Introduktion till RAG i AI-utveckling
Den här artikeln är en introduktion till hämtningsförhöjd generation (RAG): vad det är, hur det fungerar och viktiga begrepp.
Vad är hämtningsförhöjd generation?
RAG är en teknik som gör det möjligt för en stor språkmodell (LLM) att generera berikade svar genom att utöka en användares uppmaning med stöddata som hämtats från en extern informationskälla. Genom att införliva den här hämtade informationen gör RAG det möjligt för LLM att generera mer exakta svar av högre kvalitet jämfört med att inte utöka prompten med ytterligare kontext.
Anta till exempel att du skapar en chattrobot med frågor och svar som hjälper anställda att svara på frågor om företagets egna dokument. En fristående LLM kommer inte att kunna besvara frågor om innehållet i dessa dokument korrekt om det inte har tränats specifikt på dem. LLM kan vägra att svara på grund av brist på information eller, ännu värre, det kan generera ett felaktigt svar.
RAG löser det här problemet genom att först hämta relevant information från företagsdokumenten baserat på en användares fråga och sedan tillhandahålla den hämtade informationen till LLM som ytterligare kontext. Detta gör att LLM kan generera ett mer exakt svar genom att dra från den specifika information som finns i relevanta dokument. I grund och botten gör RAG det möjligt för LLM att "konsultera" den hämtade informationen för att formulera sitt svar.
Kärnkomponenter i ett RAG-program
Ett RAG-program är ett exempel på ett sammansatt AI-system: Det utökar enbart modellens språkfunktioner genom att kombinera det med andra verktyg och procedurer.
När du använder en fristående LLM skickar en användare en begäran, till exempel en fråga, till LLM, och LLM svarar med ett svar baserat enbart på dess träningsdata.
I sin mest grundläggande form sker följande steg i ett RAG-program:
- Hämtning: Användarens begäran används för att fråga efter någon annan informationskälla. Det kan innebära att köra frågor mot ett vektorlager, utföra en nyckelordssökning över viss text eller köra frågor mot en SQL-databas. Målet med hämtningssteget är att hämta stöddata som hjälper LLM att ge ett användbart svar.
- Tillägg: Stöddata från hämtningssteget kombineras med användarens begäran, ofta med hjälp av en mall med ytterligare formatering och instruktioner till LLM, för att skapa en uppmaning.
- Generation: Den resulterande prompten skickas till LLM och LLM genererar ett svar på användarens begäran.
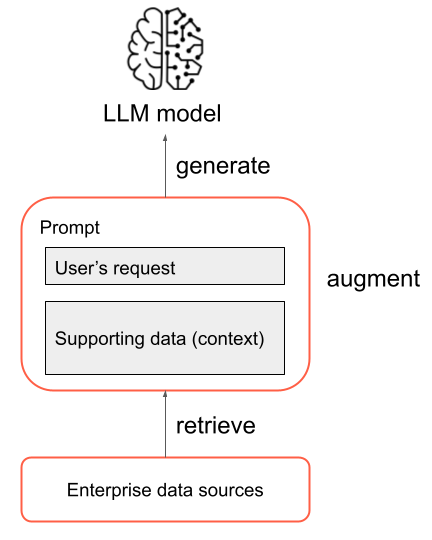
Det här är en förenklad översikt över RAG-processen, men det är viktigt att observera att implementeringen av ett RAG-program omfattar många komplexa uppgifter. Förbearbetning av källdata för att göra dem lämpliga för användning i RAG, effektivt hämta data, formatera den förhöjda prompten och utvärdera de genererade svaren kräver noggrant övervägande och ansträngning. De här ämnena kommer att behandlas mer detaljerat i senare avsnitt i den här guiden.
Varför ska jag använda RAG?
I följande tabell beskrivs fördelarna med att använda RAG jämfört med en fristående LLM:
| Med en LLM ensam | Använda LLM:er med RAG |
|---|---|
| Ingen patentskyddad kunskap: LLM:er tränas vanligtvis på offentligt tillgängliga data, så de kan inte korrekt besvara frågor om ett företags interna eller upphovsrättsskyddade data. | RAG-program kan innehålla upphovsrättsskyddade data: Ett RAG-program kan tillhandahålla patentskyddade dokument som pm, e-postmeddelanden och designdokument till en LLM, vilket gör det möjligt för det att besvara frågor om dessa dokument. |
| Kunskapen uppdateras inte i realtid: LLM:er har inte åtkomst till information om händelser som inträffade efter att de tränats. Till exempel kan en fristående LLM inte berätta något om aktierörelser idag. | RAG-program kan komma åt realtidsdata: Ett RAG-program kan förse LLM med aktuell information från en uppdaterad datakälla, vilket gör att den kan ge användbara svar om händelser efter träningsavstängningsdatumet. |
| Brist på citat: LLM:er kan inte citera specifika informationskällor när de svarar, vilket gör att användaren inte kan kontrollera om svaret är korrekt eller om det är en hallucination. | RAG kan citera källor: När den används som en del av ett RAG-program kan en LLM uppmanas att citera sina källor. |
| Brist på dataåtkomstkontroller (ACL:er): LLM:er kan inte ensamma på ett tillförlitligt sätt ge olika svar till olika användare baserat på specifika användarbehörigheter. | RAG tillåter datasäkerhet/ACL:er: Hämtningssteget kan utformas för att endast hitta den information som användaren har autentiseringsuppgifter för åtkomst, vilket gör det möjligt för ett RAG-program att selektivt hämta personlig eller upphovsrättsskyddad information. |
RAG-programkomponenter
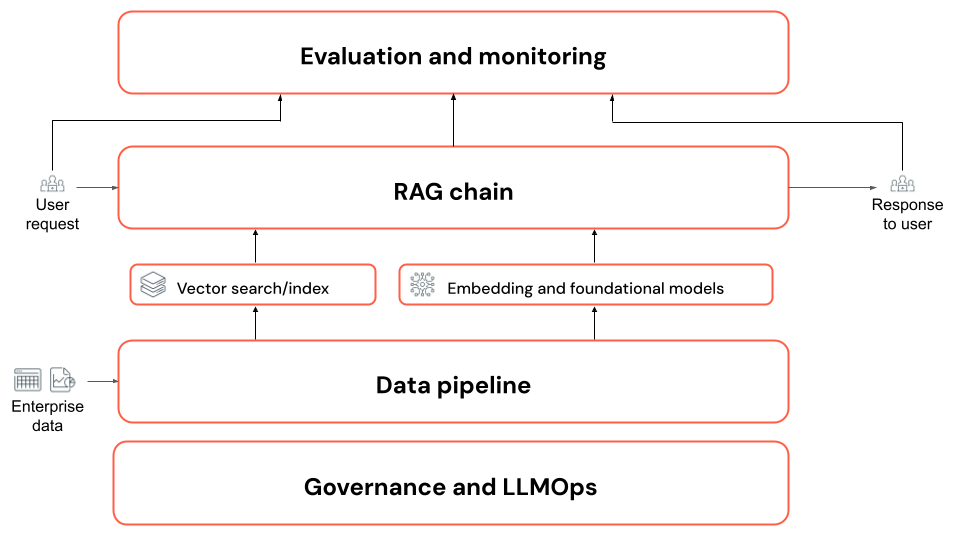
I synnerhet:
- Datapipeline: Omvandla ostrukturerade dokument, till exempel samlingar av PDF-filer, till ett format som lämpar sig för hämtning med hjälp av RAG-programmets datapipeline.
-
Hämtning, förstärkning och generation (RAG-kedja): En serie (eller kedja) med steg benämns för att:
- Förstå användarens fråga.
- Hämta stöddata.
- Anropa en LLM för att generera ett svar baserat på användarens fråga och stöddata.
- Utvärdering: Utvärdera RAG-programmet för att fastställa dess kvalitet, kostnad och svarstid för att säkerställa att det uppfyller dina affärskrav.
- Styrning och LLMOps: Spåra och hantera livscykeln för varje komponent, inklusive data härkomst och styrning (åtkomstkontroller).
Typer av RAG
RAG-arkitekturen kan fungera med två typer av stöddata:
| Strukturerade data | Ostrukturerade data | |
|---|---|---|
| Definition | Tabelldata ordnade i rader och kolumner med ett specifikt schema, till exempel tabeller i en databas. | Data utan en specifik struktur eller organisation, till exempel dokument som innehåller text och bilder eller multimediainnehåll, till exempel ljud eller videor. |
| Exempel på datakällor |
|
|
Valet av data för RAG beror på ditt användningsfall. Resten av självstudien fokuserar på RAG för ostrukturerade data.