Hämtningsförhöjd generation (RAG) med vCore-baserad Azure Cosmos DB för MongoDB
I den snabbt växande sfären av generativ AI har stora språkmodeller (LLM: er) som GPT-3.5 omvandlat bearbetning av naturligt språk. En ny trend inom AI är dock användningen av vektorlager, som spelar en avgörande roll för att förbättra AI-program.
I den här självstudien beskrivs hur du använder Azure Cosmos DB for MongoDB (vCore), LangChain och OpenAI för att implementera RAG (Retrieval-Augmented Generation) för överlägsen AI-prestanda tillsammans med att diskutera LLM:er och deras begränsningar. Vi utforskar det snabbt antagna paradigmet "retrieveal-augmented generation" (RAG) och diskuterar kort LangChain-ramverket, Azure OpenAI-modeller. Slutligen integrerar vi dessa begrepp i ett verkligt program. I slutet kommer läsarna att ha en gedigen förståelse för dessa begrepp.
Förstå stora språkmodeller (LLM) och deras begränsningar
Stora språkmodeller (LLM) är avancerade djup neurala nätverksmodeller som tränats på omfattande textdatauppsättningar, vilket gör det möjligt för dem att förstå och generera mänsklig text. Även om de är revolutionerande inom bearbetning av naturligt språk har LLM:er inneboende begränsningar:
- Hallucinationer: LLM:er genererar ibland faktamässigt felaktig eller ogrundad information, känd som "hallucinationer".
- Inaktuella data: LLM:er tränas på statiska datamängder som kanske inte innehåller den senaste informationen, vilket begränsar deras aktuella relevans.
- Ingen åtkomst till användarens lokala data: LLM:er har inte direkt åtkomst till personliga eller lokaliserade data, vilket begränsar deras möjlighet att tillhandahålla anpassade svar.
- Tokengränser: LLM:er har en maximal tokengräns per interaktion, vilket begränsar mängden text som de kan bearbeta samtidigt. Till exempel har OpenAI:s gpt-3.5-turbo en tokengräns på 4 096.
Utnyttja hämtningsförhöjd generation (RAG)
RAG (Retrieval Augmented Generation) är en arkitektur som är utformad för att övervinna LLM-begränsningar. RAG använder vektorsökning för att hämta relevanta dokument baserat på en indatafråga, vilket ger dessa dokument som kontext till LLM för att generera mer exakta svar. I stället för att enbart förlita sig på förträrade mönster förbättrar RAG svar genom att införliva uppdaterad, relevant information. Den här metoden hjälper dig att:
- Minimera hallucinationer: Grunda svar i faktainformation.
- Se till aktuell information: Hämtar de senaste data för att säkerställa uppdaterade svar.
- Använda externa databaser: Även om det inte ger direkt åtkomst till personuppgifter tillåter RAG integrering med externa, användarspecifika kunskapsbas.
- Optimera tokenanvändning: Genom att fokusera på de mest relevanta dokumenten gör RAG tokenanvändningen mer effektiv.
Den här självstudien visar hur RAG kan implementeras med hjälp av Azure Cosmos DB for MongoDB (vCore) för att skapa ett frågesvarsprogram som är skräddarsytt för dina data.
Översikt över programarkitektur
Arkitekturdiagrammet nedan illustrerar huvudkomponenterna i vår RAG-implementering:
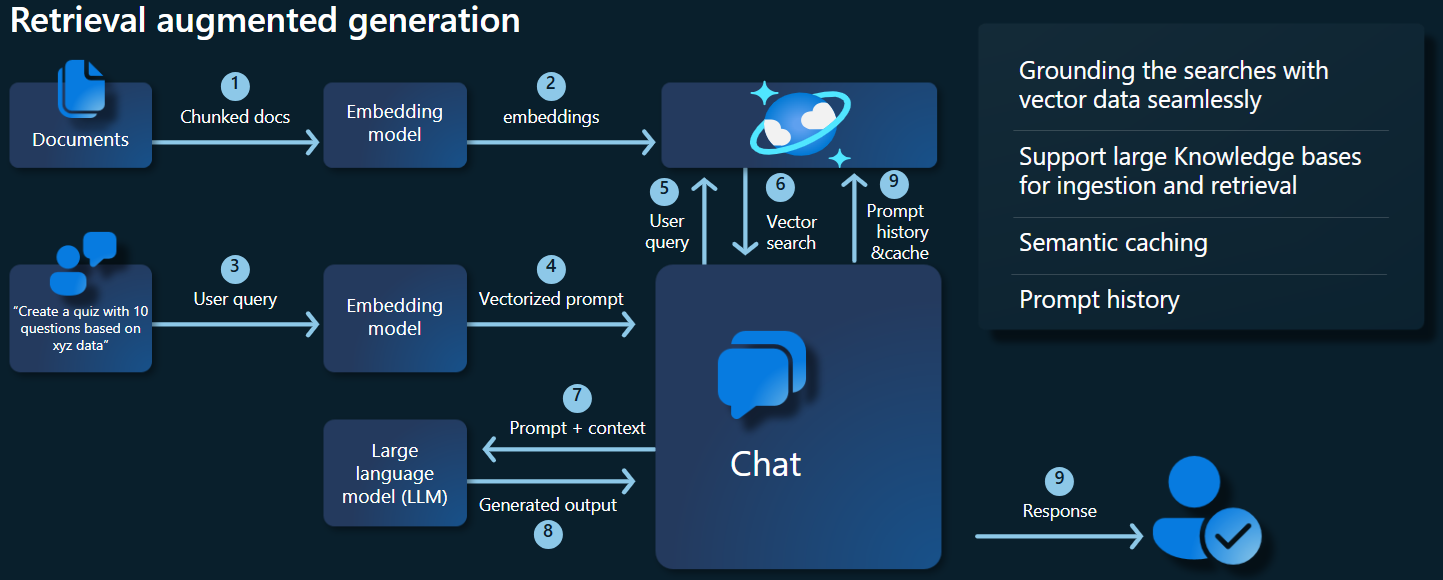
Viktiga komponenter och ramverk
Nu ska vi diskutera de olika ramverk, modeller och komponenter som används i den här självstudien och betona deras roller och nyanser.
Azure Cosmos DB för MongoDB (virtuell kärna)
Azure Cosmos DB for MongoDB (vCore) stöder semantiska likhetssökningar, vilket är viktigt för AI-baserade program. Det gör att data i olika format kan representeras som inbäddningar av vektorer, som kan lagras tillsammans med källdata och metadata. Med hjälp av en ungefärlig närmaste grannalgoritm, till exempel Hierarkisk navigeringsbar liten värld (HNSW), kan dessa inbäddningar efterfrågas för snabba semantiska likhetssökningar.
LangChain-ramverk
LangChain förenklar skapandet av LLM-program genom att tillhandahålla ett standardgränssnitt för kedjor, flera verktygsintegreringar och kedjor från slutpunkt till slutpunkt för vanliga uppgifter. Det gör det möjligt för AI-utvecklare att skapa LLM-program som utnyttjar externa datakällor.
Viktiga aspekter av LangChain:
- Kedjor: Sekvenser av komponenter som löser specifika uppgifter.
- Komponenter: Moduler som LLM-omslutningar, omslutning av vektorlager, promptmallar, datainläsare, textdelare och hämtningar.
- Modularitet: Förenklar utveckling, felsökning och underhåll.
- Popularitet: Ett projekt med öppen källkod som snabbt börjar implementeras och utvecklas för att uppfylla användarnas behov.
Azure App Services-gränssnitt
Apptjänster ger en robust plattform för att skapa användarvänliga webbgränssnitt för Gen-AI-program. I den här självstudien används Azure App Services för att skapa ett interaktivt webbgränssnitt för programmet.
OpenAI-modeller
OpenAI är ledande inom AI-forskning och tillhandahåller olika modeller för språkgenerering, textvektorisering, bildskapande och konvertering från ljud till text. I den här självstudien använder vi OpenAI:s inbäddnings- och språkmodeller, som är avgörande för att förstå och generera språkbaserade program.
Inbäddningsmodeller jämfört med språkgenereringsmodeller
| Kategori | Inbäddningsmodell för text | Språkmodell |
|---|---|---|
| Syfte | Konvertera text till vektorbäddningar. | Förstå och generera naturligt språk. |
| Funktion | Omvandlar textdata till högdimensionella matriser med tal, vilket samlar in textens semantiska innebörd. | Förstå och producerar människoliknande text baserat på angivna indata. |
| Output | Matris med tal (vektorbäddningar). | Text, svar, översättningar, kod osv. |
| Exempel på utdata | Varje inbäddning representerar den semantiska innebörden av texten i numerisk form, med en dimensionalitet som bestäms av modellen. Genererar till exempel text-embedding-ada-002 vektorer med 1 536 dimensioner. |
Sammanhangsmässigt relevant och sammanhängande text som genereras baserat på de indata som tillhandahålls. Kan till exempel gpt-3.5-turbo generera svar på frågor, översätta text, skriva kod med mera. |
| Vanliga användningsfall | - Semantisk sökning | - Chattrobotar |
| – Rekommendationssystem | – Automatiserat skapande av innehåll | |
| – Klustring och klassificering av textdata | - Språköversättning | |
| -Informationssökning | -Sammanfattas | |
| Datarepresentation | Numerisk representation (inbäddningar) | Text på naturligt språk |
| Dimensionerna | Matrisens längd motsvarar antalet dimensioner i inbäddningsutrymmet, till exempel 1 536 dimensioner. | Representeras vanligtvis som en sekvens av token, där kontexten bestämmer längden. |
Huvudkomponenterna i programmet
- Azure Cosmos DB for MongoDB vCore: Lagra och köra frågor mot inbäddningar av vektorer.
- LangChain: Konstruera programmets LLM-arbetsflöde. Använder verktyg som:
- Dokumentinläsare: För inläsning och bearbetning av dokument från en katalog.
- Vektorlagringsintegrering: För att lagra och köra frågor mot inbäddningar av vektorer i Azure Cosmos DB.
- AzureCosmosDBVectorSearch: Wrapper runt Cosmos DB Vector-sökning
- Azure App Services: Skapa användargränssnittet för Cosmic Food-appen.
- Azure OpenAI: För att tillhandahålla LLM- och inbäddningsmodeller, inklusive:
- text-embedding-ada-002: En textinbäddningsmodell som konverterar text till vektorinbäddningar med 1 536 dimensioner.
- gpt-3.5-turbo: En språkmodell för att förstå och generera naturligt språk.
Konfigurera miljön
Följ dessa steg för att komma igång med att optimera hämtningsförhöjd generation (RAG) med hjälp av Azure Cosmos DB for MongoDB (vCore):
- Skapa följande resurser på Microsoft Azure:
- Azure Cosmos DB for MongoDB vCore-kluster: Se snabbstartsguiden här.
- Azure OpenAI-resurs med:
- Inbäddningsmodelldistribution (till exempel
text-embedding-ada-002). - Distribution av chattmodell (till exempel
gpt-35-turbo).
- Inbäddningsmodelldistribution (till exempel
Exempeldokument
I den här självstudien läser vi in en enda textfil med hjälp av Dokumentet. Dessa filer bör sparas i en katalog med namnet data i mappen src . Innehållet i är följande:
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
Läsa in dokument
Ange Cosmos DB för MongoDB (vCore) anslutningssträng, databasnamn, samlingsnamn och index:
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]Initiera inbäddningsklienten.
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )Skapa inbäddningar från data, spara till databasen och returnera en anslutning till ditt vektorlager, Cosmos DB for MongoDB (vCore).
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )Skapa följande HNSW-vektorindex i samlingen (Observera att namnet på indexet är samma som ovan).
num_lists = 100 dimensions = 1536 similarity_algorithm = CosmosDBSimilarityType.COS kind = CosmosDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
Utföra vektorsökning med Cosmos DB för MongoDB (virtuell kärna)
Anslut till ditt vektorlager.
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )Definiera en funktion som utför semantisk likhetssökning med Cosmos DB Vector Search på en fråga (observera att det här kodfragmentet bara är en testfunktion).
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)Initiera chattklienten för att implementera en RAG-funktion.
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )Skapa en RAG-funktion.
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )Konverterar vektorlagret till en retriever som kan söka efter relevanta dokument baserat på angivna parametrar.
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )Skapa en hämtningskedja som är medveten om konversationshistoriken, vilket säkerställer kontextuellt relevant dokumenthämtning med hjälp av azure_openai_chat-modellen och vector_store_retriever.
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)Skapa en kedja som kombinerar hämtade dokument till ett sammanhängande svar med hjälp av språkmodellen (azure_openai_chat) och en angiven uppmaning (context_prompt).
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)Skapa en kedja som hanterar hela hämtningsprocessen och integrera den historikmedvetna kedjan och dokumentkombinationskedjan. Den här RAG-kedjan kan köras för att hämta och generera kontextuellt korrekta svar.
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
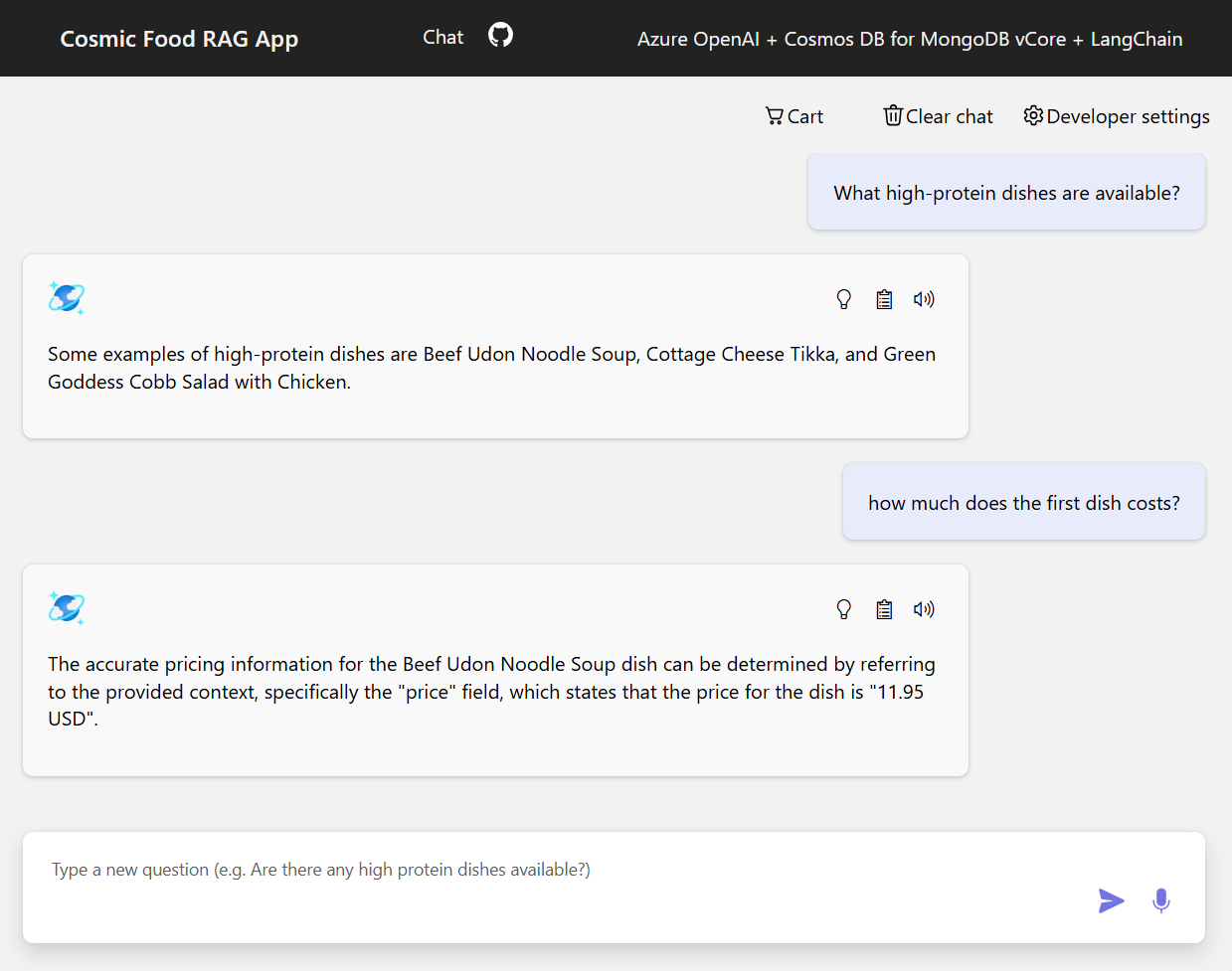
Exempelutdata
Skärmbilden nedan visar utdata för olika frågor. En rent semantisk likhetssökning returnerar råtexten från källdokumenten, medan den frågesvarande appen med HJÄLP av RAG-arkitekturen genererar exakta och anpassade svar genom att kombinera hämtat dokumentinnehåll med språkmodellen.
Slutsats
I den här självstudien utforskade vi hur du skapar en frågesvarsapp som interagerar med dina privata data med Cosmos DB som vektorlager. Genom att använda rag-arkitekturen (retrieval augmented generation) med LangChain och Azure OpenAI visade vi hur vektorlager är viktiga för LLM-program.
RAG är ett betydande framsteg inom AI, särskilt inom bearbetning av naturligt språk, och genom att kombinera dessa tekniker kan du skapa kraftfulla AI-drivna program för olika användningsfall.