Övervaka normaliserade RU/s för en Azure Cosmos DB-container eller ett konto
GÄLLER FÖR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Kassandra
Kassandra ![]() Gremlin
Gremlin ![]() Bord
Bord
Azure Monitor för Azure Cosmos DB innehåller en måttvy för att övervaka ditt konto och skapa instrumentpaneler. Azure Cosmos DB-mått samlas in som standard. Den här funktionen kräver inte att du aktiverar eller konfigurerar något explicit.
Måttdefinition
Måttet Normaliserad RU-förbrukning är ett mått mellan 0 % och 100 % som används för att mäta användningen av etablerat dataflöde i en databas eller container. Måttet genereras med 1 minuts intervall och definieras som den maximala RU/s-användningen i alla partitionsnyckelintervall i tidsintervallet. Varje partitionsnyckelintervall mappas till en fysisk partition och tilldelas lagring av data för ett intervall med möjliga hash-värden. Ju högre den normaliserade RU-procenten är, desto mer har du, i allmänhet, använt ditt etablerade dataflöde. Måttet kan också användas för att visa användningen av enskilda partitionsnyckelintervall i en databas eller container.
Anta till exempel att du har en container där du anger maximalt dataflöde för autoskalning på 20 000 RU/s (skalar mellan 2 000 och 20 000 RU/s) och du har två partitionsnyckelintervall (fysiska partitioner) P1 och P2. Eftersom Azure Cosmos DB distribuerar det etablerade dataflödet lika över alla partitionsnyckelintervall kan P1 och P2 skalas mellan 1 000 och 10 000 RU/s. Anta att P1 inom ett intervall på 1 minut förbrukade 6 000 enheter för begäran och P2 förbrukade 8 000 enheter för begäran. Den normaliserade RU-förbrukningen för P1 är 60 % och 80 % för P2. Den totala normaliserade RU-förbrukningen för hela containern är MAX(60 %, 80 %) = 80 %.
Om du är intresserad av att se förbrukningen för begärandeenheten med ett intervall per sekund, tillsammans med åtgärdstypen, kan du använda opt-in-funktionens diagnostikloggar och köra frågor mot tabellen PartitionKeyRUConsumption . Om du vill få en översikt på hög nivå över den åtgärder och statuskod som ditt program utför på Azure Cosmos DB-resursen kan du använda det inbyggda måttet Totalt antal Azure Monitor-begäranden (API för NoSQL), Mongo-begäranden, Gremlin-begäranden eller Cassandra-begäranden. Senare kan du filtrera på dessa begäranden efter statuskoden 429 och dela upp dem efter åtgärdstyp.
Vad du kan förvänta dig och göra när normaliserade RU/s är högre
När den normaliserade RU-förbrukningen når 100 % för angivet partitionsnyckelintervall, och om en klient fortfarande gör begäranden i tidsfönstret på 1 sekund till det specifika partitionsnyckelintervallet , får den ett hastighetsbegränsad fel (429).
Detta betyder inte nödvändigtvis att det finns ett problem med din resurs. Som standard försöker Azure Cosmos DB-klient-SDK:er och dataimportverktyg som Azure Data Factory och massexekutorbiblioteket automatiskt begäranden på 429:or. De försöker igen vanligtvis upp till 9 gånger. Även om du kan se 429:e i måtten kanske dessa fel inte ens har returnerats till ditt program.
Om du ser mellan 1–5 % av begäranden med 429-fel för en produktionsarbetsbelastning och svarstiden från slutpunkt till slutpunkt är acceptabel, är detta i allmänhet ett gott tecken på att RU/s används fullt ut. I det här fallet innebär det normaliserade RU-förbrukningsmåttet som når 100 % bara att minst ett partitionsnyckelintervall använde allt sitt etablerade dataflöde under en viss sekund. Detta är acceptabelt eftersom den totala 429-felfrekvensen fortfarande är låg. Ingen ytterligare åtgärd krävs.
Om du vill ta reda på vilken procent av dina begäranden till databasen eller containern som resulterade i 429:or går du till Insights>Requests>Total Requests by Status Code (Totalt antal begäranden per statuskod) från bladet Azure Cosmos DB-konto. Filtrera till en specifik databas och container. För API för Gremlin använder du måttet Gremlin-begäranden .
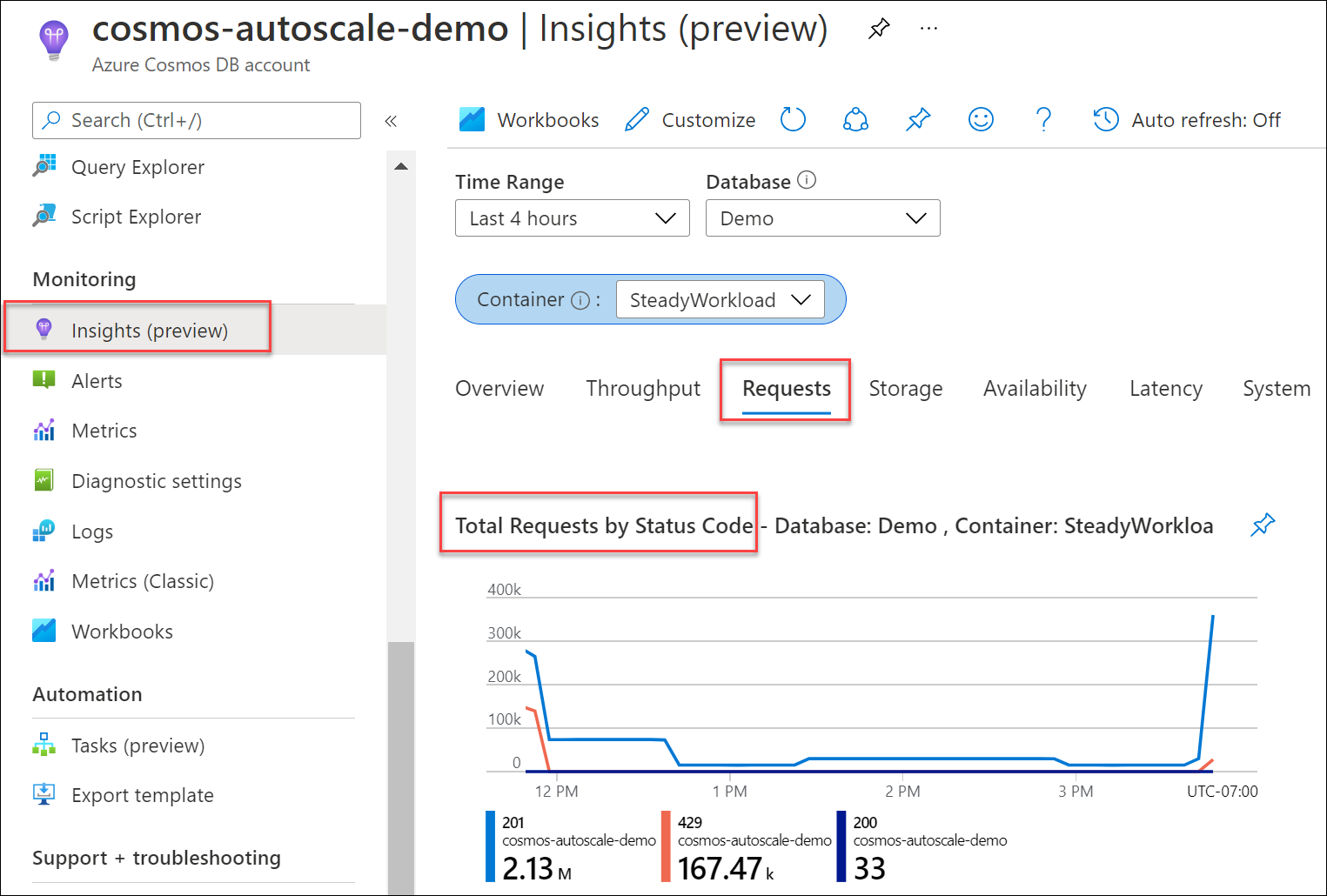
Om det normaliserade RU-förbrukningsmåttet konsekvent är 100 % över flera partitionsnyckelintervall och 429-talets hastighet är större än 5 % rekommenderar vi att du ökar dataflödet. Du kan ta reda på vilka åtgärder som är krävande och vad deras högsta användning är med hjälp av Azure-övervakningsmått och Azure-diagnostikloggar. Se Metodtips för skalning av etablerat dataflöde (RU/s).
Det är inte alltid så att du ser ett 429-hastighetsbegränsningsfel bara för att den normaliserade RU:en har nått 100 %. Det beror på att den normaliserade RU:en är ett enda värde som representerar den maximala användningen över alla partitionsnyckelintervall. Ett partitionsnyckelintervall kan vara upptaget, men de andra partitionsnyckelintervallen kan hantera begäranden utan problem. En enskild åtgärd, till exempel en lagrad procedur som förbrukar alla RU/s i ett partitionsnyckelintervall, leder till en kort topp i det normaliserade RU-förbrukningsmåttet. I sådana fall kommer det inte att finnas några omedelbara hastighetsbegränsningsfel om den övergripande begärandefrekvensen är låg eller begäranden görs till andra partitioner på olika partitionsnyckelintervall.
Läs mer om hur du tolkar och felsöker 429-fel om hastighetsbegränsning.
Så här övervakar du för frekventa partitioner
Det normaliserade RU-förbrukningsmåttet kan användas för att övervaka om din arbetsbelastning har en frekvent partition. En frekvent partition uppstår när en eller några logiska partitionsnycklar förbrukar en oproportionerlig mängd av det totala antalet RU/s på grund av en högre begärandevolym. Detta kan orsakas av en partitionsnyckeldesign som inte distribuerar begäranden jämnt. Det resulterar i att många begäranden dirigeras till en liten delmängd av logiska partitioner (vilket innebär partitionsnyckelintervall) som blir "heta". Eftersom alla data för en logisk partition finns på ett partitionsnyckelintervall och totalt antal RU/s fördelas jämnt mellan alla partitionsnyckelintervall kan en frekvent partition leda till 429-tal och ineffektiv användning av dataflödet.
Så här identifierar du om det finns en frekvent partition
Om du vill kontrollera om det finns en frekvent partition går du till Insights>Dataflöde>Normaliserad RU-förbrukning (%) av PartitionKeyRangeID. Filtrera till en specifik databas och container.
Varje PartitionKeyRangeId mappar till en fysisk partition. Om det finns ett PartitionKeyRangeId som har betydligt högre normaliserad RU-förbrukning än andra (till exempel en är konsekvent på 100 %, men andra är på 30 % eller mindre), kan detta vara ett tecken på en frekvent partition.
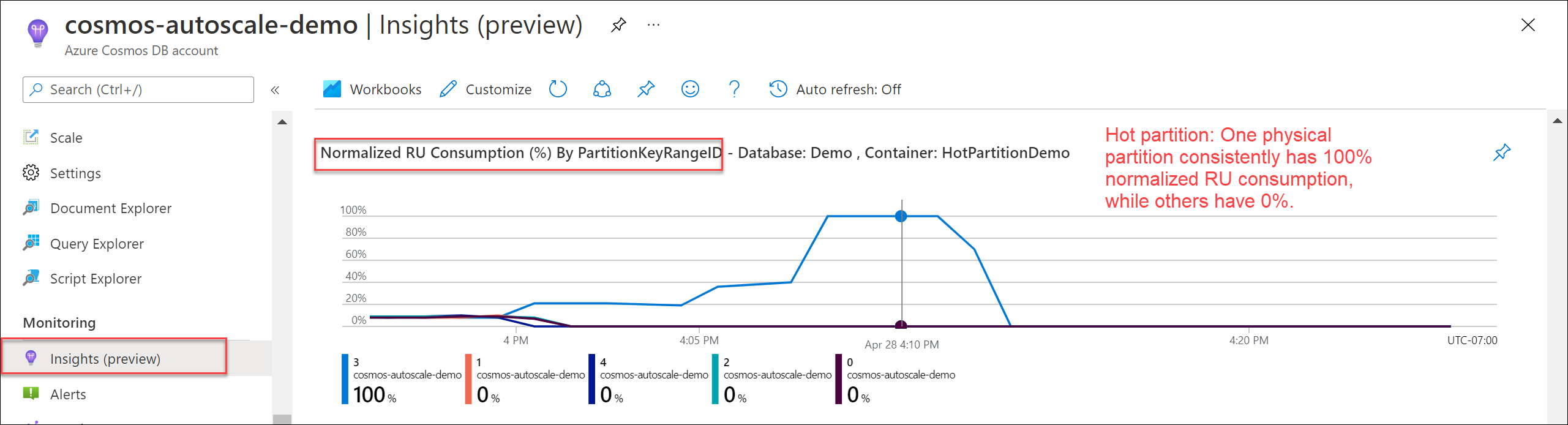
Information om de logiska partitioner som förbrukar mest RU/s samt rekommenderade lösningar finns i artikeln Diagnostisera och felsöka Azure Cosmos DB-begärandefrekvens för stora (429) undantag.
Normaliserad RU-förbrukning och autoskalning
Det normaliserade RU-förbrukningsmåttet visas som 100 % om minst 1 partitionsnyckelintervall använder alla sina allokerade RU/s under en viss sekund i tidsintervallet. En vanlig fråga som uppstår är varför normaliserad RU-förbrukning är 100 %, men Azure Cosmos DB skalade inte RU/s till maximalt dataflöde med autoskalning?
Kommentar
Informationen nedan beskriver den aktuella implementeringen av autoskalning och kan komma att ändras i framtiden.
När du använder autoskalning skalar Azure Cosmos DB bara RU/s till det maximala dataflödet när den normaliserade RU-förbrukningen är 100 % under en kontinuerlig och kontinuerlig tidsperiod i ett intervall på 5 sekunder. Detta görs för att säkerställa att skalningslogiken är kostnadsvänlig för användaren, eftersom den säkerställer att enskilda, momentära toppar inte leder till onödig skalning och högre kostnad. När det finns momentära toppar skalar systemet vanligtvis upp till ett värde som är högre än de tidigare skalade till RU/s, men lägre än max-RU/s.
Anta till exempel att du har en container med maximalt dataflöde för automatisk skalning på 20 000 RU/s (skalar mellan 2 000 och 20 000 RU/s) och 2 partitionsnyckelintervall. Varje partitionsnyckelintervall kan skalas mellan 1 000 och 10 000 RU/s. Eftersom autoskalning etablerar alla nödvändiga resurser i förväg kan du använda upp till 20 000 RU/s när som helst. Anta att du har en tillfällig trafiktoppar, där användningen av ett av partitionsnyckelintervallen under en sekund är 10 000 RU/s. Under efterföljande sekunder återgår användningen till 1 000 RU/s. Eftersom normaliserat RU-förbrukningsmått visar den högsta användningen under tidsperioden för alla partitioner visas 100 %. Men eftersom användningen bara var 100 % i 1 sekund skalas inte autoskalningen automatiskt till max.
Det gjorde att även om autoskalningen inte skalades till det maximala, kunde du fortfarande använda det totala antalet tillgängliga RU/s. Om du vill verifiera ru/s-förbrukningen kan du använda opt-in-funktionens diagnostikloggar för att fråga efter den totala RU/s-förbrukningen på en nivå per sekund i alla partitionsnyckelintervall.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= (todatetime('2022-01-28T20:35:00Z')) and TimeGenerated <= todatetime('2022-01-28T20:40:00Z')
| where DatabaseName == "MyDatabase" and CollectionName == "MyContainer"
| summarize sum(RequestCharge) by bin(TimeGenerated, 1sec), PartitionKeyRangeId
| render timechart
I allmänhet för en produktionsarbetsbelastning med autoskalning, om du ser mellan 1–5 % av begäranden med 429-enheter och din svarstid från slutpunkt till slutpunkt är acceptabelt, är detta ett felfritt tecken på att RU/s används fullt ut. Även om den normaliserade RU-förbrukningen ibland når 100 % och autoskalningen inte skalas upp till max RU/s, är detta ok eftersom den totala frekvensen på 429 är låg. Ingen åtgärd krävs.
Dricks
Om du använder autoskalning och upptäcker att normaliserad RU-förbrukning konsekvent är 100 % och du konsekvent skalas till maximalt antal RU/s, är detta ett tecken på att det kan vara mer kostnadseffektivt att använda manuellt dataflöde. Information om huruvida autoskalning eller manuellt dataflöde är bäst för din arbetsbelastning finns i hur du väljer mellan standarddataflöde (manuell) och autoskalning. Azure Cosmos DB skickar också Azure Advisor-rekommendationer baserat på dina arbetsbelastningsmönster för att rekommendera antingen manuellt dataflöde eller autoskalningsdataflöde.
Visa måttet för normaliserad enhetsförbrukning för begäran
Logga in på Azure-portalen.
Välj Övervaka i det vänstra navigeringsfältet och välj Mått.
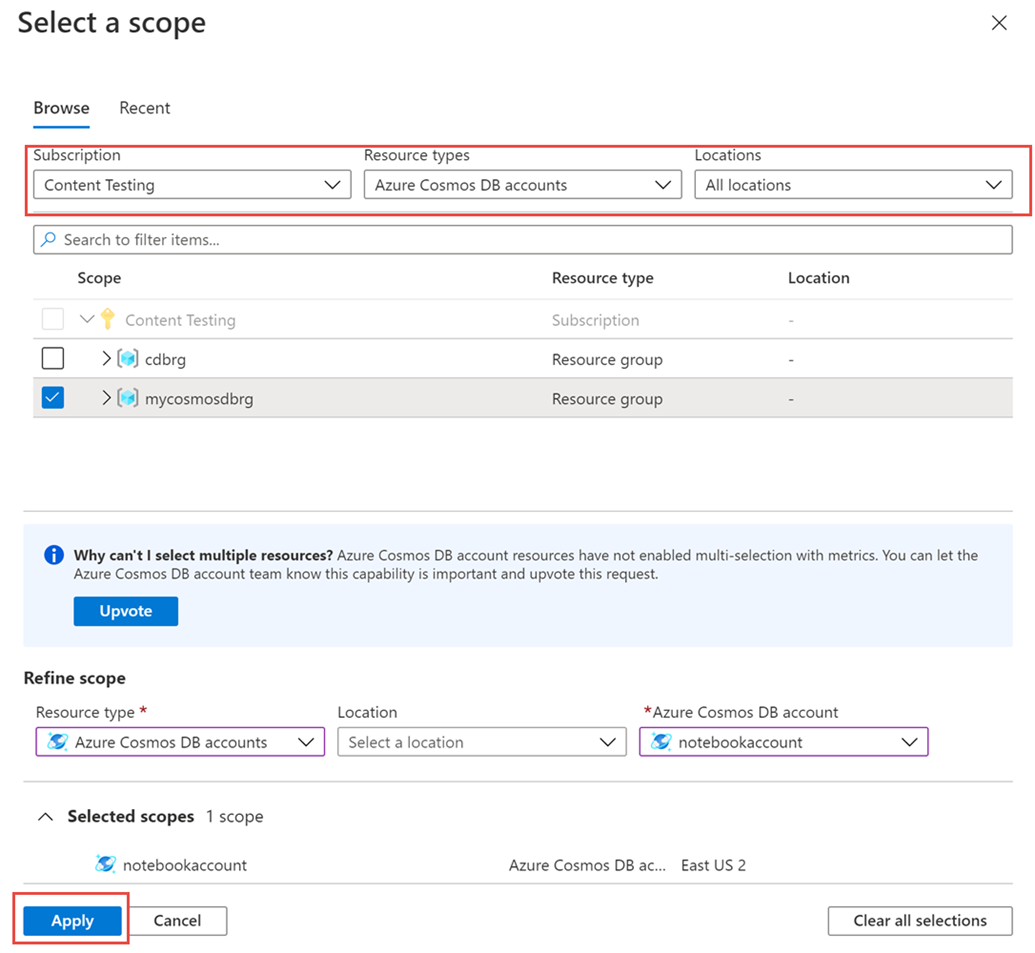
I fönstret >Mått Välj en resurs> väljer du den prenumeration som krävs och resursgruppen. Som Resurstyp väljer du Azure Cosmos DB-konton, väljer ett av dina befintliga Azure Cosmos DB-konton och väljer Tillämpa.
Därefter kan du välja ett mått i listan över tillgängliga mått. Du kan välja mått som är specifika för enheter för begäranden, lagring, svarstid, tillgänglighet, Cassandra och andra. Mer information om alla tillgängliga mått i den här listan finns i artikeln Mått efter kategori . I det här exemplet ska vi välja Normaliserat RU-förbrukningsmått och Max som aggregeringsvärde.
Förutom den här informationen kan du också välja tidsintervall och tidskornighet för måtten. Högst kan du visa mått för de senaste 30 dagarna. När du har tillämpat filtret visas ett diagram baserat på ditt filter.
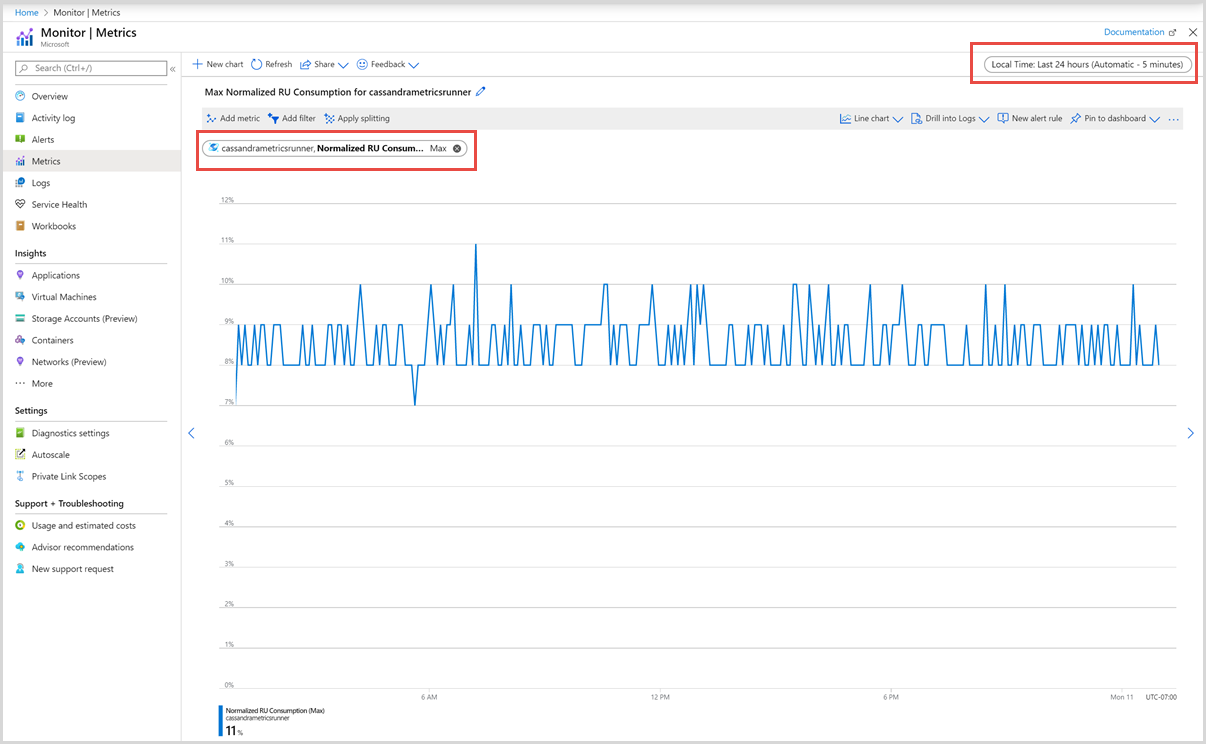
Filter för normaliserat RU-förbrukningsmått
Du kan också filtrera mått och diagrammet som visas av ett specifikt CollectionName, DatabaseName, PartitionKeyRangeID och Region. Om du vill filtrera måtten väljer du Lägg till filter och väljer den egenskap som krävs, till exempel CollectionName och motsvarande värde som du är intresserad av. Diagrammet visar sedan det normaliserade RU-förbrukningsmåttet för containern för den valda perioden.
Du kan gruppera mått med hjälp av alternativet Tillämpa delning . För databaser med delat dataflöde visar det normaliserade RU-måttet endast data i databasens kornighet, det visar inga data per samling. Så för databasen för delat dataflöde ser du inga data när du använder delning efter samlingsnamn.
Måttet för normaliserad enhetsförbrukning för begäranden för varje container visas enligt följande bild:

Nästa steg
- Övervaka Azure Cosmos DB-data med hjälp av diagnostikinställningar i Azure.
- Granska azure Cosmos DB-kontrollplansåtgärder
- Diagnostisera och felsöka för stora undantag (429) för Azure Cosmos DB-begärandefrekvens