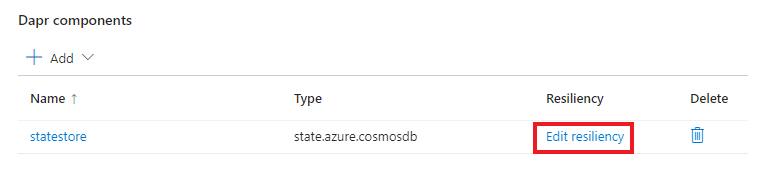
Dapr-komponentåterhämtning (förhandsversion)
Återhämtningsprinciper förhindrar, identifierar och återställer proaktivt från dina containerappfel. I den här artikeln får du lära dig hur du tillämpar återhämtningsprinciper för program som använder Dapr för att integrera med olika molntjänster, till exempel delstatsbutiker, pub-/undermeddelandeköer, hemliga butiker med mera.
Du kan konfigurera återhämtningsprinciper som återförsök, timeouter och kretsbrytare för följande utgående och inkommande åtgärdsriktningar via en Dapr-komponent:
- Utgående åtgärder: Anrop från Dapr-sidovagnen till en komponent, till exempel:
- Bevara eller hämta tillstånd
- Publicera ett meddelande
- Anropa en utdatabindning
- Inkommande åtgärder: Anrop från Dapr-sidovagnen till containerappen, till exempel:
- Prenumerationer när du levererar ett meddelande
- Indatabindningar som levererar en händelse
Följande skärmbild visar hur ett program använder en återförsöksprincip för att försöka återställa från misslyckade begäranden.
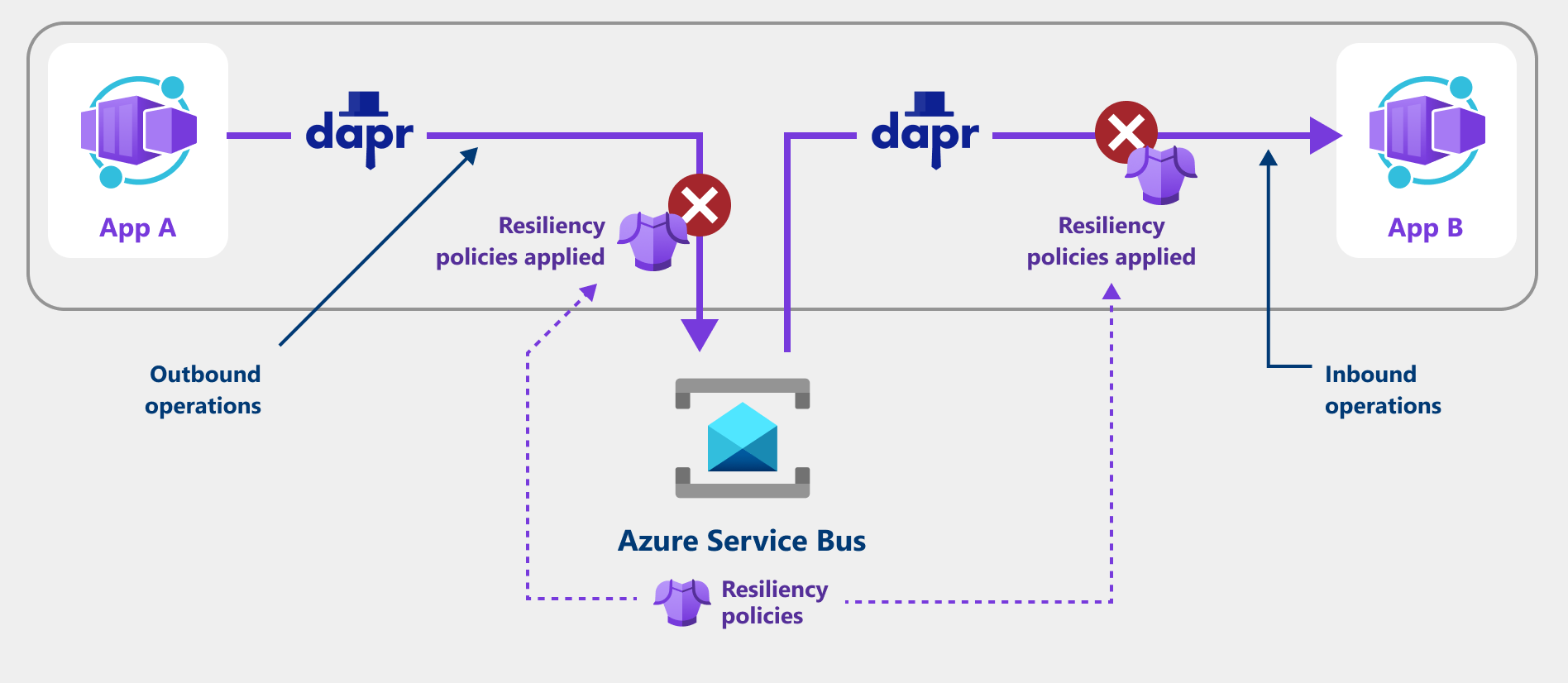
Återhämtningsprinciper som stöds
Konfigurera återhämtningsprinciper
Du kan välja om du vill skapa återhämtningsprinciper med hjälp av Bicep, CLI eller Azure Portal.
Följande återhämtningsexempel visar alla tillgängliga konfigurationer.
resource myPolicyDoc 'Microsoft.App/managedEnvironments/daprComponents/resiliencyPolicies@2023-11-02-preview' = {
name: 'my-component-resiliency-policies'
parent: '${componentName}'
properties: {
outboundPolicy: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
}
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
}
circuitBreakerPolicy: {
intervalInSeconds: 15
consecutiveErrors: 10
timeoutInSeconds: 5
}
}
inboundPolicy: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
}
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
}
circuitBreakerPolicy: {
intervalInSeconds: 15
consecutiveErrors: 10
timeoutInSeconds: 5
}
}
}
}
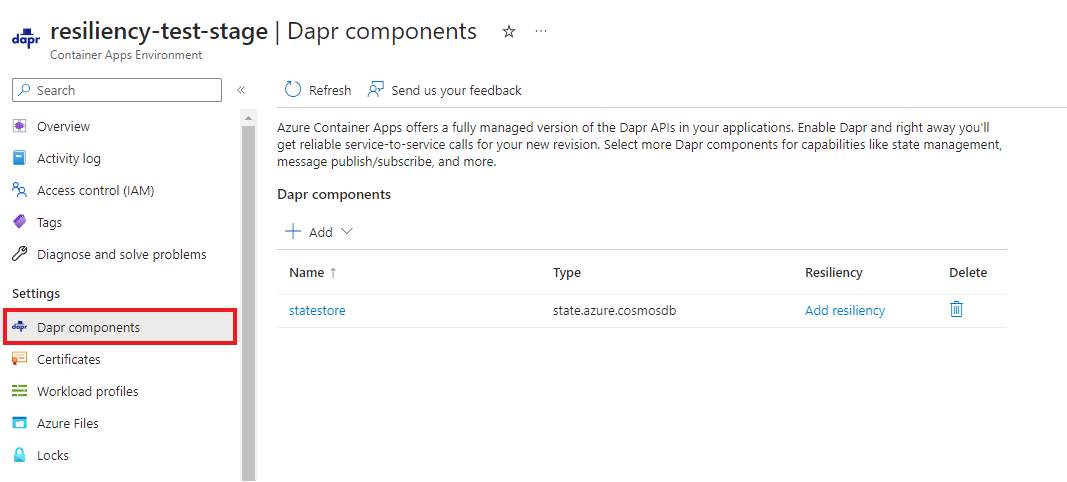
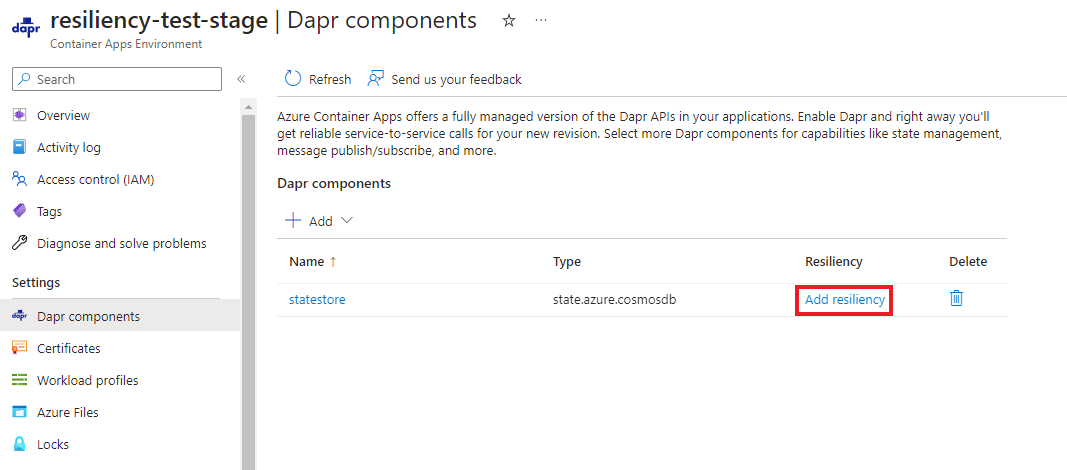
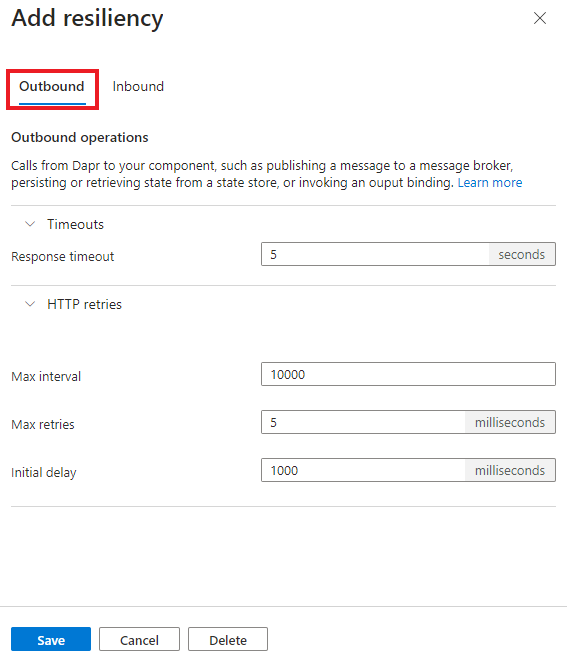
Viktigt!
När du har tillämpat alla återhämtningsprinciper måste du starta om Dina Dapr-program.
Principspecifikationer
Timeouter
Tidsgränser används för att avsluta tidskrävande åtgärder tidigt. Tidsgränsprincipen innehåller följande egenskaper.
properties: {
outbound: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
}
}
inbound: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
}
}
}
| Metadata | Obligatoriskt | Beskrivning | Exempel |
|---|---|---|---|
responseTimeoutInSeconds |
Ja | Tidsgräns väntar på ett svar från Dapr-komponenten. | 15 |
Försök
Definiera en httpRetryPolicy strategi för misslyckade åtgärder. Återförsöksprincipen innehåller följande konfigurationer.
properties: {
outbound: {
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
}
}
inbound: {
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
}
}
}
| Metadata | Obligatoriskt | Beskrivning | Exempel |
|---|---|---|---|
maxRetries |
Ja | Maximalt antal återförsök som ska köras för en misslyckad http-begäran. | 5 |
retryBackOff |
Ja | Övervaka begäranden och stäng av all trafik till den påverkade tjänsten när tidsgränsen och återförsökskriterierna uppfylls. | Ej tillämpligt |
retryBackOff.initialDelayInMilliseconds |
Ja | Fördröjning mellan det första felet och första återförsöket. | 1000 |
retryBackOff.maxIntervalInMilliseconds |
Ja | Maximal fördröjning mellan återförsök. | 10000 |
Kretsbrytare
Definiera en circuitBreakerPolicy för att övervaka begäranden som orsakar förhöjda felfrekvenser och stänga av all trafik till den påverkade tjänsten när ett visst villkor uppfylls.
properties: {
outbound: {
circuitBreakerPolicy: {
intervalInSeconds: 15
consecutiveErrors: 10
timeoutInSeconds: 5
}
},
inbound: {
circuitBreakerPolicy: {
intervalInSeconds: 15
consecutiveErrors: 10
timeoutInSeconds: 5
}
}
}
| Metadata | Obligatoriskt | Beskrivning | Exempel |
|---|---|---|---|
intervalInSeconds |
Nej | Cyklisk tidsperiod (i sekunder) som används av kretsbrytaren för att rensa dess interna antal. Om det inte anges anges intervallet till samma värde som anges för timeoutInSeconds. |
15 |
consecutiveErrors |
Ja | Antal begärandefel som tillåts inträffa innan kretsen snubblar och öppnas. | 10 |
timeoutInSeconds |
Ja | Tidsperiod (i sekunder) med öppet tillstånd, direkt efter fel. | 5 |
Kretsbrytareprocess
Om du anger consecutiveErrors (kretsresans villkor som ) anges antalet fel som consecutiveFailures > $(consecutiveErrors)-1tillåts inträffa innan kretsen går ut och öppnas halvvägs.
Kretsen väntar halvöppen under den timeoutInSeconds tid under vilken consecutiveErrors antalet begäranden måste lyckas.
- Om begäranden lyckas stängs kretsen.
- Om begäranden misslyckas förblir kretsen i ett halvöppnat tillstånd.
Om du inte har angett något intervalInSeconds värde återställs kretsen till ett stängt tillstånd efter den tid du har angett för timeoutInSeconds, oavsett om begäran lyckades eller misslyckades i följd. Om du anger intervalInSeconds till 0återställs kretsen aldrig automatiskt och flyttas bara från halvöppet till stängt tillstånd genom att consecutiveErrors slutföra begäranden på en rad.
Om du angav ett intervalInSeconds värde avgör det hur lång tid det tar innan kretsen återställs till stängt tillstånd, oberoende av om begäranden som skickats i halvöppnat tillstånd lyckades eller inte.
Återhämtningsloggar
I avsnittet Övervakning i containerappen väljer du Loggar.
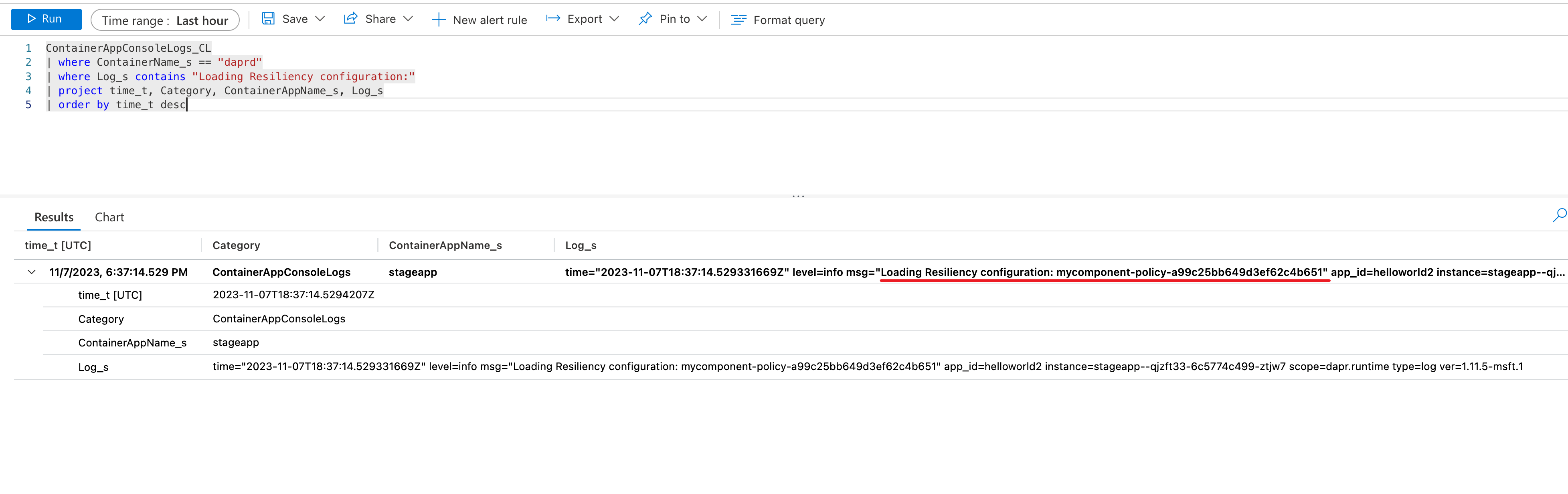
I fönstret Loggar skriver och kör du en fråga för att hitta återhämtning via systemloggarna för containerappen. Om du till exempel vill ta reda på om en återhämtningsprincip har lästs in:
ContainerAppConsoleLogs_CL
| where ContainerName_s == "daprd"
| where Log_s contains "Loading Resiliency configuration:"
| project time_t, Category, ContainerAppName_s, Log_s
| order by time_t desc
Klicka på Kör för att köra frågan och visa resultatet med loggmeddelandet som anger att principen läses in.
Du kan också hitta den faktiska återhämtningsprincipen genom att aktivera felsökningsloggar i containerappen och fråga för att se om en återhämtningsresurs har lästs in.
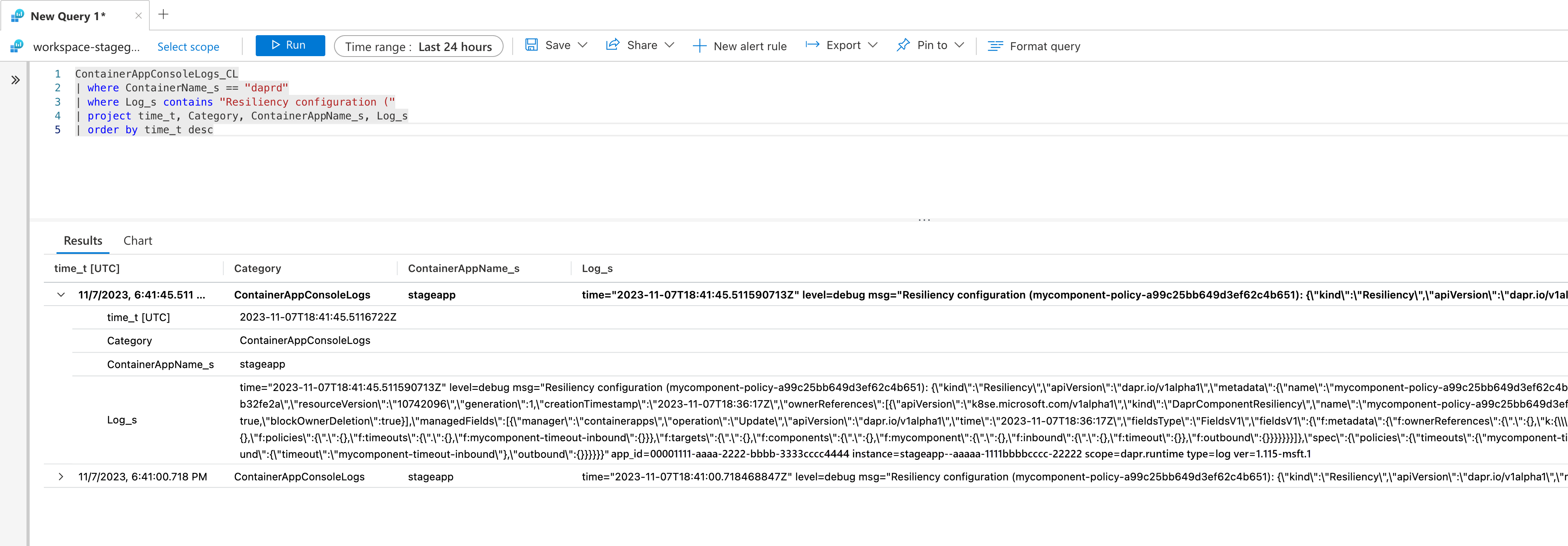
När felsökningsloggar har aktiverats använder du en fråga som liknar följande:
ContainerAppConsoleLogs_CL
| where ContainerName_s == "daprd"
| where Log_s contains "Resiliency configuration ("
| project time_t, Category, ContainerAppName_s, Log_s
| order by time_t desc
Klicka på Kör för att köra frågan och visa det resulterande loggmeddelandet med principkonfigurationen.
Relaterat innehåll
Se hur återhämtning fungerar för service-till-tjänst-kommunikation med hjälp av Azure Container Apps inbyggd tjänstidentifiering