Global datadistribution med Azure Cosmos DB – under huven
GÄLLER FÖR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Kassandra
Kassandra ![]() Gremlin
Gremlin ![]() Bord
Bord
Azure Cosmos DB är en grundläggande tjänst i Azure, så den distribueras i alla Azure-regioner över hela världen, inklusive offentliga, nationella moln, Försvarsdepartementet (DoD) och myndighetsmoln.
På hög nivå partitioneras Azure Cosmos DB-containerdata vågrätt i många replikuppsättningar, som replikerar skrivningar, i varje region. Replikuppsättningar checkar vederbörligen in skrivningar med hjälp av ett majoritetskvorum.
Varje region innehåller alla datapartitioner i en Azure Cosmos DB-container och kan hantera läsningar samt hantera skrivningar när skrivningar i flera regioner är aktiverade. Om ditt Azure Cosmos DB-konto distribueras mellan N Azure-regioner, kommer det att finnas minst N x 4 kopior av alla dina data.
I ett datacenter distribuerar och hanterar vi Azure Cosmos DB på massiva stämplar av datorer, var och en med dedikerad lokal lagring. I ett datacenter distribueras Azure Cosmos DB över många kluster, som vart och ett kan köra flera generationer av maskinvara. Datorer i ett kluster är vanligtvis spridda över 10–20 feldomäner för hög tillgänglighet i en region. Följande bild visar topologin för det globala distributionssystemet i Azure Cosmos DB:
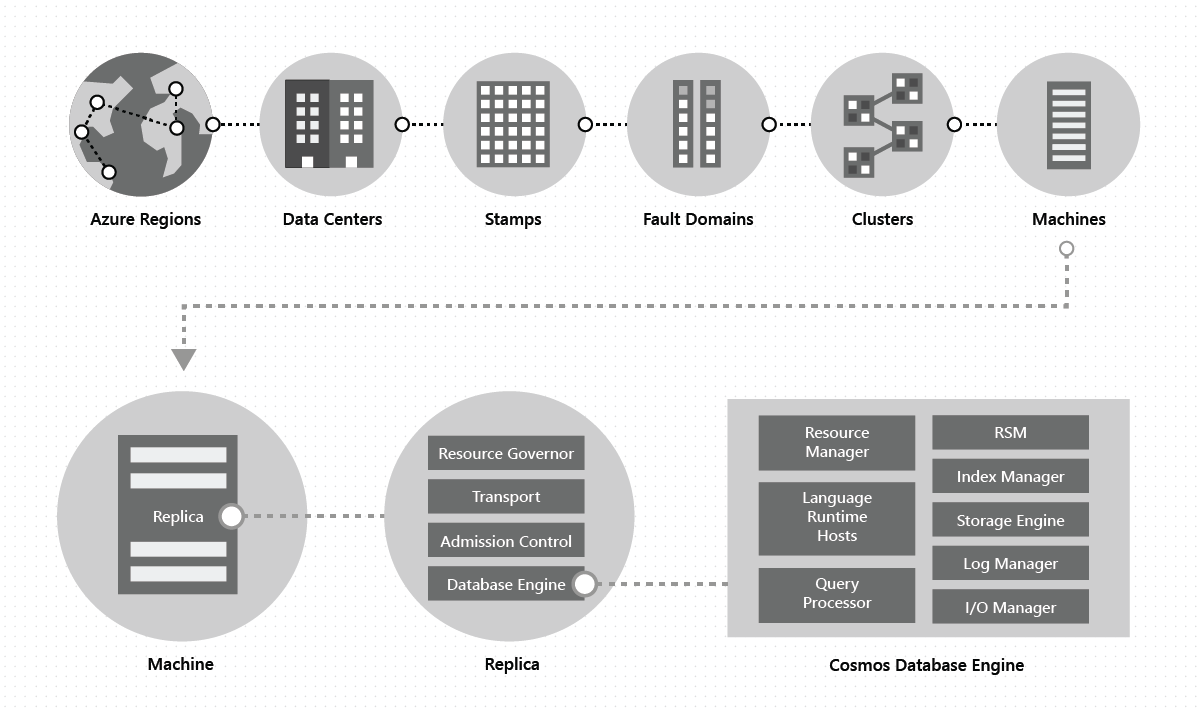
Global distribution i Azure Cosmos DB är nyckelfärdig: När som helst, med några klick eller programmatiskt med ett enda API-anrop, kan du lägga till eller ta bort de geografiska regioner som är associerade med din Azure Cosmos DB-databas. En Azure Cosmos DB-databas består i sin tur av en uppsättning Azure Cosmos DB-containrar. I Azure Cosmos DB fungerar containrar som logiska enheter för distribution och skalbarhet. De samlingar, tabeller och diagram som du skapar är (internt) bara Azure Cosmos DB-containrar. Containrar är helt schemaagnostiska och ger ett omfång för en fråga. Data i en Azure Cosmos DB-container indexeras automatiskt vid inmatning. Med automatisk indexering kan användare köra frågor mot data utan problem med schema- eller indexhantering, särskilt i en globalt distribuerad konfiguration.
I en viss region distribueras data i en container med hjälp av en partitionsnyckel som du tillhandahåller och hanteras transparent av de underliggande fysiska partitionerna (lokal distribution).
Varje fysisk partition replikeras också mellan geografiska regioner (global distribution).
När en app som använder Azure Cosmos DB elastiskt skalar dataflödet på en Azure Cosmos DB-container eller förbrukar mer lagringsutrymme hanterar Azure Cosmos DB transparent partitionshanteringsåtgärder (dela, klona, ta bort) i alla regioner. Oberoende av skalning, distribution eller fel fortsätter Azure Cosmos DB att tillhandahålla en enda systemavbildning av data i containrarna, som är globalt distribuerade över valfritt antal regioner.
Som du ser i följande bild distribueras data i en container längs två dimensioner – inom en region och mellan regioner, över hela världen:
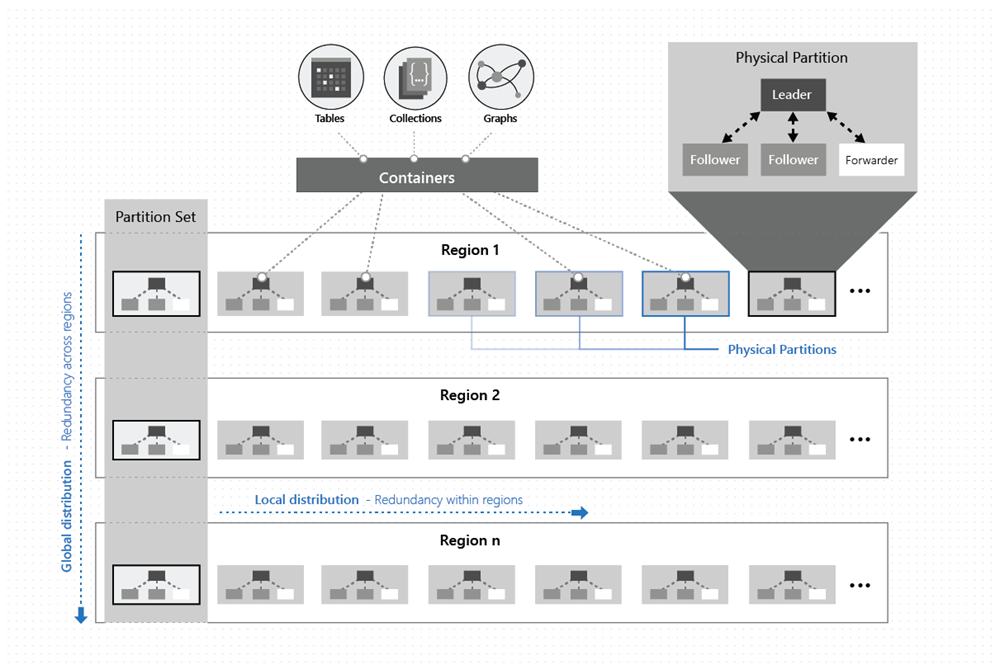
En fysisk partition implementeras av en grupp repliker, som kallas för en replikuppsättning. Varje dator är värd för hundratals repliker som motsvarar olika fysiska partitioner inom en fast uppsättning processer enligt bilden ovan. Repliker som motsvarar de fysiska partitionerna placeras dynamiskt och belastningsutjämnas mellan datorerna i ett kluster och datacenter i en region.
En replik tillhör unikt en Azure Cosmos DB-klientorganisation. Varje replik är värd för en instans av Azure Cosmos DB:s databasmotor, som hanterar resurserna och de associerade indexen. Azure Cosmos DB-databasmotorn fungerar på ett ARS-baserat typsystem (atom-record-sequence). Motorn är agnostisk för begreppet schema, vilket suddar ut gränsen mellan posternas struktur och instansvärden. Azure Cosmos DB uppnår fullständig schemaagnostik genom att automatiskt indexera allt vid inmatning på ett effektivt sätt, vilket gör att användarna kan köra frågor mot sina globalt distribuerade data utan att behöva hantera schema- eller indexhantering.
Azure Cosmos DB-databasmotorn består av komponenter som implementering av flera samordningspri primitiver, språkkörningar, frågeprocessorn och undersystemen för lagring och indexering som ansvarar för transaktionell lagring respektive indexering av data. För att ge hållbarhet och hög tillgänglighet bevarar databasmotorn sina data och index på SSD:er och replikerar dem bland databasmotorinstanserna inom replikuppsättningarna. Större klienter motsvarar en högre skala av dataflöde och lagring och har antingen större eller fler repliker eller båda. Varje komponent i systemet är helt asynkron – ingen tråd blockerar någonsin, och varje tråd utför kortvarigt arbete utan att medföra några onödiga trådväxlar. Hastighetsbegränsning och bakåttryck rör sig över hela stacken från antagningskontrollen till alla I/O-sökvägar. Azure Cosmos DB-databasmotorn är utformad för att utnyttja detaljerad samtidighet och leverera högt dataflöde när den körs inom sparsamma mängder systemresurser.
Azure Cosmos DB:s globala distribution bygger på två viktiga abstraktioner – replikuppsättningar och partitionsuppsättningar. En replikuppsättning är ett modulärt Lego-block för samordning, och en partitionsuppsättning är ett dynamiskt överlägg på en eller flera geografiskt distribuerade fysiska partitioner. För att förstå hur global distribution fungerar måste vi förstå dessa två viktiga abstraktioner.
Replikuppsättningar
En fysisk partition materialiseras som en självhanterad och dynamiskt belastningsutjämningsgrupp med repliker spridda över flera feldomäner, så kallade replikuppsättningar. Den här uppsättningen implementerar gemensamt protokollet för replikerade tillståndsdatorer för att göra data i den fysiska partitionen mycket tillgängliga, hållbara och konsekventa. Replikuppsättningsmedlemskapet N är dynamiskt – det varierar mellan NMin och NMax baserat på fel, administrativa åtgärder och tiden för misslyckade repliker att återskapa/återställa. Baserat på medlemskapsändringarna konfigurerar replikeringsprotokollet också om storleken på läs- och skrivkvorum. För att jämnt distribuera det dataflöde som tilldelas till en viss fysisk partition använder vi två idéer:
För det första är kostnaden för att bearbeta skrivbegäranden på ledaren högre än kostnaden för att tillämpa uppdateringarna på följaren. På motsvarande sätt budgeteras ledaren mer systemresurser än följarna.
För det andra består läskvorumet för en viss konsekvensnivå uteslutande av följereplikerna. Vi undviker att kontakta ledaren för att betjäna läsningar om det inte krävs. Vi använder ett antal idéer från den forskning som gjorts om förhållandet mellan belastning och kapacitet i de kvorumbaserade systemen för de fem konsekvensmodeller som Azure Cosmos DB stöder.
Partitionsuppsättningar
En grupp fysiska partitioner, en från var och en av de konfigurerade med Azure Cosmos DB-databasregionerna, består för att hantera samma uppsättning nycklar som replikeras i alla konfigurerade regioner. Den här primitiva högre samordningen kallas för en partitionsuppsättning – ett geografiskt distribuerat dynamiskt överlägg av fysiska partitioner som hanterar en viss uppsättning nycklar. Även om en viss fysisk partition (en replikuppsättning) är begränsad i ett kluster, kan en partitionsuppsättning omfatta kluster, datacenter och geografiska regioner enligt bilden nedan:
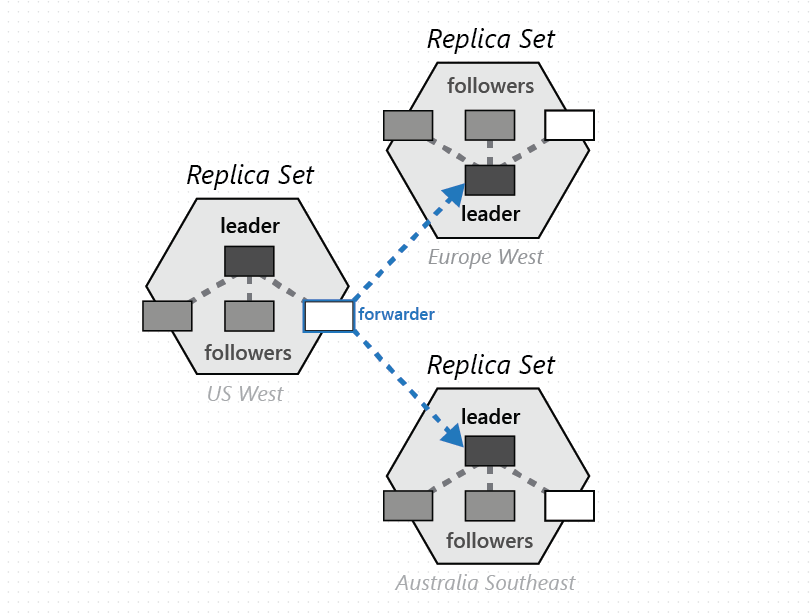
Du kan se en partitionsuppsättning som en geografiskt spridd "superreplikuppsättning", som består av flera replikuppsättningar som äger samma uppsättning nycklar. På samma sätt som en replikuppsättning är partitionsuppsättningens medlemskap också dynamiskt – det varierar beroende på implicita fysiska partitionshanteringsåtgärder för att lägga till/ta bort nya partitioner till/från en viss partitionsuppsättning (till exempel när du skalar ut dataflödet på en container, lägger till/tar bort en region i Azure Cosmos DB-databasen eller när fel inträffar). Tack vare att var och en av partitionerna (av en partitionsuppsättning) hanterar partitionsuppsättningsmedlemskapet i sin egen replikuppsättning är medlemskapet helt decentraliserat och mycket tillgängligt. Under omkonfigurationen av en partitionsuppsättning upprättas också topologin för överlägget mellan fysiska partitioner. Topologin väljs dynamiskt baserat på konsekvensnivå, geografiskt avstånd och tillgänglig nätverksbandbredd mellan källan och de fysiska målpartitionerna.
Med tjänsten kan du konfigurera dina Azure Cosmos DB-databaser med antingen en enda skrivregion eller flera skrivregioner, och beroende på valet är partitionsuppsättningar konfigurerade för att acceptera skrivningar i exakt en eller alla regioner. Systemet använder ett kapslat konsensusprotokoll på två nivåer – en nivå fungerar inom replikerna i en replikuppsättning av en fysisk partition som accepterar skrivningarna, och den andra fungerar på nivån för en partitionsuppsättning för att ge fullständiga ordergarantier för alla bekräftade skrivningar i partitionsuppsättningen. Den här kapslade konsensusen i flera lager är avgörande för implementeringen av våra strikta serviceavtal för hög tillgänglighet samt implementeringen av konsekvensmodellerna, som Azure Cosmos DB erbjuder sina kunder.
Konfliktlösning
Vår design för uppdateringsspridning, konfliktlösning och kausalitetsspårning är inspirerad av det tidigare arbetet med epidemialgoritmer och Bayou-systemet. Även om kärnorna i idéerna har överlevt och utgör en praktisk referensram för att kommunicera Azure Cosmos DB:s systemdesign, har de också genomgått betydande omvandling när vi tillämpade dem på Azure Cosmos DB-systemet. Detta behövdes eftersom de tidigare systemen varken utformades med resursstyrningen eller med den skala som Azure Cosmos DB behöver använda, eller för att tillhandahålla funktionerna (till exempel begränsad föråldringskonsekvens) och de stränga och omfattande serviceavtal som Azure Cosmos DB levererar till sina kunder.
Kom ihåg att en partitionsuppsättning distribueras över flera regioner och följer Replikeringsprotokollet för Azure Cosmos DB (skrivningar i flera regioner) för att replikera data mellan de fysiska partitionerna som består av en viss partitionsuppsättning. Varje fysisk partition (av en partitionsuppsättning) accepterar skrivningar och hanterar vanligtvis läsningar till de klienter som är lokala i den regionen. Skrivningar som accepteras av en fysisk partition inom en region är vederbörligen bekräftade och görs mycket tillgängliga inom den fysiska partitionen innan de bekräftas för klienten. Dessa är preliminära skrivningar och sprids till andra fysiska partitioner i partitionsuppsättningen med hjälp av en anti-entropikanal. Klienter kan begära antingen preliminära eller bekräftade skrivningar genom att skicka ett begärandehuvud. Spridningen av antientropi (inklusive spridningsfrekvensen) är dynamisk, baserat på topologin för partitionsuppsättningen, den regionala närheten till de fysiska partitionerna och den konfigurerade konsekvensnivån. I en partitionsuppsättning följer Azure Cosmos DB ett primärt incheckningsschema med en dynamiskt vald arbiterpartition. Valet av skiljedomare är dynamiskt och är en integrerad del av omkonfigurationen av partitionsuppsättningen baserat på överläggets topologi. De bekräftade skrivningar (inklusive uppdateringar med flera rader/batchar) kommer garanterat att ordnas.
Vi använder kodade vektorklockor (som innehåller region-ID och logiska klockor som motsvarar varje nivå av konsensus vid replikuppsättningen respektive partitionsuppsättningen) för kausalitetsspårning och versionsvektorer för att identifiera och lösa uppdateringskonflikter. Topologin och algoritmen för peerval är utformade för att säkerställa fast och minimal lagring och minimal nätverksbelastning för versionsvektorer. Algoritmen garanterar den strikta konvergensegenskapen.
För Azure Cosmos DB-databaser som konfigurerats med flera skrivregioner erbjuder systemet ett antal flexibla principer för automatisk konfliktlösning som utvecklarna kan välja mellan, inklusive:
- Last-Write-Wins (LWW), som som standard använder en systemdefinierad tidsstämpelegenskap (som baseras på tidssynkroniseringsklockans protokoll). Med Azure Cosmos DB kan du också ange andra anpassade numeriska egenskaper som ska användas för konfliktlösning.
- Programdefinierad (anpassad) konfliktlösningsprincip (uttryckt via sammanslagningsprocedurer), som är utformad för programdefinierad semantikavstämning av konflikter. Dessa procedurer anropas vid identifiering av skrivskrivningskonflikterna under överinseende av en databastransaktion på serversidan. Systemet ger exakt en gång garanti för körning av en sammanslagningsprocedur som en del av åtagandeprotokollet. Det finns flera exempel på konfliktlösning som du kan spela med.
Konsekvensmodeller
Oavsett om du konfigurerar din Azure Cosmos DB-databas med en enda eller flera skrivregioner kan du välja mellan de fem väldefinierade konsekvensmodellerna. Med flera skrivregioner är följande några viktiga aspekter av konsekvensnivåerna:
Konsekvensen för begränsad inaktuellhet garanterar att alla läsningar kommer att ligga inom K-prefix eller T-sekunder från den senaste skrivningen i någon av regionerna. Dessutom garanteras läsningar med begränsad föråldringskonsekvens att vara monotona och med konsekventa prefixgarantier. Antientropiprotokollet fungerar på ett hastighetsbegränsat sätt och säkerställer att prefixen inte ackumuleras och att återtrycket på skrivningarna inte behöver tillämpas. Sessionskonsekvens garanterar monoton läsning, monoton skrivning, läsning av egna skrivningar, skrivning följer läs- och konsekventa prefixgarantier över hela världen. För databaser som konfigurerats med stark konsekvens gäller inte fördelarna (låg skrivsvarstid, hög skrivtillgänglighet) för flera skrivregioner på grund av synkron replikering mellan regioner.
Semantiken för de fem konsekvensmodellerna i Azure Cosmos DB beskrivs här och beskrivs matematiskt med hjälp av en TLA+-specifikationer på hög nivå här.
Nästa steg
Lär dig sedan hur du konfigurerar global distribution med hjälp av följande artiklar:
- Lägga till/ta bort regioner från ditt databaskonto
- Så här skapar du en anpassad konfliktlösningsprincip
- Försöker du planera kapacitet för en migrering till Azure Cosmos DB? Du kan använda information om ditt befintliga databaskluster för kapacitetsplanering.
- Om allt du vet är antalet virtuella kärnor och servrar i ditt befintliga databaskluster läser du om att uppskatta enheter för begäranden med virtuella kärnor eller virtuella kärnor
- Om du känner till vanliga begärandefrekvenser för din aktuella databasarbetsbelastning kan du läsa om att uppskatta enheter för begäranden med azure Cosmos DB-kapacitetshanteraren