Konfigurera ditt Databricks-projekt med hjälp av Databricks-tillägget för Visual Studio Code
Databricks-tillägget för Visual Studio Code erbjuder en konfigurationsvy i tilläggspanelen som gör att du enkelt kan konfigurera och uppdatera inställningarna för ditt Databricks-projekt. Dessa funktioner omfattar en distributionsväljare för målarbetsytan, enkel konfiguration av autentisering och beräkning, synkronisering av arbetsytor och enkla steg för att aktivera den virtuella Python-miljö som krävs för felsökning.
Konfigurationsvyn i Databricks-tillägget för Visual Studio Code är tillgänglig när du har skapat eller migrerat ett projekt till ett Databricks-projekt. Se Skapa ett nytt Databricks-projekt.
Kommentar
Tidigare versioner av Databricks-tillägget för Visual Studio Code definierade konfigurationsinställningar i en JSON-projektfil och miljövariabler angavs i terminalen. I versionsversionen finns projekt- och miljökonfigurationen databricks.yml i filerna och databricks.env .
Om projektet är ett Databricks-tillgångspaket tillhandahåller databricks-utsträckningsgränssnittet även en paketresursutforskare och en paketvariabelvy för att hantera dina paketresurser och variabler. Se Tilläggsfunktionerna för Databricks Asset Bundles.
Ändra arbetsytan för måldistribution
Om du vill välja eller byta distributionsmål för ditt Databricks-projekt (till exempel för att växla från ett dev mål till ett prod mål):
I konfigurationsvyn på panelen för Databricks-tillägget klickar du på kugghjulsikonen (Välj ett Databricks Asset Bundle-mål) som är associerat med Target.
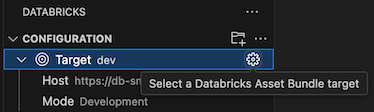
I kommandopaletten väljer du önskat distributionsmål.
När ett mål har konfigurerats visas värd- och distributionsläget. Information om distributionslägen för Databricks Asset Bundles finns i Distributionslägen för Databricks Asset Bundle.
Arbetsytevärden kan ändras genom att ändra målinställningen workspace i konfigurationsfilen databricks.yml som är associerad med projektet. Se mål.
Kommentar
Följande Databricks-tillägg för Visual Studio Code-funktioner är endast tillgängliga när måldistributionsläget är utveckling:
- Använda det anslutna utvecklingsklustret för paketjobb
- Synkronisera mappfiler för arbetsytor
- Välj ett interaktivt utvecklingskluster
Konfigurera Databricks-profilen för projektet
När du skapar ett Databricks-projekt eller konverterar ett projekt till ett Databricks-projekt konfigurerar du en profil som inkluderar autentiseringsinställningar som används för att ansluta till Databricks. Om du vill ändra den autentiseringsprofil som används klickar du på kugghjulsikonen som är associerad med AuthType i konfigurationsvyn.
Mer information om Databricks-tillägget för Visual Studio Code-autentisering finns i Konfigurera auktorisering för Databricks-tillägget för Visual Studio Code.
Välj ett kluster för att köra kod och jobb
Med databricks-tillägget för Visual Studio Code kan du välja ett befintligt Azure Databricks-kluster eller skapa ett nytt Azure Databricks-kluster för att köra kod och jobb. När du har anslutit till beräkning visas klustrets ID, Databricks Runtime-version, skapare, tillstånd och åtkomstläge. Du kan också starta och stoppa klustret och navigera direkt till klustrets sidinformation.
Dricks
Om du inte vill vänta tills jobbklustret startar kontrollerar du Åsidosätt jobbklustret i paketet precis under klustervalet för att använda det valda klustret för att köra paketjobb i utvecklingsläge.
Använda ett befintligt kluster
Om du har ett befintligt Azure Databricks-kluster som du vill använda:
Klicka på Välj ett kluster eller kugghjulsikonen (Konfigurera kluster) bredvid Kluster i konfigurationsvyn.
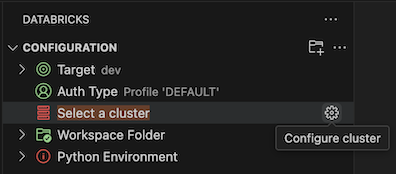
I kommandopaletten väljer du det kluster som du vill använda.
Skapa ett nytt kluster
Om du inte har ett befintligt Azure Databricks-kluster eller om du vill skapa ett nytt:
I konfigurationsvyn bredvid Kluster klickar du på kugghjulsikonen (Konfigurera kluster).
I kommandopaletten klickar du på Skapa nytt kluster.
När du uppmanas att öppna den externa webbplatsen (din Azure Databricks-arbetsyta) klickar du på Öppna.
Logga in på din Azure Databricks-arbetsyta om du uppmanas att göra det.
Följ anvisningarna för att skapa ett kluster.
Kommentar
Databricks rekommenderar att du skapar ett personligt beräkningskluster . På så sätt kan du börja köra arbetsbelastningar omedelbart, vilket minimerar kostnaderna för beräkningshantering.
När klustret har skapats och körs går du tillbaka till Visual Studio Code.
I konfigurationsvyn bredvid Kluster klickar du på kugghjulsikonen (Konfigurera kluster).
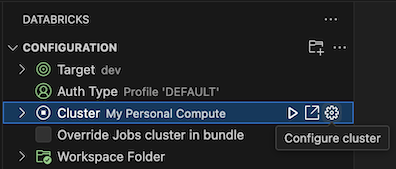
I kommandopaletten klickar du på det kluster som du vill använda.
Synkronisera din arbetsytemapp med Databricks
Du kan synkronisera den fjärranslutna Databricks-arbetsytemappen som är associerad med ditt Databricks-projekt genom att klicka på synkroniseringsikonen (Starta synkronisering) som är associerad med Fjärrmapp i Konfiguration vy i Databricks-tilläggspanelen.
Kommentar
Databricks-tillägget för Visual Studio Code fungerar endast med arbetsytekataloger som skapas. Du kan inte använda en befintlig arbetsytekatalog i projektet om den inte har skapats av tillägget.
Om du vill navigera till arbetsytevyn i Databricks klickar du på ikonen för extern länk (Öppna länk externt) som är associerad med Fjärrmapp.
Tillägget avgör vilken Azure Databricks-arbetsytemapp som ska användas baserat på file_path inställningen i mappningen workspace av projektets associerade Databricks Asset Bundle-konfiguration. Se arbetsytan.
Kommentar
Databricks-tillägget för Visual Studio Code utför endast enkelriktad, automatisk synkronisering av filändringar från ditt lokala Visual Studio Code-projekt till den relaterade arbetsytemappen i din fjärranslutna Azure Databricks-arbetsyta. Filerna i den här fjärrarbetsytans katalog är avsedda att vara tillfälliga. Initiera inte ändringar i dessa filer från din fjärrarbetsyta eftersom dessa ändringar inte synkroniseras tillbaka till ditt lokala projekt.
Användningsinformation om funktionen för katalogsynkronisering för arbetsytor för tidigare versioner av Databricks-tillägget för Visual Studio Code finns i Välj en arbetsytekatalog för Databricks-tillägget för Visual Studio Code.
Konfigurera Din Python-miljö och Databricks Connect
I avsnittet Python-miljö i konfigurationsvyn kan du enkelt konfigurera din virtuella Python-utvecklingsmiljö och installera Databricks Connect för att köra och felsöka kod och notebook-celler. Virtuella Python-miljöer ser till att projektet använder kompatibla versioner av Python- och Python-paket (i det här fallet Databricks Connect-paketet).
Om du vill konfigurera den virtuella Python-miljön för projektet går du till konfigurationsvyn på tilläggspanelen:
- Klicka på det röda objektet Aktivera virtuell miljö under Python-miljö.
- I kommandopaletten väljer du Venv eller Conda.
- Välj eventuella beroenden som du vill installera.
Om du vill ändra miljöer klickar du på kugghjulsikonen (Ändra virtuell miljö) som är associerad med Aktiv miljö.
Information om hur du installerar Databricks Connect, som gör det möjligt att köra och felsöka kod och notebook-filer i Visual Studio Code, finns i Felsöka kod med Databricks Connect för Databricks-tillägget för Visual Studio Code.