Köblobar för inmatning med hanterad identitetsautentisering
När du köar blobar för inmatning från dina egna lagringskonton kan du använda hanterade identiteter som ett alternativ till SAS-token (signatur för delad åtkomst) och autentiseringsmetoder för delade nycklar . Hanterade identiteter är ett säkrare sätt att mata in data eftersom de inte kräver att du delar dina KUND-SAS-token eller delade nycklar med tjänsten. I stället tilldelas en hanterad identitet till klustret och beviljas läsbehörighet för det lagringskonto som används för att mata in data. Du kan återkalla dessa behörigheter när som helst.
Anteckning
- Den här autentiseringsmetoden gäller endast för Azure-blobar och Azure Data Lake-filer som finns i kundägda lagringskonton. Den gäller inte för lokala filer som laddats upp med Kusto SDK.
- Endast köad inmatning stöds. Infogad inmatning i Kusto-frågespråk och direkt inmatning med SDK-API:er stöds inte.
Tilldela en hanterad identitet till klustret
Följ översikten över hanterade identiteter för att lägga till en system- eller användartilldelad hanterad identitet i klustret. Om klustret redan har den önskade hanterade identiteten tilldelad kopierar du dess objekt-ID med följande steg:
Logga in på Azure Portal med ett konto som är associerat med Azure-prenumerationen som innehåller klustret.
Gå till klustret och välj Identitet.
Välj lämplig identitetstyp, system eller användartilldelad och kopiera sedan objekt-ID:t för den nödvändiga identiteten.

Bevilja behörigheter till den hanterade identiteten
I Azure Portal går du till lagringskontot som innehåller de data som du vill mata in.
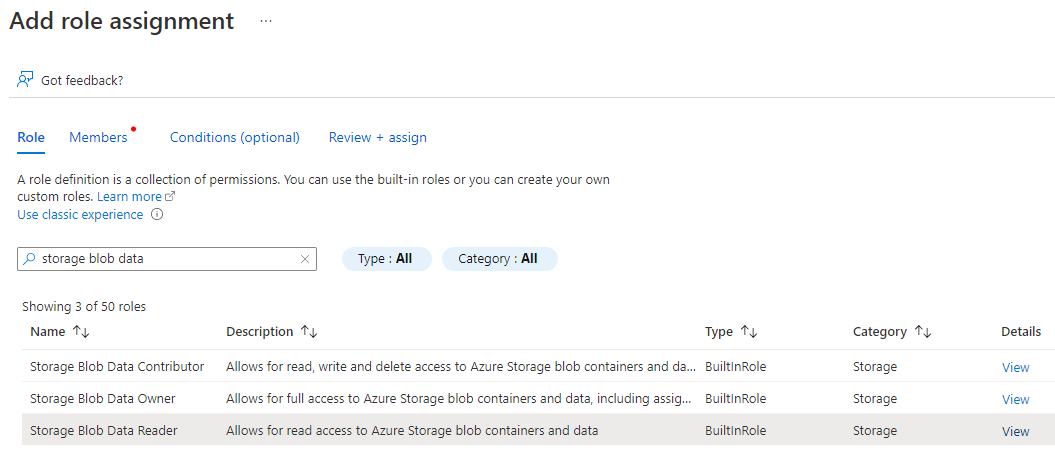
Välj Access Control och välj sedan + Lägg till>rolltilldelning.
Bevilja den hanterade identiteten Storage Blob Data Reader eller Storage Blob Data Contributor om du tänker använda källalternativet DeleteSourceOnSuccess , behörigheter till lagringskontot.
Viktigt
Det räcker inte att bevilja ägar- eller deltagarbehörigheter , vilket leder till att inmatningen misslyckas.
Ange principen för hanterad identitet i Azure Data Explorer
Om du vill använda den hanterade identiteten för att mata in data i klustret tillåter du användningsalternativet NativeIngestion för den valda hanterade identiteten. Intern inmatning syftar på möjligheten att använda en SDK för inmatning från en extern källa. Mer information om tillgängliga SDK:er finns i Klientbibliotek.
Principen för hanterad identitet för användning kan definieras på kluster- eller databasnivå i målklustret.
Om du vill tillämpa principen på databasnivå kör du följande kommando:
.alter-merge database <database name> policy managed_identity "[ { 'ObjectId' : '<managed_identity_id>', 'AllowedUsages' : 'NativeIngestion' }]"
Om du vill tillämpa principen på klusternivå kör du följande kommando:
.alter-merge cluster policy managed_identity "[ { 'ObjectId' : '<managed_identity_id>', 'AllowedUsages' : 'NativeIngestion' }]"
Ersätt <managed_identity_id> med objekt-ID:t för den hanterade identitet som krävs.
Anteckning
Du måste ha behörighet på All Database Admin klustret för att kunna redigera principen för hanterad identitet.
Köblobar för inmatning med hanterad identitet med Kusto SDK
När du matar in data med en Kusto SDK genererar du din blob-URI med hjälp av hanterad identitetsautentisering genom att lägga ;managed_identity={objectId} till den obehöriga blob-URI:n. Om du matar in data med klustrets systemtilldelade hanterade identitet kan du lägga ;managed_identity=system till i blob-URI:n.
Viktigt
Du måste använda en klient för inmatning i kö. Det går inte att använda hanterade identiteter med direkt inmatning eller infogad inmatning i Kusto-frågespråk.
Följande är exempel på blob-URI:er för system- och användartilldelade hanterade identiteter.
- Systemtilldelade:
https://demosa.blob.core.windows.net/test/export.csv;managed_identity=system - Användartilldelade:
https://demosa.blob.core.windows.net/test/export.csv;managed_identity=6a5820b9-fdf6-4cc4-81b9-b416b444fd6d
Viktigt
- När du använder hanterade identiteter för att mata in data med C# SDK måste du ange en blobstorlek i
BlobSourceOptions. Om storleken inte har angetts försöker SDK fylla i blobstorleken genom att öppna lagringskontot, vilket resulterar i ett fel. - Storleksparametern ska vara den råa (okomprimerade) datastorleken och inte nödvändigtvis blobstorleken.
- Om du inte känner till storleken vid tidpunkten för inmatningen kan du ange värdet noll (0). Tjänsten försöker identifiera storleken med hjälp av den hanterade identiteten för autentisering.