Skala ett Azure Cosmos DB för Apache Cassandra-konto elastiskt
GÄLLER FÖR: ![]() Kassandra
Kassandra
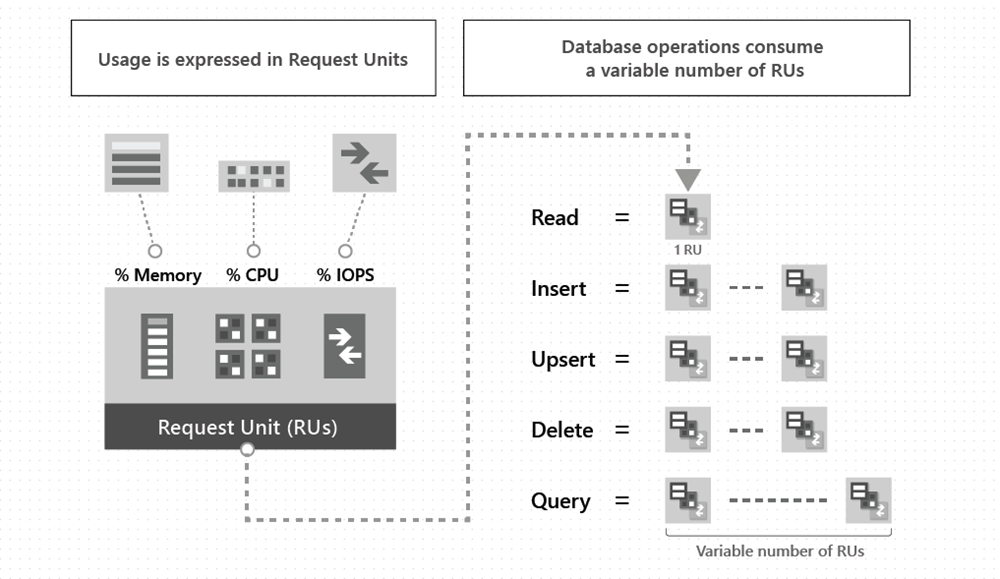
Det finns en mängd olika alternativ för att utforska den elastiska karaktären hos Azure Cosmos DB för Apache Cassandra. För att förstå hur du skalar effektivt i Azure Cosmos DB är det viktigt att förstå hur du etablerar rätt mängd enheter för begäran (RU/s) för att ta hänsyn till prestandakraven i systemet. Mer information om enheter för begäran finns i artikeln om enheter för begäran .
För API:et för Cassandra kan du hämta avgiften för begärandeenheten för enskilda frågor med hjälp av .NET- och Java-SDK:erna. Det här är användbart när du ska fastställa hur många RU/s du behöver etablera i tjänsten.
Hanteringsfrekvensbegränsning (429 fel)
Azure Cosmos DB returnerar hastighetsbegränsade (429) fel om klienter använder mer resurser (RU/s) än det belopp som du har etablerat. API:et för Cassandra i Azure Cosmos DB översätter dessa undantag till överlagrade fel i det interna Cassandra-protokollet.
Om systemet inte är känsligt för svarstid kan det vara tillräckligt för att hantera dataflödesbegränsningen med hjälp av återförsök. Se Java-kodexempel för version 3 och version 4 av Apache Cassandra Java-drivrutiner för att hantera hastighetsbegränsning transparent. De här exemplen implementerar en anpassad version av cassandra-standardprincipen för återförsök i Java. Du kan också använda Spark-tillägget för att hantera hastighetsbegränsning. När du använder Spark följer du vår vägledning om hur du optimerar konfigurationen av Spark-anslutningstjänstens dataflöde.
Hantera skalning
Om du behöver minimera svarstiden finns det ett spektrum av alternativ för att hantera skalnings- och etableringsdataflöde (RU:er) i API:et för Cassandra:
- Manuellt med hjälp av Azure Portal
- Programmatiskt med hjälp av kontrollplansfunktionerna
- Programmatiskt med hjälp av CQL-kommandon med ett specifikt SDK
- Dynamiskt med autoskalning
I följande avsnitt förklaras fördelarna och nackdelarna med varje metod. Du kan sedan välja den bästa strategin för att balansera systemets skalningsbehov, den totala kostnaden och effektivitetsbehoven för din lösning.
Använda Azure Portal
Du kan skala resurserna i Azure Cosmos DB för Apache Cassandra-kontot med hjälp av Azure Portal. Mer information finns i artikeln om Etablera dataflöde för containrar och databaser. Den här artikeln förklarar de relativa fördelarna med att ange dataflöde på databas- eller containernivå i Azure Portal. Termerna "databas" och "container" som nämns i dessa artiklar mappas till "keyspace" respektive "table" för API:et för Cassandra.
Fördelen med den här metoden är att det är ett enkelt nyckelfärdigt sätt att hantera dataflödeskapacitet i databasen. Nackdelen är dock att din metod för skalning i många fall kan kräva att vissa automatiseringsnivåer är både kostnadseffektiva och högpresterande. I nästa avsnitt beskrivs relevanta scenarier och metoder.
Använda kontrollplanet
Azure Cosmos DB:s API för Cassandra ger möjlighet att justera dataflödet programmatiskt med hjälp av våra olika kontrollplansfunktioner. Mer information och exempel finns i artiklarna om Azure Resource Manager, PowerShell och Azure CLI .
Fördelen med den här metoden är att du kan automatisera upp- eller nedskalningen av resurser baserat på en timer för att ta hänsyn till hög aktivitet eller perioder med låg aktivitet. Ta en titt på vårt exempel här för att se hur du gör detta med hjälp av Azure Functions och PowerShell.
En nackdel med den här metoden kan vara att du inte kan svara på oförutsägbara föränderliga skalningsbehov i realtid. I stället kan du behöva använda programkontexten i systemet, på klient-/SDK-nivå eller med autoskalning.
Använda CQL-frågor med ett specifikt SDK
Du kan skala systemet dynamiskt med kod genom att köra CQL ALTER-kommandona för den angivna databasen eller containern.
Fördelen med den här metoden är att du kan svara på skalningsbehov dynamiskt och på ett anpassat sätt som passar ditt program. Med den här metoden kan du fortfarande använda standardavgifter och priser för RU/s. Om systemets skalningsbehov oftast är förutsägbara (cirka 70 % eller mer) kan användning av SDK med CQL vara en mer kostnadseffektiv metod för automatisk skalning än att använda autoskalning. Nackdelen med den här metoden är att det kan vara ganska komplext att implementera återförsök medan hastighetsbegränsning kan öka svarstiden.
Använda autoskalningsetablerade dataflöden
Förutom standard (manuell) eller programmatiskt sätt att etablera dataflöde kan du även konfigurera Azure Cosmos DB-containrar i automatiskt etablerat dataflöde. Autoskalning skalas automatiskt och omedelbart efter dina förbrukningsbehov inom angivna RU-intervall utan att äventyra serviceavtalen. Mer information finns i artikeln Skapa Azure Cosmos DB-containrar och databaser i autoskalning .
Fördelen med den här metoden är att det är det enklaste sättet att hantera skalningsbehoven i systemet. Den tillämpar inte hastighetsbegränsning inom de konfigurerade RU-intervallen. Nackdelen är att om skalningsbehoven i systemet är förutsägbara kan autoskalning vara ett mindre kostnadseffektivt sätt att hantera dina skalningsbehov än att använda det skräddarsydda kontrollplanet eller SDK-nivåmetoderna som nämns ovan.
Om du vill ange eller ändra maximalt dataflöde (RU:er) för autoskalning med hjälp av CQL använder du följande (ersätter nyckelområde/tabellnamn i enlighet med detta):
# to set max throughput (RUs) for autoscale at keyspace level:
create keyspace <keyspace name> WITH cosmosdb_autoscale_max_throughput=5000;
# to alter max throughput (RUs) for autoscale at keyspace level:
alter keyspace <keyspace name> WITH cosmosdb_autoscale_max_throughput=4000;
# to set max throughput (RUs) for autoscale at table level:
create table <keyspace name>.<table name> (pk int PRIMARY KEY, ck int) WITH cosmosdb_autoscale_max_throughput=5000;
# to alter max throughput (RUs) for autoscale at table level:
alter table <keyspace name>.<table name> WITH cosmosdb_autoscale_max_throughput=4000;
Nästa steg
- Kom igång med att skapa ett API för Cassandra-konto, databas och en tabell med hjälp av ett Java-program