Skapa en träningskörning med hjälp av API:et för finjustering av foundation-modellen
Viktigt!
Den här funktionen finns i offentlig förhandsversion i följande regioner: centralus, eastus, eastus2, och .northcentraluswestus
Den här artikeln beskriver hur du skapar och konfigurerar en träningskörning med hjälp av API:et För grundläggande modell finjustering (nu en del av Mosaic AI Model Training) och beskriver alla parametrar som används i API-anropet. Du kan också skapa en körning med hjälp av användargränssnittet. Anvisningar finns i Skapa en träningskörning med hjälp av basmodellens finjusteringsgränssnitt.
Krav
Se Krav.
Skapa en träningskörning
Använd funktionen för create() att skapa träningskörningar programmatiskt. Den här funktionen tränar en modell på den angivna datamängden och konverterar den slutliga kontrollpunkten Composer till en huggande ansiktsformaterad kontrollpunkt för slutsatsdragning.
De indata som krävs är den modell som du vill träna, platsen för din träningsdatauppsättning och var du ska registrera din modell. Det finns också valfria parametrar som gör att du kan utföra utvärdering och ändra hyperparametrar för din körning.
När körningen är klar sparas den slutförda körningen och den slutliga kontrollpunkten, modellen klonas och klonen registreras i Unity Catalog som en modellversion för slutsatsdragning.
Modellen från den slutförda körningen inte den klonade modellversionen i Unity Catalog och dess Composer- och Hugging Face-kontrollpunkter sparas i MLflow. Kontrollpunkterna Composer kan användas för fortsatta finjusteringsuppgifter.
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-3.2-3B-Instruct',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
Konfigurera en träningskörning
I följande tabell sammanfattas parametrarna för funktionen foundation_model.create().
| Parameter | Obligatoriskt | Type | Description |
|---|---|---|---|
model |
x | Str | Namnet på den modell som ska användas. Se Modeller som stöds. |
train_data_path |
x | Str | Platsen för dina träningsdata. Det kan vara en plats i Unity Catalog (<catalog>.<schema>.<table> eller dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl), eller en HuggingFace-datauppsättning.För INSTRUCTION_FINETUNEska data formateras med varje rad som innehåller ett prompt och-fält response .För CONTINUED_PRETRAINär det här en mapp med .txt filer. Se Förbereda data för Foundation Model Finjustering för godkända dataformat och Rekommenderad datastorlek för modellträning för rekommendationer om datastorlek. |
register_to |
x | Str | Unity Catalog-katalogen och schemat (<catalog>.<schema> eller <catalog>.<schema>.<custom-name>) där modellen registreras efter träning för enkel driftsättning. Om custom-name inte anges används körnamnet som standard. |
data_prep_cluster_id |
Str | Kluster-ID för klustret som ska användas för Spark-databearbetning. Detta krävs för instruktionsträningsuppgifter där träningsdata finns i en Delta-tabell. Information om hur du hittar kluster-ID:t finns i Hämta kluster-ID. | |
experiment_path |
Str | Sökvägen till MLflow-experimentet där resultatet av träningskörningen (mått och kontrollpunkter) sparas. Standardvärdet är körningsnamnet på användarens personliga arbetsyta (dvs. /Users/<username>/<run_name>). |
|
task_type |
Str | Vilken typ av uppgift som ska köras. Kan vara CHAT_COMPLETION (standard), CONTINUED_PRETRAIN, eller INSTRUCTION_FINETUNE. |
|
eval_data_path |
Str | Fjärrplatsen för dina utvärderingsdata (om det finns några). Måste följa samma format som train_data_path. |
|
eval_prompts |
Lista[str] | En lista med promptsträngar för att generera svar vid utvärdering. Standardvärdet är None (generera inte prompter). Resultaten loggas till experimentet varje gång modellen är kontrollpunkt. Generationer sker vid varje modellkontrollpunkt med följande generationsparametrar: max_new_tokens: 100, temperature: 1, top_k: 50, top_p: 0.95, do_sample: true. |
|
custom_weights_path |
Str | Fjärrplatsen för en anpassad modellkontrollpunkt för träning. Standardvärdet är None, vilket innebär att körningen startar från den valda modellens ursprungliga förtränad vikt. Om anpassade vikter anges används dessa vikter i stället för modellens ursprungliga förtränad vikt. Dessa vikter måste vara en kontrollpunkt för Composer och måste matcha arkitekturen för den model angivna. Se Build on custom model weights (Skapa på anpassade modellvikter) |
|
training_duration |
Str | Den totala varaktigheten för körningen. Standardvärdet är en epok eller 1ep. Kan anges i epoker (10ep) eller token (1000000tok). |
|
learning_rate |
Str | Inlärningsfrekvensen för modellträning. För alla andra modeller än Llama 3.1 405B Instruct är 5e-7standardinlärningshastigheten . För Llama 3.1 405B Instruct är 1.0e-5standardinlärningsfrekvensen . Optimeraren är DecoupledLionW med betaversioner på 0,99 och 0,95 och ingen vikt förfall. Schemaläggaren för inlärningsfrekvens är LinearWithWarmupSchedule med en uppvärmning på 2 % av den totala utbildningsvaraktigheten och en slutlig inlärningsfrekvensmultiplikator på 0. |
|
context_length |
Str | Den maximala sekvenslängden för ett dataexempel. Detta används för att trunkera data som är för långa och för att paketera kortare sekvenser tillsammans för effektivitet. Standardvärdet är 8 192 token eller den maximala kontextlängden för den angivna modellen, beroende på vilket som är lägre. Du kan använda den här parametern för att konfigurera kontextlängden, men det går inte att konfigurera utöver varje modells maximala kontextlängd. Se Modeller som stöds för den maximala kontextlängden som stöds för varje modell. |
|
validate_inputs |
Booleskt | Om du vill verifiera åtkomsten till indatasökvägar innan du skickar träningsjobbet. Standard är True. |
Bygga på anpassade modellvikter
Grundmodell Finjustering har stöd för att lägga till anpassade vikter med hjälp av den valfria parametern custom_weights_path för att träna och anpassa en modell.
Kom igång genom att ange custom_weights_path till sökvägen för Composer kontrollpunktsfil från en tidigare träningspass. Kontrollpunktssökvägar finns på fliken Artefakter i en tidigare MLflow-körning. Namnet på kontrollpunktsmappen motsvarar batchen och epoken för en viss ögonblicksbild, till exempel ep29-ba30/.

- Om du vill ange den senaste kontrollpunkten från en tidigare körning anger du
custom_weights_pathtill kontrollpunkten Kompositör. Exempel:custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink - Ange en tidigare kontrollpunkt genom att ange
custom_weights_pathtill en sökväg till en mapp som innehåller.distcpfiler som motsvarar den önskade kontrollpunkten, till exempelcustom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#.
Uppdatera sedan parametern model så att den matchar basmodellen för kontrollpunkten som du skickade till custom_weights_path.
I följande exempel ift-meta-llama-3-1-70b-instruct-ohugkq är en tidigare körning som finjusterar meta-llama/Meta-Llama-3.1-70B. Om du vill finjustera den senaste kontrollpunkten från ift-meta-llama-3-1-70b-instruct-ohugkqanger du variablerna model och custom_weights_path enligt följande:
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
Se Konfigurera en träningskörning för att konfigurera andra parametrar i finjusteringskörningen.
Hämta kluster-ID
Så här hämtar du kluster-ID:t:
I det vänstra navigeringsfältet på Databricks-arbetsytan klickar du på Beräkning.
I tabellen klickar du på namnet på klustret.
Klicka på
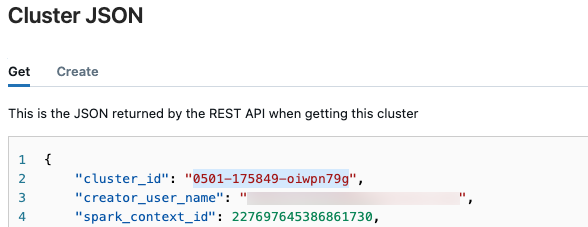
 i det övre högra hörnet och välj Visa JSON- i den nedrullningsbara menyn.
i det övre högra hörnet och välj Visa JSON- i den nedrullningsbara menyn.Kluster-JSON-filen visas. Kopiera kluster-ID:t, som är den första raden i filen.
Hämta status för en körning
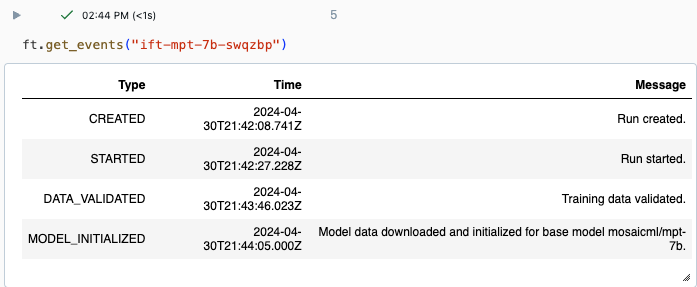
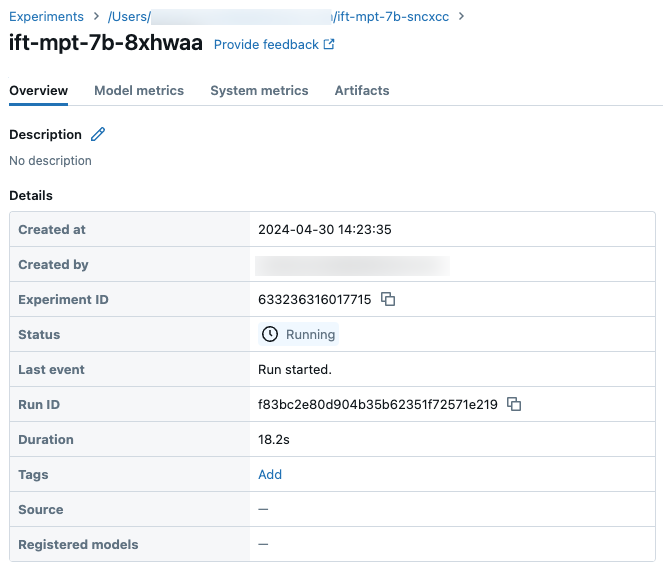
Du kan spåra förloppet för en körning med hjälp av sidan Experiment i Databricks-användargränssnittet eller med hjälp av API-kommandot get_events(). Mer information finns i Visa, hantera och analysera grundläggande modell Finjusteringskörningar.
Exempel på utdata från get_events():
Exempel på körningsinformation på sidan Experiment:
Nästa steg
När träningskörningen är klar kan du granska mått i MLflow och distribuera din modell för slutsatsdragning. Se steg 5 till och med 7 i Självstudie: Skapa och distribuera en grundmodell Finjusteringskörning.
Se instruktionens finjustering: Den namngivna demoanteckningsboken För entitetsigenkänning finns ett exempel på finjustering av instruktioner som går igenom dataförberedelser, finjustering av träningskörningskonfiguration och distribution.
Notebook-exempel
Följande notebook-fil visar ett exempel på hur du genererar syntetiska data med hjälp av Meta Llama 3.1 405B Instruct-modellen och använder dessa data för att finjustera en modell: