AI-förbättrad annonsgenerering med Azure Cosmos DB för MongoDB vCore
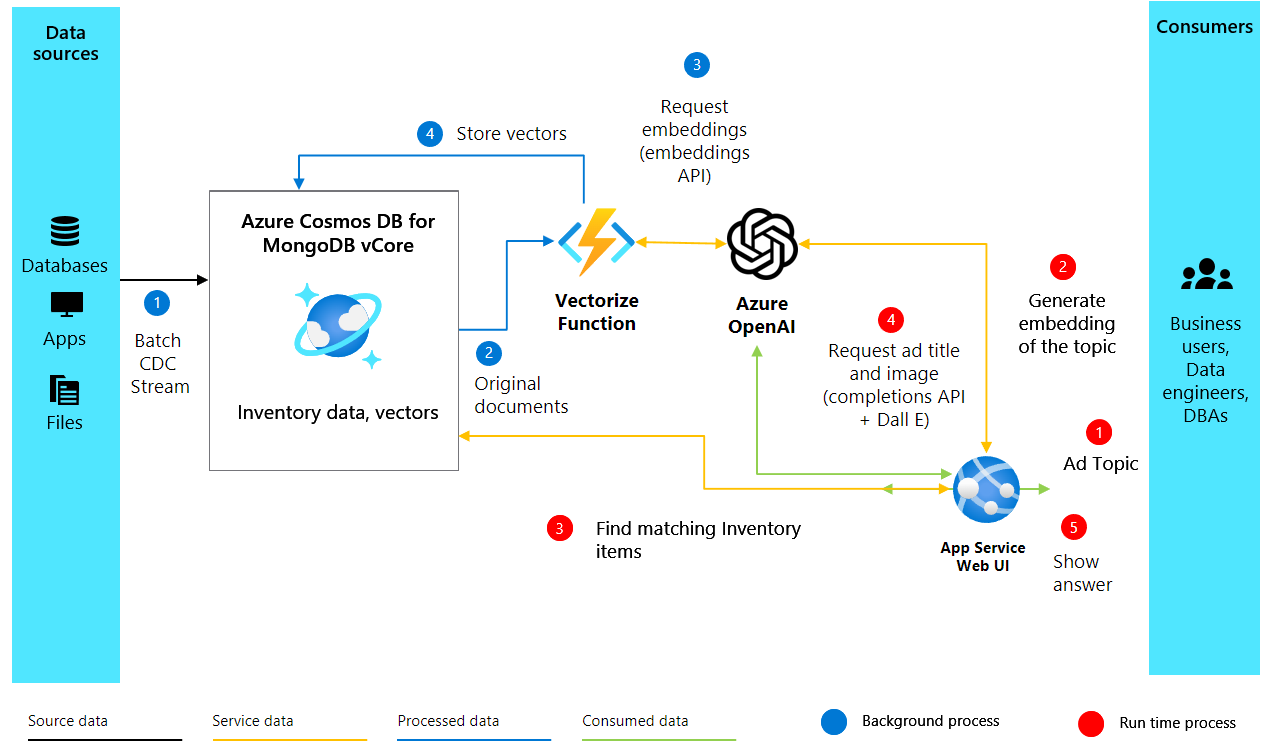
I den här guiden visar vi hur du skapar dynamiskt reklaminnehåll som resonerar med din publik med hjälp av vår anpassade AI-assistent Heelie. Med hjälp av Azure Cosmos DB for MongoDB vCore utnyttjar vi funktionen för vektorlikhetssökning för att semantiskt analysera och matcha inventeringsbeskrivningar med annonsämnen. Processen möjliggörs genom att vektorer genereras för inventeringsbeskrivningar med OpenAI-inbäddningar, vilket avsevärt förbättrar deras semantiska djup. Dessa vektorer lagras och indexeras sedan i Cosmos DB for MongoDB vCore-resursen. När vi genererar innehåll för annonser vektoriserar vi annonsavsnittet för att hitta de bäst matchande inventeringsobjekten. Detta följs av en rag-process (retrieveal augmented generation), där de bästa matchningarna skickas till OpenAI för att skapa en övertygande annons. Hela kodbasen för programmet är tillgänglig på en GitHub-lagringsplats för din referens.
Funktioner
- Vektorlikhetssökning: Använder Azure Cosmos DB för MongoDB vCores kraftfulla vektorlikhetssökning för att förbättra semantiska sökfunktioner, vilket gör det enklare att hitta relevanta inventeringsobjekt baserat på innehållet i annonser.
- OpenAI-inbäddningar: Använder de senaste inbäddningarna från OpenAI för att generera vektorer för inventeringsbeskrivningar. Den här metoden möjliggör mer nyanserade och semantiskt omfattande matchningar mellan inventeringen och annonsinnehållet.
- Innehållsgenerering: Använder OpenAI:s avancerade språkmodeller för att generera engagerande, trendfokuserade annonser. Den här metoden säkerställer att innehållet inte bara är relevant utan även fängslande för målgruppen.
Förutsättningar
Azure OpenAI: Nu ska vi konfigurera Azure OpenAI-resursen. Åtkomst till den här tjänsten är för närvarande endast tillgänglig för program. Du kan ansöka om åtkomst till Azure OpenAI genom att fylla i formuläret på https://aka.ms/oai/access. Slutför följande steg när du har åtkomst:
- Skapa en Azure OpenAI-resurs efter den här snabbstarten.
- Distribuera en
completionsoch enembeddingsmodell - Anteckna dina slutpunkts-, nyckel- och distributionsnamn.
Cosmos DB for MongoDB vCore-resurs: Vi börjar med att skapa en Azure Cosmos DB for MongoDB vCore-resurs kostnadsfritt genom att följa den här snabbstartsguiden .
- Anteckna anslutningsinformationen (anslutningssträng).
Python-miljö (>= 3.9-version) med paket som
numpy,openai,pymongo,python-dotenv,azure-core,azure-cosmos, ochtenacitygradio.Ladda ned datafilen och spara den i en angiven datamapp.
Köra skriptet
Innan vi går in på den spännande delen av att generera AI-förbättrade annonser måste vi konfigurera vår miljö. Den här konfigurationen omfattar installation av nödvändiga paket för att säkerställa att skriptet körs smidigt. Här är en steg-för-steg-guide för att förbereda allt.
1.1 Installera nödvändiga paket
För det första måste vi installera några Python-paket. Öppna terminalen och kör följande kommandon:
pip install numpy
pip install openai==1.2.3
pip install pymongo
pip install python-dotenv
pip install azure-core
pip install azure-cosmos
pip install tenacity
pip install gradio
pip show openai
1.2 Konfigurera OpenAI- och Azure-klienten
När du har installerat de nödvändiga paketen handlar nästa steg om att konfigurera våra OpenAI- och Azure-klienter för skriptet, vilket är viktigt för att autentisera våra begäranden till OpenAI API och Azure-tjänsterna.
import json
import time
import openai
from dotenv import dotenv_values
from openai import AzureOpenAI
# Configure the API to use Azure as the provider
openai.api_type = "azure"
openai.api_key = "<AZURE_OPENAI_API_KEY>" # Replace with your actual Azure OpenAI API key
openai.api_base = "https://<OPENAI_ACCOUNT_NAME>.openai.azure.com/" # Replace with your OpenAI account name
openai.api_version = "2023-06-01-preview"
# Initialize the AzureOpenAI client with your API key, version, and endpoint
client = AzureOpenAI(
api_key=openai.api_key,
api_version=openai.api_version,
azure_endpoint=openai.api_base
)
Lösningsarkitekturen
2. Skapa inbäddningar och konfigurera Cosmos DB
När vi har konfigurerat vår miljö och OpenAI-klient går vi vidare till kärndelen av vårt AI-förbättrade annonsgenereringsprojekt. Följande kod skapar vektorinbäddningar från textbeskrivningar av produkter och konfigurerar vår databas i Azure Cosmos DB för MongoDB vCore för att lagra och söka i dessa inbäddningar.
2.1 Skapa inbäddningar
För att generera övertygande annonser måste vi först förstå objekten i vårt lager. Vi gör detta genom att skapa vektorinbäddningar från beskrivningar av våra objekt, vilket gör att vi kan samla in deras semantiska betydelse i ett formulär som datorer kan förstå och bearbeta. Så här kan du skapa vektorinbäddningar för en objektbeskrivning med Hjälp av Azure OpenAI:
import openai
def generate_embeddings(text):
try:
response = client.embeddings.create(
input=text, model="text-embedding-ada-002")
embeddings = response.data[0].embedding
return embeddings
except Exception as e:
print(f"An error occurred: {e}")
return None
embeddings = generate_embeddings("Shoes for San Francisco summer")
if embeddings is not None:
print(embeddings)
Funktionen tar en textinmatning , till exempel en produktbeskrivning, och använder client.embeddings.create metoden från OpenAI-API:et för att generera en vektorinbäddning för texten. Vi använder text-embedding-ada-002 modellen här, men du kan välja andra modeller baserat på dina krav. Om processen lyckas skriver den ut de genererade inbäddningarna. Annars hanterar den undantag genom att skriva ut ett felmeddelande.
3. Anslut och konfigurera Cosmos DB för MongoDB vCore
Med våra inbäddningar klara är nästa steg att lagra och indexera dem i en databas som stöder vektorlikhetssökning. Azure Cosmos DB for MongoDB vCore passar perfekt för den här uppgiften eftersom den är avsedd att lagra dina transaktionsdata och utföra vektorsökning på ett och samma ställe.
3.1 Konfigurera anslutningen
För att ansluta till Cosmos DB använder vi pymongo-biblioteket, vilket gör att vi enkelt kan interagera med MongoDB. Följande kodfragment upprättar en anslutning till vår Cosmos DB for MongoDB vCore-instans:
import pymongo
# Replace <USERNAME>, <PASSWORD>, and <VCORE_CLUSTER_NAME> with your actual credentials and cluster name
mongo_conn = "mongodb+srv://<USERNAME>:<PASSWORD>@<VCORE_CLUSTER_NAME>.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000"
mongo_client = pymongo.MongoClient(mongo_conn)
Ersätt <USERNAME>, <PASSWORD>och <VCORE_CLUSTER_NAME> med ditt faktiska MongoDB-användarnamn, lösenord respektive vCore-klusternamn.
4. Konfigurera databas- och vektorindexet i Cosmos DB
När du har upprättat en anslutning till Azure Cosmos DB innebär nästa steg att konfigurera databasen och samlingen och sedan skapa ett vektorindex för att möjliggöra effektiva vektorlikhetssökningar. Nu ska vi gå igenom de här stegen.
4.1 Konfigurera databasen och samlingen
Först skapar vi en databas och en samling i vår Cosmos DB-instans. Så här gör du:
DATABASE_NAME = "AdgenDatabase"
COLLECTION_NAME = "AdgenCollection"
mongo_client.drop_database(DATABASE_NAME)
db = mongo_client[DATABASE_NAME]
collection = db[COLLECTION_NAME]
if COLLECTION_NAME not in db.list_collection_names():
# Creates a unsharded collection that uses the DBs shared throughput
db.create_collection(COLLECTION_NAME)
print("Created collection '{}'.\n".format(COLLECTION_NAME))
else:
print("Using collection: '{}'.\n".format(COLLECTION_NAME))
4.2 Skapa vektorindexet
För att kunna utföra effektiva sökningar med vektorlikhet i vår samling måste vi skapa ett vektorindex. Cosmos DB stöder olika typer av vektorindex och här diskuterar vi två: IVF och HNSW.
IVF
IVF står för Inverterat filindex, är standardalgoritmen för vektorindexering, som fungerar på alla klusternivåer. Det är en ungefärlig närmsta angränsande metod (ANN) som använder klustring för att påskynda sökningen efter liknande vektorer i en datamängd. Använd följande kommando för att skapa ett IVF-index:
db.command({
'createIndexes': COLLECTION_NAME,
'indexes': [
{
'name': 'vectorSearchIndex',
'key': {
"contentVector": "cosmosSearch"
},
'cosmosSearchOptions': {
'kind': 'vector-ivf',
'numLists': 1,
'similarity': 'COS',
'dimensions': 1536
}
}
]
});
Viktigt!
Du kan bara skapa ett index per vektoregenskap. Du kan alltså inte skapa fler än ett index som pekar på samma vektoregenskap. Om du vill ändra indextyp (t.ex. från IVF till HNSW) måste du först släppa indexet innan du skapar ett nytt index.
HNSW
HNSW står för Hierarchical Navigable Small World, en grafbaserad datastruktur som partitionerar vektorer i kluster och underkluster. Med HNSW kan du utföra snabb ungefärlig sökning till närmaste granne med högre hastighet med större noggrannhet. HNSW är en ungefärlig metod (ANN). Så här konfigurerar du det:
db.command(
{
"createIndexes": "ExampleCollection",
"indexes": [
{
"name": "VectorSearchIndex",
"key": {
"contentVector": "cosmosSearch"
},
"cosmosSearchOptions": {
"kind": "vector-hnsw",
"m": 16, # default value
"efConstruction": 64, # default value
"similarity": "COS",
"dimensions": 1536
}
}
]
}
)
Kommentar
HNSW-indexering är endast tillgängligt på M40-klusternivåer och högre.
5. Infoga data i samlingen
Infoga nu inventeringsdata, som innehåller beskrivningar och motsvarande vektorinbäddningar, i den nyligen skapade samlingen. För att infoga data i vår samling använder vi den insert_many() metod som tillhandahålls av pymongo biblioteket. Med metoden kan vi infoga flera dokument i samlingen samtidigt. Våra data lagras i en JSON-fil som vi läser in och sedan infogar i databasen.
Ladda ned shoes_with_vectors.json-filen från GitHub-lagringsplatsen och lagra den i en data katalog i projektmappen.
data_file = open(file="./data/shoes_with_vectors.json", mode="r")
data = json.load(data_file)
data_file.close()
result = collection.insert_many(data)
print(f"Number of data points added: {len(result.inserted_ids)}")
6. Vektorsökning i Cosmos DB för MongoDB vCore
När våra data har laddats upp kan vi nu använda kraften i vektorsökning för att hitta de mest relevanta objekten baserat på en fråga. Med det vektorindex som vi skapade tidigare kan vi utföra semantiska sökningar i vår datauppsättning.
6.1 Genomföra en vektorsökning
För att utföra en vektorsökning definierar vi en funktion vector_search som tar en fråga och antalet resultat som ska returneras. Funktionen genererar en vektor för frågan med den generate_embeddings funktion som vi definierade tidigare och använder sedan Cosmos DB:s $search funktioner för att hitta de närmaste matchande objekten baserat på deras vektorbäddningar.
# Function to assist with vector search
def vector_search(query, num_results=3):
query_vector = generate_embeddings(query)
embeddings_list = []
pipeline = [
{
'$search': {
"cosmosSearch": {
"vector": query_vector,
"numLists": 1,
"path": "contentVector",
"k": num_results
},
"returnStoredSource": True }},
{'$project': { 'similarityScore': { '$meta': 'searchScore' }, 'document' : '$$ROOT' } }
]
results = collection.aggregate(pipeline)
return results
6.2 Utföra vektorsökningsfråga
Slutligen kör vi vår vektorsökningsfunktion med en specifik fråga och bearbetar resultaten för att visa dem:
query = "Shoes for Seattle sweater weather"
results = vector_search(query, 3)
print("\nResults:\n")
for result in results:
print(f"Similarity Score: {result['similarityScore']}")
print(f"Title: {result['document']['name']}")
print(f"Price: {result['document']['price']}")
print(f"Material: {result['document']['material']}")
print(f"Image: {result['document']['img_url']}")
print(f"Purchase: {result['document']['purchase_url']}\n")
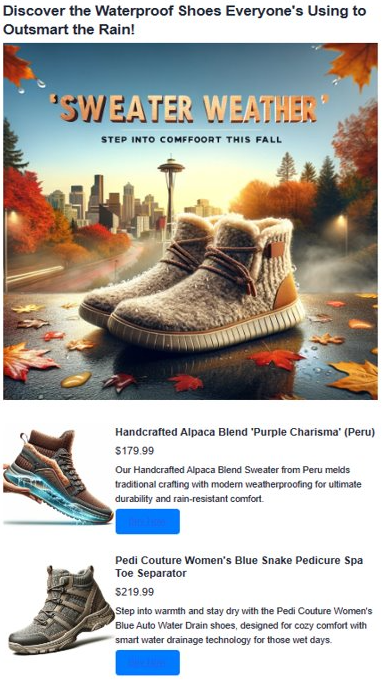
7. Generera annonsinnehåll med GPT-4 och DALL. E
Vi kombinerar alla utvecklade komponenter för att skapa övertygande annonser och använder OpenAI:s GPT-4 för text och DALL· E 3 för bilder. Tillsammans med vektorsökresultat bildar de en fullständig annons. Vi introducerar också Heelie, vår intelligenta assistent, med uppgift att skapa engagerande annonstaliner. Med den kommande koden ser du Heelie i praktiken, vilket förbättrar vår annonsskapandeprocess.
from openai import OpenAI
def generate_ad_title(ad_topic):
system_prompt = '''
You are Heelie, an intelligent assistant for generating witty and cativating tagline for online advertisement.
- The ad campaign taglines that you generate are short and typically under 100 characters.
'''
user_prompt = f'''Generate a catchy, witty, and short sentence (less than 100 characters)
for an advertisement for selling shoes for {ad_topic}'''
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
response = client.chat.completions.create(
model="gpt-4",
messages=messages
)
return response.choices[0].message.content
def generate_ad_image(ad_topic):
daliClient = OpenAI(
api_key="<DALI_API_KEY>"
)
image_prompt = f'''
Generate a photorealistic image of an ad campaign for selling {ad_topic}.
The image should be clean, with the item being sold in the foreground with an easily identifiable landmark of the city in the background.
The image should also try to depict the weather of the location for the time of the year mentioned.
The image should not have any generated text overlay.
'''
response = daliClient.images.generate(
model="dall-e-3",
prompt= image_prompt,
size="1024x1024",
quality="standard",
n=1,
)
return response.data[0].url
def render_html_page(ad_topic):
# Find the matching shoes from the inventory
results = vector_search(ad_topic, 4)
ad_header = generate_ad_title(ad_topic)
ad_image_url = generate_ad_image(ad_topic)
with open('./data/ad-start.html', 'r', encoding='utf-8') as html_file:
html_content = html_file.read()
html_content += f'''<header>
<h1>{ad_header}</h1>
</header>'''
html_content += f'''
<section class="ad">
<img src="{ad_image_url}" alt="Base Ad Image" class="ad-image">
</section>'''
for result in results:
html_content += f'''
<section class="product">
<img src="{result['document']['img_url']}" alt="{result['document']['name']}" class="product-image">
<div class="product-details">
<h3 class="product-title" color="gray">{result['document']['name']}</h2>
<p class="product-price">{"$"+str(result['document']['price'])}</p>
<p class="product-description">{result['document']['description']}</p>
<a href="{result['document']['purchase_url']}" class="buy-now-button">Buy Now</a>
</div>
</section>
'''
html_content += '''</article>
</body>
</html>'''
return html_content
8. Sätta ihop allt
För att göra annonsgenereringen interaktiv använder vi Gradio, ett Python-bibliotek för att skapa enkla webb-UIs. Vi definierar ett användargränssnitt som gör det möjligt för användare att ange annonsämnen och sedan dynamiskt genererar och visar den resulterande annonsen.
import gradio as gr
css = """
button { background-color: purple; color: red; }
<style>
</style>
"""
with gr.Blocks(css=css, theme=gr.themes.Default(spacing_size=gr.themes.sizes.spacing_sm, radius_size="none")) as demo:
subject = gr.Textbox(placeholder="Ad Keywords", label="Prompt for Heelie!!")
btn = gr.Button("Generate Ad")
output_html = gr.HTML(label="Generated Ad HTML")
btn.click(render_html_page, [subject], output_html)
btn = gr.Button("Copy HTML")
if __name__ == "__main__":
demo.launch()
Output