Attributanvändning med taggar
Den här artikeln beskriver hur du använder anpassade taggar och standardtaggar för att tillskriva arbetsbelastningar till specifika arbetsytor, team, projekt och användare.
Om du vill övervaka kostnader och korrekt tillskriva Azure Databricks-användning till organisationens affärsenheter och team (till exempel för återbetalningar) kan du tagga arbetsytor (resursgrupper) och beräkningsresurser. De här taggarna sprids till detaljerade kostnadsanalysrapporter som du kan komma åt i Azure-portalen.
Obs! Taggdata kan replikeras globalt. Använd inte taggnamn eller värden som kan äventyra säkerheten för dina resurser. Använd till exempel inte taggnamn som innehåller personlig eller känslig information.
Här är en rapport med fakturainformation för kostnadsanalys i Azure Portal som beskriver kostnaden per clusterid tagg under en månad:
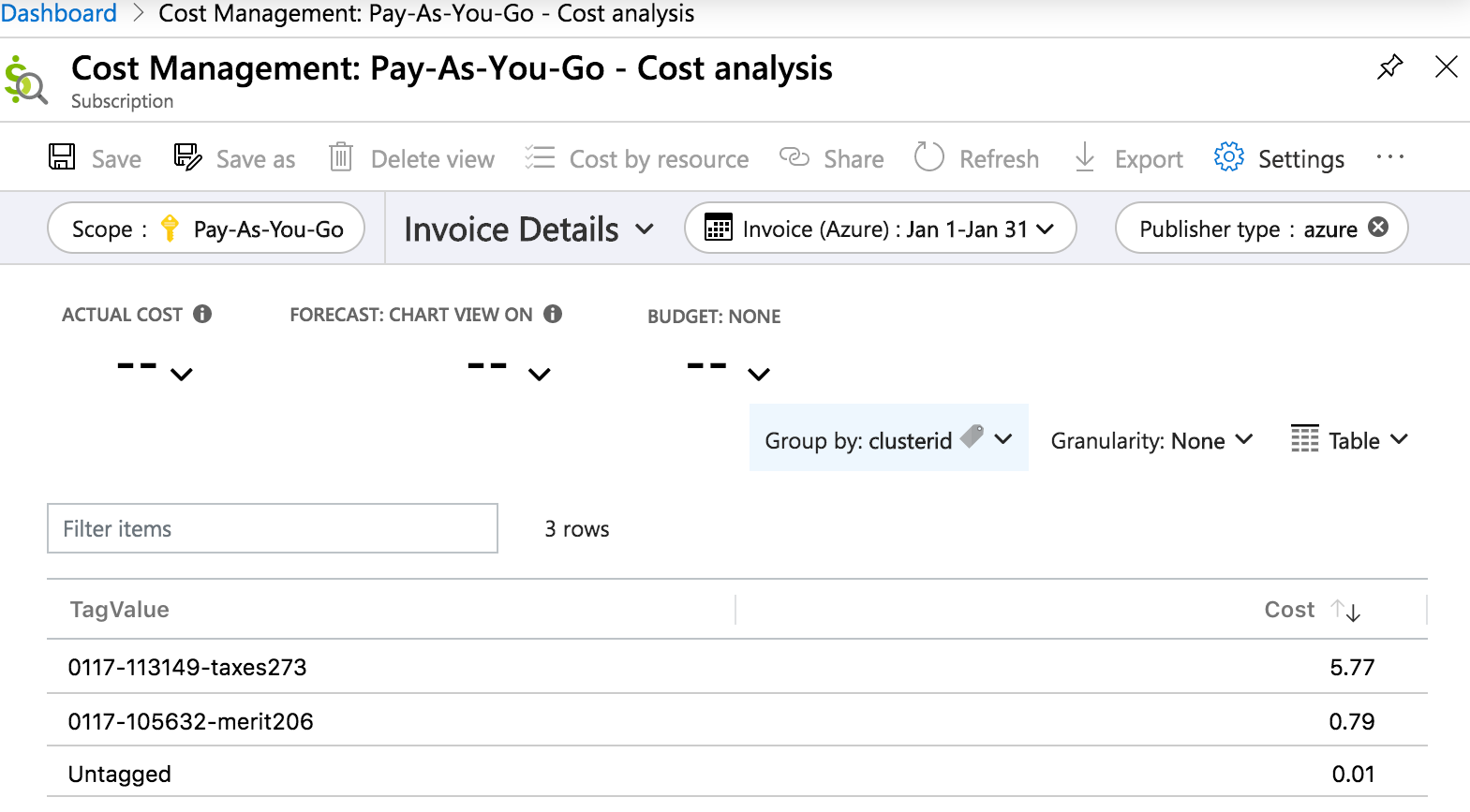
Taggade objekt och resurser
| Objekt | Taggningsgränssnitt (UI) | Taggningsgränssnitt (API) |
|---|---|---|
| Arbetsyta | Azure Portal | API för Azure-resurser |
| Pool | Poolgränssnitt i Azure Databricks-arbetsytan | API för instanspool |
| All-purpose och jobbberäkning | Beräkningsgränssnittet på Azure Databricks-arbetsytan | Kluster-API |
| SQL-lager | SQL Warehouse-användargränssnittet på Azure Databricks-arbetsytan | API för lager |
Varning
Tilldela inte en anpassad tagg med nyckeln Name till ett kluster. Varje kluster har en tagg Name vars värde anges av Azure Databricks. Om du ändrar värdet som är associerat med nyckeln Namekan klustret inte längre spåras av Azure Databricks. Därför kanske klustret inte avslutas när det har blivit inaktivt och fortsätter att medföra användningskostnader.
Standardtaggar
Azure Databricks lägger till följande standardtaggar i all-purpose compute:
| Taggnyckel | Värde |
|---|---|
Vendor |
Konstant värde: Databricks |
ClusterId |
Azure Databricks interna ID för klustret |
ClusterName |
Namnet på klustret |
Creator |
Användarnamn (e-postadress) för den användare som skapade klustret |
I jobbkluster tillämpar Azure Databricks även följande standardtaggar:
| Taggnyckel | Värde |
|---|---|
RunName |
Jobbnamn |
JobId |
Job-ID |
Azure Databricks lägger till följande standardtaggar i alla pooler:
| Taggnyckel | Värde |
|---|---|
Vendor |
Konstant värde: Databricks |
DatabricksInstancePoolCreatorId |
Internt ID för Azure Databricks för användaren som skapade poolen |
DatabricksInstancePoolId |
Azure Databricks interna ID för poolen |
Vid beräkning som används av Lakehouse Monitoring tillämpar Azure Databricks även följande taggar:
| Taggnyckel | Värde |
|---|---|
LakehouseMonitoring |
true |
LakehouseMonitoringTableId |
ID för den övervakade tabellen |
LakehouseMonitoringWorkspaceId |
ID för arbetsytan där monitorn skapades |
LakehouseMonitoringMetastoreId |
ID för metaarkivet där den övervakade tabellen finns |
Märk serverlösa beräkningsarbetslaster
Viktig
Den här funktionen finns i offentlig förhandsversion.
Om du vill tilldela serverlös beräkningsanvändning till användare, grupper eller projekt kan du använda budgetprinciper. När en användare tilldelas en budgetprincip märks deras serverlösa användning automatiskt med principtaggar. Se Attributserverlös användning med budgetprinciper.
Spridning av taggar
Taggar för arbetsyta, pool och kluster aggregeras av Azure Databricks och sprids till virtuella Azure-datorer för kostnadsanalysrapportering. Men pool- och klustertaggar sprids på olika sätt än varandra.
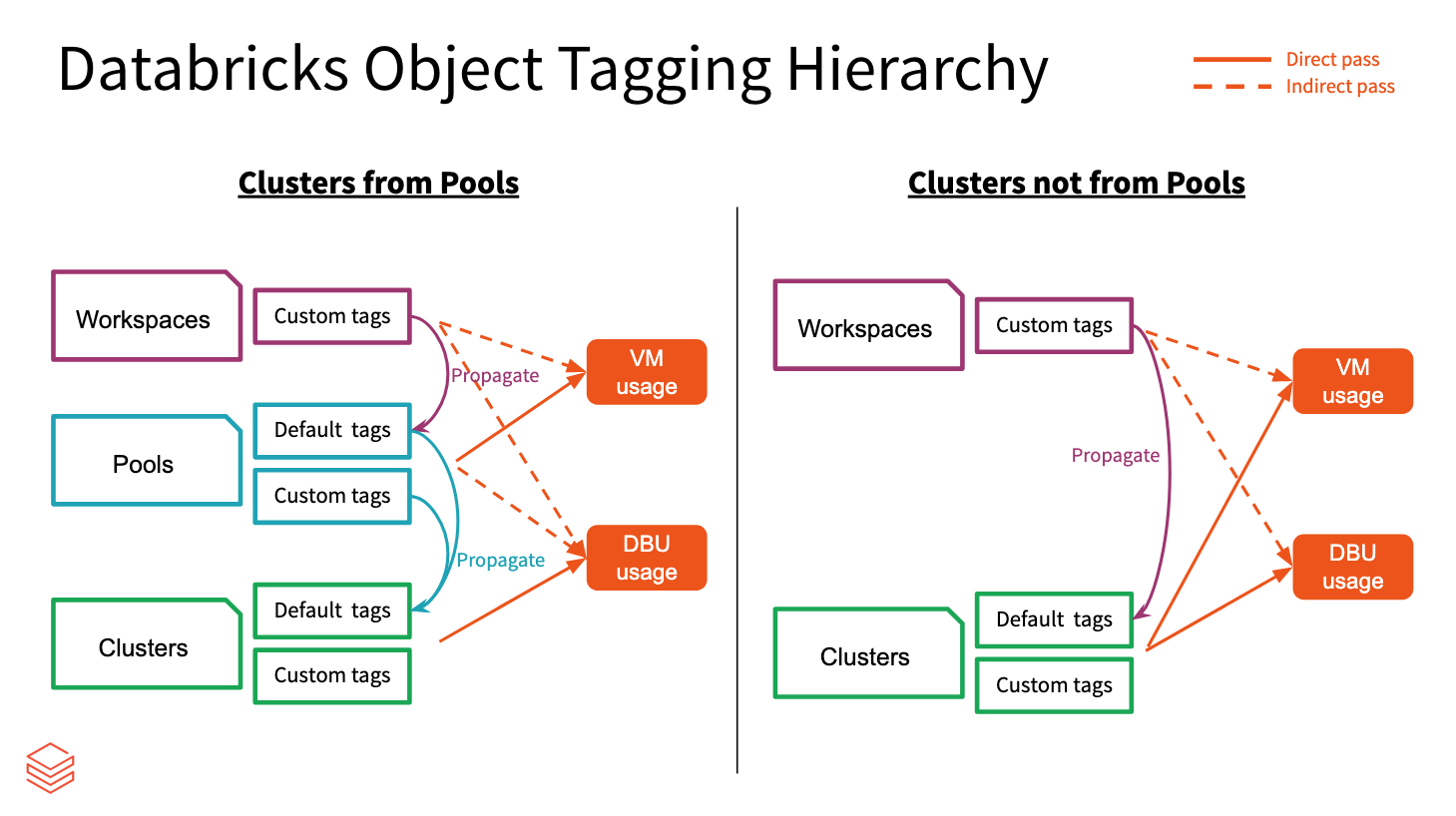
Arbetsyte- och pooltaggar aggregeras och tilldelas som resurstaggar för de virtuella Azure-datorer som är värdar för poolerna.
Arbetsyte- och klustertaggar aggregeras och tilldelas som resurstaggar för de virtuella Azure-datorer som är värdar för klustren.
När kluster skapas från pooler sprids endast arbetsytetaggar och pooltaggar till de virtuella datorerna. Klustertaggar sprids inte för att bevara startprestanda för poolkluster.
Tagga konfliktlösning
Om en anpassad klustertagg, pooltagg eller arbetsytetagg har samma namn som ett Azure Databricks-standardkluster eller en pooltagg, prefixet för den anpassade taggen när x_ den sprids.
Om en arbetsyta till exempel är taggad med vendor = Azure Databrickskommer den taggen att vara i konflikt med standardklustertaggen vendor = Databricks. Taggarna sprids därför som x_vendor = Azure Databricks och vendor = Databricks.
Begränsningar
- Det kan ta upp till en timme innan anpassade taggar för arbetsyta sprids till Azure Databricks efter en ändring.
- Högst 50 taggar kan tilldelas till en Azure-resurs. Om det totala antalet aggregerade taggar överskrider den här gränsen utvärderas
x_-prefixerade taggar i alfabetisk ordning och de som överskrider gränsen ignoreras. Om allax_-prefixerade taggar ignoreras och antalet är till över gränsen utvärderas de återstående taggarna i alfabetisk ordning och de som överskrider gränsen ignoreras. - Taggnycklar och värden får bara innehålla bokstäver, blanksteg, siffror eller tecken
+,-,=,.,_,:,/,@. Taggar som innehåller andra tecken är ogiltiga. - Om du ändrar taggnyckelnamn eller -värden gäller dessa ändringar endast efter klusteromstart eller poolexpansion.
- Om klustrets anpassade taggar står i konflikt med en pools anpassade taggar kan klustret inte skapas.
- Nyligen tillagda arbetsytetaggar propogate inte automatiskt till befintliga beräkningsresurser. Om du vill hämta nya taggar för propogate öppnar du informationssidan för beräkningsresursen, klickar på Redigeraoch sedan Bekräfta och starta om.
Metodtips för taggning
- Eftersom taggar kan anges manuellt bör organisationen standardisera sina nyckel/värde-par. Databricks rekommenderar att du utvecklar en affärsprincip för nyckel- och värdenamngivning som du kan dela med alla användare.
- Alla resurser ska taggas med allmänna nycklar som tillskriver användningen till en affärsenhet eller ett projekt. Till exempel kan en jobbberäkningsresurs som skapats av ekonomiteamet för deras årliga budget innehålla taggarna
business-unit:financeochproject:annual-budget. - Om du vill ha mer detaljerad information tilldelar du taggar med hjälp av nycklar med hög specificitet. Du kan till exempel skapa nycklar baserat på roller, produkter, tjänster eller kunder.
- När det är tillämpligt bör arbetsyteadministratörer framtvinga taggar med hjälp av beräkningsprinciper och budgetprinciper. Se Tillämpning av anpassad tagg.