Vad är DLT?
Anteckning
DLT kräver Premium-plan. Kontakta databricks-kontoteamet om du vill ha mer information.
DLT är ett deklarativt ramverk som är utformat för att förenkla skapandet av tillförlitliga och underhållsbara pipelines för extrahering, transformering och belastning (ETL). Du anger vilka data som ska matas in och hur du transformerar dem, och DLT automatiserar viktiga aspekter av hanteringen av din datapipeline, inklusive orkestrering, beräkningshantering, övervakning, tillämpning av datakvalitet och felhantering.
DLT bygger på Apache Spark, men i stället för att definiera dina datapipelines med hjälp av en serie separata Apache Spark-uppgifter definierar du strömmande tabeller och materialiserade vyer som systemet ska skapa och de frågor som krävs för att fylla i och uppdatera dessa strömmande tabeller och materialiserade vyer.
Mer information om fördelarna med att skapa och köra ETL-pipelines med DLT finns på produktsidan DLT.
fördelar med DLT jämfört med Apache Spark
Apache Spark är en mångsidig enhetlig analysmotor med öppen källkod, inklusive ETL. DLT bygger på Spark för att hantera specifika och vanliga ETL-bearbetningsuppgifter. DLT kan avsevärt påskynda din väg till produktion när dina krav omfattar dessa bearbetningsuppgifter, inklusive:
- Mata in data från vanliga källor.
- Transformera data stegvis.
- Utföra ändringsdatainsamling (CDC).
DLT är dock olämpligt för att implementera vissa typer av procedurlogik. Till exempel kan bearbetningskrav som att skriva till en extern tabell eller inkludera ett villkor som fungerar på extern fillagring eller databastabeller inte utföras i koden som definierar en DLT-datauppsättning. För att implementera bearbetning som inte stöds av DLT rekommenderar Databricks att du använder Apache Spark eller inkluderar pipelinen i ett Databricks-jobb som utför bearbetningen i en separat jobbuppgift. Se DLT-pipelinesuppgift för jobb.
I följande tabell jämförs DLT med Apache Spark:
| Förmåga | DLT | Apache Spark |
|---|---|---|
| Datatransformeringar | Du kan transformera data med hjälp av SQL eller Python. | Du kan transformera data med hjälp av SQL, Python, Scala eller R. |
| Inkrementell databehandling | Många datatransformeringar bearbetas automatiskt inkrementellt. | Du måste bestämma vilka data som är nya så att du kan bearbeta dem stegvis. |
| Orkestrering | Transformeringar dirigeras automatiskt i rätt ordning. | Du måste se till att olika transformeringar körs i rätt ordning. |
| Parallellitet | Alla transformeringar körs med rätt parallellitetsnivå. | Du måste använda trådar eller en extern orkestrerare för att köra orelaterade transformeringar parallellt. |
| Felhantering | Misslyckanden försöks automatiskt igen. | Du måste bestämma hur du ska hantera fel och återförsök. |
| Övervakning | Mått och händelser loggas automatiskt. | Du måste skriva kod för att samla in mått om körning eller datakvalitet. |
viktiga begrepp för DLT
Följande bild visar viktiga komponenter i en DLT-pipeline följt av en förklaring av var och en.
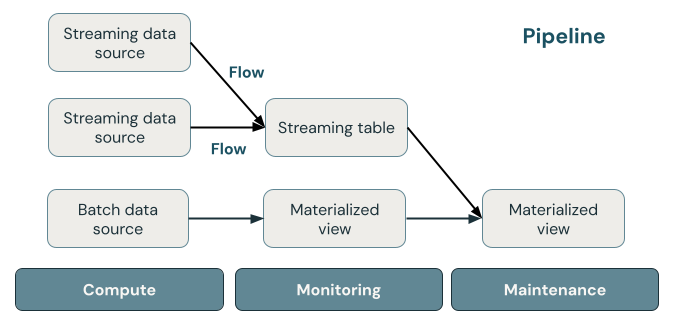
direktuppspelningstabell
En strömmande tabell är en Delta-tabell som har en eller flera strömmar som skrivs till den. Strömmande tabeller används ofta för inmatning eftersom de bearbetar indata exakt en gång och kan bearbeta stora mängder tilläggsdata. Direktuppspelningstabeller är också användbara för omvandling med låg latens av dataströmmar med hög volym.
Materialiserad vy
En materialiserad vy är en vy som innehåller förberäknade poster som är baserade på den fråga som definierar den materialiserade vyn. Posterna i den materialiserade vyn hålls automatiskt uppdaterade av DLT baserat på uppdateringsschemat eller utlösarna för pipelinen. Varje gång en materialiserad vy uppdateras får den garanterat samma resultat som när du kör den definierande frågan över de senaste tillgängliga data. Detta görs dock ofta utan att omberäkna det fullständiga resultatet från grunden, med hjälp av inkrementell uppdatering. Materialiserade vyer används ofta för transformeringar.
Visningar
Alla vyer i Azure Databricks-beräkningsresultat från källdatauppsättningar när de efterfrågas, vilket utnyttjar cacheoptimeringar när de är tillgängliga. DLT publicerar inte vyer till katalogen, så vyer kan endast refereras till i pipelinen där de definieras. Vyer är användbara som mellanliggande frågor som inte ska exponeras för slutanvändare eller system. Databricks rekommenderar att du använder vyer för att framtvinga datakvalitetsbegränsningar eller transformera och utöka datauppsättningar som kör flera underordnade frågor.
Rörledning
En pipeline är en samling strömmande tabeller och materialiserade vyer som uppdateras tillsammans. Dessa strömmande tabeller och materialiserade vyer deklareras i Python- eller SQL-källfiler. En pipeline innehåller också en konfiguration som definierar den beräkning som används för att uppdatera strömmande tabeller och materialiserade vyer när pipelinen körs. På samma sätt som en Terraform-mall definierar infrastrukturen i ditt molnkonto definierar en DLT-pipeline datauppsättningar och transformeringar för databearbetningen.
Hur bearbetar DLT-datauppsättningar data?
I följande tabell beskrivs hur materialiserade vyer, strömmande tabeller och vyer bearbetar data:
| Datasettyp | Hur bearbetas poster via definierade frågor? |
|---|---|
| Direktuppspelningstabell | Varje post bearbetas exakt en gång. Detta förutsätter en källa som endast tillåter tillägg. |
| Materialiserad vy | Posterna behandlas efter behov för att ge korrekta resultat baserat på aktuellt dataläge. Materialiserade vyer bör användas för databearbetningsuppgifter som transformeringar, sammansättningar eller långsamma frågor före databehandling och ofta använda beräkningar. |
| Utsikt | Poster bearbetas varje gång vyn efterfrågas. Använd vyer för mellanliggande transformeringar och datakvalitetskontroller som inte ska publiceras till offentliga datauppsättningar. |
Deklarera dina första datauppsättningar i DLT
DLT introducerar ny syntax för Python och SQL. Mer information om grunderna i pipelinesyntax finns i Utveckla pipelinekod med Python och Utveckla pipelinekod med SQL.
Not
DLT separerar datauppsättningsdefinitioner från uppdateringsbearbetning och DLT-notebook-filer är inte avsedda för interaktiv körning.
Hur konfigurerar du DLT-pipelines?
Inställningarna för DLT-pipelines finns i två breda kategorier:
- Konfigurationer som definierar en samling anteckningsböcker eller filer (kallas källkod) som använder DLT-syntax för att deklarera datamängder.
- Konfigurationer som styr pipelineinfrastruktur, beroendehantering, hur uppdateringar bearbetas och hur tabeller sparas på arbetsytan.
De flesta konfigurationer är valfria, men vissa kräver noggrann uppmärksamhet, särskilt när du konfigurerar produktionspipelines. Dessa inkluderar följande:
- För att göra data tillgängliga utanför pipelinen måste du deklarera ett målschema att publicera till Hive-metaarkivet eller en målkatalog och målschema att publicera till Unity Catalog.
- Behörigheter för dataåtkomst konfigureras via det kluster som används för exekvering. Se till att klustret har rätt behörigheter konfigurerade för datakällor och för den angivna lagringsplatsen , om det specificerats.
Mer information om hur du använder Python och SQL för att skriva källkod för pipelines finns i DLT SQL-språkreferens och DLT Python-språkreferens.
Mer information om pipelineinställningar och konfigurationer finns i Konfigurera en DLT-pipeline.
Distribuera din första pipeline och trigga uppdateringar
Innan du bearbetar data med DLT måste du konfigurera en pipeline. När en pipeline har konfigurerats kan du utlösa en uppdatering för att beräkna resultat för varje datauppsättning i pipelinen. För att komma igång med att använda DLT-pipelines, se Handledning: Kör din första DLT-pipeline.
Vad är en pipelineuppdatering?
Pipelines distribuerar infrastruktur och beräknar om datatillstånd när du startar en uppdatering. En uppdatering gör följande:
- Startar ett kluster med rätt konfiguration.
- Identifierar alla tabeller och vyer som definierats och söker efter eventuella analysfel, till exempel ogiltiga kolumnnamn, saknade beroenden och syntaxfel.
- Skapar eller uppdaterar tabeller och vyer med de senaste tillgängliga data.
Pipelines kan köras kontinuerligt eller enligt ett schema beroende på ditt användningsfalls krav på kostnad och svarstid. Se Utför en uppdatering på en DLT-pipeline.
Importera data med DLT
DLT stöder alla datakällor som är tillgängliga i Azure Databricks.
Databricks rekommenderar att du använder strömningstabeller för de flesta inmatningsanvändningsfall. För filer som anländer till molnobjektlagring rekommenderar Databricks automatisk inläsning. Du kan mata in data direkt med DLT från de flesta meddelandebussar.
Mer information om hur du konfigurerar åtkomst till molnlagring finns i Cloud Storage-konfiguration.
För format som inte stöds av Auto Loader kan du använda Python eller SQL för att köra frågor mot alla format som stöds av Apache Spark. Se Ladda in data med DLT.
Övervaka och framtvinga datakvalitet
Du kan använda förväntningar för att ange datakvalitetskontroller för innehållet i en datauppsättning. Till skillnad från en CHECK begränsning i en traditionell databas som förhindrar att poster läggs till som inte uppfyller villkoret, ger förväntningarna flexibilitet när data bearbetas som inte uppfyller kraven på datakvalitet. Med den här flexibiliteten kan du bearbeta och lagra data som du förväntar dig är röriga och data som måste uppfylla strikta kvalitetskrav. Se Hantera datakvalitet med pipelineförväntningar.
Hur är DLT och Delta Lake relaterade?
DLT utökar funktionerna i Delta Lake. Eftersom tabeller som skapats och hanteras av DLT är Delta-tabeller har de samma garantier och funktioner som tillhandahålls av Delta Lake. Se Vad är Delta Lake?.
DLT lägger till flera tabellegenskaper utöver de många tabellegenskaper som kan anges i Delta Lake. Se referensen för DLT-egenskaper och referensen för Delta-tabellegenskaper.
Så här skapas och hanteras tabeller av DLT
Azure Databricks hanterar automatiskt tabeller som skapats med DLT, avgör hur uppdateringar måste bearbetas för att korrekt beräkna det aktuella tillståndet för en tabell och utföra ett antal underhålls- och optimeringsuppgifter.
För de flesta åtgärder bör du tillåta att DLT bearbetar alla uppdateringar, infogningar och borttagningar i en måltabell. För ytterligare information och begränsningar, se Behåll manuella borttagningar eller uppdateringar.
Underhållsaktiviteter som utförs av DLT
DLT utför underhållsaktiviteter inom 24 timmar efter att en tabell har uppdaterats. Underhåll kan förbättra frågeprestanda och minska kostnaderna genom att ta bort gamla versioner av tabeller. Som standard utför systemet en fullständig OPTIMIZE åtgärd följt av VACUUM. Du kan inaktivera OPTIMIZE för en tabell genom att ange pipelines.autoOptimize.managed = false i tabellegenskaper för tabellen. Underhållsaktiviteter utförs endast om en pipelineuppdatering har körts under de 24 timmarna innan underhållsaktiviteterna schemaläggs.
Delta Live Tables är nu DLT
Den produkt som tidigare kallades Delta Live Tables är nu DLT.
Begränsningar
En lista över begränsningar finns i DLT-begränsningar.
En lista över krav och begränsningar som är specifika för att använda DLT med Unity Catalog finns i Använda Unity Catalog med dina DLT-pipelines
Ytterligare resurser
- DLT har fullt stöd i Databricks REST API. Se DLT API.
- Information om pipeline- och tabellinställningar finns i referensen DLT-egenskaper.
- DLT SQL-språkreferens.
- DLT Python-språkreferens.