Transformera data med datapipelines
Den här artikeln beskriver hur du kan använda DLT för att deklarera transformeringar på datauppsättningar och ange hur poster bearbetas via frågelogik. Den innehåller också exempel på vanliga transformeringsmönster för att skapa DLT-pipelines.
Du kan definiera en datauppsättning mot alla frågor som returnerar en DataFrame. Du kan använda inbyggda Apache Spark-åtgärder, UDF:er, anpassad logik och MLflow-modeller som transformeringar i DLT-pipelinen. När data har matats in i din DLT-pipeline kan du definiera nya datauppsättningar mot överordnade källor för att skapa nya strömmande tabeller, materialiserade vyer och vyer.
För att lära dig hur du effektivt utför tillståndsbaserad bearbetning med DLT, se Optimera tillståndsbaserad bearbetning i DLT med vattenstämplar.
När du ska använda vyer, materialiserade vyer och strömmande tabeller
När du implementerar dina pipelinefrågor väljer du den bästa datamängdstypen för att säkerställa att de är effektiva och underhållsbara.
Överväg att använda en vy för att göra följande:
- Dela upp en stor eller komplex fråga i enklare, hanterbara frågor.
- Verifiera mellanliggande resultat med hjälp av förväntningar.
- Minska lagrings- och beräkningskostnaderna för resultat som du inte behöver spara. Eftersom tabeller materialiseras behöver de ytterligare beräknings- och lagringsresurser.
Överväg att använda en materialiserad vy när:
- Flera nedströmsförfrågningar använder tabellen. Eftersom vyer beräknas på begäran beräknas vyn varje gång vyn efterfrågas.
- Andra pipelines, jobb eller frågor konsumerar databastabellen. Eftersom vyer inte materialiseras kan du bara använda dem inom samma pipeline.
- Du vill visa resultatet av en fråga under utvecklingen. Eftersom tabeller materialiseras och kan visas och efterfrågas utanför pipelinen kan du använda tabeller under utvecklingen för att verifiera att beräkningarna är korrekta. När du har verifierat konverterar du frågor som inte kräver materialisering till vyer.
Överväg att använda en streamingtabell när:
- En fråga definieras mot en datakälla som växer kontinuerligt eller inkrementellt.
- Frågeresultat bör beräknas stegvis.
- Pipelinen behöver högt dataflöde och låg svarstid.
Anteckning
Strömmande tabeller definieras alltid utifrån strömmande källor. Du kan också använda strömmande källor med APPLY CHANGES INTO för att tillämpa uppdateringar från CDC-flöden. Se API:er för TILLÄMPA ÄNDRINGAR: Förenkla insamling av ändringsdata med DLT.
Undanta tabeller från målschemat
Om du måste beräkna mellanliggande tabeller som inte är avsedda för extern förbrukning kan du förhindra att de publiceras till ett schema med hjälp av nyckelordet TEMPORARY. Tillfälliga tabeller lagrar och bearbetar fortfarande data enligt DLT-semantik men bör inte nås utanför den aktuella pipelinen. En tillfällig tabell finns kvar under livslängden för den pipeline som skapar den. Använd följande syntax för att deklarera temporära tabeller:
SQL
CREATE TEMPORARY STREAMING TABLE temp_table
AS SELECT ... ;
Python
@dlt.table(
temporary=True)
def temp_table():
return ("...")
Kombinera strömmande tabeller och materialiserade vyer i en enda pipeline
Strömmande tabeller ärver bearbetningsgarantierna för Apache Spark Structured Streaming och är konfigurerade för att bearbeta frågor från tilläggsdatakällor, där nya rader alltid infogas i källtabellen i stället för att ändras.
Not
Även om strömmande tabeller som standard kräver tilläggsdatakällor, kan du åsidosätta det här beteendet med flaggan hoppa överChangeCommits-flaggannär en strömmande källa är en annan strömmande tabell som kräver uppdateringar eller borttagningar.
Ett vanligt strömningsmönster omfattar inmatning av källdata för att skapa de första datauppsättningarna i en pipeline. Dessa inledande datauppsättningar kallas ofta bronstabeller och utför ofta enkla transformeringar.
De sista tabellerna i en pipeline, som ofta kallas guldtabeller, kräver däremot ofta komplicerade aggregeringar eller läsning från mål för en APPLY CHANGES INTO åtgärd. Eftersom dessa åtgärder skapar uppdateringar i stället för tillägg stöds de inte som indata till strömmande tabeller. Dessa transformationer passar bättre för materialiserade vyer.
Genom att blanda strömmande tabeller och materialiserade vyer i en enda pipeline kan du förenkla din pipeline, undvika kostsam återinmatning eller ombearbetning av rådata och ha den fulla kraften i SQL för att beräkna komplexa aggregeringar över en effektivt kodad och filtrerad datauppsättning. I följande exempel visas den här typen av blandad bearbetning:
Not
I de här exemplen används automatisk inläsning för att läsa in filer från molnlagring. Om du vill läsa in filer med Auto Loader i en pipeline som är aktiverad i Unity Catalog måste du använda externa platser. Mer information om hur du använder Unity Catalog med DLT finns i Använda Unity Catalog med dina DLT-pipelines.
Python
@dlt.table
def streaming_bronze():
return (
# Since this is a streaming source, this table is incremental.
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("abfss://path/to/raw/data")
)
@dlt.table
def streaming_silver():
# Since we read the bronze table as a stream, this silver table is also
# updated incrementally.
return spark.readStream.table("streaming_bronze").where(...)
@dlt.table
def live_gold():
# This table will be recomputed completely by reading the whole silver table
# when it is updated.
return spark.readStream.table("streaming_silver").groupBy("user_id").count()
SQL
CREATE OR REFRESH STREAMING TABLE streaming_bronze
AS SELECT * FROM read_files(
"abfss://path/to/raw/data", "json"
)
CREATE OR REFRESH STREAMING TABLE streaming_silver
AS SELECT * FROM STREAM(streaming_bronze) WHERE...
CREATE OR REFRESH MATERIALIZED VIEW live_gold
AS SELECT count(*) FROM streaming_silver GROUP BY user_id
Läs mer om hur du använder Auto Loader för successiv inläsning av JSON-filer från Azure Storage.
Stream-statiska kopplingar
Stream-static-kopplingar är ett bra val när du avnormaliserar en kontinuerlig ström av tilläggsdata med en primärt statisk dimensionstabell.
För varje pipelineuppdatering sammanfogas nya poster från strömmen med den senaste ögonblicksbilden av den statiska tabellen. Om poster läggs till eller uppdateras i den statiska tabellen efter att den motsvarande datan från strömningstabellen har bearbetats beräknas inte de resulterande uppgifterna om såvida inte en hel uppdatering utförs.
I pipelines som har konfigurerats för triggad körning returnerar den statiska tabellen resultat vid den tidpunkt då uppdateringen började. I pipelines som konfigurerats för kontinuerlig körning efterfrågas den senaste versionen av den statiska tabellen varje gång tabellen bearbetar en uppdatering.
Följande är ett exempel på en ström-statisk koppling:
Python
@dlt.table
def customer_sales():
return spark.readStream.table("sales").join(spark.readStream.table("customers"), ["customer_id"], "left")
SQL
CREATE OR REFRESH STREAMING TABLE customer_sales
AS SELECT * FROM STREAM(sales)
INNER JOIN LEFT customers USING (customer_id)
Beräkna aggregeringar effektivt
Du kan använda strömmande tabeller för att stegvis beräkna enkla fördelningsaggregeringar som antal, min, max eller summa och algebraiska aggregeringar som medelvärde eller standardavvikelse. Databricks rekommenderar inkrementell aggregering för frågor med ett begränsat antal grupper, till exempel en fråga med en GROUP BY country-sats. Endast nya indata läses med varje uppdatering.
Mer information om hur du skriver DLT-frågor som utför inkrementella aggregeringar finns i Utföra fönsterbaserade aggregeringar med vattenstämplar.
Använda MLflow-modeller i en DLT-pipeline
Anteckning
Om du vill använda MLflow-modeller i en Unity Catalog-aktiverad pipeline måste din pipeline konfigureras för att använda den preview kanalen. Om du vill använda current-kanalen måste du konfigurera din pipeline för att publicera till Hive-metaarkivet.
Du kan använda modeller tränade med MLflow i DLT-pipelines. MLflow-modeller behandlas som transformeringar i Azure Databricks, vilket innebär att de agerar på en Spark DataFrame-indata och returnerar resultat som en Spark DataFrame. Eftersom DLT definierar datauppsättningar mot DataFrames kan du konvertera Apache Spark-arbetsbelastningar som använder MLflow till DLT med bara några rader kod. Mer information om MLflow finns i MLflow för generativa AI-agenter och ML-modellers livscykel.
Om du redan har en Python-notebook-fil som anropar en MLflow-modell kan du anpassa koden till DLT med hjälp av @dlt.table dekoratör och se till att funktioner definieras för att returnera transformeringsresultat. DLT installerar inte MLflow som standard, så bekräfta att du har installerat MLFlow-biblioteken med %pip install mlflow och har importerat mlflow och dlt överst i anteckningsboken. En introduktion till DLT-syntax finns i Utveckla pipelinekod med Python.
Utför följande steg för att använda MLflow-modeller i DLT:
- Hämta körnings-ID:t och modellnamnet för MLflow-modellen. Körnings-ID och modellnamn används för att konstruera URI:n för MLflow-modellen.
- Använd URI:n för att definiera en Spark UDF för att läsa in MLflow-modellen.
- Anropa UDF i dina tabelldefinitioner för att använda MLflow-modellen.
I följande exempel visas den grundläggande syntaxen för det här mönstret:
%pip install mlflow
import dlt
import mlflow
run_id= "<mlflow-run-id>"
model_name = "<the-model-name-in-run>"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
@dlt.table
def model_predictions():
return spark.read.table(<input-data>)
.withColumn("prediction", loaded_model_udf(<model-features>))
Som ett fullständigt exempel definierar följande kod en Spark UDF med namnet loaded_model_udf som läser in en MLflow-modell som tränats på låneriskdata. De datakolumner som används för att göra förutsägelsen skickas som ett argument till UDF. Tabellen loan_risk_predictions beräknar förutsägelser för varje rad i loan_risk_input_data.
%pip install mlflow
import dlt
import mlflow
from pyspark.sql.functions import struct
run_id = "mlflow_run_id"
model_name = "the_model_name_in_run"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
categoricals = ["term", "home_ownership", "purpose",
"addr_state","verification_status","application_type"]
numerics = ["loan_amnt", "emp_length", "annual_inc", "dti", "delinq_2yrs",
"revol_util", "total_acc", "credit_length_in_years"]
features = categoricals + numerics
@dlt.table(
comment="GBT ML predictions of loan risk",
table_properties={
"quality": "gold"
}
)
def loan_risk_predictions():
return spark.read.table("loan_risk_input_data")
.withColumn('predictions', loaded_model_udf(struct(features)))
Behålla manuella borttagningar eller uppdateringar
Med DLT kan du manuellt ta bort eller uppdatera poster från en tabell och utföra en uppdateringsåtgärd för att omkomplera underordnade tabeller.
Som standard beräknar DLT tabellresultat baserat på indata varje gång en pipeline uppdateras, så du måste se till att den borttagna posten inte laddas om från källdata. Om du anger egenskapen pipelines.reset.allowed tabell till false förhindras uppdateringar av en tabell, men förhindrar inte att inkrementella skrivningar till tabellerna eller nya data flödar till tabellen.
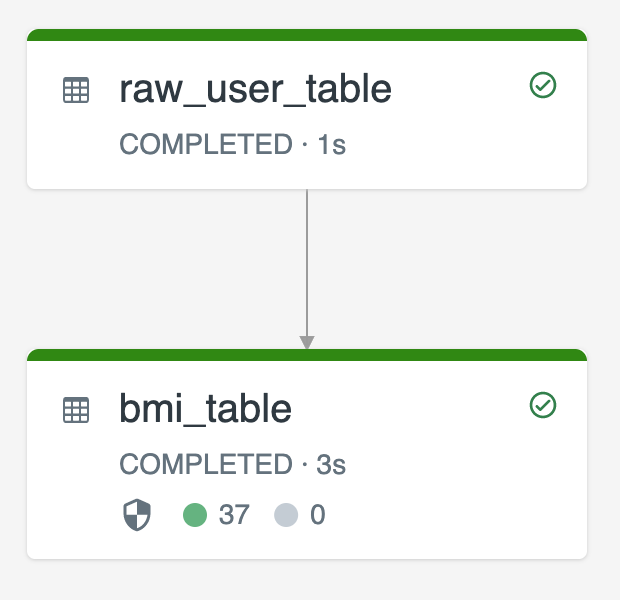
Följande diagram illustrerar ett exempel med två strömmande tabeller:
-
raw_user_tablematar in rå användardata från en källa. -
bmi_tableberäknar inkrementellt BMI-poäng med hjälp av vikt och höjd frånraw_user_table.
Du vill manuellt ta bort eller uppdatera användarposter från raw_user_table och beräkna om bmi_tablepå nytt.
Följande kod visar hur du anger egenskapen pipelines.reset.allowed tabell till false för att inaktivera fullständig uppdatering för raw_user_table så att avsedda ändringar behålls över tid, men underordnade tabeller omberäknas när en pipelineuppdatering körs:
CREATE OR REFRESH STREAMING TABLE raw_user_table
TBLPROPERTIES(pipelines.reset.allowed = false)
AS SELECT * FROM read_files("/databricks-datasets/iot-stream/data-user", "csv");
CREATE OR REFRESH STREAMING TABLE bmi_table
AS SELECT userid, (weight/2.2) / pow(height*0.0254,2) AS bmi FROM STREAM(raw_user_table);