Migrera en-till-få-relationsdata till ett Azure Cosmos DB för NoSQL-konto
GÄLLER FÖR: ![]() NoSQL
NoSQL
För att kunna migrera från en relationsdatabas till Azure Cosmos DB för NoSQL kan det vara nödvändigt att göra ändringar i datamodellen för optimering.
En vanlig transformering är att avnormalisera data genom att bädda in relaterade underwebbplatser i ett JSON-dokument. Här tittar vi på några alternativ för detta med hjälp av Azure Data Factory eller Azure Databricks. Mer information om datamodellering för Azure Cosmos DB finns i datamodellering i Azure Cosmos DB.
Exempel på ett scenario
Anta att vi har följande två tabeller i vår SQL-databas, Orders och OrderDetails.
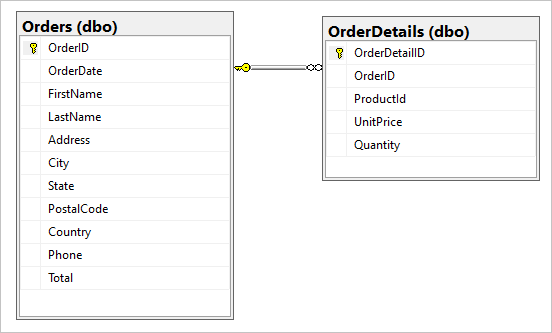
Vi vill kombinera den här en-till-få-relationen till ett JSON-dokument under migreringen. Skapa ett enda dokument genom att skapa en T-SQL-fråga med hjälp av FOR JSON:
SELECT
o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o;
Resultatet av den här frågan skulle innehålla data från tabellen Beställningar :

Helst vill du använda en enda Azure Data Factory-kopieringsaktivitet (ADF) för att köra frågor mot SQL-data som källa och skriva utdata direkt till Azure Cosmos DB-mottagare som lämpliga JSON-objekt. För närvarande är det inte möjligt att utföra den JSON-transformering som krävs i en kopieringsaktivitet. Om vi försöker kopiera resultatet av ovanstående fråga till en Azure Cosmos DB för NoSQL-container ser vi fältet OrderDetails som en strängegenskap för vårt dokument i stället för den förväntade JSON-matrisen.
Vi kan kringgå den här aktuella begränsningen på något av följande sätt:
- Använd Azure Data Factory med två kopieringsaktiviteter:
- Hämta JSON-formaterade data från SQL till en textfil på en mellanliggande bloblagringsplats
- Läs in data från JSON-textfilen till en container i Azure Cosmos DB.
- Använd Azure Databricks för att läsa från SQL och skriva till Azure Cosmos DB – vi presenterar två alternativ här.
Nu ska vi titta närmare på dessa metoder:
Azure Data Factory
Även om vi inte kan bädda in OrderDetails som en JSON-matris i Azure Cosmos DB-måldokumentet kan vi kringgå problemet med hjälp av två separata kopieringsaktiviteter.
Kopieringsaktivitet nr 1: SqlJsonToBlobText
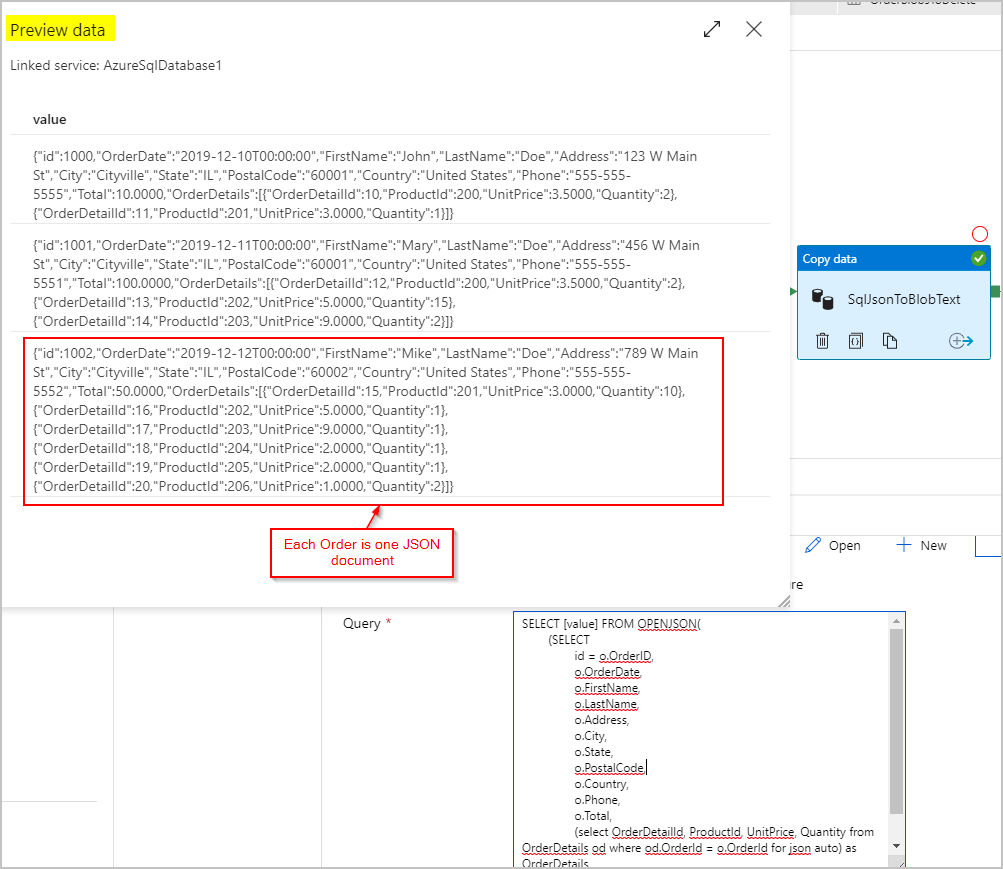
För källdata använder vi en SQL-fråga för att hämta resultatuppsättningen som en enda kolumn med ett JSON-objekt (som representerar order) per rad med hjälp av funktionerna SQL Server OPENJSON och FOR JSON PATH:
SELECT [value] FROM OPENJSON(
(SELECT
id = o.OrderID,
o.OrderDate,
o.FirstName,
o.LastName,
o.Address,
o.City,
o.State,
o.PostalCode,
o.Country,
o.Phone,
o.Total,
(select OrderDetailId, ProductId, UnitPrice, Quantity from OrderDetails od where od.OrderId = o.OrderId for json auto) as OrderDetails
FROM Orders o FOR JSON PATH)
)
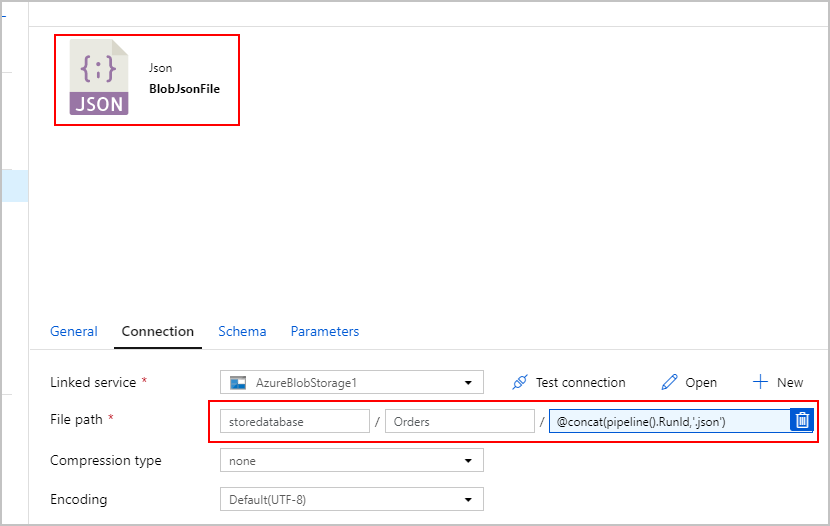
För kopieringsaktivitetens SqlJsonToBlobText mottagare väljer vi "Avgränsad text" och pekar den på en specifik mapp i Azure Blob Storage. Den här mottagaren innehåller ett dynamiskt genererat unikt filnamn (till exempel @concat(pipeline().RunId,'.json').
Eftersom vår textfil inte är "avgränsad" och vi inte vill att den ska parsas i separata kolumner med kommatecken. Vi vill också bevara dubbla citattecken ("), ange "Kolumn avgränsare" till en flik ("\t") – eller ett annat tecken som inte förekommer i data och sedan ange "Citattecken" till "Inget citattecken".

Kopieringsaktivitet nr 2: BlobJsonToCosmos
Därefter ändrar vi vår ADF-pipeline genom att lägga till den andra kopieringsaktiviteten som söker i Azure Blob Storage efter textfilen som skapades av den första aktiviteten. Den bearbetar den som "JSON"-källa för att infoga i Azure Cosmos DB-mottagare som ett dokument per JSON-rad som finns i textfilen.
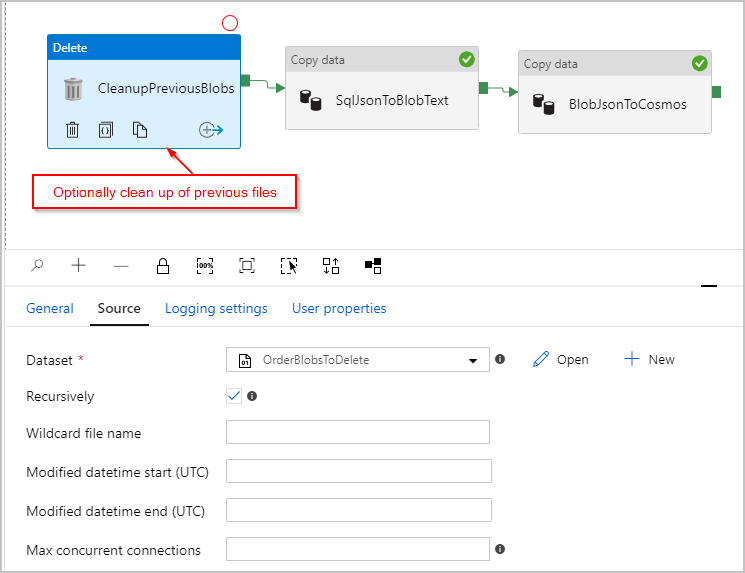
Vi kan också lägga till en "Ta bort"-aktivitet i pipelinen så att alla tidigare filer som finns kvar i mappen /Orders/tas bort före varje körning. Vår ADF-pipeline ser nu ut ungefär så här:
När vi har utlöst pipelinen som nämnts tidigare ser vi en fil som skapats på vår mellanliggande Azure Blob Storage-plats som innehåller ett JSON-objekt per rad:
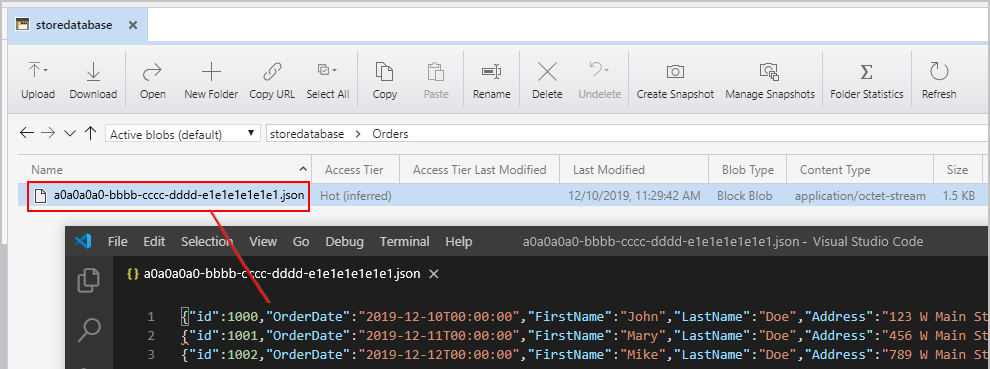
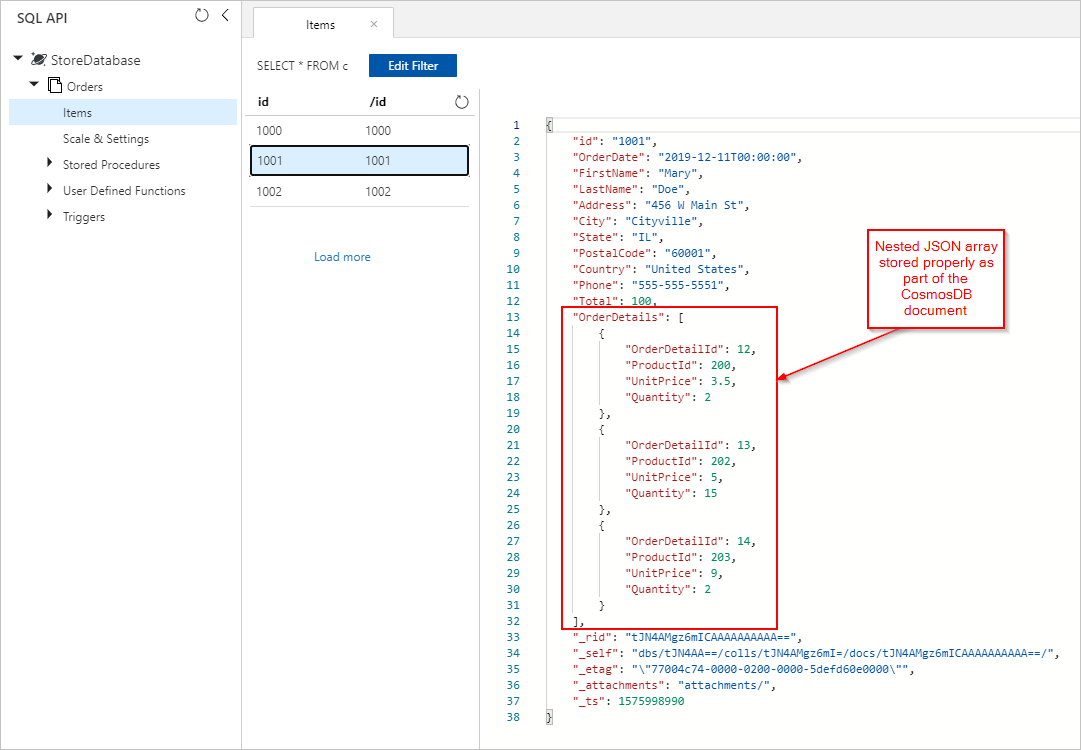
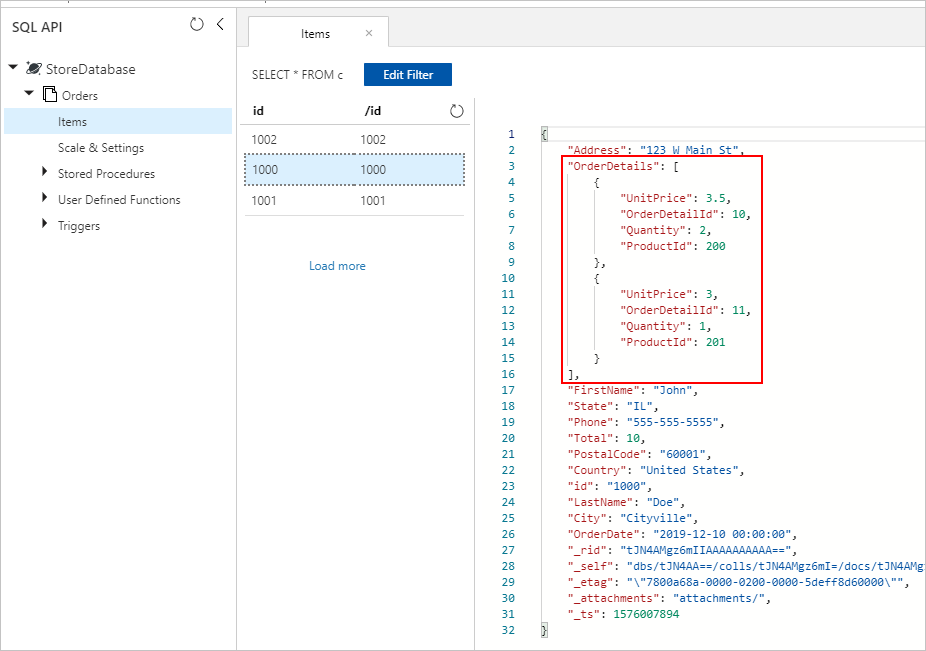
Vi ser även Order-dokument med korrekt inbäddade OrderDetails infogade i vår Azure Cosmos DB-samling:
Azure Databricks
Vi kan också använda Spark i Azure Databricks för att kopiera data från vår SQL Database-källa till Azure Cosmos DB-målet utan att skapa mellanliggande text/JSON-filer i Azure Blob Storage.
Kommentar
För tydlighetens skull och enkelhet innehåller kodfragmenten dummydatabaslösenord uttryckligen infogade, men du bör helst använda Azure Databricks-hemligheter.
Först skapar och kopplar vi nödvändiga SQL-anslutningsappar och Azure Cosmos DB-anslutningsbibliotek till vårt Azure Databricks-kluster. Starta om klustret för att se till att biblioteken läses in.

Därefter presenterar vi två exempel för Scala och Python.
Scala
Här får vi resultatet av SQL-frågan med "FOR JSON"-utdata till en DataFrame:
// Connect to Azure SQL /connectors/sql/
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val configSql = Config(Map(
"url" -> "xxxx.database.windows.net",
"databaseName" -> "xxxx",
"queryCustom" -> "SELECT o.OrderID, o.OrderDate, o.FirstName, o.LastName, o.Address, o.City, o.State, o.PostalCode, o.Country, o.Phone, o.Total, (SELECT OrderDetailId, ProductId, UnitPrice, Quantity FROM OrderDetails od WHERE od.OrderId = o.OrderId FOR JSON AUTO) as OrderDetails FROM Orders o",
"user" -> "xxxx",
"password" -> "xxxx" // NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
))
// Create DataFrame from Azure SQL query
val orders = sqlContext.read.sqlDB(configSql)
display(orders)
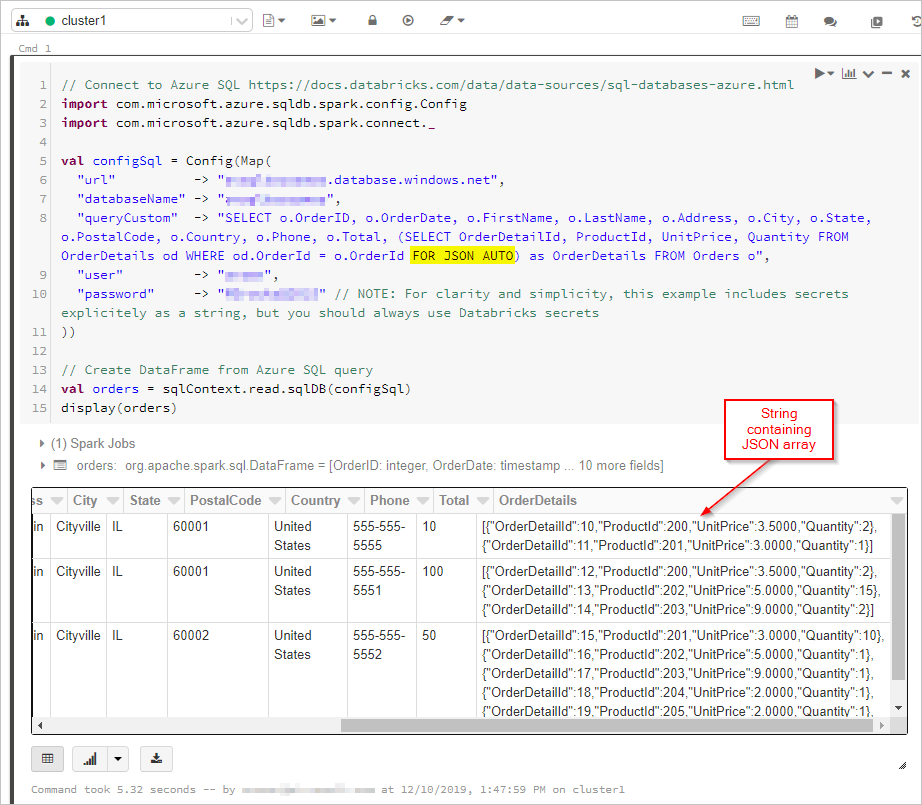
Därefter ansluter vi till vår Azure Cosmos DB-databas och -samling:
// Connect to Azure Cosmos DB https://docs.databricks.com/data/data-sources/azure/cosmosdb-connector.html
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
import org.joda.time._
import org.joda.time.format._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.CosmosDBSpark
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.apache.spark.sql.functions._
val configMap = Map(
"Endpoint" -> "https://xxxx.documents.azure.com:443/",
// NOTE: For clarity and simplicity, this example includes secrets explicitely as a string, but you should always use Databricks secrets
"Masterkey" -> "xxxx",
"Database" -> "StoreDatabase",
"Collection" -> "Orders")
val configAzure Cosmos DB= Config(configMap)
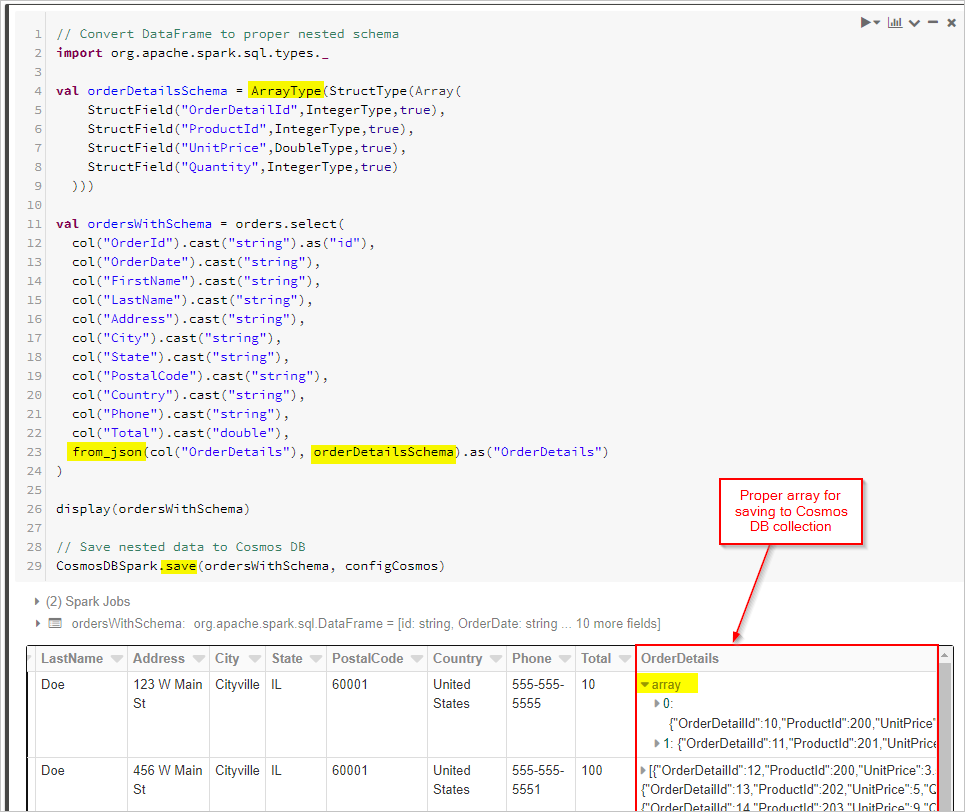
Slutligen definierar vi vårt schema och använder from_json för att tillämpa DataFrame innan vi sparar det i Cosmos DB-samlingen.
// Convert DataFrame to proper nested schema
import org.apache.spark.sql.types._
val orderDetailsSchema = ArrayType(StructType(Array(
StructField("OrderDetailId",IntegerType,true),
StructField("ProductId",IntegerType,true),
StructField("UnitPrice",DoubleType,true),
StructField("Quantity",IntegerType,true)
)))
val ordersWithSchema = orders.select(
col("OrderId").cast("string").as("id"),
col("OrderDate").cast("string"),
col("FirstName").cast("string"),
col("LastName").cast("string"),
col("Address").cast("string"),
col("City").cast("string"),
col("State").cast("string"),
col("PostalCode").cast("string"),
col("Country").cast("string"),
col("Phone").cast("string"),
col("Total").cast("double"),
from_json(col("OrderDetails"), orderDetailsSchema).as("OrderDetails")
)
display(ordersWithSchema)
// Save nested data to Azure Cosmos DB
CosmosDBSpark.save(ordersWithSchema, configCosmos)
Python
Som en alternativ metod kan du behöva köra JSON-transformeringar i Spark om källdatabasen inte stöder FOR JSON eller en liknande åtgärd. Du kan också använda parallella åtgärder för en stor datamängd. Här presenterar vi ett PySpark-exempel. Börja med att konfigurera käll- och måldatabasanslutningarna i den första cellen:
import uuid
import pyspark.sql.functions as F
from pyspark.sql.functions import col
from pyspark.sql.types import StringType,DateType,LongType,IntegerType,TimestampType
#JDBC connect details for SQL Server database
jdbcHostname = "jdbcHostname"
jdbcDatabase = "OrdersDB"
jdbcUsername = "jdbcUsername"
jdbcPassword = "jdbcPassword"
jdbcPort = "1433"
connectionProperties = {
"user" : jdbcUsername,
"password" : jdbcPassword,
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, jdbcUsername, jdbcPassword)
#Connect details for Target Azure Cosmos DB for NoSQL account
writeConfig = {
"Endpoint": "Endpoint",
"Masterkey": "Masterkey",
"Database": "OrdersDB",
"Collection": "Orders",
"Upsert": "true"
}
Sedan frågar vi källdatabasen (i det här fallet SQL Server) efter både order- och orderinformationsposterna och placerar resultatet i Spark Dataframes. Vi skapar också en lista som innehåller alla order-ID:t och en trådpool för parallella åtgärder:
import json
import ast
import pyspark.sql.functions as F
import uuid
import numpy as np
import pandas as pd
from functools import reduce
from pyspark.sql import SQLContext
from pyspark.sql.types import *
from pyspark.sql import *
from pyspark.sql.functions import exp
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.functions import array
from pyspark.sql.types import *
from multiprocessing.pool import ThreadPool
#get all orders
orders = sqlContext.read.jdbc(url=jdbcUrl, table="orders", properties=connectionProperties)
#get all order details
orderdetails = sqlContext.read.jdbc(url=jdbcUrl, table="orderdetails", properties=connectionProperties)
#get all OrderId values to pass to map function
orderids = orders.select('OrderId').collect()
#create thread pool big enough to process merge of details to orders in parallel
pool = ThreadPool(10)
Skapa sedan en funktion för att skriva Beställningar till mål-API:et för NoSQL-samlingen. Den här funktionen filtrerar all orderinformation för det angivna order-ID:t, konverterar dem till en JSON-matris och infogar matrisen i ett JSON-dokument. JSON-dokumentet skrivs sedan till mål-API:et för NoSQL-containern för den ordern:
def writeOrder(orderid):
#filter the order on current value passed from map function
order = orders.filter(orders['OrderId'] == orderid[0])
#set id to be a uuid
order = order.withColumn("id", lit(str(uuid.uuid1())))
#add details field to order dataframe
order = order.withColumn("details", lit(''))
#filter order details dataframe to get details we want to merge into the order document
orderdetailsgroup = orderdetails.filter(orderdetails['OrderId'] == orderid[0])
#convert dataframe to pandas
orderpandas = order.toPandas()
#convert the order dataframe to json and remove enclosing brackets
orderjson = orderpandas.to_json(orient='records', force_ascii=False)
orderjson = orderjson[1:-1]
#convert orderjson to a dictionaory so we can set the details element with order details later
orderjsondata = json.loads(orderjson)
#convert orderdetailsgroup dataframe to json, but only if details were returned from the earlier filter
if (orderdetailsgroup.count() !=0):
#convert orderdetailsgroup to pandas dataframe to work better with json
orderdetailsgroup = orderdetailsgroup.toPandas()
#convert orderdetailsgroup to json string
jsonstring = orderdetailsgroup.to_json(orient='records', force_ascii=False)
#convert jsonstring to dictionary to ensure correct encoding and no corrupt records
jsonstring = json.loads(jsonstring)
#set details json element in orderjsondata to jsonstring which contains orderdetailsgroup - this merges order details into the order
orderjsondata['details'] = jsonstring
#convert dictionary to json
orderjsondata = json.dumps(orderjsondata)
#read the json into spark dataframe
df = spark.read.json(sc.parallelize([orderjsondata]))
#write the dataframe (this will be a single order record with merged many-to-one order details) to Azure Cosmos DB db using spark the connector
#https://learn.microsoft.com/azure/cosmos-db/spark-connector
df.write.format("com.microsoft.azure.cosmosdb.spark").mode("append").options(**writeConfig).save()
Slutligen anropar vi Python-funktionen writeOrder med hjälp av en kartfunktion i trådpoolen för att köra parallellt och skicka in listan över order-ID:t som vi skapade tidigare:
#map order details to orders in parallel using the above function
pool.map(writeOrder, orderids)
I båda förhållningssätten bör vi i slutet få korrekt sparade inbäddade OrderDetails i varje Order-dokument i Azure Cosmos DB-samlingen:
Nästa steg
- Lär dig mer om datamodellering i Azure Cosmos DB
- Lär dig hur du modellerar och partitioner data i Azure Cosmos DB