Hantera indexeringsprinciper i Azure Cosmos DB
I Azure Cosmos DB indexeras data efter indexeringsprinciper som definieras för varje container. Standardprincipen för indexering för nyligen skapade containrar framtvingar intervallindex för strängar eller nummer. Du kan åsidosätta den här principen med din egen anpassade indexeringsprincip.
Kommentar
Metoden för att uppdatera indexeringsprinciper som beskrivs i den här artikeln gäller endast för Azure Cosmos DB för NoSQL. Lär dig mer om indexering i Azure Cosmos DB för MongoDB och sekundär indexering i Azure Cosmos DB för Apache Cassandra.
Exempel på indexeringsprincip
Här är några exempel på indexeringsprinciper som visas i deras JSON-format. De exponeras på Azure Portal i JSON-format. Samma parametrar kan anges via Azure CLI eller valfri SDK.
Avregistrera principen för att selektivt exkludera vissa egenskapssökvägar
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/path/to/single/excluded/property/?"
},
{
"path": "/path/to/root/of/multiple/excluded/properties/*"
}
]
}
Opt-in-princip för att selektivt inkludera vissa egenskapssökvägar
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/path/to/included/property/?"
},
{
"path": "/path/to/root/of/multiple/included/properties/*"
}
],
"excludedPaths": [
{
"path": "/*"
}
]
}
Kommentar
Vi rekommenderar vanligtvis att du använder en princip för att välja bort indexering. Azure Cosmos DB indexerar proaktivt alla nya egenskaper som kan läggas till i din datamodell.
Endast använda ett rumsligt index på en specifik egenskapssökväg
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
}
],
"spatialIndexes": [
{
"path": "/path/to/geojson/property/?",
"types": [
"Point",
"Polygon",
"MultiPolygon",
"LineString"
]
}
]
}
Principexempel för vektorindexering
Förutom att inkludera eller exkludera sökvägar för enskilda egenskaper kan du även ange ett vektorindex. I allmänhet bör vektorindex anges när VectorDistance systemfunktionen används för att mäta likheten mellan en frågevektor och en vektoregenskap.
Kommentar
Innan du fortsätter måste du aktivera Indexering och sökning av Azure Cosmos DB NoSQL-vektorer.
Viktigt!
En vektorindexeringsprincip måste finnas på samma sökväg som definierats i containerns vektorprincip. Läs mer om principer för containervektorer.
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
},
{
"path": "/vector/*"
}
],
"vectorIndexes": [
{
"path": "/vector",
"type": "quantizedFlat"
}
]
}
Viktigt!
Vektorsökvägen har lagts till i avsnittet "excludedPaths" i indexeringsprincipen för att säkerställa optimerad prestanda för infogning. Om du inte lägger till vektorsökvägen till "excludedPaths" resulterar det i högre RU-laddning och svarstid för vektorinfogningar.
Viktigt!
För närvarande är vektorprinciper och vektorindex oföränderliga när de har skapats. Skapa en ny samling för att göra ändringar.
Du kan definiera följande typer av vektorindexprinciper:
| Typ | Beskrivning | Maximalt antal dimensioner |
|---|---|---|
flat |
Lagrar vektorer i samma index som andra indexerade egenskaper. | 505 |
quantizedFlat |
Kvantifierar (komprimerar) vektorer innan de lagras i indexet. Detta kan förbättra svarstiden och dataflödet på bekostnad av en liten mängd noggrannhet. | 4096 |
diskANN |
Skapar ett index baserat på DiskANN för snabb och effektiv ungefärlig sökning. | 4096 |
Indextyperna flat och quantizedFlat använder Azure Cosmos DB:s index för att lagra och läsa varje vektor när du utför en vektorsökning. Vektorsökningar med ett flat index är råstyrkesökningar och ger 100 % noggrannhet. Det finns dock en begränsning av 505 dimensioner för vektorer i ett platt index.
Indexet quantizedFlat lagrar kvantiserade eller komprimerade vektorer i indexet. Vektorsökningar med quantizedFlat index är också råstyrkesökningar, men deras noggrannhet kan vara något mindre än 100 % eftersom vektorerna kvantifieras innan de läggs till i indexet. Vektorsökningar med quantized flat bör dock ha lägre svarstid, högre dataflöde och lägre RU-kostnad än vektorsökningar i ett flat index. Det här är ett bra alternativ för scenarier där du använder frågefilter för att begränsa vektorsökningen till en relativt liten uppsättning vektorer.
Indexet diskANN är ett separat index som definierats specifikt för vektorer som använder DiskANN, en uppsättning vektorindexeringsalgoritmer med hög prestanda som utvecklats av Microsoft Research. DiskANN-index kan erbjuda några av de lägsta svarstiderna, högsta fråge-per-sekund (QPS) och frågor med lägsta RU-kostnad med hög noggrannhet. Men eftersom DiskANN är ett ungefärligt närmsta grannindex (ANN) kan noggrannheten vara lägre än quantizedFlat eller flat.
Indexen diskANN och quantizedFlat kan ta valfria indexgenereringsparametrar som kan användas för att justera avvägningen mellan noggrannhet och svarstid som gäller för varje ungefärligt vektorindex för närmaste grannar.
quantizationByteSize: Anger storleken (i byte) för produktkvantisering. Min=1, Default=dynamic (systemet bestämmer), Max=512. Om du anger detta större kan det leda till högre precisionsvektorsökningar på bekostnad av högre RU-kostnader och högre svarstid. Detta gäller bådequantizedFlatochDiskANNindextyper.indexingSearchListSize: Anger hur många vektorer som ska sökas över under indexbygget. Min=10, Default=100, Max=500. Om du anger detta större kan det leda till högre noggrannhetsvektorsökningar på bekostnad av längre indexgenereringstider och högre svarstider för vektormatning. Detta gäller endast indexDiskANN.
Exempel på tuppelns indexeringsprincip
I det här exemplet definierar indexeringsprincipen ett tupppelindex för events.name och events.category
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{"path":"/*"},
{"path":"/events/[]/{name,category}/?"}
],
"excludedPaths":[],
"compositeIndexes":[]
}
Ovanstående index används för frågan nedan.
SELECT *
FROM root r
WHERE
EXISTS (SELECT VALUE 1 FROM ev IN r.events
WHERE ev.name = ‘M&M’ AND ev.category = ‘Candy’)
Exempel på sammansatt indexeringsprincip
Förutom att inkludera eller exkludera sökvägar för enskilda egenskaper kan du även ange ett sammansatt index. För att utföra en fråga som har en ORDER BY sats för flera egenskaper krävs ett sammansatt index för dessa egenskaper. Om frågan innehåller filter tillsammans med sortering på flera egenskaper kan du behöva mer än ett sammansatt index.
Sammansatta index har också en prestandafördel för frågor som har flera filter eller både ett filter och en ORDER BY-sats.
Kommentar
Sammansatta sökvägar har en implicit /? eftersom endast det skalära värdet på den sökvägen indexeras. Jokertecknet /* stöds inte i sammansatta sökvägar. Du bör inte ange /? eller /* i en sammansatt sökväg. Sammansatta sökvägar är också skiftlägeskänsliga.
Sammansatt index definierat för (name asc, age desc)
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
Det sammansatta indexet för namn och ålder krävs för följande frågor:
Fråga nr 1:
SELECT *
FROM c
ORDER BY c.name ASC, c.age DESC
Fråga nr 2:
SELECT *
FROM c
ORDER BY c.name DESC, c.age ASC
Det här sammansatta indexet gynnar följande frågor och optimerar filtren:
Fråga nr 3:
SELECT *
FROM c
WHERE c.name = "Tim"
ORDER BY c.name DESC, c.age ASC
Fråga nr 4:
SELECT *
FROM c
WHERE c.name = "Tim" AND c.age > 18
Sammansatt index definierat för (namn ASC, ålder ASC) och (namn ASC, ålder DESC)
Du kan definiera flera sammansatta index inom samma indexeringsprincip.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"ascending"
}
],
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
Sammansatt index definierat för (namn ASC, ålder ASC)
Det är valfritt att ange ordningen. Om den inte anges är ordningen stigande.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name"
},
{
"path":"/age"
}
]
]
}
Exkludera alla egenskapssökvägar men håll indexeringen aktiv
Du kan använda den här principen där TTL-funktionen (Time-to-Live) är aktiv, men inga andra index krävs för att använda Azure Cosmos DB som ett rent nyckelvärdeslager.
{
"indexingMode": "consistent",
"includedPaths": [],
"excludedPaths": [{
"path": "/*"
}]
}
Ingen indexering
Den här principen inaktiverar indexering. Om indexingMode är inställt nonepå kan du inte ange en TTL på containern.
{
"indexingMode": "none"
}
Uppdatera indexeringsprincip
I Azure Cosmos DB kan indexeringsprincipen uppdateras med någon av följande metoder:
- Från Azure-portalen
- Använda Azure CLI
- Med hjälp av PowerShell
- Använda en av SDK:erna
En indexeringsprincipuppdatering utlöser en indextransformering. Förloppet för den här omvandlingen kan också spåras från SDK:erna.
Kommentar
När du uppdaterar indexeringsprincipen avbryts skrivningar till Azure Cosmos DB. Läs mer om indexering av transformeringar.
Viktigt!
Att ta bort ett index börjar gälla omedelbart, medan det tar lite tid att lägga till ett nytt index eftersom det kräver en indexeringstransformering. När du ersätter ett index med ett annat (till exempel ersätta ett enskilt egenskapsindex med ett sammansatt index) måste du lägga till det nya indexet först och sedan vänta tills indextransformeringen har slutförts innan du tar bort det tidigare indexet från indexeringsprincipen. Annars påverkar detta din möjlighet att fråga det tidigare indexet negativt och kan bryta alla aktiva arbetsbelastningar som refererar till det tidigare indexet.
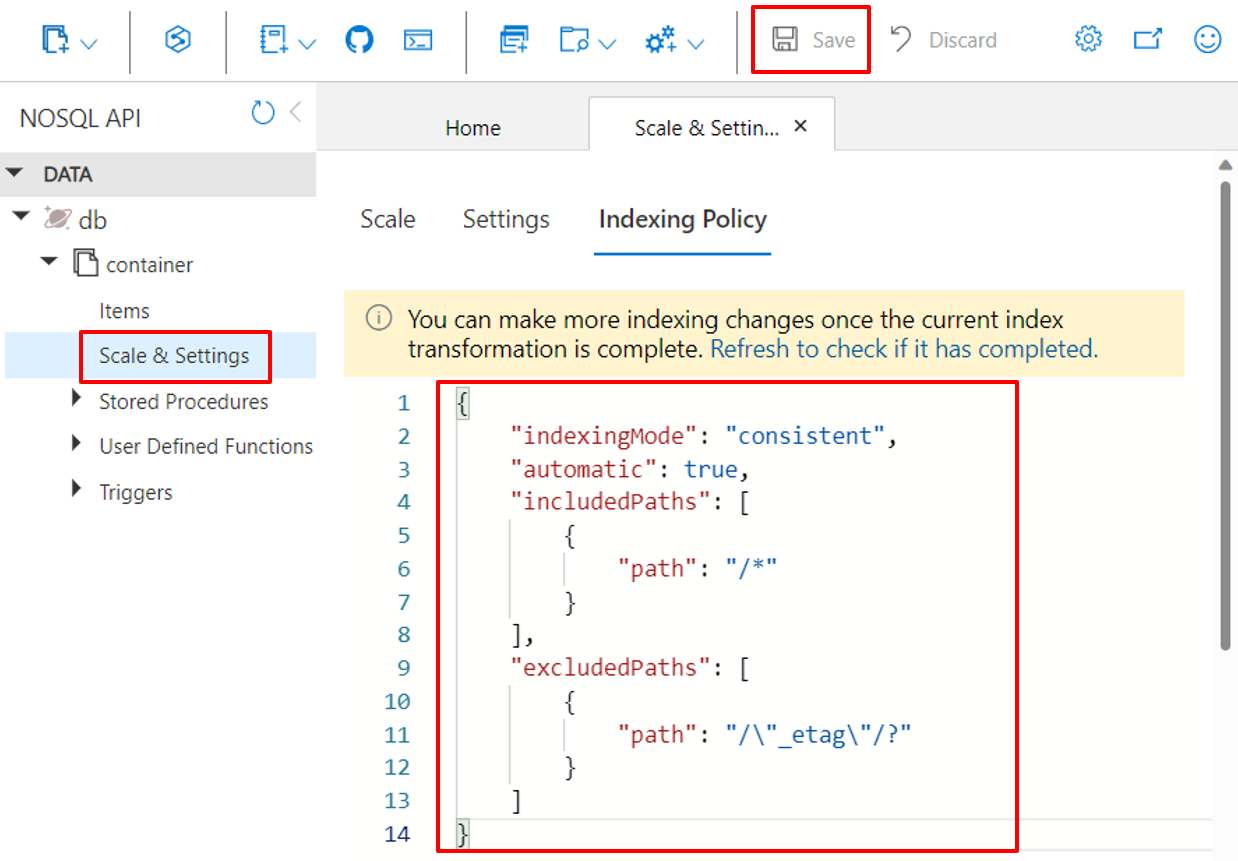
Använda Azure Portal
Azure Cosmos DB-containrar lagrar sin indexeringsprincip som ett JSON-dokument som Azure Portal låter dig redigera direkt.
Logga in på Azure-portalen.
Skapa ett nytt Azure Cosmos DB-konto eller välj ett befintligt konto.
Öppna fönstret Datautforskaren och välj den container som du vill arbeta med.
Välj Skala och inställningar.
Ändra JSON-dokumentet för indexeringsprincip, som du ser i de här exemplen.
Välj Spara när du är klar.
Använda Azure CLI
Information om hur du skapar en container med en anpassad indexeringsprincip finns i Skapa en container med en anpassad indexprincip med CLI.
Använda PowerShell
Information om hur du skapar en container med en anpassad indexeringsprincip finns i Skapa en container med en anpassad indexprincip med PowerShell.
Använda .NET SDK
Objektet ContainerProperties från .NET SDK v3 exponerar en IndexingPolicy egenskap som gör att du kan ändra IndexingMode och lägga till eller ta bort IncludedPaths och ExcludedPaths. Mer information finns i Snabbstart: Azure Cosmos DB för NoSQL-klientbibliotek för .NET.
// Retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync();
// Set the indexing mode to consistent
containerResponse.Resource.IndexingPolicy.IndexingMode = IndexingMode.Consistent;
// Add an included path
containerResponse.Resource.IndexingPolicy.IncludedPaths.Add(new IncludedPath { Path = "/*" });
// Add an excluded path
containerResponse.Resource.IndexingPolicy.ExcludedPaths.Add(new ExcludedPath { Path = "/name/*" });
// Add a spatial index
SpatialPath spatialPath = new SpatialPath
{
Path = "/locations/*"
};
spatialPath.SpatialTypes.Add(SpatialType.Point);
containerResponse.Resource.IndexingPolicy.SpatialIndexes.Add(spatialPath);
// Add a composite index
containerResponse.Resource.IndexingPolicy.CompositeIndexes.Add(new Collection<CompositePath> { new CompositePath() { Path = "/name", Order = CompositePathSortOrder.Ascending }, new CompositePath() { Path = "/age", Order = CompositePathSortOrder.Descending } });
// Update container with changes
await client.GetContainer("database", "container").ReplaceContainerAsync(containerResponse.Resource);
Om du vill spåra indextransformeringens förlopp skickar du ett RequestOptions objekt som anger PopulateQuotaInfo egenskapen till true. Hämta värdet från svarshuvudet x-ms-documentdb-collection-index-transformation-progress .
// retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync(new ContainerRequestOptions { PopulateQuotaInfo = true });
// retrieve the index transformation progress from the result
long indexTransformationProgress = long.Parse(containerResponse.Headers["x-ms-documentdb-collection-index-transformation-progress"]);
Med SDK V3 fluent API kan du skriva den här definitionen på ett koncist och effektivt sätt när du definierar en anpassad indexeringsprincip när du skapar en ny container:
await client.GetDatabase("database").DefineContainer(name: "container", partitionKeyPath: "/myPartitionKey")
.WithIndexingPolicy()
.WithIncludedPaths()
.Path("/*")
.Attach()
.WithExcludedPaths()
.Path("/name/*")
.Attach()
.WithSpatialIndex()
.Path("/locations/*", SpatialType.Point)
.Attach()
.WithCompositeIndex()
.Path("/name", CompositePathSortOrder.Ascending)
.Path("/age", CompositePathSortOrder.Descending)
.Attach()
.Attach()
.CreateIfNotExistsAsync();
Använda Java SDK
Objektet DocumentCollection från Java SDK exponerar getIndexingPolicy() metoderna och setIndexingPolicy() . Med IndexingPolicy det objekt som de manipulerar kan du ändra indexeringsläget och lägga till eller ta bort inkluderade och exkluderade sökvägar. Mer information finns i Snabbstart: Skapa en Java-app för att hantera Azure Cosmos DB för NoSQL-data.
// Retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), null);
containerResponse.subscribe(result -> {
DocumentCollection container = result.getResource();
IndexingPolicy indexingPolicy = container.getIndexingPolicy();
// Set the indexing mode to consistent
indexingPolicy.setIndexingMode(IndexingMode.Consistent);
// Add an included path
Collection<IncludedPath> includedPaths = new ArrayList<>();
IncludedPath includedPath = new IncludedPath();
includedPath.setPath("/*");
includedPaths.add(includedPath);
indexingPolicy.setIncludedPaths(includedPaths);
// Add an excluded path
Collection<ExcludedPath> excludedPaths = new ArrayList<>();
ExcludedPath excludedPath = new ExcludedPath();
excludedPath.setPath("/name/*");
excludedPaths.add(excludedPath);
indexingPolicy.setExcludedPaths(excludedPaths);
// Add a spatial index
Collection<SpatialSpec> spatialIndexes = new ArrayList<SpatialSpec>();
Collection<SpatialType> collectionOfSpatialTypes = new ArrayList<SpatialType>();
SpatialSpec spec = new SpatialSpec();
spec.setPath("/locations/*");
collectionOfSpatialTypes.add(SpatialType.Point);
spec.setSpatialTypes(collectionOfSpatialTypes);
spatialIndexes.add(spec);
indexingPolicy.setSpatialIndexes(spatialIndexes);
// Add a composite index
Collection<ArrayList<CompositePath>> compositeIndexes = new ArrayList<>();
ArrayList<CompositePath> compositePaths = new ArrayList<>();
CompositePath nameCompositePath = new CompositePath();
nameCompositePath.setPath("/name");
nameCompositePath.setOrder(CompositePathSortOrder.Ascending);
CompositePath ageCompositePath = new CompositePath();
ageCompositePath.setPath("/age");
ageCompositePath.setOrder(CompositePathSortOrder.Descending);
compositePaths.add(ageCompositePath);
compositePaths.add(nameCompositePath);
compositeIndexes.add(compositePaths);
indexingPolicy.setCompositeIndexes(compositeIndexes);
// Update the container with changes
client.replaceCollection(container, null);
});
Om du vill spåra indextransformeringens förlopp för en container skickar du ett RequestOptions objekt som begär att kvotinformationen ska fyllas i. Hämta värdet från svarshuvudet x-ms-documentdb-collection-index-transformation-progress .
// set the RequestOptions object
RequestOptions requestOptions = new RequestOptions();
requestOptions.setPopulateQuotaInfo(true);
// retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), requestOptions);
containerResponse.subscribe(result -> {
// retrieve the index transformation progress from the response headers
String indexTransformationProgress = result.getResponseHeaders().get("x-ms-documentdb-collection-index-transformation-progress");
});
Använda Node.js SDK
Gränssnittet ContainerDefinition från Node.js SDK exponerar en indexingPolicy egenskap som gör att du kan ändra indexingMode och lägga till eller ta bort includedPaths och excludedPaths. Mer information finns i Snabbstart – Azure Cosmos DB för NoSQL-klientbibliotek för Node.js.
Hämta containerns information:
const containerResponse = await client.database('database').container('container').read();
Ange indexeringsläget till konsekvent:
containerResponse.body.indexingPolicy.indexingMode = "consistent";
Lägg till inkluderad sökväg, inklusive ett rumsligt index:
containerResponse.body.indexingPolicy.includedPaths.push({
includedPaths: [
{
path: "/age/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.String
},
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.Number
}
]
},
{
path: "/locations/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Spatial,
dataType: cosmos.DocumentBase.DataType.Point
}
]
}
]
});
Lägg till utesluten sökväg:
containerResponse.body.indexingPolicy.excludedPaths.push({ path: '/name/*' });
Uppdatera containern med ändringar:
const replaceResponse = await client.database('database').container('container').replace(containerResponse.body);
Om du vill spåra indextransformeringens förlopp för en container skickar du ett RequestOptions objekt som anger populateQuotaInfo egenskapen till true. Hämta värdet från svarshuvudet x-ms-documentdb-collection-index-transformation-progress .
// retrieve the container's details
const containerResponse = await client.database('database').container('container').read({
populateQuotaInfo: true
});
// retrieve the index transformation progress from the response headers
const indexTransformationProgress = replaceResponse.headers['x-ms-documentdb-collection-index-transformation-progress'];
Lägg till ett sammansatt index:
console.log("create container with composite indexes");
const containerDefWithCompositeIndexes = {
id: "containerWithCompositeIndexingPolicy",
indexingPolicy: {
automatic: true,
indexingMode: IndexingMode.consistent,
includedPaths: [
{
path: "/*",
},
],
excludedPaths: [
{
path: '/"systemMetadata"/*',
},
],
compositeIndexes: [
[
{ path: "/field", order: "ascending" },
{ path: "/key", order: "ascending" },
],
],
},
};
const containerWithCompositeIndexes = (
await database.containers.create(containerDefWithCompositeIndexes)
).container;
Använda Python SDK
När du använder Python SDK V3 hanteras containerkonfigurationen som en ordlista. I den här ordlistan kan du komma åt indexeringsprincipen och alla dess attribut. Mer information finns i Snabbstart: Azure Cosmos DB för NoSQL-klientbibliotek för Python.
Hämta containerns information:
containerPath = 'dbs/database/colls/collection'
container = client.ReadContainer(containerPath)
Ange indexeringsläget till konsekvent:
container['indexingPolicy']['indexingMode'] = 'consistent'
Definiera en indexeringsprincip med en inkluderad sökväg och ett rumsligt index:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"spatialIndexes":[
{"path":"/location/*","types":["Point"]}
],
"includedPaths":[{"path":"/age/*","indexes":[]}],
"excludedPaths":[{"path":"/*"}]
}
Definiera en indexeringsprincip med en undantagen sökväg:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"includedPaths":[{"path":"/*","indexes":[]}],
"excludedPaths":[{"path":"/name/*"}]
}
Lägg till ett sammansatt index:
container['indexingPolicy']['compositeIndexes'] = [
[
{
"path": "/name",
"order": "ascending"
},
{
"path": "/age",
"order": "descending"
}
]
]
Uppdatera containern med ändringar:
response = client.ReplaceContainer(containerPath, container)