmodeller. Följande är ett exempel på hur du loggar modellen Alibaba-NLP/gte-large-en-v1.5 så att den kan hanteras med etablerat dataflöde:
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
När modellen har loggats i Unity Catalog fortsätter du på Skapa din etablerade dataflödesslutpunkt med hjälp av användargränssnittet för att skapa en modell som betjänar slutpunkten med etablerat dataflöde.
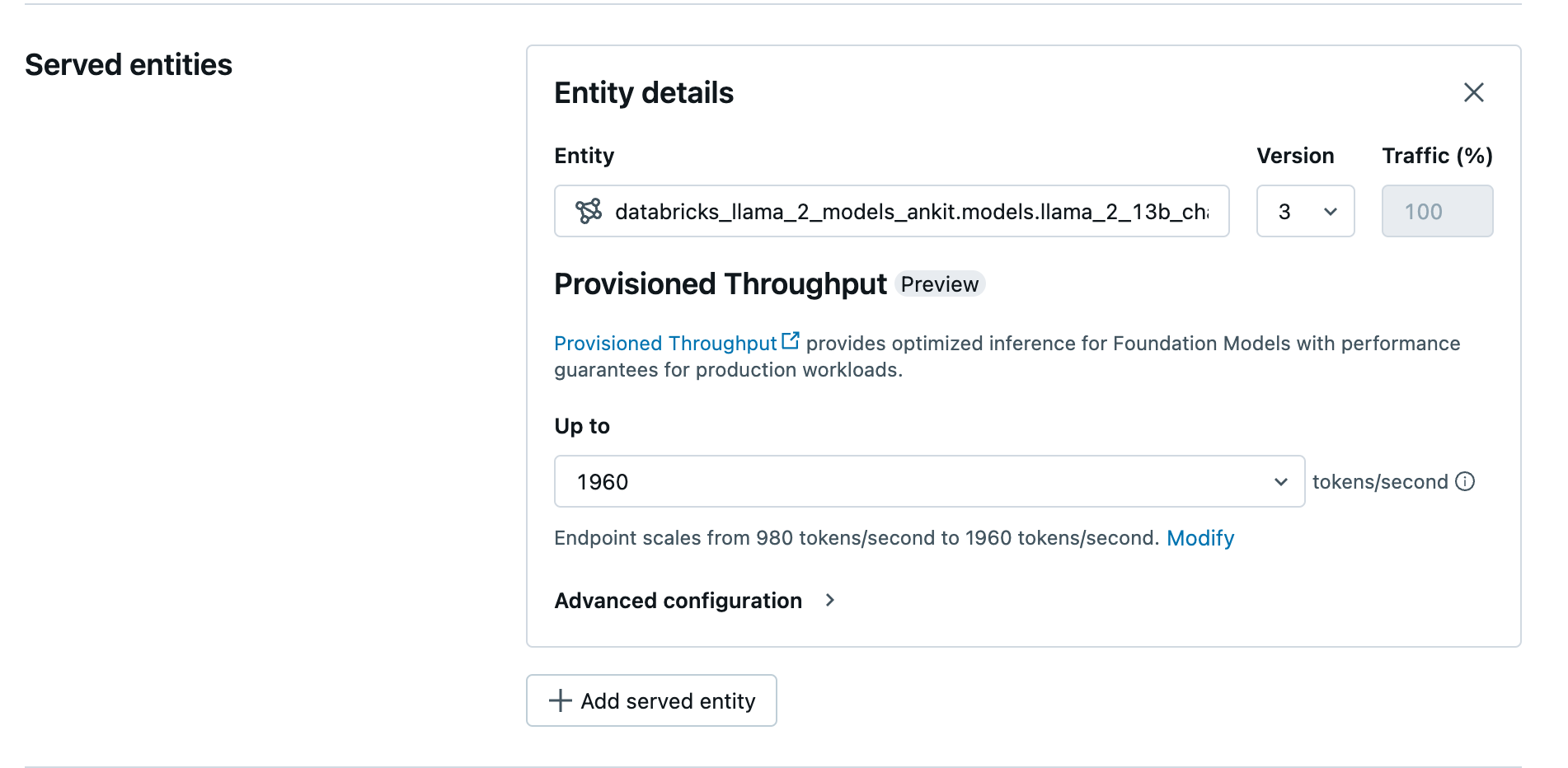
Skapa din etablerade dataflödesslutpunkt med hjälp av användargränssnittet
När den loggade modellen finns i Unity Catalog skapar du en etablerad dataflödesserverslutpunkt med följande steg:
- Gå till servicegränssnittet i din arbetsyta.
- Välj Skapa tjänsteslutpunkt.
- I fältet Entitet väljer du din modell från Unity Catalog. För berättigade modeller visar användargränssnittet för den betjänade entiteten skärmen Konfigurerad Genomströmning.
- I listrutan Upp till kan du konfigurera det maximala dataflödet för token per sekund för slutpunkten.
- Tilldelade dataflödesslutpunkter skalas automatiskt, så att du kan välja Ändra för att visa det minsta antalet tokens per sekund som slutpunkten kan minskas till.
Skapa din provisionerade genomströmningsslutpunkt med REST API
Om du vill distribuera din modell i etablerat dataflödesläge med hjälp av REST-API:et måste du ange min_provisioned_throughput och max_provisioned_throughput fält i din begäran. Om du föredrar Python kan du också skapa en slutpunkt med MLflow Deployment SDK.
Information om hur du identifierar lämpligt intervall med etablerat dataflöde för din modell finns i Hämta etablerat dataflöde i steg.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Logaritmisk sannolikhet för chattkompletteringsuppgifter
För uppgifter om chattens slutförande kan du använda parametern logprobs för att ange den logaritmiska sannolikheten för att en token samplas som en del av processen för att generera stora språkmodeller. Du kan använda logprobs för en mängd olika scenarier, till exempel klassificering, utvärdering av modellosäkerhet och körning av utvärderingsmått. Mer information om parametern finns i Chattaktivitet.
Hämta allokerad genomströmning i steg
Tilldelad genomströmning är tillgänglig i steg om token per sekund, där specifika steg varierar beroende på modell. För att identifiera det lämpliga intervallet för dina behov rekommenderar Databricks att du använder API:et för modelloptimeringsinformation på plattformen.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
Följande är ett exempelsvar från API:et:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
Anteckningsboksexempel
Följande anteckningsböcker visar exempel på hur man skapar ett API för allokerad genomströmning för Foundation Model.
Etablerad dataflödesserver för GTE-modellanteckningsbok
Reserverad genomströmning för BGE-modellens bärbara dator
Följande notebook-fil visar hur du kan ladda ned och registrera DeepSeek R1 destillerad Llama-modell i Unity Catalog, så att du kan distribuera den genom Foundation Model API:er via en slutpunkt för tilldelad bandbredd.
Tilldelad datakapacitet för användning med DeepSeek R1-destillerad Llama-modellnotebook
Begränsningar
- Modellutplaceringen kan misslyckas på grund av problem med GPU-kapaciteten, vilket resulterar i en timeout när slutpunkten skapas eller uppdateras. Kontakta ditt Databricks-kontoteam för att lösa problemet.
- Automatisk skalning för Foundation Models API:er är långsammare än modellbetjäning med processor. Databricks rekommenderar överprovisionering för att undvika begärandetidsgränser.
- GTE v1.5 (engelska) genererar inte normaliserade inbäddningar.