Vad är meddelandeläge för automatisk inläsning av fil?
I filmeddelandeläget konfigurerar Auto Loader automatiskt en meddelandetjänst och kötjänst som prenumererar på filhändelser från indatakatalogen. Du kan använda filmeddelanden för att skala Auto Loader för att mata in miljontals filer i timmen. Jämfört med kataloglistningsläget är filmeddelandeläget mer högpresterande och skalbart för stora indatakataloger eller en hög volym filer, men kräver ytterligare molnbehörigheter.
Du kan växla mellan filmeddelanden och kataloglistor när som helst och ändå upprätthålla garantier för databearbetning exakt en gång.
Kommentar
Filmeddelandeläget stöds inte för Azure Premium-lagringskonton eftersom Premium-konton inte stöder kölagring.
Varning
Det går inte att ändra källsökvägen för automatisk inläsning för filmeddelandeläget. Om filmeddelandeläget används och sökvägen ändras, kan du misslyckas med att inhämta filer som redan finns i den nya katalogen vid tidpunkten för uppdateringen av katalogen.
Molnresurser som används i meddelandeläge för automatisk inläsning av fil
Viktigt!
Du behöver utökade behörigheter för att automatiskt konfigurera molninfrastruktur för filmeddelandeläge. Kontakta molnadministratören eller arbetsyteadministratören. Se:
Automatisk inläsning kan konfigurera filaviseringar åt dig automatiskt när du anger alternativet cloudFiles.useNotifications till true och ge de behörigheter som krävs för att skapa molnresurser. Dessutom kan du behöva ange ytterligare alternativ för att bevilja automatisk inläsningsauktorisering för att skapa dessa resurser.
I följande tabell sammanfattas vilka resurser som skapas av Auto Loader.
| Molnlagring | Prenumerationstjänst | Kötjänst | Prefix* | Gräns** |
|---|---|---|---|---|
| Amazon S3 | AWS SNS | AWS SQS | databricks-auto-ingest | 100 per S3-bucket |
| ADLS Gen2 | Azure Event Grid | Azure Queue Storage | databricks | 500 per lagringskonto |
| GCS | Google Pub/Sub | Google Pub/Sub | databricks-auto-ingest | 100 per GCS-bucket |
| Azure Blob Storage | Azure Event Grid | Azure Queue Storage | databricks | 500 per lagringskonto |
- Auto loader namnger resurserna med det här prefixet.
** Hur många pipelines för samtidiga filmeddelanden som kan startas
Om du behöver köra mer än det begränsade antalet pipelines för filmeddelanden för ett visst lagringskonto kan du:
- Utnyttja en tjänst som AWS Lambda, Azure Functions eller Google Cloud Functions för att distribuera aviseringar från en enda kö, som lyssnar på en hel container eller bucket, till köer som är specifika för olika kataloger.
Filaviseringshändelser
Amazon S3 tillhandahåller en ObjectCreated-händelse när en fil laddas upp till en S3-hink, oavsett om den laddades upp med en enkel uppladdning eller som en flerdelsuppladdning.
ADLS Gen2 tillhandahåller olika händelsemeddelanden för filer som visas i din Gen2-container.
- Automatisk inläsning lyssnar efter händelsen för bearbetning av
FlushWithCloseen fil. - Automatiska inläsningsströmmar stöder
RenameFileåtgärden för att identifiera filer.RenameFileåtgärder kräver en API-begäran till lagringssystemet för att få storleken på den omdöpta filen. - Automatiska inläsningsströmmar som skapats med Databricks Runtime 9.0 och efter har stöd
RenameDirectoryför åtgärden för att identifiera filer.RenameDirectoryåtgärder kräver API-begäranden till lagringssystemet för att visa innehållet i den omdöpta katalogen.
Google Cloud Storage tillhandahåller en OBJECT_FINALIZE händelse när en fil laddas upp, som innehåller överskrivningar och filkopior. Misslyckade uppladdningar genererar inte den här händelsen.
Kommentar
Molnleverantörer garanterar inte 100 % leverans av alla filhändelser under mycket sällsynta förhållanden och tillhandahåller inte strikta serviceavtal för svarstiden för filhändelserna. Databricks rekommenderar att du utlöser regelbundna återfyllnad med automatisk inläsning med hjälp cloudFiles.backfillInterval av alternativet för att garantera att alla filer identifieras inom ett visst serviceavtal om data är fullständiga. Att utlösa vanliga återfyllnad orsakar inte dubbletter.
Nödvändiga behörigheter för att konfigurera filavisering för ADLS Gen2 och Azure Blob Storage
Du måste ha läsbehörighet för indatakatalogen. Se Azure Blob Storage.
Om du vill använda filmeddelandeläget måste du ange autentiseringsuppgifter för att konfigurera och komma åt händelsemeddelandetjänsterna.
Du kan autentisera med någon av följande metoder:
- Databricks-tjänstens autentiseringsuppgifter (rekommenderas): Skapa en tjänsteautentiseringsuppgift med hjälp av en hanterad identitet och en Databricks-åtkomstkoppling.
- Tjänsthuvudnamn: Skapa en Microsoft Entra ID (tidigare Azure Active Directory) app och tjänsthuvudnamn i form av klient-ID och klienthemlighet.
När du har hämtat autentiseringsuppgifterna tilldelar du de behörigheter som krävs till Databricks-åtkomstanslutningen (för autentiseringsuppgifter för tjänsten) eller Microsoft Entra ID-appen (för tjänstens huvudnamn).
Använda inbyggda Azure-roller
Tilldela åtkomstanslutningsappen följande roller till lagringskontot där indatasökvägen finns:
- Deltagare: Den här rollen är till för att konfigurera resurser i ditt lagringskonto, till exempel köer och händelseprenumerationer.
- Lagringsködatadeltagare: Den här rollen är till för att utföra köåtgärder som att hämta och ta bort meddelanden från köerna. Den här rollen krävs bara när du anger ett huvudnamn för tjänsten utan anslutningssträng.
Tilldela den här åtkomstanslutningsappen följande roll till den relaterade resursgruppen:
- EventGrid EventSubscription-deltagare: Den här rollen är till för att utföra prenumerationsåtgärder för Azure Event Grid (Event Grid), till exempel att skapa eller lista händelseprenumerationer.
Mer information finns i Tilldela Azure-roller med Azure-portalen.
Använda en anpassad roll
Om du är bekymrad över de överdrivna behörigheter som krävs för föregående roller kan du skapa en anpassad roll med minst följande behörigheter, som anges nedan i JSON-format för Azure-roll:
"permissions": [ { "actions": [ "Microsoft.EventGrid/eventSubscriptions/write", "Microsoft.EventGrid/eventSubscriptions/read", "Microsoft.EventGrid/eventSubscriptions/delete", "Microsoft.EventGrid/locations/eventSubscriptions/read", "Microsoft.Storage/storageAccounts/read", "Microsoft.Storage/storageAccounts/write", "Microsoft.Storage/storageAccounts/queueServices/read", "Microsoft.Storage/storageAccounts/queueServices/write", "Microsoft.Storage/storageAccounts/queueServices/queues/write", "Microsoft.Storage/storageAccounts/queueServices/queues/read", "Microsoft.Storage/storageAccounts/queueServices/queues/delete" ], "notActions": [], "dataActions": [ "Microsoft.Storage/storageAccounts/queueServices/queues/messages/delete", "Microsoft.Storage/storageAccounts/queueServices/queues/messages/read", "Microsoft.Storage/storageAccounts/queueServices/queues/messages/write", "Microsoft.Storage/storageAccounts/queueServices/queues/messages/process/action" ], "notDataActions": [] } ]Sedan kan du tilldela den här anpassade rollen till din åtkomstanslutning.
Mer information finns i Tilldela Azure-roller med Azure-portalen.
Behörigheter som krävs för att konfigurera filavisering för Amazon S3
Du måste ha läsbehörighet för indatakatalogen. Mer information finns i S3-anslutningsinformation .
Om du vill använda filmeddelandeläget bifogar du följande JSON-principdokument till din IAM-användare eller roll. Den här IAM-rollen krävs för att skapa en tjänstebehörighet för Automatisk inläsning att använda vid autentisering.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DatabricksAutoLoaderSetup",
"Effect": "Allow",
"Action": [
"s3:GetBucketNotification",
"s3:PutBucketNotification",
"sns:ListSubscriptionsByTopic",
"sns:GetTopicAttributes",
"sns:SetTopicAttributes",
"sns:CreateTopic",
"sns:TagResource",
"sns:Publish",
"sns:Subscribe",
"sqs:CreateQueue",
"sqs:DeleteMessage",
"sqs:ReceiveMessage",
"sqs:SendMessage",
"sqs:GetQueueUrl",
"sqs:GetQueueAttributes",
"sqs:SetQueueAttributes",
"sqs:TagQueue",
"sqs:ChangeMessageVisibility",
"sqs:PurgeQueue"
],
"Resource": [
"arn:aws:s3:::<bucket-name>",
"arn:aws:sqs:<region>:<account-number>:databricks-auto-ingest-*",
"arn:aws:sns:<region>:<account-number>:databricks-auto-ingest-*"
]
},
{
"Sid": "DatabricksAutoLoaderList",
"Effect": "Allow",
"Action": [
"sqs:ListQueues",
"sqs:ListQueueTags",
"sns:ListTopics"
],
"Resource": "*"
},
{
"Sid": "DatabricksAutoLoaderTeardown",
"Effect": "Allow",
"Action": [
"sns:Unsubscribe",
"sns:DeleteTopic",
"sqs:DeleteQueue"
],
"Resource": [
"arn:aws:sqs:<region>:<account-number>:databricks-auto-ingest-*",
"arn:aws:sns:<region>:<account-number>:databricks-auto-ingest-*"
]
}
]
}
där:
-
<bucket-name>: S3-bucketnamnet där strömmen läser filer, till exempelauto-logs. Du kan använda*som jokertecken,databricks-*-logstill exempel . Om du vill ta reda på den underliggande S3-bucketen för din DBFS-sökväg kan du visa en lista över alla DBFS-monteringspunkter i en notebook-fil genom att köra%fs mounts. -
<region>: Den AWS-region där S3-bucketen finns, till exempelus-west-2. Om du inte vill ange regionen använder du*. -
<account-number>: Det AWS-kontonummer som äger S3-bucketen,123456789012till exempel . Om du inte vill ange kontonumret använder du*.
Strängen databricks-auto-ingest-* i SQS- och SNS ARN-specifikationen är det namnprefix som cloudFiles källan använder när du skapar SQS- och SNS-tjänster. Eftersom Azure Databricks konfigurerar meddelandetjänsterna i den första körningen av dataströmmen kan du använda en princip med begränsade behörigheter efter den första körningen (till exempel stoppa strömmen och starta sedan om den).
Kommentar
Föregående princip gäller endast de behörigheter som krävs för att konfigurera filmeddelandetjänster, nämligen S3-bucketmeddelande, SNS- och SQS-tjänster och förutsätter att du redan har läsbehörighet till S3-bucketen. Om du behöver lägga till skrivskyddade S3-behörigheter lägger du till följande Action i listan i -instruktionen DatabricksAutoLoaderSetup i JSON-dokumentet:
s3:ListBuckets3:GetObject
Minskade behörigheter efter den första installationen
De behörigheter för resurskonfiguration som beskrivs ovan krävs endast under den första körningen av strömmen. Efter den första körningen kan du växla till följande IAM-princip med begränsade behörigheter.
Viktigt!
Med de begränsade behörigheterna kan du inte starta nya direktuppspelningsfrågor eller återskapa resurser vid fel (till exempel har SQS-kön tagits bort av misstag). Du kan inte heller använda API:et för hantering av molnresurser för att lista eller ta bort resurser.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DatabricksAutoLoaderUse",
"Effect": "Allow",
"Action": [
"s3:GetBucketNotification",
"sns:ListSubscriptionsByTopic",
"sns:GetTopicAttributes",
"sns:TagResource",
"sns:Publish",
"sqs:DeleteMessage",
"sqs:ReceiveMessage",
"sqs:SendMessage",
"sqs:GetQueueUrl",
"sqs:GetQueueAttributes",
"sqs:TagQueue",
"sqs:ChangeMessageVisibility",
"sqs:PurgeQueue"
],
"Resource": [
"arn:aws:sqs:<region>:<account-number>:<queue-name>",
"arn:aws:sns:<region>:<account-number>:<topic-name>",
"arn:aws:s3:::<bucket-name>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<bucket-name>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<bucket-name>/*"
]
},
{
"Sid": "DatabricksAutoLoaderListTopics",
"Effect": "Allow",
"Action": [
"sqs:ListQueues",
"sqs:ListQueueTags",
"sns:ListTopics"
],
"Resource": "arn:aws:sns:<region>:<account-number>:*"
}
]
}
Nödvändiga behörigheter för att konfigurera filavisering för GCS
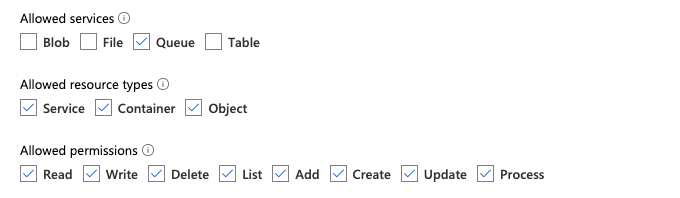
Du måste ha list och get behörigheter på din GCS-bucket och på alla objekt. Mer information finns i Google-dokumentationen om IAM-behörigheter.
Om du vill använda filmeddelandeläget måste du lägga till behörigheter för GCS-tjänstkontot och tjänstkontot som används för att komma åt Google Cloud Pub/Sub-resurserna.
Pub/Sub Publisher Lägg till rollen i GCS-tjänstkontot. På så sätt kan kontot publicera meddelanden om händelser från dina GCS-bucketar till Google Cloud Pub/Sub.
När det gäller tjänstkontot som används för Google Cloud Pub/Sub-resurserna måste du lägga till följande behörigheter. Det här tjänstkontot skapas automatiskt när du skapar en Databricks-tjänstautentiseringsuppgifter.
pubsub.subscriptions.consume
pubsub.subscriptions.create
pubsub.subscriptions.delete
pubsub.subscriptions.get
pubsub.subscriptions.list
pubsub.subscriptions.update
pubsub.topics.attachSubscription
pubsub.topics.create
pubsub.topics.delete
pubsub.topics.get
pubsub.topics.list
pubsub.topics.update
För att göra detta kan du antingen skapa en anpassad IAM-roll med dessa behörigheter eller tilldela befintliga GCP-roller för att täcka dessa behörigheter.
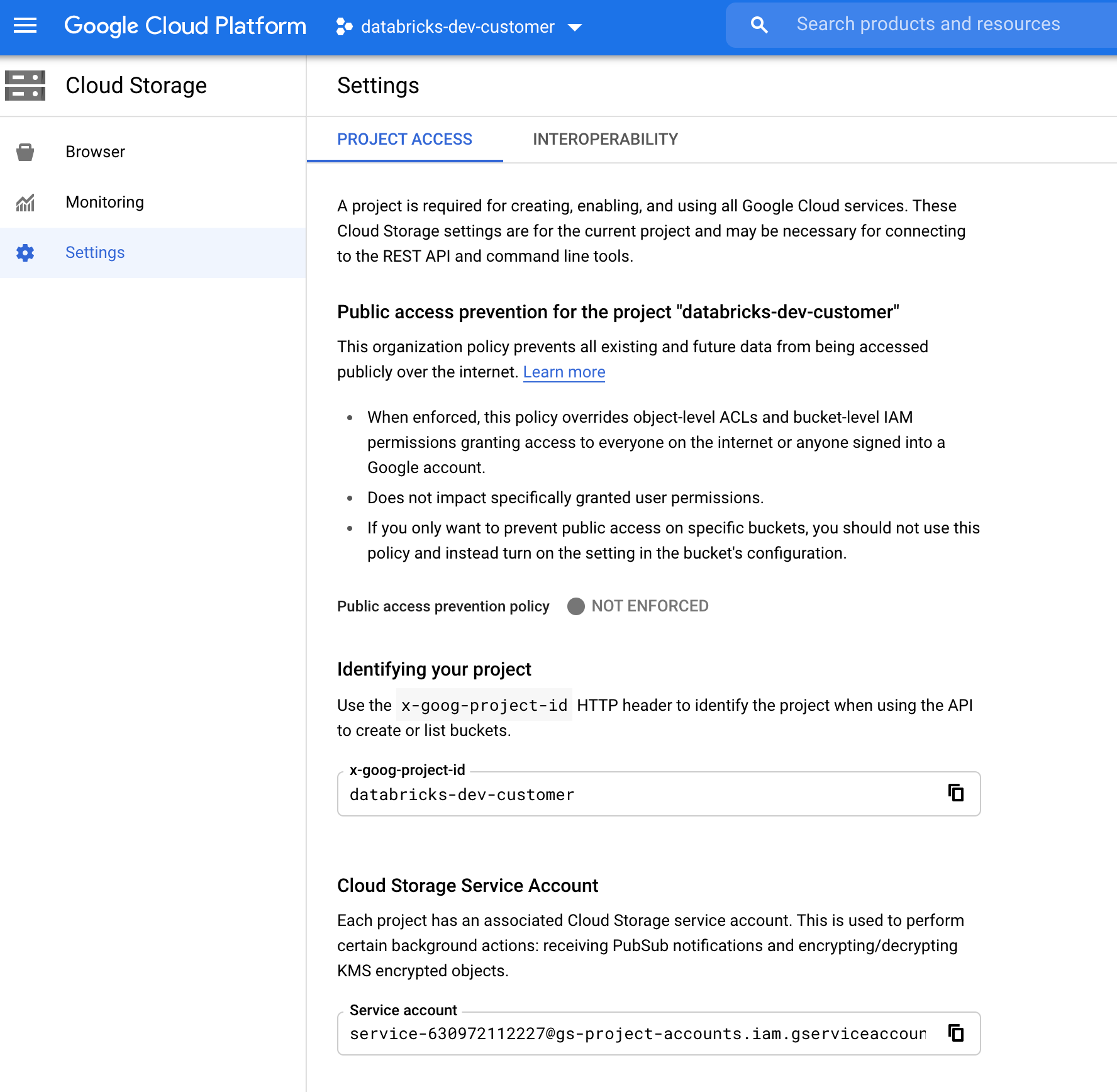
Hitta GCS-tjänstkontot
I Google Cloud Console för motsvarande projekt går du till Cloud Storage > Settings.
Avsnittet "Molnlagringstjänstkonto" innehåller e-postmeddelandet för GCS-tjänstkontot.
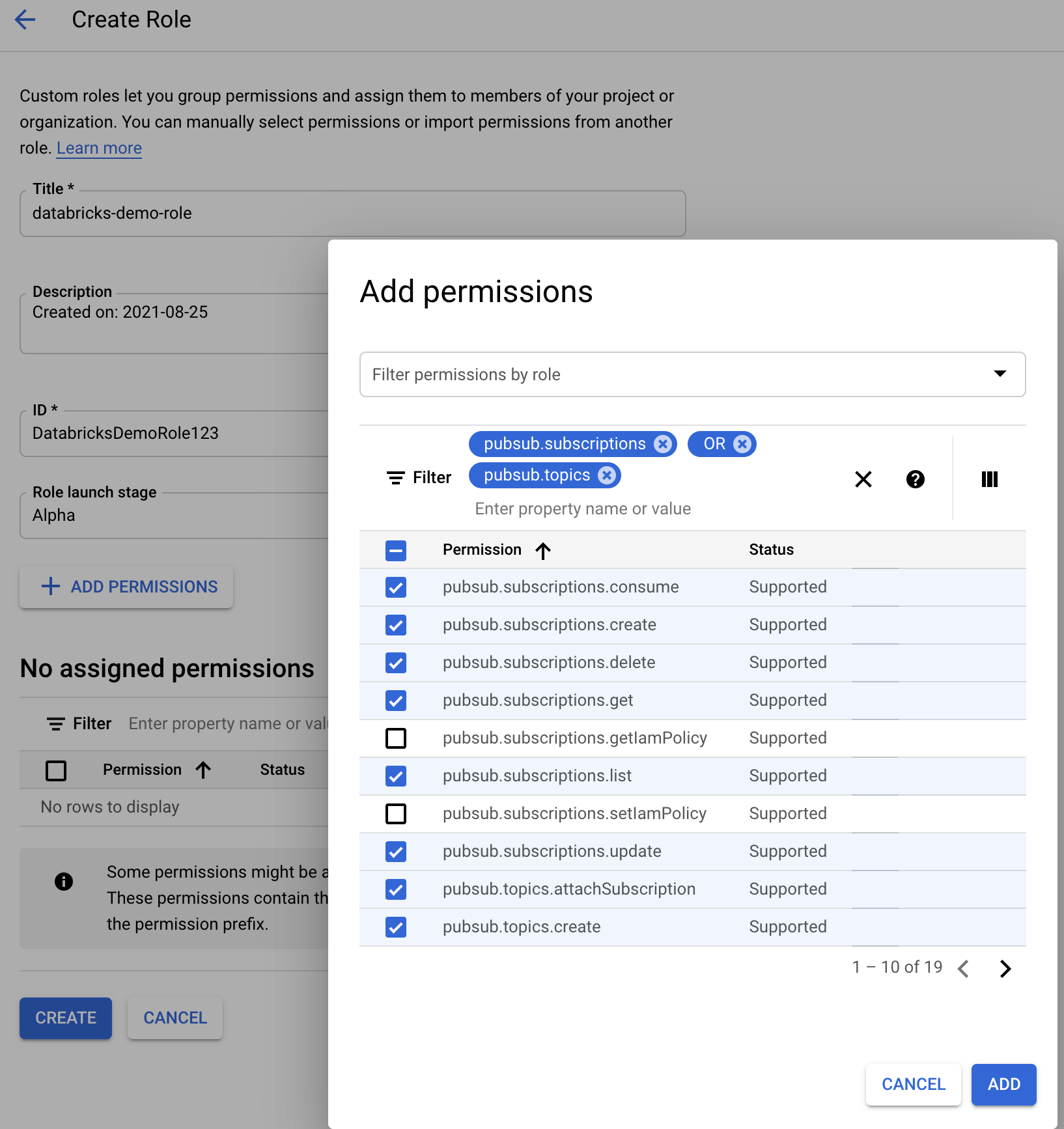
Skapa en anpassad Google Cloud IAM-roll för filmeddelandeläge
I Google Cloud-konsolen för motsvarande projekt går du till IAM & Admin > Roles. Skapa sedan en roll överst eller uppdatera en befintlig roll. På skärmen för att skapa eller redigera rollen klickar du på Add Permissions. En meny visas där du kan lägga till önskade behörigheter i rollen.
Konfigurera eller hantera filaviseringsresurser manuellt
Privilegierade användare kan konfigurera eller hantera filaviseringsresurser manuellt.
- Konfigurera filmeddelandetjänsterna manuellt via molnleverantören och ange köidentifieraren manuellt. Mer information finns i Alternativ för filmeddelanden.
- Använd Scala-API:er för att skapa eller hantera meddelanden och kötjänster, enligt följande exempel:
Kommentar
Du måste ha rätt behörighet för att konfigurera eller ändra molninfrastrukturen. Se behörighetsdokumentationen för Azure, S3 eller GCS.
Python
# Databricks notebook source
# MAGIC %md ## Python bindings for CloudFiles Resource Managers for all 3 clouds
# COMMAND ----------
#####################################
## Creating a ResourceManager in AWS
#####################################
# Using a Databricks service credential
manager = spark._jvm.com.databricks.sql.CloudFilesAWSResourceManager \
.newManager() \
.option("cloudFiles.region", <region>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.option("databricks.serviceCredential", <service-credential-name>) \
.create()
# Using AWS access key and secret key
manager = spark._jvm.com.databricks.sql.CloudFilesAWSResourceManager \
.newManager() \
.option("cloudFiles.region", <region>) \
.option("cloudFiles.awsAccessKey", <aws-access-key>) \
.option("cloudFiles.awsSecretKey", <aws-secret-key>) \
.option("cloudFiles.roleArn", <role-arn>) \
.option("cloudFiles.roleExternalId", <role-external-id>) \
.option("cloudFiles.roleSessionName", <role-session-name>) \
.option("cloudFiles.stsEndpoint", <sts-endpoint>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.create()
#######################################
## Creating a ResourceManager in Azure
#######################################
# Using a Databricks service credential
manager = spark._jvm.com.databricks.sql.CloudFilesAzureResourceManager \
.newManager() \
.option("cloudFiles.resourceGroup", <resource-group>) \
.option("cloudFiles.subscriptionId", <subscription-id>) \
.option("databricks.serviceCredential", <service-credential-name>) \
.option("path", <path-to-specific-container-and-folder>) \
.create()
# Using an Azure service principal
manager = spark._jvm.com.databricks.sql.CloudFilesAzureResourceManager \
.newManager() \
.option("cloudFiles.connectionString", <connection-string>) \
.option("cloudFiles.resourceGroup", <resource-group>) \
.option("cloudFiles.subscriptionId", <subscription-id>) \
.option("cloudFiles.tenantId", <tenant-id>) \
.option("cloudFiles.clientId", <service-principal-client-id>) \
.option("cloudFiles.clientSecret", <service-principal-client-secret>) \
.option("path", <path-to-specific-container-and-folder>) \
.create()
#######################################
## Creating a ResourceManager in GCP
#######################################
# Using a Databricks service credential
manager = spark._jvm.com.databricks.sql.CloudFilesGCPResourceManager \
.newManager() \
.option("cloudFiles.projectId", <project-id>) \
.option("databricks.serviceCredential", <service-credential-name>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.create()
# Using a Google service account
manager = spark._jvm.com.databricks.sql.CloudFilesGCPResourceManager \
.newManager() \
.option("cloudFiles.projectId", <project-id>) \
.option("cloudFiles.client", <client-id>) \
.option("cloudFiles.clientEmail", <client-email>) \
.option("cloudFiles.privateKey", <private-key>) \
.option("cloudFiles.privateKeyId", <private-key-id>) \
.option("path", <path-to-specific-bucket-and-folder>) \
.create()
# Set up a queue and a topic subscribed to the path provided in the manager.
manager.setUpNotificationServices(<resource-suffix>)
# List notification services created by <AL>
from pyspark.sql import DataFrame
df = DataFrame(manager.listNotificationServices(), spark)
# Tear down the notification services created for a specific stream ID.
# Stream ID is a GUID string that you can find in the list result above.
manager.tearDownNotificationServices(<stream-id>)
Scala
/////////////////////////////////////
// Creating a ResourceManager in AWS
/////////////////////////////////////
import com.databricks.sql.CloudFilesAWSResourceManager
/**
* Using a Databricks service credential
*/
val manager = CloudFilesAWSResourceManager
.newManager
.option("cloudFiles.region", <region>) // optional, will use the region of the EC2 instances by default
.option("databricks.serviceCredential", <service-credential-name>)
.option("path", <path-to-specific-bucket-and-folder>) // required only for setUpNotificationServices
.create()
/**
* Using AWS access key and secret key
*/
val manager = CloudFilesAWSResourceManager
.newManager
.option("cloudFiles.region", <region>)
.option("cloudFiles.awsAccessKey", <aws-access-key>)
.option("cloudFiles.awsSecretKey", <aws-secret-key>)
.option("cloudFiles.roleArn", <role-arn>)
.option("cloudFiles.roleExternalId", <role-external-id>)
.option("cloudFiles.roleSessionName", <role-session-name>)
.option("cloudFiles.stsEndpoint", <sts-endpoint>)
.option("path", <path-to-specific-bucket-and-folder>) // required only for setUpNotificationServices
.create()
///////////////////////////////////////
// Creating a ResourceManager in Azure
///////////////////////////////////////
import com.databricks.sql.CloudFilesAzureResourceManager
/**
* Using a Databricks service credential
*/
val manager = CloudFilesAzureResourceManager
.newManager
.option("cloudFiles.resourceGroup", <resource-group>)
.option("cloudFiles.subscriptionId", <subscription-id>)
.option("databricks.serviceCredential", <service-credential-name>)
.option("path", <path-to-specific-container-and-folder>) // required only for setUpNotificationServices
.create()
/**
* Using an Azure service principal
*/
val manager = CloudFilesAzureResourceManager
.newManager
.option("cloudFiles.connectionString", <connection-string>)
.option("cloudFiles.resourceGroup", <resource-group>)
.option("cloudFiles.subscriptionId", <subscription-id>)
.option("cloudFiles.tenantId", <tenant-id>)
.option("cloudFiles.clientId", <service-principal-client-id>)
.option("cloudFiles.clientSecret", <service-principal-client-secret>)
.option("path", <path-to-specific-container-and-folder>) // required only for setUpNotificationServices
.create()
///////////////////////////////////////
// Creating a ResourceManager in GCP
///////////////////////////////////////
import com.databricks.sql.CloudFilesGCPResourceManager
/**
* Using a Databricks service credential
*/
val manager = CloudFilesGCPResourceManager
.newManager
.option("cloudFiles.projectId", <project-id>)
.option("databricks.serviceCredential", <service-credential-name>)
.option("path", <path-to-specific-bucket-and-folder>) // Required only for setUpNotificationServices.
.create()
/**
* Using a Google service account
*/
val manager = CloudFilesGCPResourceManager
.newManager
.option("cloudFiles.projectId", <project-id>)
.option("cloudFiles.client", <client-id>)
.option("cloudFiles.clientEmail", <client-email>)
.option("cloudFiles.privateKey", <private-key>)
.option("cloudFiles.privateKeyId", <private-key-id>)
.option("path", <path-to-specific-bucket-and-folder>) // Required only for setUpNotificationServices.
.create()
// Set up a queue and a topic subscribed to the path provided in the manager.
manager.setUpNotificationServices(<resource-suffix>)
// List notification services created by <AL>
val df = manager.listNotificationServices()
// Tear down the notification services created for a specific stream ID.
// Stream ID is a GUID string that you can find in the list result above.
manager.tearDownNotificationServices(<stream-id>)
Använd setUpNotificationServices(<resource-suffix>) för att skapa en kö och en prenumeration med namnet <prefix>-<resource-suffix> (prefixet beror på lagringssystemet som sammanfattas i Molnresurser som används i meddelandeläge för automatisk inläsning av fil. Om det finns en befintlig resurs med samma namn återanvänder Azure Databricks den befintliga resursen i stället för att skapa en ny. Den här funktionen returnerar en köidentifierare som du kan skicka till cloudFiles källan med hjälp av identifieraren i Filaviseringsalternativ. På så sätt kan källanvändaren cloudFiles ha färre behörigheter än den användare som skapar resurserna.
Ange alternativet "path" till newManager endast om anropa ; setUpNotificationServicesdet behövs inte för listNotificationServices eller tearDownNotificationServices. Det här är samma path som du använder när du kör en direktuppspelningsfråga.
Följande matris anger vilka API-metoder som stöds där Databricks Runtime för varje typ av lagring:
| Molnlagring | Installations-API | List-API | Riva ned API |
|---|---|---|---|
| Amazon S3 | Alla versioner | Alla versioner | Alla versioner |
| ADLS Gen2 | Alla versioner | Alla versioner | Alla versioner |
| GCS | Databricks Runtime 9.1 och senare | Databricks Runtime 9.1 och senare | Databricks Runtime 9.1 och senare |
| Azure Blob Storage | Alla versioner | Alla versioner | Alla versioner |
| ADLS Gen1 | Stöd saknas | Stöd saknas | Stöd saknas |
Felsöka vanliga fel
I det här avsnittet beskrivs vanliga fel när du använder Auto Loader med filmeddelandeläge och hur du löser dem.
Det gick inte att skapa En Event Grid-prenumeration
Om du ser följande felmeddelande när du kör Auto Loader för första gången registreras inte Event Grid som resursprovider i Azure-prenumerationen.
java.lang.RuntimeException: Failed to create event grid subscription.
Om du vill registrera Event Grid som en resursprovider gör du följande:
- Gå till din prenumeration i Azure-portalen.
- Klicka på Resursprovidrar under avsnittet Inställningar.
- Registrera leverantören
Microsoft.EventGrid.
Auktorisering krävs för att utföra Event Grid-prenumerationsåtgärder
Om du ser följande felmeddelande när du kör Auto Loader för första gången, kontrollerar du att rollen deltagare tilldelas tjänsthuvudmannen för Event Grid och lagringskontot.
403 Forbidden ... does not have authorization to perform action 'Microsoft.EventGrid/eventSubscriptions/[read|write]' over scope ...
Event Grid-klienten kringgår proxy
I Databricks Runtime 15.2 och senare använder Event Grid-anslutningar i Auto Loader proxyinställningar från systemegenskaper som standard. I Databricks Runtime 13.3 LTS, 14.3 LTS och 15.0 till 15.2 kan du manuellt konfigurera Event Grid-anslutningar för att använda en proxy genom att ange egenskapen Spark Configspark.databricks.cloudFiles.eventGridClient.useSystemProperties true. Se Ange Spark-konfigurationsegenskaper på Azure Databricks.