Konfigurera Delta Lake för att styra datafilstorleken
Kommentar
Rekommendationerna i den här artikeln gäller inte för hanterade unity-katalogtabeller. Databricks rekommenderar att du använder hanterade Unity Catalog-tabeller med standardinställningar för alla nya Delta-tabeller.
I Databricks Runtime 13.3 och senare rekommenderar Databricks att du använder klustring för Delta-tabelllayout. Se Använda flytande klustring för Delta-tabeller.
Databricks rekommenderar att du använder förutsägelseoptimering för att automatiskt köra OPTIMIZE och VACUUM för Delta-tabeller. Se Förutsägande optimering för hanterade Unity Catalog-tabeller.
I Databricks Runtime 10.4 LTS och senare aktiveras alltid automatisk komprimering och optimerade skrivningar för MERGE, UPDATEoch DELETE åtgärder. Du kan inte inaktivera den här funktionen.
Delta Lake innehåller alternativ för att manuellt eller automatiskt konfigurera målfilstorleken för skrivningar och åtgärder OPTIMIZE . Azure Databricks justerar automatiskt många av de här inställningarna och aktiverar funktioner som automatiskt förbättrar tabellprestanda genom att försöka ändra storlek på filer.
För hanterade tabeller i Unity Catalog justerar Databricks de flesta av dessa konfigurationer automatiskt om du använder ett SQL-lager eller Databricks Runtime 11.3 LTS eller senare.
Om du uppgraderar en arbetsbelastning från Databricks Runtime 10.4 LTS eller lägre, se Uppgradera till automatisk bakgrundskomprimering.
När du ska köra OPTIMIZE
Automatisk komprimering och optimerade skrivningar minskar problemen med små filer, men ersätter inte OPTIMIZE. Särskilt för tabeller som är större än 1 TB rekommenderar Databricks att du kör OPTIMIZE enligt ett schema för att ytterligare konsolidera filer. Azure Databricks kör inte ZORDER automatiskt på tabeller, så du måste köra OPTIMIZE med ZORDER för att aktivera utökad datautelämning. Se Hoppa över data för Delta Lake.
Vad är automatisk optimering på Azure Databricks?
Termen automatisk optimering används ibland för att beskriva funktioner som styrs av inställningarna delta.autoOptimize.autoCompact och delta.autoOptimize.optimizeWrite. Den här termen har dragits tillbaka för att beskriva varje inställning individuellt. Se Automatisk komprimering för Delta Lake på Azure Databricks och Optimerade skrivningar för Delta Lake på Azure Databricks.
Automatisk komprimering för Delta Lake i Azure Databricks
Automatisk komprimering kombinerar små filer i Delta-tabellpartitioner för att automatiskt minska små filproblem. Automatisk komprimering sker efter att en skrivning till en tabell har slutförts och körs synkront på klustret som har utfört skrivning. Automatisk komprimering komprimerar endast filer som inte har komprimerats tidigare.
Du kan styra utdatafilens storlek genom att ange Spark-konfigurationenspark.databricks.delta.autoCompact.maxFileSize. Databricks rekommenderar att du använder automatisk tunning baserat på arbetsbelastning eller tabellstorlek. Se Autotune-filstorlek baserat på arbetsbelastning och Autotune-filstorlek baserat på tabellstorlek.
Automatisk komprimering utlöses endast för partitioner eller tabeller som har minst ett visst antal små filer. Du kan också ändra det minsta antalet filer som krävs för att utlösa automatisk komprimering genom att ange spark.databricks.delta.autoCompact.minNumFiles.
Automatisk komprimering kan aktiveras på tabell- eller sessionsnivå med hjälp av följande inställningar:
- Tabellens egenskap:
delta.autoOptimize.autoCompact - Inställning för SparkSession:
spark.databricks.delta.autoCompact.enabled
De här inställningarna accepterar följande alternativ:
| Alternativ | Funktionssätt |
|---|---|
auto (rekommenderas) |
Justerar målfilstorlek samtidigt som man beaktar andra autotuning-funktioner. Kräver Databricks Runtime 10.4 LTS eller senare. |
legacy |
Alias för true. Kräver Databricks Runtime 10.4 LTS eller senare. |
true |
Använd 128 MB som målfilstorlek. Ingen dynamisk storleksändring. |
false |
Inaktiverar automatisk komprimering. Kan ställas in på sessionsnivå för att åsidosätta automatisk komprimering för alla Delta-tabeller som ändrats i arbetsbelastningen. |
Viktigt!
I Databricks Runtime 9.1 LTS, när andra skrivare utför åtgärder som DELETE, MERGE, UPDATE eller OPTIMIZE samtidigt, kan automatisk komprimering leda till att de andra jobben misslyckas med en transaktionskonflikt. Det här är inte ett problem i Databricks Runtime 10.4 LTS och senare.
Optimerade skrivningar för Delta Lake i Azure Databricks
Optimerade skrivningar förbättrar filstorleken när data skrivs, vilket gynnar efterföljande läsningar i tabellen.
Optimerade skrivningar är mest effektiva för partitionerade tabeller, eftersom de minskar antalet små filer som skrivs till varje partition. Att skriva färre stora filer är effektivare än att skriva många små filer, men du kan fortfarande se en ökning av skrivfördröjningen eftersom data blandas innan de skrivs.
Följande bild visar hur optimerade skrivningar fungerar:
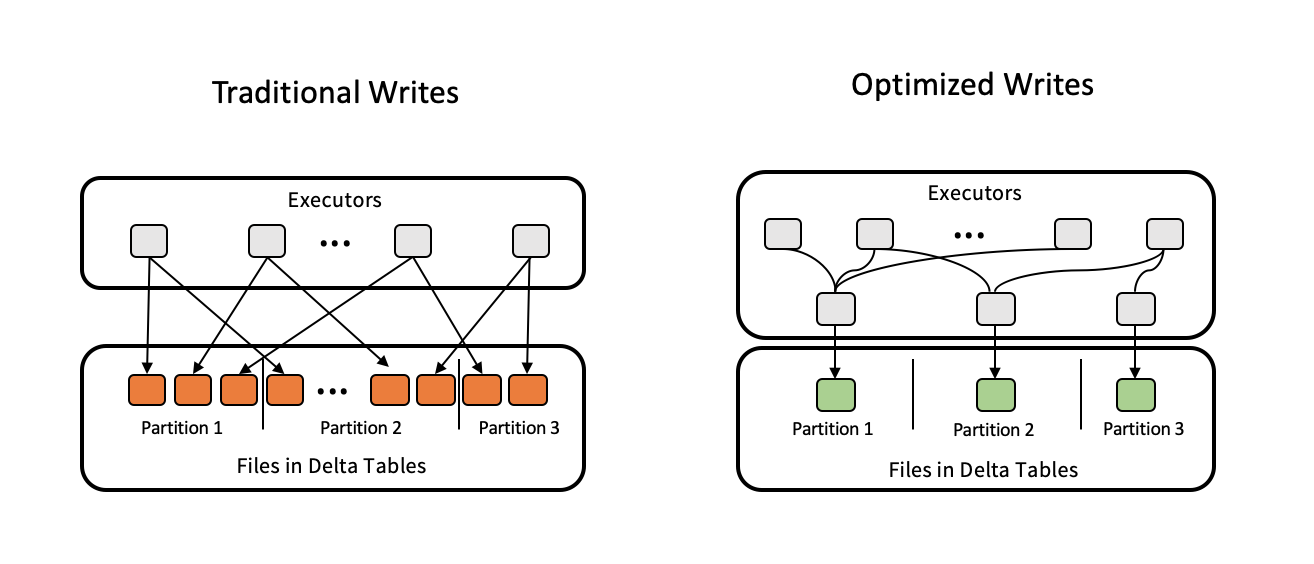
Kommentar
Du kan ha kod som körs coalesce(n) eller repartition(n) precis innan du skriver ut dina data för att kontrollera antalet filer som skrivs. Optimerade skrivningar eliminerar behovet av att använda det här mönstret.
Optimerade skrivningar är aktiverade som standard för följande åtgärder i Databricks Runtime 9.1 LTS och senare:
MERGE-
UPDATEmed underfrågor -
DELETEmed underfrågor
Optimerade skrivningar är också aktiverade för CTAS instruktioner och INSERT åtgärder vid användning av SQL-databaser. I Databricks Runtime 13.3 LTS och senare har alla Delta-tabeller som är registrerade i Unity Catalog optimerade skrivningar aktiverade för CTAS instruktioner och INSERT åtgärder för partitionerade tabeller.
Optimerade skrivningar kan aktiveras på tabell- eller sessionsnivå med hjälp av följande inställningar:
- Tabellinställning:
delta.autoOptimize.optimizeWrite - Inställning för SparkSession:
spark.databricks.delta.optimizeWrite.enabled
De här inställningarna accepterar följande alternativ:
| Alternativ | Funktionssätt |
|---|---|
true |
Använd 128 MB som målfilstorlek. |
false |
Inaktiverar optimerade skrivningar. Kan ställas in på sessionsnivå för att åsidosätta automatisk komprimering för alla Delta-tabeller som ändrats i arbetsbelastningen. |
Ange en målfilstorlek
Om du vill justera storleken på filerna i deltatabellen anger du tabellegenskapen delta.targetFileSize till önskad storlek. Om den här egenskapen har angetts kommer alla optimeringsåtgärder för datalayout att göra ett bästa försök att generera filer av den angivna storleken. Exempel här inkluderar optimering eller Z-ordning, automatisk komprimering, och optimerade skrivningar.
Kommentar
När du använder hanterade tabeller i Unity Catalog och SQL-datalager eller Databricks Runtime 11.3 LTS och senare, är det endast kommandon OPTIMIZE som respekterar inställningen targetFileSize.
| Tabelleegenskap |
|---|
|
delta.targetFileSize Typ: Storlek i byte eller högre enheter. Målfilens storlek. Till exempel 104857600 (byte) eller 100mb.Standardvärde: Ingen |
För befintliga tabeller kan du ange och ta bort egenskaper med hjälp av SQL-kommandot ALTER TABLESET TBL PROPERTIES. Du kan också ange dessa egenskaper automatiskt när du skapar nya tabeller med spark-sessionskonfigurationer. Se referens för deltatabellegenskaper för detaljer.
Autotune-filstorlek baserat på arbetsbelastning
Databricks rekommenderar att du ställer in tabellegenskapen delta.tuneFileSizesForRewrites på true för alla tabeller som är mål för många MERGE eller DML-åtgärder, oavsett Databricks Runtime, Unity Catalog eller andra optimeringar.
trueNär värdet är inställt på anges målfilstorleken för tabellen till ett mycket lägre tröskelvärde, vilket påskyndar skrivintensiva åtgärder.
Om inte uttryckligen anges identifierar Azure Databricks automatiskt om 9 av de senaste 10 tidigare åtgärderna i en Delta-tabell var MERGE åtgärder och anger den här tabellegenskapen till true. Du måste uttryckligen ange den här egenskapen till false för att undvika detta beteende.
| Egenskap för tabell |
|---|
|
delta.tuneFileSizesForRewrites Typ: BooleanOm filstorlekar ska justeras för optimering av datalayout. Standardvärde: Ingen |
För befintliga tabeller kan du ange och ta bort egenskaper med hjälp av SQL-kommandot ALTER TABLESET TBL PROPERTIES. Du kan också ange dessa egenskaper automatiskt när du skapar nya tabeller med spark-sessionskonfigurationer. Se referens för deltatabellegenskaper för detaljer.
Autotune-filstorlek baserat på tabellstorlek
För att minimera behovet av manuell justering justerar Azure Databricks automatiskt filstorleken för Delta-tabeller baserat på tabellens storlek. Azure Databricks använder mindre filstorlekar för mindre tabeller och större filstorlekar för större tabeller så att antalet filer i tabellen inte blir för stort. Azure Databricks skriver inte automatiskt tabeller som du har justerat med en specifik målstorlek eller baserat på en arbetsbelastning med frekventa omskrivningar.
Målfilens storlek baseras på den aktuella storleken på Delta-tabellen. För tabeller som är mindre än 2,56 TB är den automatiska målfilens storlek 256 MB. För tabeller med en storlek mellan 2,56 TB och 10 TB ökar målstorleken linjärt från 256 MB till 1 GB. För tabeller som är större än 10 TB är målfilens storlek 1 GB.
Kommentar
När målfilens storlek för en tabell växer optimeras inte befintliga filer på nytt till större filer med OPTIMIZE kommandot . En stor tabell kan därför alltid ha vissa filer som är mindre än målstorleken. Om det krävs för att optimera de mindre filerna även i större filer kan du konfigurera en fast målfilstorlek för tabellen med hjälp av tabellegenskapen delta.targetFileSize .
När en tabell skrivs inkrementellt kommer målfilstorlekarna och antalet filer att ligga nära följande tal, baserat på tabellstorleken. Antalet filer i den här tabellen är bara ett exempel. De faktiska resultaten skiljer sig beroende på många faktorer.
| Tabellstorlek | Målfilstorlek | Ungefärligt antal filer i tabellen |
|---|---|---|
| 10 GB | 256 MB | 40 |
| 1 TB | 256 MB | 4096 |
| 2,56 TB | 256 MB | 10240 |
| 3 TB | 307 MB | 12108 |
| 5 TB | 512 MB | 17339 |
| 7 TB | 716 MB | 20784 |
| 10 TB | 1 GB | 24437 |
| 20 TB | 1 GB | 34437 |
| 50 TB | 1 GB | 64437 |
| 100 TB | 1 GB | 114437 |
Begränsa rader som skrivs i en datafil
Ibland kan tabeller med smala data stöta på ett fel där antalet rader i en viss datafil överskrider stödgränserna för Parquet-formatet. För att undvika det här felet kan du använda SQL-sessionskonfigurationen spark.sql.files.maxRecordsPerFile för att ange det maximala antalet poster som ska skrivas till en enda fil för en Delta Lake-tabell. Att ange ett värde på noll eller ett negativt värde representerar ingen gräns.
I Databricks Runtime 11.3 LTS och senare kan du också använda alternativet maxRecordsPerFile DataFrameWriter när du använder DataFrame-API:erna för att skriva till en Delta Lake-tabell. När maxRecordsPerFile anges ignoreras värdet för SQL-sessionskonfigurationen spark.sql.files.maxRecordsPerFile .
Kommentar
Databricks rekommenderar inte att du använder det här alternativet om det inte är nödvändigt att undvika ovan nämnda fel. Den här inställningen kan fortfarande vara nödvändig för vissa hanterade Unity Catalog-tabeller med mycket smala data.
Uppgradera till automatisk komprimering i bakgrunden
Automatisk komprimering i bakgrunden är tillgängligt för hanterade Unity Catalog-tabeller i Databricks Runtime 11.3 LTS och senare. När du migrerar en äldre arbetsbelastning eller tabell gör du följande:
- Ta bort Spark-konfigurationen
spark.databricks.delta.autoCompact.enabledfrån klustrets eller anteckningsbökernas konfigurationsinställningar. - För varje tabell kör du
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)för att ta bort eventuella äldre inställningar för automatisk komprimering.
När du har tagit bort dessa äldre konfigurationer bör du se automatisk komprimering i bakgrunden som utlöses automatiskt för alla hanterade Unity Catalog-tabeller.