Få åtkomst till Azure Data Lake Storage med Microsoft Entra ID autentisering med referensvidarekoppling (äldre)
Viktigt!
Den här dokumentationen har dragits tillbaka och kanske inte uppdateras.
Vidarebefordran av autentiseringsuppgifter är föråldrad från och med Databricks Runtime 15.0 och kommer att tas bort i framtida Databricks Runtime-versioner. Databricks rekommenderar att du uppgraderar till Unity Catalog. Unity Catalog förenklar säkerheten och styrningen av dina data genom att tillhandahålla en central plats för att administrera och granska dataåtkomst över flera arbetsytor i ditt konto. Se Vad är Unity Catalog?.
För ökad säkerhets- och styrningsstatus kontaktar du ditt Azure Databricks-kontoteam för att inaktivera genomströmning av autentiseringsuppgifter i ditt Azure Databricks-konto.
Anteckning
Den här artikeln innehåller referenser till termen vitlistad, en term som Azure Databricks inte använder. När termen tas bort från programvaran tar vi bort den från den här artikeln.
Du kan autentisera dig automatiskt till ADLS från Azure Databricks-kluster med samma Microsoft Entra-ID-identitet som du använder för att logga in på Azure Databricks. När du aktiverar användning av Azure Data Lake Storage-autentiseringsuppgifter för klustret kan kommandon som du kör i klustret läsa och skriva data i Azure Data Lake Storage utan att du behöver konfigurera service principal-autentiseringsuppgifter för åtkomst till lagring.
Endast Azure Data Lake Storage stöder vidarebefordran av autentiseringsuppgifter. Azure Blob Storage stöder inte vidarebefordran av autentiseringsuppgifter.
Denna artikel omfattar:
- Aktivera genomströmning av autentiseringsuppgifter för standardkluster och kluster med hög samtidighet.
- Konfigurera genomströmning av autentiseringsuppgifter och initiera lagringsresurser i ADLS-konton.
- Åtkomst till ADLS-resurser direkt när genomströmning av autentiseringsuppgifter är aktiverat.
- Åtkomst till ADLS-resurser via en monteringspunkt när vidarebefordran av autentiseringsuppgifter är aktiverad.
- Funktioner och begränsningar som stöds vid användning av vidarebefordran av autentiseringsuppgifter.
Krav
- Premium-plan. Mer information om hur du uppgraderar en Standard-plan till en Premium-plan finns i Uppgradera eller nedgradera en Azure Databricks-arbetsyta.
- Ett Azure Data Lake Storage-lagringskonto. Azure Data Lake Storage-lagringskonton måste använda hierarkisk namnrymd för att fungera med identifieringsuppgiftsöverföring i Azure Data Lake Storage. Se Skapa ett lagringskonto för instruktioner om hur du skapar ett nytt ADLS-konto, inklusive hur du aktiverar det hierarkiska namnområdet.
- Korrekt konfigurerade användarbehörigheter för Azure Data Lake Storage. En Azure Databricks-administratör måste se till att användarna har rätt roller, till exempel Storage Blob Data Contributor, för att läsa och skriva data som lagras i Azure Data Lake Storage. Se Använda Azure-portalen för tilldelning av en Azure-roll för åtkomst till blob- och ködata.
- Förstå behörigheterna för arbetsyteadministratörer i arbetsytor som är aktiverade för genomströmning och granska dina befintliga administratörstilldelningar för arbetsytan. Arbetsyteadministratörer kan hantera åtgärder för sin arbetsyta, inklusive att lägga till användare och tjänstens huvudnamn, skapa kluster och delegera andra användare till arbetsyteadministratörer. Hanteringsuppgifter för arbetsytor, till exempel hantering av jobbägarskap och visning av notebook-filer, kan ge indirekt åtkomst till data som registrerats i Azure Data Lake Storage. Arbetsyteadministratör är en privilegierad roll som du bör distribuera noggrant.
- Du kan inte använda ett kluster som har konfigurerats med ADLS-autentiseringsuppgifter, till exempel tjänstens huvudautentiseringsuppgifter, med autentiseringsöverföring.
Viktigt!
Du kan inte autentisera till Azure Data Lake Storage med dina autentiseringsuppgifter för Microsoft Entra-ID om du är bakom en brandvägg som inte har konfigurerats för att tillåta trafik till Microsoft Entra-ID. Azure Firewall blockerar Active Directory-åtkomst som standard. Om du vill tillåta åtkomst konfigurerar du tjänsttaggen AzureActiveDirectory. Du hittar motsvarande information för virtuella nätverksinstallationer under AzureActiveDirectory-taggen i JSON-filen med Azure IP-intervall och tjänsttaggar. Mer information finns i Tjänsttaggar för Azure Firewall.
Loggningsrekommendationer
Du kan logga identiteter som skickas till ADLS Storage i Azure Storage-diagnostikloggar. Loggningsidentiteter gör att ADLS-begäranden kan kopplas till enskilda användare från Azure Databricks-kluster. Aktivera diagnostikloggning på ditt lagringskonto för att börja ta emot loggarna genom att göra följande: konfigurera med hjälp av PowerShell med kommandot Set-AzStorageServiceLoggingProperty. Ange 2.0 som version eftersom loggpostformat 2.0 innehåller användarens huvudnamn i begäran.
Aktivera överföring av autentiseringsuppgifter för Azure Data Lake Storage för ett kluster med hög parallellitet
Kluster med hög samtidighet kan delas av flera användare. De stöder endast Python och SQL med autentiseringsuppgiftspassthrough för Azure Data Lake Storage.
Viktigt!
Om du aktiverar genomströmning av Azure Data Lake Storage-autentiseringsuppgifter för ett kluster med hög samtidighet blockeras alla portar i klustret förutom portarna 44, 53 och 80.
- När du skapar ett kluster anger du Klusterläge till Hög samtidighet.
- Under Avancerade alternativ väljer du Aktivera genomströmning av autentiseringsuppgifter för dataåtkomst på användarnivå och tillåter endast Python- och SQL-kommandon.

Aktivera vidarebefordran av autentiseringsuppgifter för Azure Data Lake Storage för ett Standard-kluster
Standardkluster med genomströmning av autentiseringsuppgifter är begränsade till en enskild användare. Standardkluster stöder Python, SQL, Scala och R. På Databricks Runtime 10.4 LTS och senare stöds sparklyr.
Du måste tilldela en användare när klustret skapas, men klustret kan redigeras av en användare med behörighet att hantera när som helst för att ersätta den ursprungliga användaren.
Viktigt!
Den användare som tilldelats klustret måste ha minst behörigheten KAN KOPPLA TILL för klustret för att kunna köra kommandon i klustret. Arbetsplatsadministratörer och klusterskapare har hanteringsbehörighet, men kan inte köra kommandon i klustret om de inte är den utsedda klusteranvändaren.
- När du skapar ett kluster ställer du in klusterläget på Standard.
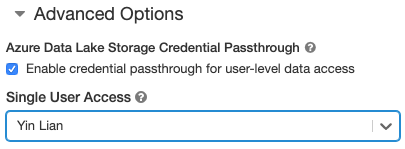
- Under Avancerade alternativ väljer du Aktivera genomströmning av autentiseringsuppgifter för dataåtkomst på användarnivå och väljer användarnamnet i listrutan Åtkomst för enskild användare.
Skapa en container
Containrar är ett sätt att organisera objekt i ett Azure-lagringskonto.
Få åtkomst till Azure Data Lake Storage direkt med autentiseringsöverföring
När du har konfigurerat överföring av Azure Data Lake Storage-autentiseringsuppgifter och skapat lagringscontainrar kan du komma åt data direkt i Azure Data Lake Storage med hjälp av en abfss:// sökväg.
Azure Data Lake Storage
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- Ersätt
<container-name>med namnet på en container i ADLS-lagringskontot. - Ersätt
<storage-account-name>med namnet på ADLS-lagringskontot.
Montera Azure Data Lake Storage till DBFS med autentiseringspassering
Du kan montera ett Azure Data Lake Storage-konto eller en mapp inuti det till Vad är DBFS?. Monteringen är en pekare till en data lake store, så data synkroniseras aldrig lokalt.
När du monterar data med ett kluster som har aktiverats med vidarebefordran av autentiseringsuppgifter för Azure Data Lake Storage, använder alla läsningar eller skrivningar till monteringspunkten dina Microsoft Entra ID-autentiseringsuppgifter. Den här monteringspunkten visas för andra användare, men de enda användare som har läs- och skrivåtkomst är de som:
- Ha åtkomst till det underliggande Azure Data Lake Storage-lagringskontot
- Använder ett kluster aktiverat för genomströmning av autentiseringsuppgifter i Azure Data Lake Storage
Azure Data Lake Storage
Om du vill montera ett Azure Data Lake Storage-filsystem eller en mapp i det använder du följande kommandon:
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Ersätt
<container-name>med namnet på en container i ADLS-lagringskontot. - Ersätt
<storage-account-name>med namnet på ADLS-lagringskontot. - Ersätt
<mount-name>med namnet på den avsedda monteringspunkten i DBFS.
Varning
Ange inte åtkomstnycklarna för lagringskontot eller tjänstens huvudautentiseringsuppgifter för att autentisera mot monteringspunkten. Det skulle ge andra användare åtkomst till filsystemet med dessa autentiseringsuppgifter. Syftet med genomströmning av Azure Data Lake Storage-autentiseringsuppgifter är att förhindra att du behöver använda dessa autentiseringsuppgifter och se till att åtkomsten till filsystemet är begränsad till användare som har åtkomst till det underliggande Azure Data Lake Storage-kontot.
Säkerhet
Det är säkert att dela Azure Data Lake Storage-kluster för genomströmning av autentiseringsuppgifter med andra användare. Du kommer att isoleras från varandra och kommer inte att kunna läsa eller använda varandras autentiseringsuppgifter.
Funktioner som stöds
| Funktion | Minsta version av Databricks Runtime | Anteckningar |
|---|---|---|
| Python och SQL | 5,5 | |
%run |
5,5 | |
| DBFS | 5,5 | Autentiseringsuppgifter skickas endast om DBFS-sökvägen matchas till en plats i Azure Data Lake Storage. För DBFS-sökvägar som matchar andra lagringssystem använder du en annan metod för att ange dina autentiseringsuppgifter. |
| Azure Data Lake Storage | 5,5 | |
| cachelagring på disk | 5,5 | |
| PySpark ML API | 5,5 |
Följande ML-klasser stöds inte:
|
| Broadcast-variabler | 5,5 | I PySpark finns det en gräns för storleken på de Python-UDF:er som du kan skapa, eftersom stora UDF:er skickas som sändningsvariabler. |
| Anteckningsboksspecifika bibliotek | 5,5 | |
| Scala | 5,5 | |
| SparkR | 6,0 | |
| sparklyr | 10.1 | |
| Hantera anteckningsböcker och modularisera kod i anteckningsböcker | 6.1 | |
| PySpark ML API | 6.1 | Alla PySpark ML-klasser stöds. |
| Klustermått | 6.1 | |
| Databricks Connect | 7.3 | Passthrough stöds på standardkluster. |
Begränsningar
Följande funktioner stöds inte med pass-through av autentiseringsuppgifter för Azure Data Lake Storage:
-
%fs(använd motsvarande dbutils.fs-kommando i stället). - Databricks-jobb.
- Referens för Databricks REST API.
- Unity Catalog.
-
Åtkomstkontroll för tabell. Behörigheterna som beviljas av genomströmning av autentiseringsuppgifter i Azure Data Lake Storage kan användas för att kringgå de detaljerade behörigheterna för tabell-ACL:er, medan de extra begränsningarna för tabell-ACL:er begränsar några av de fördelar du får med genomströmning av autentiseringsuppgifter. I synnerhet:
- Om du har Microsoft Entra-ID-behörighet att komma åt de datafiler som ligger till grund för en viss tabell har du fullständig behörighet för tabellen via RDD-API:et, oavsett begränsningarna för dem via tabell-ACL:er.
- Du kommer endast att begränsas av tabell-ACL:er när du använder DataFrame-API:et. Du får varningar om att du inte har behörighet
SELECTför någon fil om du försöker läsa filer direkt med DataFrame-API:et, även om du kan läsa filerna direkt via RDD-API:et. - Du kommer inte att kunna läsa från tabeller som backas upp av andra filsystem än Azure Data Lake Storage, även om du har tabell-ACL-behörighet att läsa tabellerna.
- Följande metoder för SparkContext-objekt (
sc) och SparkSession (spark) :- Inaktuella metoder.
- Metoder som
addFile()ochaddJar()som gör det möjligt för icke-administratörsanvändare att anropa Scala-kod. - Alla metoder som använder ett annat filsystem än Azure Data Lake Storage (för att få åtkomst till andra filsystem i ett kluster med Azure Data Lake Storage-genomströmning aktiverat använder du en annan metod för att ange dina autentiseringsuppgifter och se avsnittet om betrodda filsystem under Felsökning).
- De gamla Hadoop-API:erna (
hadoopFile()ochhadoopRDD()). - Streaming-API:er eftersom de autentiseringsuppgifter som skickas skulle upphöra att gälla medan strömmen fortfarande spelades.
-
DBFS-monteringar (
/dbfs) finns endast tillgängliga i Databricks Runtime 7.3 LTS och senare. Fästpunkter med konfigurerad autentiseringsuppgiftsöverföring stöds inte via den här sökvägen. - Azure Data Factory.
- MLflow på kluster med hög samtidighet.
- azureml-sdk Python-paket på kluster med hög samtidighet.
- Du kan inte förlänga livslängden för Microsoft Entra ID passthrough-token med hjälp av Microsoft Entra ID-tokens livslängdsprinciper. Om du skickar ett kommando till klustret som tar längre tid än en timme misslyckas det därför om en Azure Data Lake Storage-resurs nås efter 1-timmarsmarkeringen.
- När du använder Hive 2.3 och senare kan du inte lägga till en partition i ett kluster med genomströmning av autentiseringsuppgifter aktiverat. Mer information finns i avsnittet om relevant felsökning.
Felsökning
py4j.security.Py4JSecurityException: ... är inte vitlistad
Det här undantaget returneras när du använder en metod som Azure Databricks inte uttryckligen har markerat som säker för Azure Data Lake Storage-kluster med genomströmning för autentiseringsuppgifter. I de flesta fall innebär det att metoden skulle kunna tillåta att en användare i ett Azure Data Lake Storage-kluster med genomströmning för autentiseringsuppgifter kan komma åt en annan användares autentiseringsuppgifter.
org.apache.spark.api.python.PythonSecurityException: Path ... använder ett opålitligt filsystem
Det här undantaget utlöses om du försöker komma åt ett filsystem som Azure Data Lake Storage-klustret med genomströmning för autentiseringsuppgifter inte identifierar som ett säkert filsystem. Om du använder ett obetrott filsystem kan en användare i ett Azure Data Lake Storage-kluster för genomströmning av autentiseringsuppgifter komma åt en annan användares autentiseringsuppgifter, så vi tillåter inte att alla filsystem som vi inte är säkra på används på ett säkert sätt.
Om du vill konfigurera uppsättningen med betrodda filsystem i ett Azure Data Lake Storage-kluster med genomströmning för autentiseringsuppgifter anger du att Spark-konfigurationsnyckeln spark.databricks.pyspark.trustedFilesystems på klustret ska vara en kommaavgränsad lista med klassnamn som är betrodda implementeringar av org.apache.hadoop.fs.FileSystem.
Det går inte att lägga till en partition med AzureCredentialNotFoundException när genomströmning av autentiseringsuppgifter är aktiverat
Om du använder Hive 2.3-3.1 och försöker lägga till en partition i ett kluster med genomströmning för autentiseringsuppgifter aktiverat, inträffar följande undantag:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Token
Du kan undvika det här problemet genom att lägga till partitioner i ett kluster utan genomströmning av autentiseringsuppgifter aktiverat.