Skapa lösningar för affärskontinuitet och haveriberedskap med Azure Data Explorer
Den här artikeln beskriver hur du kan förbereda dig för ett regionalt avbrott i Azure genom att replikera dina Azure-Data Explorer resurser, hantering och inmatning i olika Azure-regioner. Ett exempel på datainmatning med Azure Event Hubs ges. Kostnadsoptimering beskrivs också för olika arkitekturkonfigurationer. En mer djupgående titt på arkitekturöverväganden och återställningslösningar finns i översikten över affärskontinuitet.
Förbereda för regionalt avbrott i Azure för att skydda dina data
Azure Data Explorer stöder inte automatiskt skydd mot avbrott i en hel Azure-region. Denna störning kan inträffa under en naturkatastrof, som en jordbävning. Om du behöver en lösning för en haveriberedskapssituation utför du följande steg för att säkerställa affärskontinuitet. I de här stegen replikerar du kluster, hantering och datainmatning i två Azure-kopplade regioner.
- Skapa två eller flera oberoende kluster i två länkade Azure-regioner.
- Replikera alla hanteringsaktiviteter , till exempel att skapa nya tabeller eller hantera användarroller i varje kluster.
- Mata in data i varje kluster parallellt.
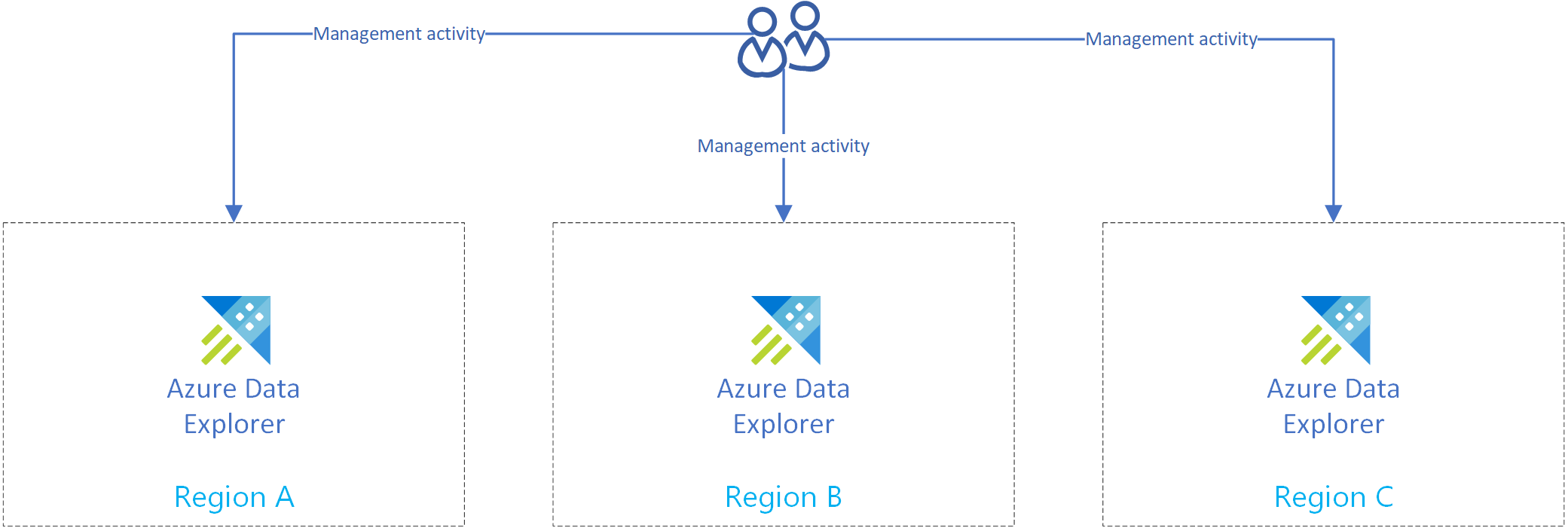
Skapa flera oberoende kluster
Skapa fler än ett Azure Data Explorer-kluster i mer än en region. Kontrollera att minst två av dessa kluster har skapats i azure-kopplade regioner.
Följande bild visar repliker, tre kluster i tre olika regioner.

Replikera hanteringsaktiviteter
Replikera hanteringsaktiviteterna för att ha samma klusterkonfiguration i varje replik.
Skapa på varje replik på samma sätt:
- Databaser: Du kan använda Azure Portal eller någon av våra SDK:er för att skapa en ny databas.
- Tabeller
- Mappningar
- Principer
Hantera autentisering och auktorisering på varje replik.
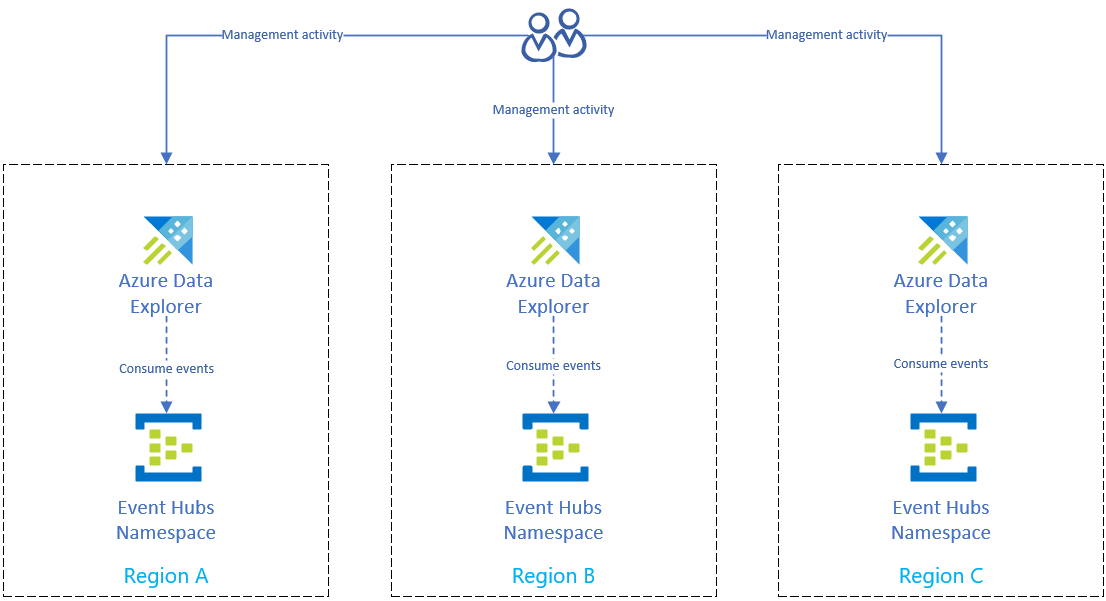
Haveriberedskapslösning med inmatning av händelsehubb
När du är klar med att förbereda för regionalt avbrott i Azure för att skydda dina data distribueras dina data och din hantering till flera regioner. Om det uppstår ett avbrott i en region kan Azure Data Explorer använda de andra replikerna.
Konfigurera inmatning med hjälp av en händelsehubb
Om du vill mata in data från Azure Event Hubs till varje regions Azure Data Explorer-kluster replikerar du först Azure Event Hubs konfigurationen i varje region. Konfigurera sedan varje regions Azure Data Explorer-replik för att mata in data från motsvarande Händelsehubbar.
Anteckning
Inmatning via Azure Event Hubs/IoT Hub/Storage är robust. Om ett kluster inte är tillgängligt under en viss tidsperiod kommer det att komma ikapp vid ett senare tillfälle och infoga väntande meddelanden eller blobar. Den här processen förlitar sig på kontrollpunkter.
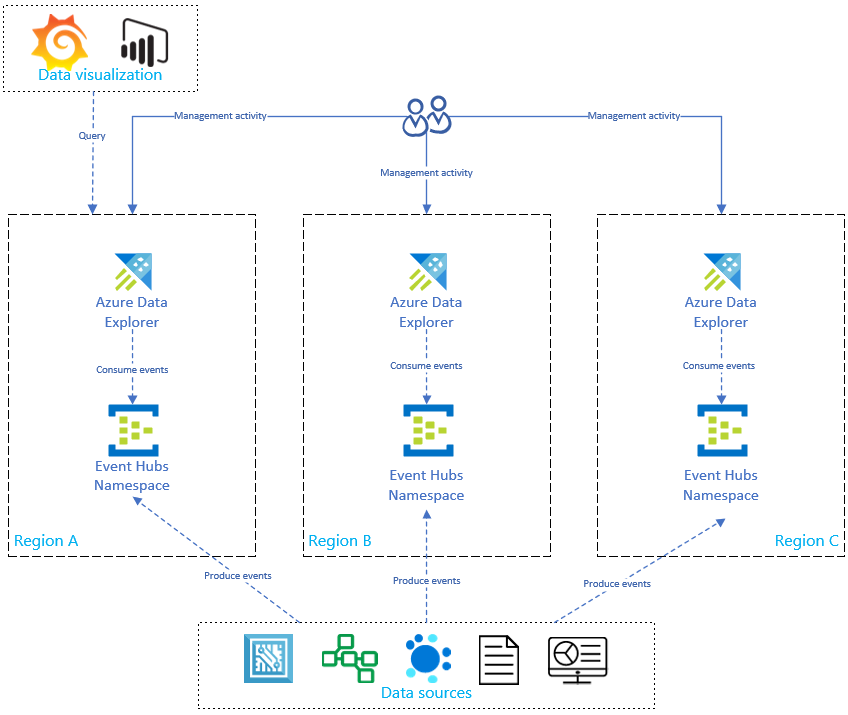
Som du ser i diagrammet nedan skapar dina datakällor händelser till händelsehubbar i alla regioner, och varje Azure-Data Explorer replik använder händelserna. Datavisualiseringskomponenter som Power BI, Grafana eller SDK-baserade WebApps kan fråga en av replikerna.
Optimera kostnader
Nu är du redo att optimera replikerna med hjälp av några av följande metoder:
- Skapa en konfiguration för dataåterställning på begäran
- Starta och stoppa replikerna
- Implementera en programtjänst med hög tillgänglighet
- Optimera kostnaden i en aktiv-aktiv-konfiguration
Skapa en konfiguration för dataåterställning på begäran
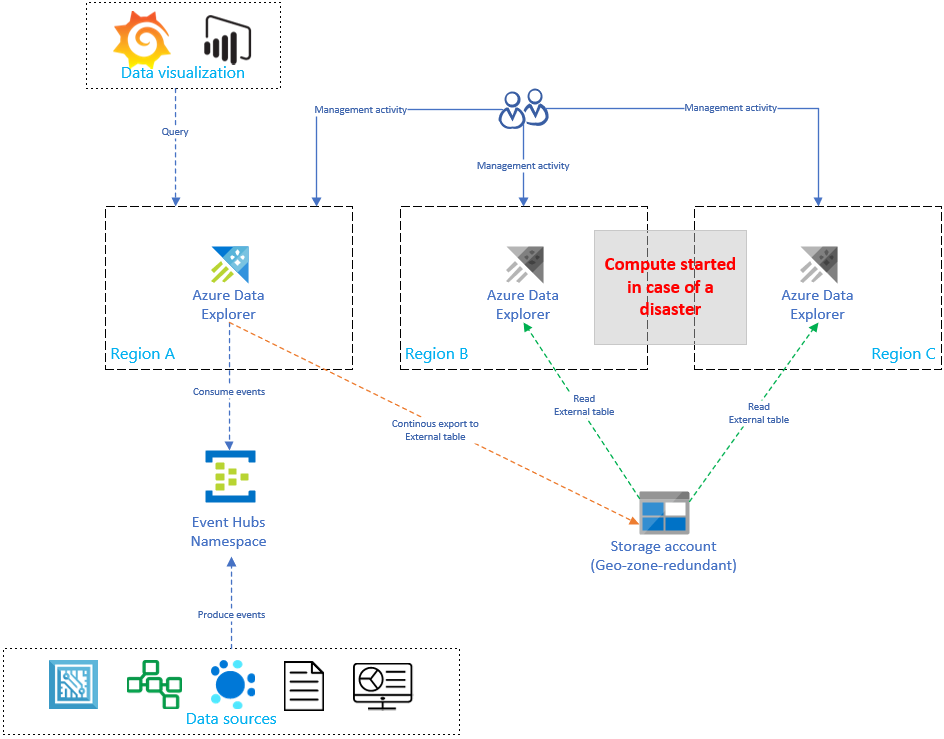
Om du replikerar och uppdaterar Azure-Data Explorer ökar konfigurationen linjärt kostnaden med antalet repliker. För att optimera kostnaden kan du implementera en arkitekturvariant för att balansera tid, redundans och kostnad. I en konfiguration för dataåterställning på begäran har kostnadsoptimering implementerats genom att införa passiva Azure Data Explorer-repliker. Dessa repliker aktiveras bara om det inträffar en katastrof i den primära regionen (till exempel region A). Replikerna i regionerna B och C behöver inte vara aktiva dygnet innan, vilket minskar kostnaderna avsevärt. I de flesta fall är dock prestandan för dessa repliker inte lika bra som det primära klustret. Mer information finns i Konfiguration av dataåterställning på begäran.
I bilden nedan matas endast ett kluster in data från händelsehubben. Det primära klustret i region A utför kontinuerlig dataexport av alla data till ett lagringskonto. De sekundära replikerna har åtkomst till data med hjälp av externa tabeller.
Starta och stoppa replikerna
Du kan starta och stoppa de sekundära replikerna med någon av följande metoder:
Azure Data Explorer-anslutning till Power Automate (förhandsversion)
Knappen Stoppa på fliken Översikt i Azure Portal. Mer information finns i Stoppa och starta om klustret.
Azure CLI:
az kusto cluster stop --name=<clusterName> --resource-group=<rgName> --subscription=<subscriptionId>”
Implementera en programtjänst med hög tillgänglighet
Skapa Azure App Service BCDR-klienten
Det här avsnittet visar hur du skapar en Azure App Service som stöder en anslutning till en enda primär och flera sekundära Azure-Data Explorer kluster. Följande bild illustrerar den Azure App Service konfigurationen.
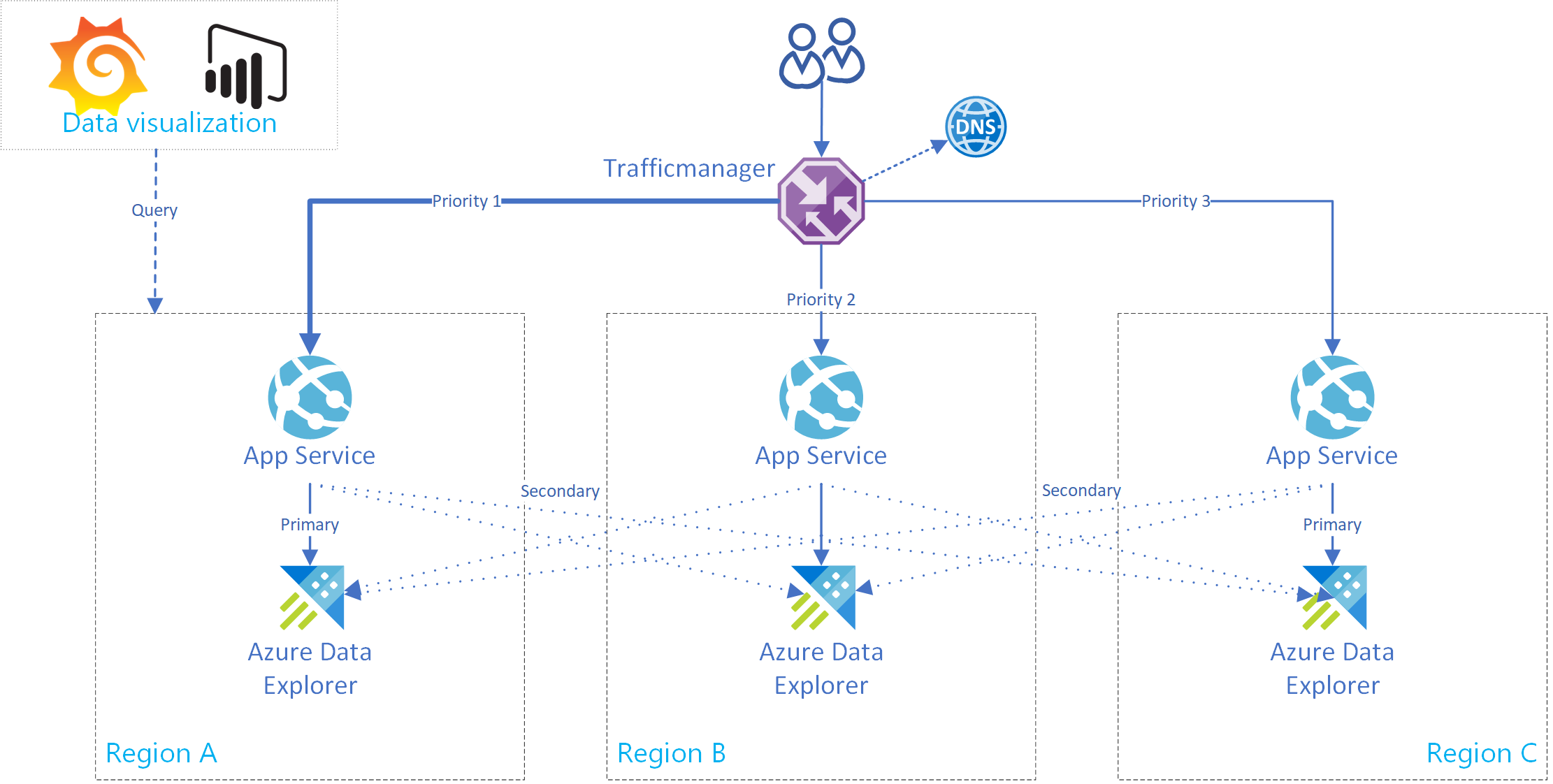
Tips
Om du har flera anslutningar mellan repliker i samma tjänst får du ökad tillgänglighet. Den här konfigurationen är inte bara användbar i instanser av regionala avbrott.
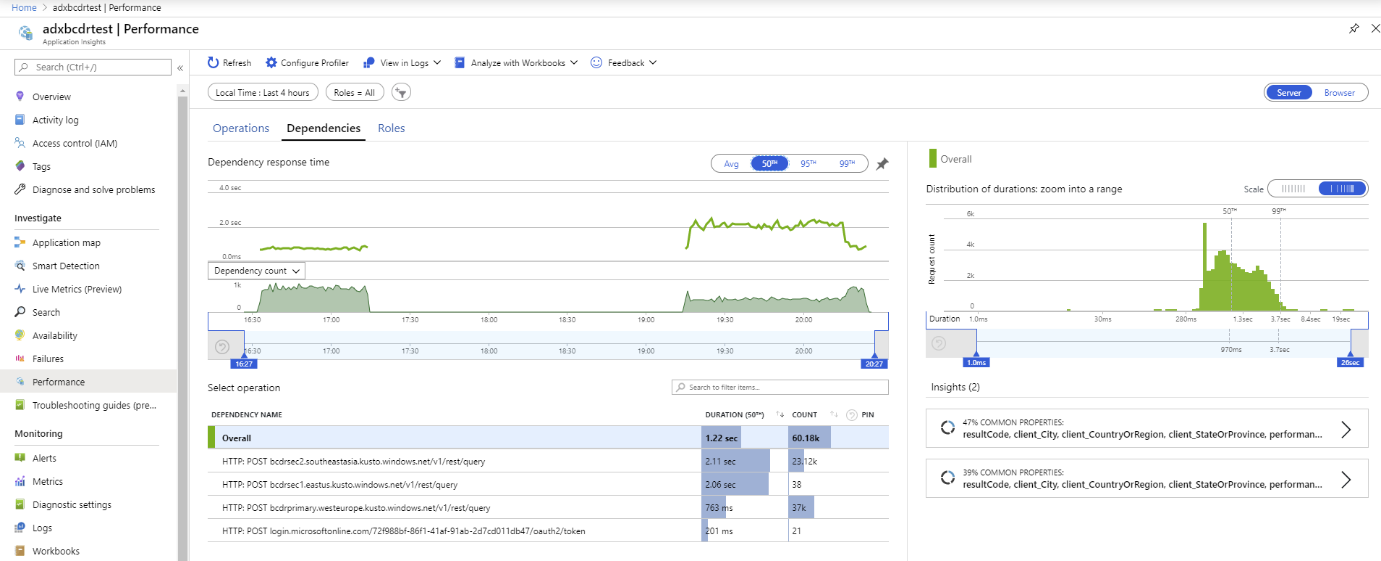
Använd den här exempelkoden för en apptjänst. För att implementera en klient med flera kluster har klassen AdxBcdrClient skapats. Varje fråga som körs med den här klienten skickas först till det primära klustret. Om det uppstår ett fel skickas frågan till sekundära repliker.
Använd mått för anpassade application insights för att mäta prestanda och begära distribution till primära och sekundära kluster.
Testa Azure App Service BCDR-klienten
Vi körde ett test med flera Azure Data Explorer-repliker. Efter ett simulerat avbrott i primära och sekundära kluster kan du se att BCDR-klienten för apptjänsten fungerar som avsett.
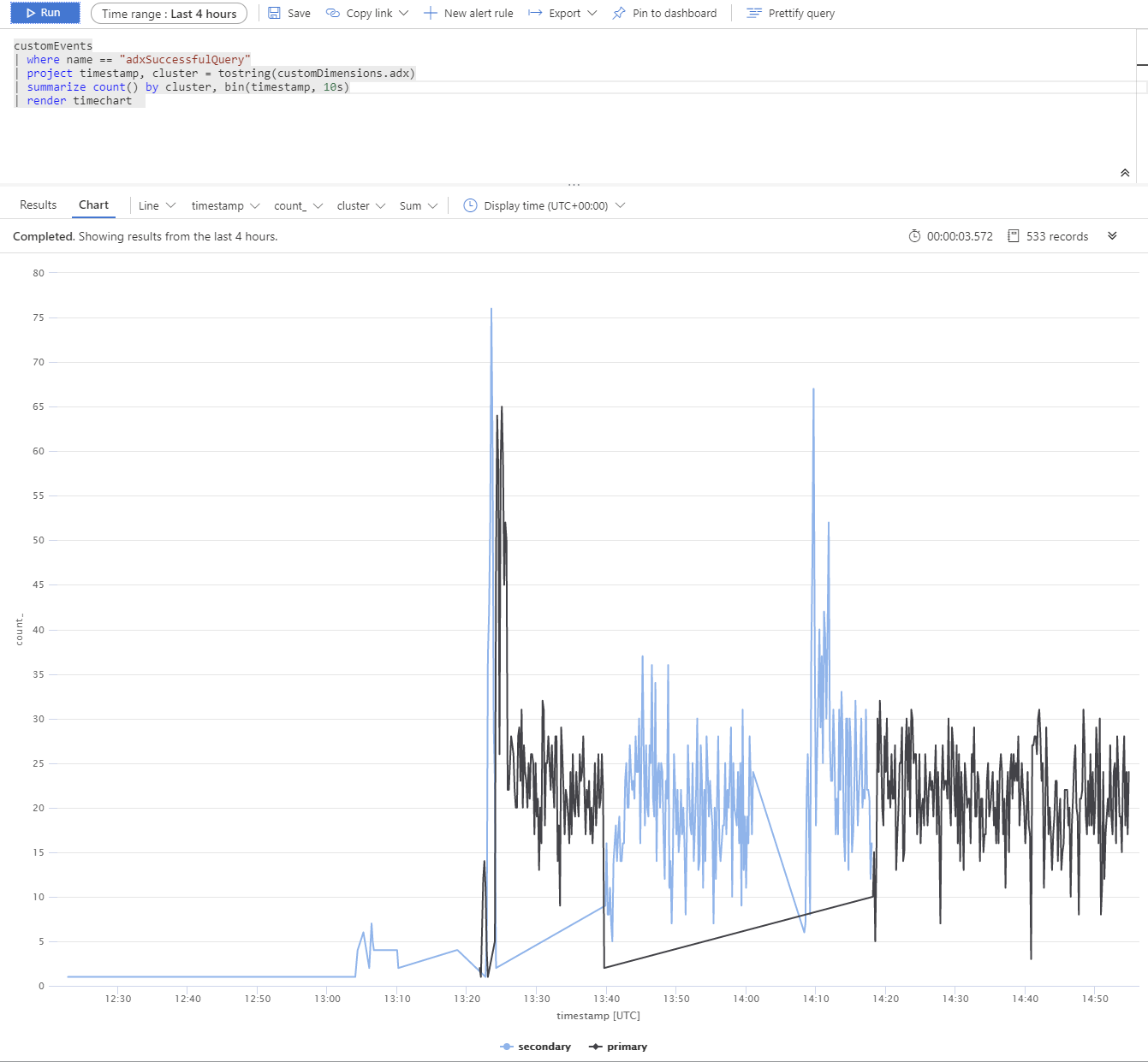
Azure-Data Explorer-kluster distribueras i Europa, västra (primärt 2xD14v2), Sydostasien och USA, östra (2xD11v2).
Anteckning
Långsammare svarstider beror på olika SKU:er och frågor över hela planeten.
Utföra dynamisk eller statisk routning
Använd Azure Traffic Manager-routningsmetoder för dynamisk eller statisk routning av begäranden. Azure Traffic Manager är en DNS-baserad trafiklastbalanserare som gör att du kan distribuera App Service-trafik. Den här trafiken är optimerad för tjänster i globala Azure-regioner, samtidigt som den ger hög tillgänglighet och svarstider.
Du kan också använda Azure Front Door-baserad routning. Jämförelse av dessa två metoder finns i Belastningsutjämning med Azures programleveranssvit.
Optimera kostnaden i en aktiv-aktiv-konfiguration
Om du använder en aktiv-aktiv konfiguration för haveriberedskap ökar kostnaden linjärt. Kostnaden omfattar noder, lagring, pålägg och ökade nätverkskostnader för bandbredd.
Använda optimerad autoskalning för att optimera kostnader
Använd funktionen optimerad autoskalning för att konfigurera horisontell skalning för de sekundära klustren. De bör dimensioneras så att de kan hantera inmatningsbelastningen. När det primära klustret inte kan nås får de sekundära klustren mer trafik och skalas enligt konfigurationen.
Med optimerad autoskalning i det här exemplet sparades ungefär 50 % av kostnaden i jämförelse med samma vågräta och lodräta skalning på alla repliker.