Dataagnostisk inmatningsmotor
Den här artikeln beskriver hur du kan implementera scenarier för dataagnostisk inmatningsmotor med hjälp av en kombination av PowerApps, Azure Logic Apps och metadatadrivna kopieringsuppgifter i Azure Data Factory.
Scenarier med dataagnostisk inmatningsmotor fokuserar vanligtvis på att låta icke-tekniska (icke-datatekniker) användare publicera datatillgångar till en Data Lake för vidare bearbetning. För att implementera det här scenariot måste du ha onboarding-funktioner som aktiverar:
- Registrering av datatillgång
- Etablering av arbetsflöden och metadatainsamling
- Schemaläggning av inmatning
Du kan se hur dessa funktioner interagerar:
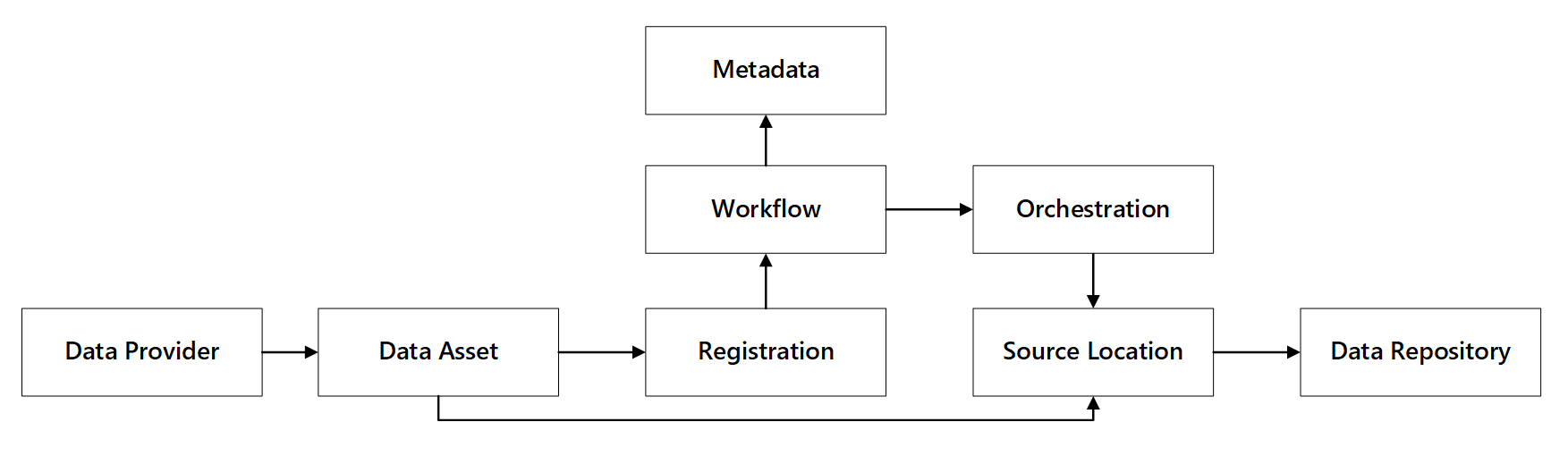
bild 1: Interaktioner med dataregistreringsfunktioner.
Följande diagram visar hur du implementerar den här processen med hjälp av en kombination av Azure-tjänster:
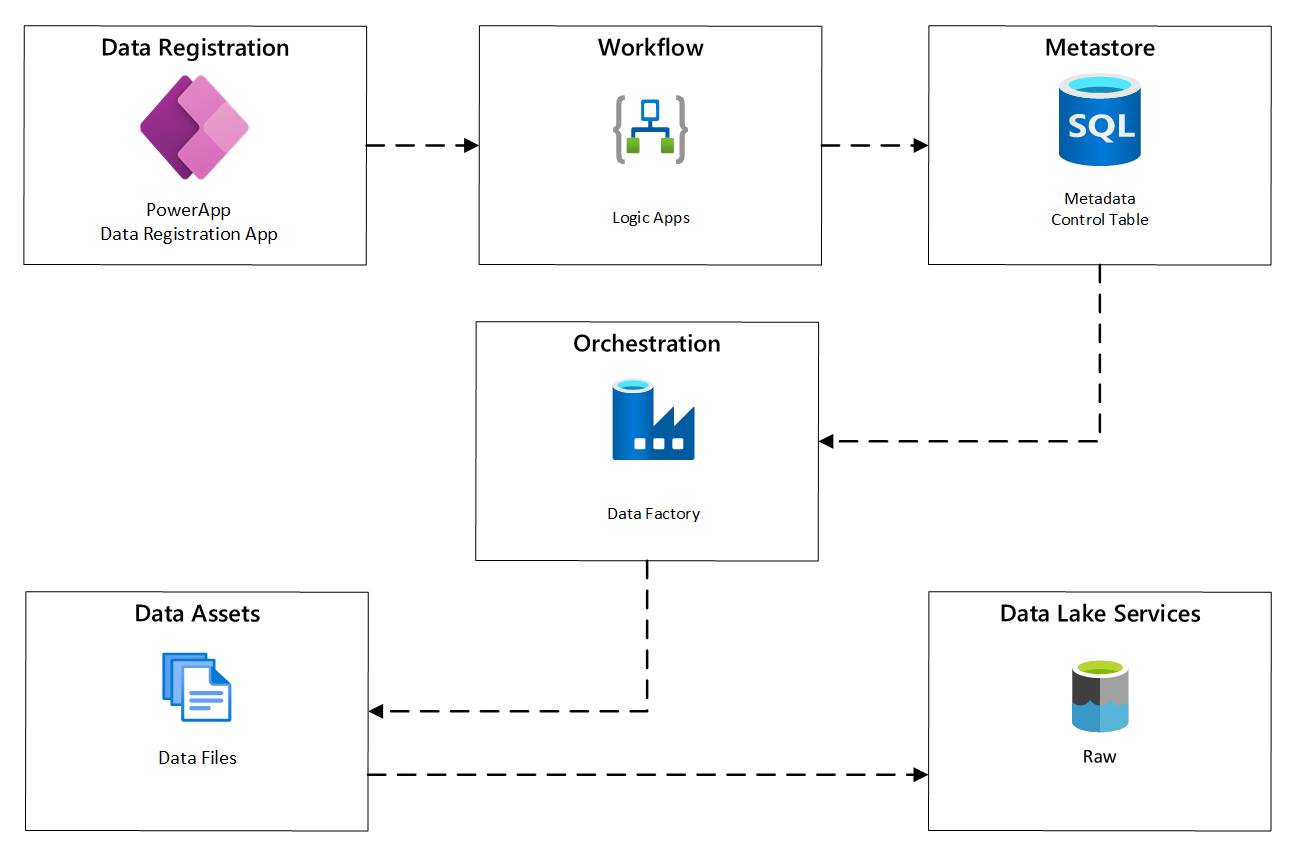
bild 2: Automatiserad inmatningsprocess.
Registrering av datatillgång
För att tillhandahålla de metadata som används för automatisk inmatning behöver du registrering av datatillgång. Informationen som du samlar in innehåller:
- Teknisk information: Namn på datatillgång, källsystem, typ, format och frekvens.
- styrningsinformation: ägare, förvaltare, synlighet (i identifieringssyfte) och känslighet.
PowerApps används för att samla in metadata som beskriver varje datatillgång. Använd en modelldriven app för att ange den information som sparas i en anpassad Dataverse-tabell. När metadata skapas eller uppdateras i Dataverse utlöses ett automatiserat molnflöde som anropar ytterligare bearbetningssteg.
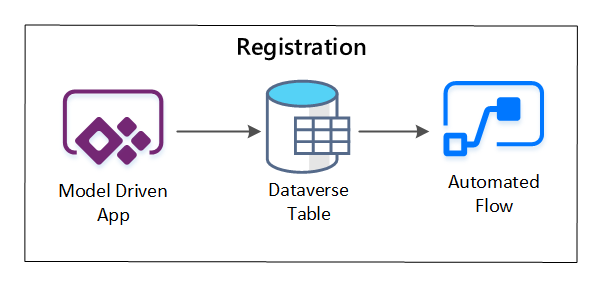
bild 3: Registrering av datatillgång.
Etableringsarbetsflöde/metadatainsamling
I steget för förberedelsearbetsflöde verifierar och bevarar du data som samlats in i registreringssteget i metaarkivet. Både tekniska och affärsverifieringssteg utförs, inklusive:
- Validering av indataflöde
- Utlösande av godkännandearbetsflöde
- Logikbearbetning för att utlösa beständighet för metadata till metadatalagret
- Aktivitetsgranskning
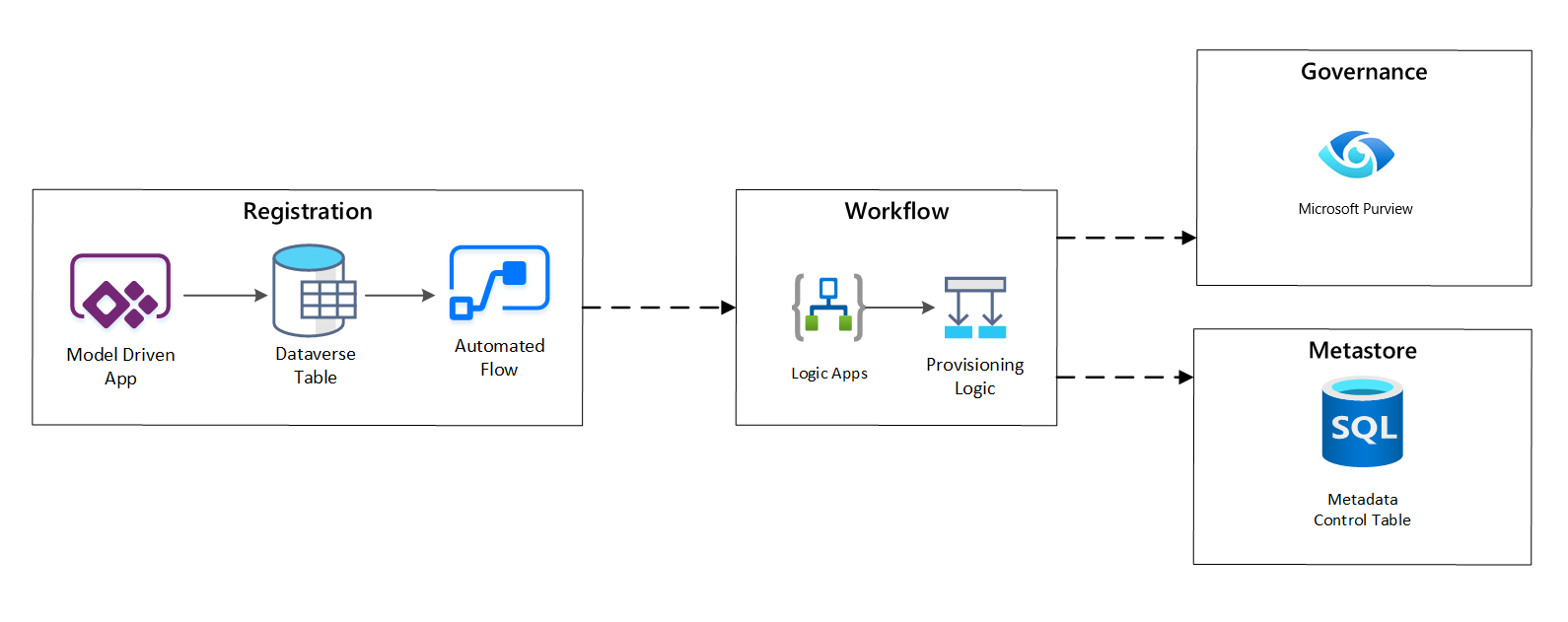
bild 4: Arbetsflöde för registrering.
När inmatningsbegäranden har godkänts använder arbetsflödet REST-API:et Microsoft Purview för att infoga källorna i Microsoft Purview.
Detaljerat arbetsflöde för introduktion av dataprodukter
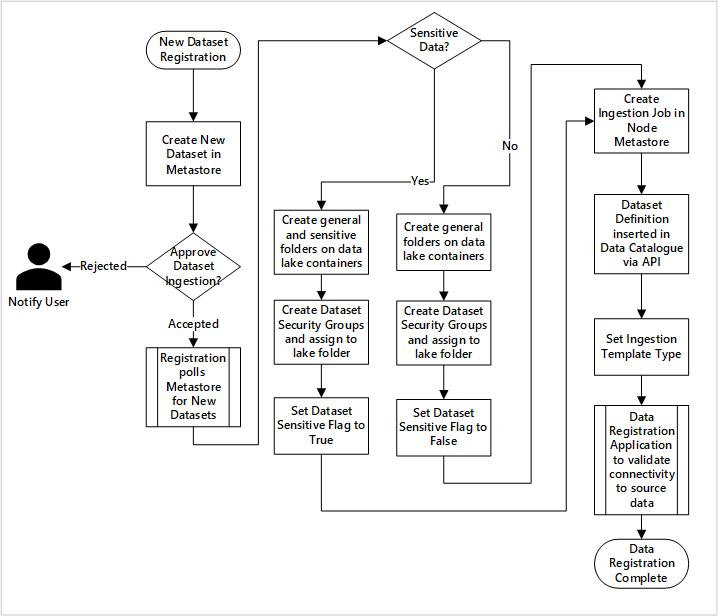
bild 5: Hur nya datauppsättningar matas in (automatiserad).
Bild 5 visar den detaljerade registreringsprocessen för att automatisera inmatningen av nya datakällor:
- Källinformation registreras, inklusive produktions- och datafabriksmiljöer.
- Dataform, format och kvalitetsbegränsningar samlas in.
- Dataapplikationsteam bör ange om data är känslig (personuppgifter) Den här klassificeringen styr processen under vilken datasjömappar skapas för att importera rådata, berikad och kuraterad data. Källan namnger rådata och berikade data, och i dataprodukterna benämns det kurerade data.
- Tjänsthuvudkonto och säkerhetsgrupper skapas för att mata in och ge åtkomst till en dataset.
- Ett inmatningsjobb skapas i datalandningszonens Data Factory-metaarkiv.
- Ett API infogar datadefinitionen i Microsoft Purview.
- Med förbehåll för valideringen av datakällan och godkännande av ops-teamet publiceras information till ett Data Factory-metaarkiv.
Schemaläggning av inmatning
I Azure Data Factory metadatadrivna kopieringsuppgifter tillhandahålla funktioner som gör att orkestreringspipelines kan styras av rader i en kontrolltabell som lagras i Azure SQL Database. Du kan använda verktyget Kopiera data för att skapa metadatadrivna pipelines i förväg.
När en pipeline har skapats lägger ditt implementeringsarbetsflöde till poster i Kontrolltabellen för att stödja inmatning från källor som identifieras av metadata för dataresursregistrering. Azure Data Factory-pipeliner och Azure SQL-databasen som innehåller ditt kontrolltabellens metaarkiv kan båda finnas i varje datalandningszon för att skapa nya datakällor och mata in dem i dessa zoner.
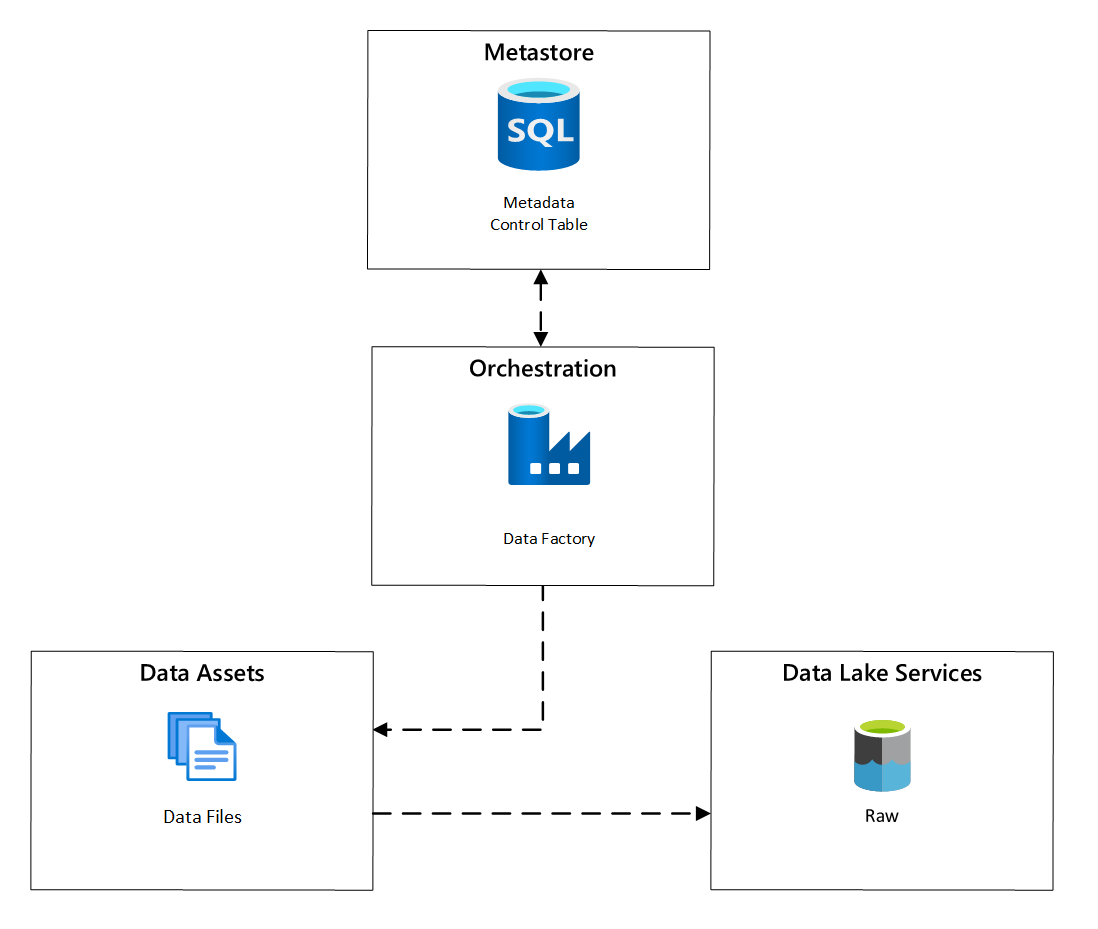
bild 6: Schemaläggning av datatillgångsinmatning.
Detaljerat arbetsflöde för att mata in nya datakällor
Följande diagram visar hur du hämtar registrerade datakällor i ett Data Factory SQL Database-metaarkiv och hur data matas in först:
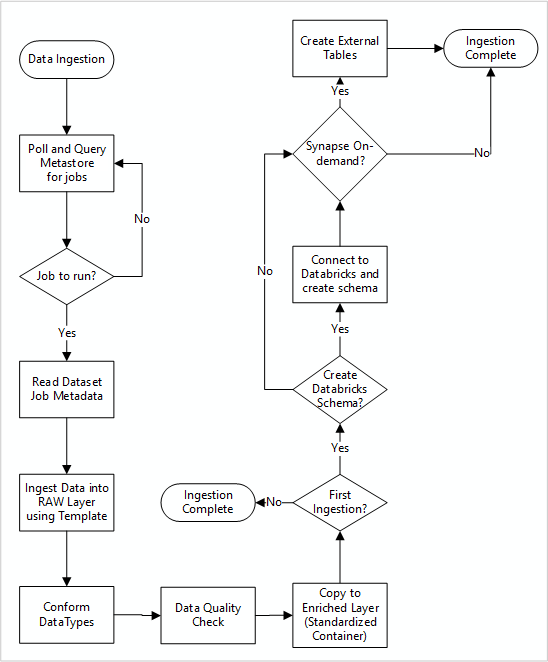
Data Factory-inmatningens huvudpipeline läser konfigurationer från ett Data Factory SQL Database-metaarkiv och kör sedan iterativt med rätt parametrar. Data överförs från källan till rådatalagret i Azure Data Lake med liten eller ingen ändring. Dataformen verifieras baserat på ditt Data Factory-metaarkiv. Filformat konverteras till antingen Apache Parquet- eller Avro-format och kopieras sedan till det berikade lagret.
Data som matas in ansluter till en Azure Databricks-arbetsyta för datavetenskap och teknik, och en datadefinition skapas i Apache Hive-metaarkivet i datalandningszonen.
Om du behöver använda en serverlös SQL-pool i Azure Synapse för att exponera data bör din anpassade lösning skapa vyer över data i sjön.
Om du behöver kryptering på radnivå eller kolumnnivå bör din anpassade lösning landa data i datasjön och sedan mata in data direkt i interna tabeller i SQL-poolerna och konfigurera lämplig säkerhet för SQL-poolberäkningen.
Insamlade metadata
När du använder automatiserad datainmatning kan du köra frågor mot associerade metadata och skapa instrumentpaneler för att:
- Spåra jobb och de senaste tidsstämplarna för dataladdning för dataprodukter relaterade till sina funktioner.
- Spåra tillgängliga dataprodukter.
- Växande datavolymer.
- Hämta realtidsuppdateringar om arbetsfel.
Operativa metadata kan användas för att spåra:
- Jobb, jobbsteg och deras beroenden.
- Jobbprestanda och prestandahistorik.
- Datavolymtillväxt.
- Jobbmisslyckanden
- Ändringar i källmetadata.
- Affärsfunktioner som är beroende av dataprodukter.
Använda Microsoft Purview REST API för att identifiera data
Microsoft Purview REST API:er bör användas för att registrera data under den första inmatningen. Du kan använda API:erna för att skicka data till datakatalogen strax efter att de har matats in.
Mer information finns i hur du använder Rest-API:er för Microsoft Purview.
Registrera datakällor
Använd följande API-anrop för att registrera nya datakällor:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}
URI-parametrar för datakällan:
| Namn | Krävs | Typ | Beskrivning |
|---|---|---|---|
accountName |
Sann | Sträng | Namnet på Microsoft Purview-kontot |
dataSourceName |
Sann | Sträng | Namnet på datakällan |
Använda Microsoft Purview REST API för registrering
Följande exempel visar hur du använder Microsoft Purview REST API för att registrera datakällor med nyttolaster:
Registrera en Azure Data Lake Storage Gen2-datakälla:
{
"kind":"AdlsGen2",
"name":"<source-name> (for example, My-AzureDataLakeStorage)",
"properties":{
"endpoint":"<endpoint> (for example, https://adls-account.dfs.core.windows.net/)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Registrera en SQL Database-datakälla:
{
"kind":"<source-kind> (for example, AdlsGen2)",
"name":"<source-name> (for example, My-AzureSQLDatabase)",
"properties":{
"serverEndpoint":"<server-endpoint> (for example, sqlservername.database.windows.net)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Note
<collection-name>är en aktuell samling som finns i ett Microsoft Purview-konto.
Skapa en skanning
Lär dig hur du kan skapa autentiseringsuppgifter för att autentisera källor i Microsoft Purview innan du konfigurerar och kör en genomsökning.
Använd följande API-anrop för att söka igenom datakällor:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/
URI-parametrar för en skanning:
| Namn | Krävs | Typ | Beskrivning |
|---|---|---|---|
accountName |
Sann | Sträng | Namnet på Microsoft Purview-kontot |
dataSourceName |
Sann | Sträng | Namnet på datakällan |
newScanName |
Sann | Sträng | Namnet på den nya genomsökningen |
Använda Microsoft Purview REST API för genomsökning
I följande exempel visas hur du kan använda Microsoft Purview REST API för att genomsöka datakällor med nyttolaster:
Skanna en datakälla för Azure Data Lake Storage Gen2:
{
"name":"<scan-name>",
"kind":"AdlsGen2Msi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AdlsGen2"
}
}
Genomsök en SQL Database-datakälla:
{
"name":"<scan-name>",
"kind":"AzureSqlDatabaseMsi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AzureSqlDatabase",
"databaseName": "<database-name>",
"serverEndpoint": "<server-endpoint> (for example, sqlservername.database.windows.net)"
}
}
Använd följande API-anrop för att genomsöka datakällor:
POST https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/run