Kom igång: Förbättra och rensa data
Den här kom igång-artikeln beskriver hur du använder en Azure Databricks-notebook-fil för att rensa och förbättra babynamnsdata för New York State som tidigare lästes in i en tabell i Unity Catalog med hjälp av Python, Scala och R. I den här artikeln ändrar du kolumnnamn, ändrar versaler och stavar ut könet för varje babynamn från rådatatabellen – och sparar sedan DataFrame i en silvertabell. Sedan filtrerar du data så att de endast innehåller data för 2021, grupperar data på tillståndsnivå och sorterar sedan data efter antal. Slutligen sparar du dataramen i en guldtabell och visualiserar data i ett stapeldiagram. För mer information om silver- och guldtabeller, se medallionarkitektur .
Viktigt!
Den här kom igång-artikeln bygger på Kom igång: Mata in och infoga ytterligare data. Du måste slutföra stegen i den artikeln för att slutföra den här artikeln. Den fullständiga notebook-filen för att komma igång finns i Mata in ytterligare dataanteckningsböcker.
Krav
För att slutföra uppgifterna i den här artikeln måste du uppfylla följande krav:
- Arbetsytan måste ha Unity Catalog aktiverad. Information om hur du kommer igång med Unity Catalog finns i Konfigurera och hantera Unity Catalog.
- Du måste ha
WRITE VOLUMEbehörighet på en volym,USE SCHEMAbehörighet för det överordnade schemat ochUSE CATALOGbehörighet i den överordnade katalogen. - Du måste ha behörighet att använda en befintlig beräkningsresurs eller skapa en ny beräkningsresurs. Se Kom igång med Azure Databricks eller se din Databricks-administratör.
Dricks
En slutförd notebook-fil för den här artikeln finns i Rensa och förbättra dataanteckningsböcker.
Steg 1: Skapa en ny notebook-fil
Om du vill skapa en notebook-fil på arbetsytan klickar du på ![]() Nytt i sidofältet och klickar sedan på Notebook. En tom anteckningsbok öppnas på arbetsytan.
Nytt i sidofältet och klickar sedan på Notebook. En tom anteckningsbok öppnas på arbetsytan.
Mer information om hur du skapar och hanterar notebook-filer finns i Hantera notebook-filer.
Steg 2: Definiera variabler
I det här steget definierar du variabler som ska användas i den notebook-exempelanteckningsbok som du skapar i den här artikeln.
Kopiera och klistra in följande kod i den nya tomma notebook-cellen. Ersätt
<catalog-name>,<schema-name>och<volume-name>med katalog-, schema- och volymnamnen för en Unity Catalog-volym. Alternativt kan du ersätta värdettable_namemed ett valfritt tabellnamn. Du sparar babynamndata i den här tabellen senare i den här artikeln.Tryck
Shift+Enterför att köra cellen och skapa en ny tom cell.Python
catalog = "<catalog_name>" schema = "<schema_name>" table_name = "baby_names" silver_table_name = "baby_names_prepared" gold_table_name = "top_baby_names_2021" path_table = catalog + "." + schema print(path_table) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val tableName = "baby_names" val silverTableName = "baby_names_prepared" val goldTableName = "top_baby_names_2021" val pathTable = s"${catalog}.${schema}" print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" table_name <- "baby_names" silver_table_name <- "baby_names_prepared" gold_table_name <- "top_baby_names_2021" path_table <- paste(catalog, ".", schema, sep = "") print(path_table) # Show the complete path
Steg 3: Läs in rådata i en ny DataFrame
Det här steget läser in rådata som tidigare sparats i en Delta-tabell till en ny DataFrame som förberedelse för rensning och förbättring av dessa data för ytterligare analys.
Kopiera och klistra in följande kod i den nya tomma notebook-cellen.
Python
df_raw = spark.read.table(f"{path_table}.{table_name}") display(df_raw)Scala
val dfRaw = spark.read.table(s"${pathTable}.${tableName}") display(dfRaw)R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df_raw = sql(paste0("SELECT * FROM ", path_table, ".", table_name)) display(df_raw)Tryck
Shift+Enterför att köra cellen och flytta sedan till nästa cell.
Steg 4: Rensa och förbättra rådata och spara
I det här steget ändrar du namnet på kolumnen Year, ändrar data i kolumnen First_Name till inledande versaler och uppdaterar värdena för kolumnen Sex för att stava ut könet och sparar sedan DataFrame i en ny tabell.
Kopiera och klistra in följande kod i en tom notebook-cell.
Python
from pyspark.sql.functions import col, initcap, when # Rename "Year" column to "Year_Of_Birth" df_rename_year = df_raw.withColumnRenamed("Year", "Year_Of_Birth") # Change the case of "First_Name" column to initcap df_init_caps = df_rename_year.withColumn("First_Name", initcap(col("First_Name").cast("string"))) # Update column values from "M" to "male" and "F" to "female" df_baby_names_sex = df_init_caps.withColumn( "Sex", when(col("Sex") == "M", "Male") .when(col("Sex") == "F", "Female") ) # display display(df_baby_names_sex) # Save DataFrame to table df_baby_names_sex.write.mode("overwrite").saveAsTable(f"{path_table}.{silver_table_name}")Scala
import org.apache.spark.sql.functions.{col, initcap, when} // Rename "Year" column to "Year_Of_Birth" val dfRenameYear = dfRaw.withColumnRenamed("Year", "Year_Of_Birth") // Change the case of "First_Name" data to initial caps val dfNameInitCaps = dfRenameYear.withColumn("First_Name", initcap(col("First_Name").cast("string"))) // Update column values from "M" to "Male" and "F" to "Female" val dfBabyNamesSex = dfNameInitCaps.withColumn("Sex", when(col("Sex") equalTo "M", "Male") .when(col("Sex") equalTo "F", "Female")) // Display the data display(dfBabyNamesSex) // Save DataFrame to a table dfBabyNamesSex.write.mode("overwrite").saveAsTable(s"${pathTable}.${silverTableName}")R
# Rename "Year" column to "Year_Of_Birth" df_rename_year <- withColumnRenamed(df_raw, "Year", "Year_Of_Birth") # Change the case of "First_Name" data to initial caps df_init_caps <- withColumn(df_rename_year, "First_Name", initcap(df_rename_year$First_Name)) # Update column values from "M" to "Male" and "F" to "Female" df_baby_names_sex <- withColumn(df_init_caps, "Sex", ifelse(df_init_caps$Sex == "M", "Male", ifelse(df_init_caps$Sex == "F", "Female", df_init_caps$Sex))) # Display the data display(df_baby_names_sex) # Save DataFrame to a table saveAsTable(df_baby_names_sex, paste(path_table, ".", silver_table_name), mode = "overwrite")Tryck
Shift+Enterför att köra cellen och flytta sedan till nästa cell.
Steg 5: Gruppera och visualisera data
I det här steget filtrerar du data till endast år 2021, grupperar data efter kön och namn, aggregerar efter antal och ordning efter antal. Sedan sparar du DataFrame i en tabell och visualiserar sedan data i ett stapeldiagram.
Kopiera och klistra in följande kod i en tom notebook-cell.
Python
from pyspark.sql.functions import expr, sum, desc from pyspark.sql import Window # Count of names for entire state of New York by sex df_baby_names_2021_grouped=(df_baby_names_sex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count"))) # Display data display(df_baby_names_2021_grouped) # Save DataFrame to a table df_baby_names_2021_grouped.write.mode("overwrite").saveAsTable(f"{path_table}.{gold_table_name}")Scala
import org.apache.spark.sql.functions.{expr, sum, desc} import org.apache.spark.sql.expressions.Window // Count of male and female names for entire state of New York by sex val dfBabyNames2021Grouped = dfBabyNamesSex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count")) // Display data display(dfBabyNames2021Grouped) // Save DataFrame to a table dfBabyNames2021Grouped.write.mode("overwrite").saveAsTable(s"${pathTable}.${goldTableName}")R
# Filter to only 2021 data df_baby_names_2021 <- filter(df_baby_names_sex, df_baby_names_sex$Year_Of_Birth == 2021) # Count of names for entire state of New York by sex df_baby_names_grouped <- agg( groupBy(df_baby_names_2021, df_baby_names_2021$Sex, df_baby_names_2021$First_Name), Total_Count = sum(df_baby_names_2021$Count) ) # Display data display(arrange(select(df_baby_names_grouped, df_baby_names_grouped$Sex, df_baby_names_grouped$First_Name, df_baby_names_grouped$Total_Count), desc(df_baby_names_grouped$Total_Count))) # Save DataFrame to a table saveAsTable(df_baby_names_2021_grouped, paste(path_table, ".", gold_table_name), mode = "overwrite")Tryck
Ctrl+Enterför att köra cellen.-
- Bredvid fliken Tabell klickar du på + och klickar sedan på Visualisering.
I visualiseringsredigeraren klickar du på Visualiseringstyp och kontrollerar att Fältet är markerat.
I kolumnen Xväljer du
First_Name.Klicka på Lägg till kolumn under Y-kolumner och välj sedan Total_Count.
I Gruppering efterväljer du Kön.
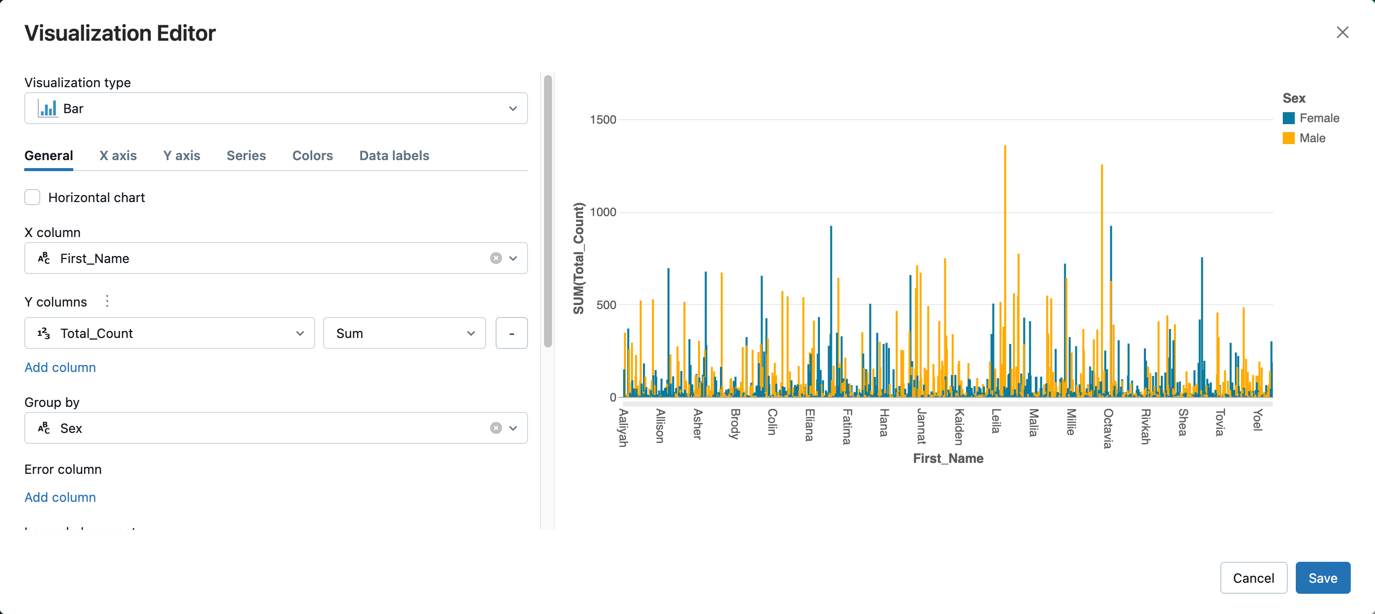
Klicka på Spara.
Rensa och förbättra dataanteckningsböcker
Använd någon av följande notebook-filer för att utföra stegen i den här artikeln. Ersätt <catalog-name>, <schema-name>och <volume-name> med katalog-, schema- och volymnamnen för en Unity Catalog-volym. Alternativt kan du ersätta värdet table_name med ett valfritt tabellnamn.