Utforma en databas för flera klientorganisationer med Hjälp av Azure Cosmos DB for PostgreSQL
GÄLLER FÖR: ![]() Azure Cosmos DB for PostgreSQL (drivs av Citus-databastillägget till PostgreSQL)
Azure Cosmos DB for PostgreSQL (drivs av Citus-databastillägget till PostgreSQL)
I den här självstudien använder du Azure Cosmos DB for PostgreSQL för att lära dig hur du:
- Skapa ett kluster
- Använda psql-verktyget för att skapa ett schema
- Fragmentera tabeller mellan noder
- Mata in exempeldata
- Fråga efter klientdata
- Dela data mellan klientorganisationer
- Anpassa schemat per klientorganisation
Förutsättningar
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Skapa ett kluster
Logga in på Azure Portal och följ dessa steg för att skapa ett Azure Cosmos DB for PostgreSQL-kluster:
Gå till Skapa ett Azure Cosmos DB for PostgreSQL-kluster i Azure-portalen.
I klusterformuläret Skapa en Azure Cosmos DB for PostgreSQL-kluster :
Fyll i informationen på fliken Basics (Grunder).
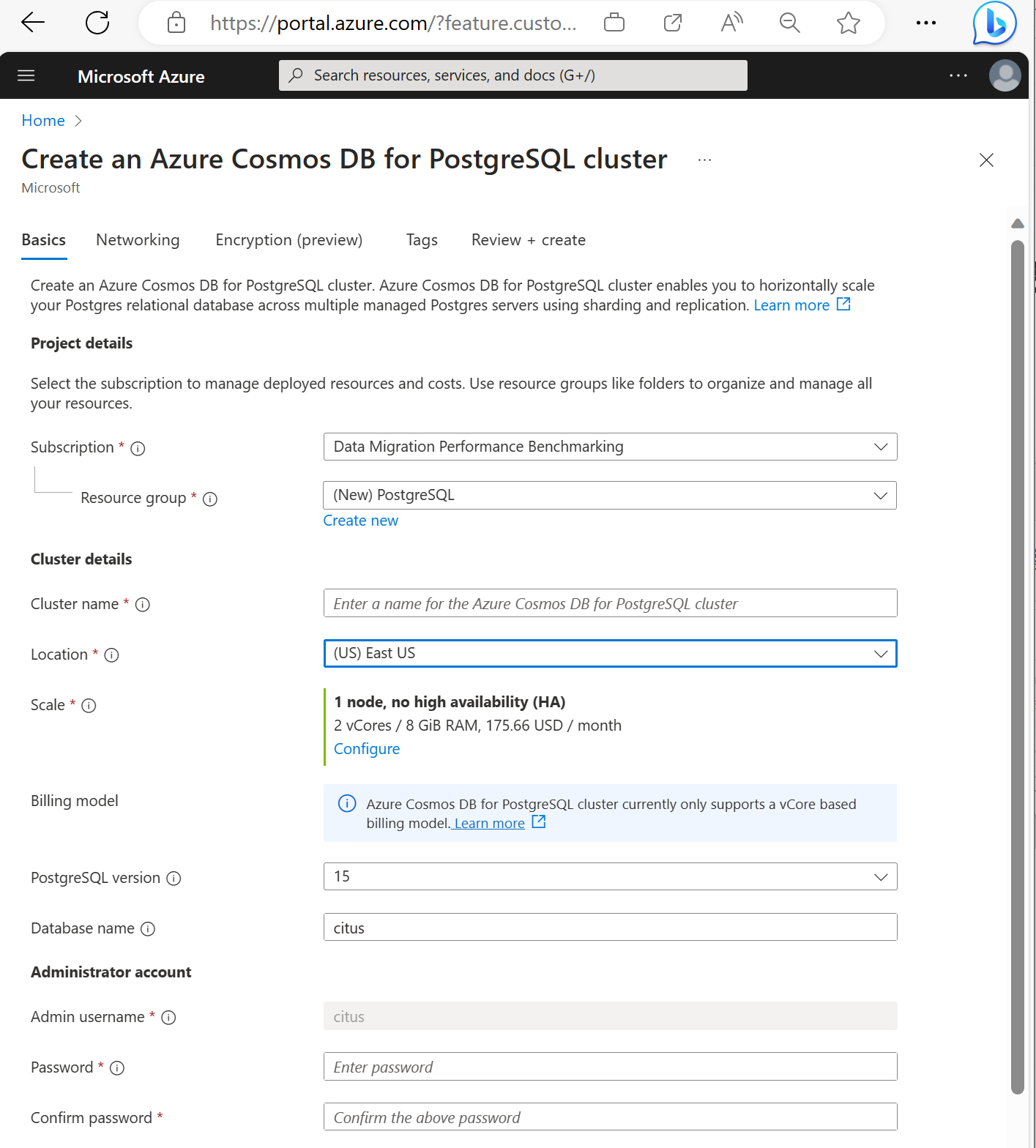
De flesta alternativ är självförklarande, men tänk på följande:
- Klusternamnet bestämmer det DNS-namn som dina program använder för att ansluta, i formuläret
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Du kan välja en större PostgreSQL-version, till exempel 15. Azure Cosmos DB for PostgreSQL stöder alltid den senaste Citus-versionen för den valda större Postgres-versionen.
- Administratörsanvändarnamnet måste ha värdet
citus. - Du kan lämna databasnamnet som standardvärde "citus" eller definiera ditt enda databasnamn. Du kan inte byta namn på databasen efter klusteretablering.
- Klusternamnet bestämmer det DNS-namn som dina program använder för att ansluta, i formuläret
Välj Nästa: Nätverk längst ned på skärmen.
På skärmen Nätverk väljer du Tillåt offentlig åtkomst från Azure-tjänster och resurser i Azure till det här klustret.
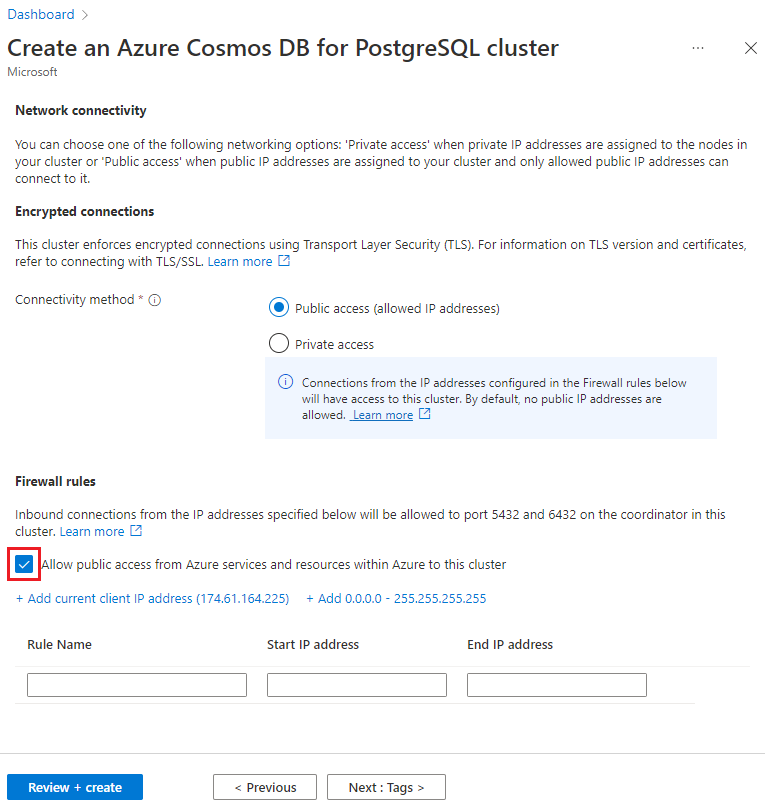
Välj Granska + skapa, och när valideringen är godkänd väljer du Skapa för att skapa klustret.
Etableringen tar några minuter. Sidan omdirigeras till övervakning av distribution. När statusen ändras från Distribution pågår till Distributionen är klar väljer du Gå till resurs.
Använda psql-verktyget för att skapa ett schema
När du har anslutit till Azure Cosmos DB for PostgreSQL med psql kan du utföra några grundläggande uppgifter. Den här självstudien beskriver hur du skapar en webbapp som gör det möjligt för annonsörer att spåra sina kampanjer.
Flera företag kan använda appen, så vi skapar en tabell för företag och en annan för deras kampanjer. Kör följande kommandon i psql-konsolen:
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blocked_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id)
);
Varje kampanj betalar för att köra annonser. Lägg också till en tabell för annonser genom att köra följande kod i psql efter koden ovan:
CREATE TABLE ads (
id bigserial,
company_id bigint,
campaign_id bigint,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, campaign_id)
REFERENCES campaigns (company_id, id)
);
Slutligen spårar vi statistik om klick och visningar för varje annons:
CREATE TABLE clicks (
id bigserial,
company_id bigint,
ad_id bigint,
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial,
company_id bigint,
ad_id bigint,
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
Du kan se de nyligen skapade tabellerna i listan över tabeller som nu finns i psql genom att köra:
\dt
Program med flera klientorganisationer kan endast framtvinga unikhet per klientorganisation, vilket är anledningen till att alla primära och externa nycklar inkluderar företagets ID.
Fragmentera tabeller mellan noder
En Azure Cosmos DB for PostgreSQL-distribution lagrar tabellrader på olika noder baserat på värdet för en användarutnämnd kolumn. Den här "distributionskolumnen" markerar vilken klientorganisation som äger vilka rader.
Nu ska vi ange att distributionskolumnen ska vara company_id, klientidentifieraren. Kör följande funktioner i psql:
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
Viktigt!
Det är nödvändigt att distribuera tabeller eller använda schemabaserad horisontell partitionering för att dra nytta av prestandafunktionerna i Azure Cosmos DB for PostgreSQL. Om du inte distribuerar tabeller eller scheman kan arbetsnoder inte hjälpa till att köra frågor som rör deras data.
Mata in exempeldata
Utanför psql laddar du nu ned exempeldatauppsättningar på den normala kommandoraden:
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
I psql kan du massinläsa data. Se till att köra psql i samma katalog där du laddade ned datafilerna.
SET client_encoding TO 'UTF8';
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
Dessa data kommer nu att spridas över arbetsnoder.
Fråga efter klientdata
När programmet begär data för en enda klientorganisation kan databasen köra frågan på en enda arbetsnod. Frågor med en klientorganisation filtreras efter ett enda klientorganisations-ID. Följande frågefilter company_id = 5 för annonser och visningar. Prova att köra den i psql för att se resultatet.
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
Dela data mellan klientorganisationer
Hittills har alla tabeller distribuerats av company_id. Vissa data tillhör dock inte naturligt någon klientorganisation i synnerhet och kan delas. Till exempel kanske alla företag i exempelannonsplattformen vill få geografisk information för sin målgrupp baserat på IP-adresser.
Skapa en tabell för att lagra delad geografisk information. Kör följande kommandon i psql:
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
geo_ips Gör sedan en "referenstabell" för att lagra en kopia av tabellen på varje arbetsnod.
SELECT create_reference_table('geo_ips');
Läs in den med exempeldata. Kom ihåg att köra det här kommandot i psql inifrån katalogen där du laddade ned datauppsättningen.
\copy geo_ips from 'geo_ips.csv' with csv
Att koppla klicktabellen med geo_ips är effektivt på alla noder. Här är en koppling för att hitta platserna för alla som klickade på annons 290. Prova att köra frågan i psql.
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
Anpassa schemat per klientorganisation
Varje klientorganisation kan behöva lagra särskild information som inte behövs av andra. Alla klienter delar dock en gemensam infrastruktur med ett identiskt databasschema. Vart kan de extra data gå?
Ett trick är att använda en öppen kolumntyp som PostgreSQL:s JSONB. Vårt schema har ett JSONB-fält i clicks med namnet user_data.
Ett företag (till exempel företag fem) kan använda kolumnen för att spåra om användaren finns på en mobil enhet.
Här är en fråga för att hitta vem som klickar mer: mobila eller traditionella besökare.
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
Vi kan optimera den här frågan för ett enskilt företag genom att skapa ett partiellt index.
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
Mer allmänt kan vi skapa en GIN-index för varje nyckel och värde i kolumnen.
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
Rensa resurser
I föregående steg skapade du Azure-resurser i ett kluster. Om du inte förväntar dig att behöva dessa resurser i framtiden tar du bort klustret. Välj knappen Ta bort på översiktssidan för klustret. När du uppmanas till det på en popup-sida bekräftar du namnet på klustret och väljer den sista knappen Ta bort .
Nästa steg
I den här självstudien har du lärt dig hur du etablerar ett kluster. Du anslöt till den med psql, skapade ett schema och distribuerade data. Du har lärt dig att fråga data både inom och mellan klientorganisationer och anpassa schemat per klientorganisation.
- Läs mer om klusternodtyper
- Fastställa den bästa initiala storleken för klustret