Tillgänglighet via redundans – Azure SQL Database
gäller för:![]() Azure SQL Database
Azure SQL Database![]() SQL-databas i Fabric
SQL-databas i Fabric
Den här artikeln beskriver arkitekturen för Azure SQL Database och SQL Database i Fabric som uppnår tillgänglighet genom lokal redundans och hög tillgänglighet via zonredundans.
Överblick
Azure SQL Database och SQL Database i Fabric körs båda på den senaste stabila versionen av SQL Server Database Engine på Windows-operativsystemet med alla tillämpliga korrigeringar. SQL Database hanterar automatiskt kritiska underhållsaktiviteter, till exempel korrigeringar, säkerhetskopieringar, Windows- och SQL-motoruppgraderingar och oplanerade händelser, till exempel underliggande maskinvaru-, programvaru- eller nätverksfel. När en databas eller elastisk pool i SQL Database korrigeras eller redundansväxlar påverkas inte driftstoppet om du använda omprövningslogik i din app. SQL Database kan snabbt återställas även under de mest kritiska omständigheterna, vilket säkerställer att dina data alltid är tillgängliga. De flesta användare märker inte att uppgraderingar utförs kontinuerligt.
Som standard uppnår Azure SQL Database tillgänglighet genom lokal redundans, vilket gör databasen tillgänglig under:
- Kundinitierade hanteringsåtgärder som resulterar i en kort stilleståndstid
- Serviceunderhållsåtgärder
- Problem med:
- rack där datorerna som driver din tjänst körs
- fysisk dator som är värd för SQL-databasmotorn
- Andra problem med SQL-databasmotorn
- Andra potentiella oplanerade lokala avbrott
Standardtillgänglighetslösningen är utformad för att säkerställa att incheckade data aldrig går förlorade på grund av fel, att underhållsåtgärder inte påverkar din arbetsbelastning och att databasen inte är en enda felpunkt i din programvaruarkitektur.
Men för att minimera påverkan på dina data i händelse av ett avbrott i en hel zon kan du uppnå hög tillgänglighet genom att aktivera zonredundans. Utan zonredundans sker failover lokalt inom samma datacenter, vilket kan leda till att databasen inte är tillgänglig tills strömbortfallet har lösts. Det enda sättet att återställa är genom en haveriberedskapslösning, till exempel geo-failover via aktiv geo-replikering, failovergrupper, eller en geo-återställning av en geo-redundant säkerhetskopia. Mer information finns i översikt över affärskontinuitet.
Det finns tre arkitekturmodeller för tillgänglighet:
- Fjärrlagringsmodell som baseras på en separation av beräkning och lagring. Den förlitar sig på tillgängligheten och tillförlitligheten på fjärrlagringsnivån. Den här arkitekturen riktar sig till budgetorienterade affärsprogram som kan tolerera viss prestandaförsämring under underhållsaktiviteter.
- lokal lagringsmodell som baseras på ett kluster med databasmotorprocesser. Den förlitar sig på det faktum att det alltid finns ett kvorum med tillgängliga databasmotornoder. Den här arkitekturen riktar sig till verksamhetskritiska program med höga I/O-prestanda, hög transaktionshastighet och garanterar minimal prestandapåverkan på arbetsbelastningen under underhållsaktiviteter.
- Hyperskala-modell som använder ett distribuerat system med komponenter med hög tillgänglighet, till exempel beräkningsnoder, sidservrar, loggtjänst och beständig lagring. Varje komponent som stöder en Hyperskala-databas har sin egen redundans och motståndskraft mot fel. Beräkningsnoder, sidservrar och loggtjänst körs på Azure Service Fabric, som styr hälsotillståndet för varje komponent och utför redundansväxlingar till tillgängliga felfria noder efter behov. Beständig lagring använder Azure Storage med sina interna funktioner för hög tillgänglighet och redundans. Mer information finns i Hyperskala-arkitektur.
I var och en av de tre tillgänglighetsmodellerna stöder SQL Database lokala redundans- och zonredundansalternativ. Lokal redundans ger återhämtning i ett datacenter, medan zonredundans förbättrar återhämtning ytterligare genom att skydda mot avbrott i en tillgänglighetszon i en region.
I följande tabell visas tillgänglighetsalternativ baserat på tjänstnivåer:
| Tjänstnivå | Modell för hög tillgänglighet | Lokalt redundans tillgänglighet | Zonredundant tillgänglighet |
|---|---|---|---|
| Generell användning (vCore) | Fjärrlagring | Ja | Ja |
| Affärskritisk (vCore) | Lokal lagring | Ja | Ja |
| Hyperskala (vCore) | Hyperskala | Ja | Ja |
| Bas (DTU) | Fjärrlagring | Ja | Nej |
| Standard (DTU) | Fjärrlagring | Ja | Nej |
| Premium (DTU) | Lokal lagring | Ja | Ja |
Mer information om specifika serviceavtal för olika tjänstnivåer finns i serviceavtal för Azure SQL Database.
Tillgänglighet via lokal redundans
Lokalt redundant tillgänglighet baseras på lagring av databasen till lokalt redundant lagring (LRS) som kopierar dina data tre gånger inom ett enda datacenter i den primära regionen och skyddar dina data i händelse av lokala fel, till exempel ett småskaligt nätverk eller strömavbrott. LRS är det lägsta alternativet för redundans och erbjuder minst hållbarhet jämfört med andra alternativ. Om en storskalig katastrof som brand eller översvämning inträffar i en region kan alla repliker av ett lagringskonto som använder LRS gå förlorade eller oåterkalleliga. För att ytterligare skydda dina data när du använder det lokalt redundanta tillgänglighetsalternativet bör du överväga att använda ett mer motståndskraftigt lagringsalternativ för dina databassäkerhetskopior. Detta gäller inte för Hyperskala-databaser, där samma lagring används för både datafiler och säkerhetskopior.
Lokalt redundant tillgänglighet är tillgängligt för alla databaser på alla tjänstnivåer och Återställningspunktmål (RPO) som anger att mängden dataförlust är noll.
Tjänstnivåer för Basic, Standard och Generell användning
Tjänstnivåerna Basic och Standard för den DTU-baserade inköpsmodellen, samt tjänstnivån Allmänt syfte för den vCore-baserade inköpsmodellen, använder fjärrlagringstillgänglighetsmodellen för både serverlös och tillhandahållen beräkning. Följande bild visar fyra olika noder med de avgränsade beräknings- och lagringsskikten.
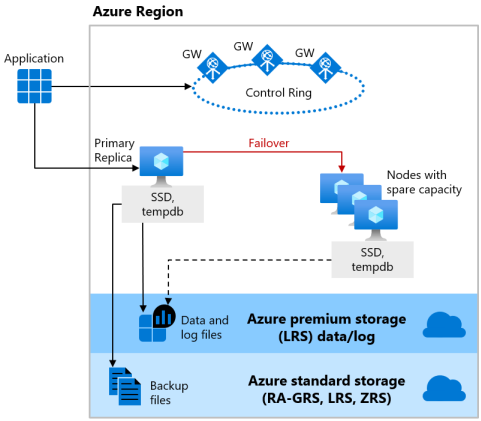
Tillgänglighetsmodellen för fjärrlagring innehåller två lager:
- Ett tillståndslöst beräkningslager som kör databasmotorprocessen och som endast innehåller tillfälliga och cachelagrade data, till exempel
tempdb- ochmodel-databaser på den anslutna SSD:en och planera cacheminne, buffertpool och kolumnlagringspool i minnet. Den här tillståndslösa noden drivs av Azure Service Fabric som initierar databasmotorn, kontrollerar nodens hälsotillstånd och utför redundans till en annan nod om det behövs. - Ett tillståndskänsligt datalager med databasfilerna (
.mdfoch.ldf) som lagras i Azure Blob Storage. Azure Blob Storage har inbyggda funktioner för datatillgänglighet och redundans. Det garanterar att varje post i loggfilen eller sidan i datafilen bevaras även om databasmotorprocessen kraschar.
När databasmotorn eller operativsystemet uppgraderas, eller om ett fel upptäcks, flyttar Azure Service Fabric den tillståndslösa databasmotorprocessen till en annan tillståndslös beräkningsnod med tillräcklig ledig kapacitet. Data i Azure Blob Storage påverkas inte av flytten och data-/loggfilerna är kopplade till den nyligen initierade databasmotorprocessen. Den här processen garanterar hög tillgänglighet, men en tung arbetsbelastning kan uppleva en viss prestandaförsämring under övergången eftersom den nya databasmotorprocessen börjar med kall cache.
Premium- och affärskritisk tjänstnivå
Premium-tjänstnivån för den DTU-baserade inköpsmodellen och tjänstnivån Affärskritisk för den VCore-baserade inköpsmodellen använda den lokala lagringstillgänglighetsmodellen, som integrerar beräkningsresurser (databasmotorprocess) och lagring (lokalt ansluten SSD) på en enda nod. Hög tillgänglighet uppnås genom att replikera både beräkning och lagring till ytterligare noder.
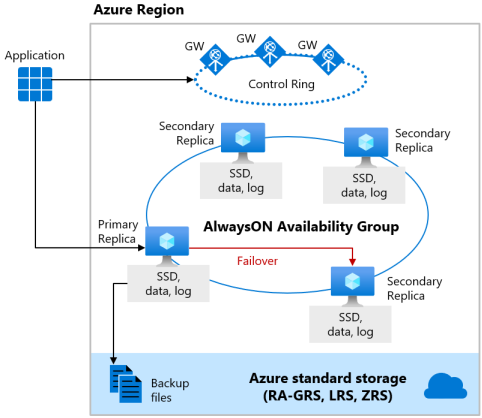
De underliggande databasfilerna (.mdf/.ldf) placeras på den anslutna SSD-lagringen för att ge mycket låg svarstids-I/O till din arbetsbelastning. Hög tillgänglighet implementeras med hjälp av en teknik som liknar SQL Server AlwaysOn-tillgänglighetsgrupper. Klustret innehåller en enda primär replik som är tillgänglig för kundarbetsbelastningar med läs- och skrivbehörighet och upp till tre sekundära repliker (beräkning och lagring) som innehåller kopior av data. Den primära repliken skickar ständigt ändringar till de sekundära replikerna i ordning och ser till att data sparas på ett tillräckligt antal sekundära repliker innan de genomför varje transaktion. Den här processen garanterar att om den primära repliken eller en läsbar sekundär replik kraschar av någon anledning finns det alltid en helt synkroniserad replik att redundansväxla till. Redundansväxlingen initieras av Azure Service Fabric. När en sekundär replik blir den nya primära repliken skapas en annan sekundär replik för att säkerställa att klustret har tillräckligt många repliker för att upprätthålla kvorum. När en failover är klar omdirigeras Azure SQL-anslutningar automatiskt till den nya primära repliken eller sekundär replika för läsning.
Som en extra fördel omfattar den lokala lagringstillgänglighetsmodellen möjligheten att omdirigera skrivskyddade Azure SQL-anslutningar till en av de sekundära replikerna. Den här funktionen kallas Read Scale-Out. Funktionen erbjuder 100% ytterligare beräkningskapacitet utan extra kostnad för att avlasta skrivskyddade operationer, som analytiska arbetsbelastningar, från den primära repliken.
Tjänstnivå för hyperskala
Arkitekturen på Hyperskala-tjänstnivå beskrivs i arkitekturen för distribuerade funktioner .

Tillgänglighetsmodellen i Hyperskala innehåller fyra lager:
- Ett tillståndslöst beräkningslager som kör databasmotorprocesserna och endast innehåller tillfälliga och cachelagrade data, till exempel icke-täckande RBPEX-cache,
tempdbochmodeldatabaser osv. på den anslutna SSD:n, samt plancache, buffertpool och kolumnlagringspool i minnet. Det här tillståndslösa lagret innehåller den primära beräkningsrepliken och eventuellt ett antal sekundära beräkningsrepliker som kan fungera som redundansmål. - Ett tillståndslöst lagringslager som bildas av sidservrar. Det här lagret är den distribuerade lagringsmotorn för databasmotorprocesserna som körs på beräkningsreplikerna. Varje sidserver innehåller endast tillfälliga och cachelagrade data, såsom RBPEX-cachen på den anslutna SSD:n och datasidor som lagras i minnet. Varje sidserver har en kopplad sidserver i en aktiv-aktiv konfiguration för att tillhandahålla belastningsutjämning, redundans och hög tillgänglighet.
- Ett tillståndskänsligt lagringslager för transaktionsloggar som bildas av beräkningsnoden som kör Log Service-processen, landningszonen för transaktionsloggen och långsiktig lagring av transaktionsloggar. Landningszon och långsiktig lagring använder Azure Storage, vilket ger tillgänglighet och redundans för transaktionsloggen, säkerställande av datahållbarheten för genomförda transaktioner.
- Ett tillståndskänsligt datalagringslager med databasfilerna (.mdf/.ndf) som lagras i Azure Storage och uppdateras av sidservrar. Det här lagret använder datatillgänglighet och redundans funktioner i Azure Storage. Det garanterar att varje sida i en datafil bevaras även om processer i andra lager av Hyperskala-arkitektur kraschar eller om beräkningsnoder misslyckas.
Beräkningsnoder i alla Hyperskala-lager körs på Azure Service Fabric, som styr hälsotillståndet för varje nod och utför redundansväxlingar till tillgängliga felfria noder efter behov.
Mer information om hög tillgänglighet i Hyperskala finns i Database High Availability in Hyperscale.
Hög tillgänglighet via zonredundans
Zonredundant tillgänglighet säkerställer att dina data är spridda över tre Azure-tillgänglighetszoner i den primära regionen. Varje tillgänglighetszon är en separat fysisk plats med oberoende ström, kylning och nätverk.
Zonredundant tillgänglighet är tillgänglig för databaser på tjänstnivåerna Affärskritisk, Generell användning och Hyperskala för den VCore-baserade inköpsmodellenoch endast Premium-tjänstnivån för den DTU-baserade inköpsmodellen – tjänstnivåerna Basic och Standard stöder inte zonredundans.
Varje tjänstnivå implementerar zonredundans på olika sätt, men alla implementeringar säkerställer ett mål för återställningspunkt (RPO) utan förlust av allokerade data vid redundansväxling.
Tjänstnivå för generell användning
Zonredundant konfiguration för tjänstenivån Allmänt ändamål erbjuds för både serverlös och tilldelad beräkningskapacitet för databaser i köpsmodell med vCore. Den här konfigurationen använder Azure-tillgänglighetszoner för att replikera databaser över flera fysiska platser i en Azure-region. Genom att välja zonredundans kan du göra dina nya och befintliga serverlösa och etablerade allmänna databaser och elastiska pooler motståndskraftiga mot en mycket större uppsättning fel, inklusive oåterkalleliga datacenterfel, utan några ändringar i programlogik.
Zonredundant konfiguration för nivån Allmänt bruk har två lager:
- Ett tillståndskänsligt datalager med databasfilerna (.mdf/.ldf) som lagras i ZRS (zonredundant lagring). Med hjälp av ZRS kopieras data- och loggfilerna synkront över tre fysiskt isolerade Azure-tillgänglighetszoner.
- Ett tillståndslöst beräkningslager som kör sqlservr.exe processen och som endast innehåller tillfälliga och cachelagrade data, till exempel
tempdb- ochmodel-databaser på den anslutna SSD:en, samt planera cacheminne, buffertpool och kolumnlagringspool i minnet. Den här tillståndslösa noden drivs av Azure Service Fabric som initierar sqlservr.exe, kontrollerar nodens hälsotillstånd och utför redundans till en annan nod om det behövs. För zonredundanta serverlösa och etablerade databaser för generell användning är noder med outnyttjad kapacitet lättillgängliga i andra tillgänglighetszoner för redundans.
Den zonredundanta versionen av arkitekturen med hög tillgänglighet för tjänstnivån Generell användning illustreras av följande diagram:
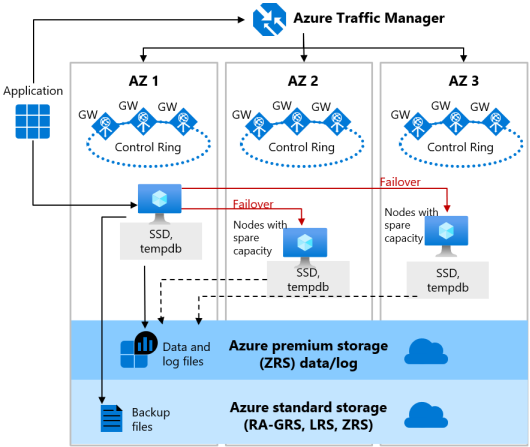
Tänk på följande när du konfigurerar dina allmänna databaser med zonredundans:
- För nivån Generell användning är zonredundant konfiguration allmänt tillgänglig i följande regioner:
- (Afrika) Sydafrika, norra
- (Asien och Stillahavsområdet) Australien, östra
- (Asien och Stillahavsområdet) Asien, östra
- (Asien och Stillahavsområdet) Japan, östra
- (Asien och Stillahavsområdet) Korea, centrala
- (Asien och Stillahavsområdet) Sydostasien
- (Asien och Stillahavsområdet) Indien, centrala
- (Asien och Stillahavsområdet) Kina, norra 3
- (Asien och Stillahavsområdet) Förenade Arabemiraten, norra
- (Europa) Frankrike, centrala
- (Europa) Tyskland, västra centrala
- (Europa) Italien, norra
- (Europa) Europa, norra
- (Europa) Norge, östra
- (Europa) Polen, centrala
- (Europa) Västeuropa
- (Europa) Storbritannien, södra
- (Europa) Schweiz, norra
- (Europa) Sverige, centrala
- (Mellanöstern) Israel, centrala
- (Mellanöstern) Qatar Central
- (Nordamerika) Kanada, centrala
- (Nordamerika) USA, centrala
- (Nordamerika) USA, östra
- (Nordamerika) Östra USA 2
- (Nordamerika) Sydcentrala USA
- (Nordamerika) Västra USA 2
- (Nordamerika) Väst USA 3
- (Sydamerika) Brasilien, södra
- För zonredundant tillgänglighet är det för närvarande tillgängligt att välja en underhållsperiod annat än standard i välja regioner.
- Zonredundant konfiguration är endast tillgängligt i SQL Database när standardseriemaskinvara (Gen5) har valts.
- Zonredundans är inte tillgängligt för basic- och standardtjänstnivåer i DTU-inköpsmodellen.
Premium- och affärskritiska tjänstnivåer
När Zonredundans är aktiverat för premium- eller affärskritisk tjänstnivå placeras replikerna i olika tillgänglighetszoner i samma region. För att eliminera en enskild felpunkt dupliceras även kontrollringen över flera zoner som tre gatewayringar (GW). Routningen till en specifik gatewayring styrs av Azure Traffic Manager-. Eftersom den zonredundanta konfigurationen på tjänstnivåerna Premium eller Affärskritisk använder sina befintliga repliker för att placera i olika tillgänglighetszoner kan du aktivera den utan extra kostnad. Genom att välja en zonredundant konfiguration kan du göra dina Premium- eller Affärskritiska databaser och elastiska pooler motståndskraftiga mot en mycket större uppsättning fel, inklusive oåterkalleliga datacenterfel, utan några ändringar i programlogik. Du kan också konvertera befintliga Premium- eller affärskritiska databaser eller elastiska pooler till zonredundant konfiguration.
Den zonredundanta versionen av arkitekturen för hög tillgänglighet illustreras av följande diagram:
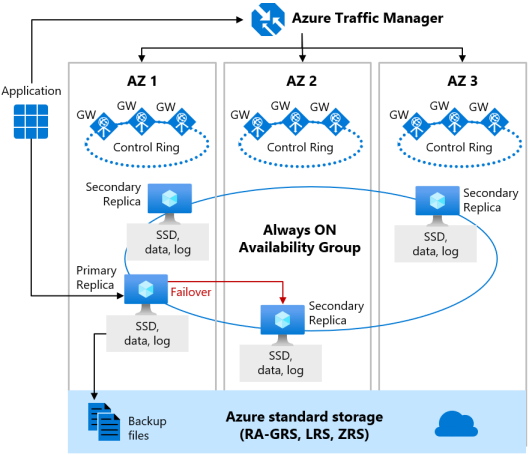
Tänk på följande när du konfigurerar dina Premium- eller Affärskritiska databaser med zonredundans:
- Uppdaterad information om de regioner som stöder zonredundanta databaser finns i Services-stöd per region.
- För zonredundant tillgänglighet är det för närvarande möjligt att välja en underhållsperiod annat än standard i utvalda regioner.
Tjänstnivå för hyperskala
Det går att konfigurera zonredundans för databaser på tjänstnivån Hyperskala. Mer information finns i Skapa zonredundant Hyperskala-databas.
Om du aktiverar den här konfigurationen säkerställs återhämtning på zonnivå genom replikering mellan tillgänglighetszoner för alla Hyperskala-lager. Genom att välja zonredundans kan du göra dina Hyperskala-databaser motståndskraftiga mot en mycket större uppsättning fel, inklusive oåterkalleliga datacenteravbrott, utan några ändringar i programlogik. Alla Azure-regioner som har tillgänglighetszoner stöder zonredundant Hyperscale-databas. Zonredundansstöd för Hyperskala-PRMS- och MOPRMS-maskinvara är tillgängligt i regioner som anges här.
Zonredundant tillgänglighet stöds i både fristående Hyperskala-databaser och elastiska hyperskalapooler. Mer information finns i elastiska hyperskalapooler.
Följande diagram visar den underliggande arkitekturen för zonredundanta Hyperskala-databaser:

Tänk på följande begränsningar:
Zonredundant konfiguration kan bara anges när databasen skapas. Den här inställningen kan inte ändras när resursen har etablerats. Använd Databaskopiering, återställning till tidpunkteller skapa en geo-replik för att uppdatera den zonredundanta konfigurationen för en befintlig Hyperskala-databas. När en av dessa uppdateringsalternativ används, om måldatabasen finns i en annan region än källan eller om redundansen i databassäkerhetskopiering från målet skiljer sig från källans, kommer kopieringsåtgärden att vara en dataoperation baserad på storlek.
För zonredundant tillgänglighet är det för närvarande möjligt att välja en annan underhållsperiod än standard i utvalda regioner.
Det finns för närvarande inget alternativ för att ange zonredundans när du migrerar en databas till Hyperskala med hjälp av Azure-portalen. Zonredundans kan dock anges med hjälp av Azure PowerShell, Azure CLI eller REST-API:et när du migrerar en befintlig databas från en annan Azure SQL Database-tjänstnivå till Hyperskala. Här är ett exempel med Azure CLI:
az sql db update --resource-group "myRG" --server "myServer" --name "myDB" --edition Hyperscale --zone-redundant true`Minst 1 datorkopia med hög tillgänglighet och användning av zonredundant eller geo-zonredundant säkerhetskopieringslagring krävs för att aktivera konfiguration med zonredundans för Hyperscale.
Redundant tillgänglighet för databaszon
I Azure SQL Database är en server en logisk konstruktion som fungerar som en central administrativ plats för en samling databaser. På servernivå kan du administrera inloggningar, autentiseringsmetod, brandväggsregler, granskningsregler, principer för hotidentifiering och redundansgrupper. Data som rör vissa av dessa funktioner, till exempel inloggningar och brandväggsregler, lagras i master-databasen. På samma sätt lagras även data för vissa DMV:er, till exempel sys.resource_stats, i master-databasen.
När en databas med en zonredundant konfiguration skapas på en logisk server blir även den master databas som är associerad med servern automatiskt zonredundant. Detta säkerställer att program som använder databasen i ett zonindelad avbrott fortfarande inte påverkas eftersom funktioner som är beroende av master-databasen, till exempel inloggningar och brandväggsregler, fortfarande är tillgängliga. Att göra master databaszonredundant är en asynkron process och tar lite tid att slutföra i bakgrunden.
När ingen av databaserna på en server är zonredundant, eller när du skapar en tom server, är den master databas som är associerad med servern inte zonredundant.
Du kan använda Azure PowerShell eller Azure CLI eller REST API- för att kontrollera egenskapen ZoneRedundant för master-databasen:
Använd följande exempelkommando för att kontrollera värdet för egenskapen "ZoneRedundant" för master databas.
Get-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "myServerName" -DatabaseName "master"
Testa applikationsfelmotståndskraft
Hög tillgänglighet är en grundläggande del av SQL Database-plattformen som fungerar transparent för ditt databasprogram. Vi inser dock att du kanske vill testa hur de automatiska redundansåtgärder som initierades under planerade eller oplanerade händelser skulle påverka ett program innan du distribuerar det till produktion. Du kan utlösa en redundansväxling manuellt genom att anropa ett särskilt API för att starta om en databas eller en elastisk pool. Om det gäller en zonredundant serverlös eller etablerad databas för generell användning eller elastisk pool skulle API-anropet leda till att klientanslutningar omdirigeras till den nya primära i en tillgänglighetszon som skiljer sig från tillgänglighetszonen för den gamla primära. Förutom att testa hur redundans påverkar befintliga databassessioner kan du även kontrollera om det ändrar prestanda från slutpunkt till slutpunkt på grund av ändringar i nätverksfördröjningen. Eftersom omstartsåtgärden är påträngande och ett stort antal av dem kan stressa plattformen tillåts endast ett redundansanrop var 15:e minut för varje databas eller elastisk pool.
Mer information om hög tillgänglighet och haveriberedskap i Azure SQL Database finns i HA/DR Checklista.
En failover kan initieras med hjälp av PowerShell, REST API eller Azure CLI.
| Distributionstyp | PowerShell | REST API | Azure CLI |
|---|---|---|---|
| Databas | Invoke-AzSqlDatabaseFailover | Databas-failover | az rest kan användas för att anropa ett REST API-anrop från Azure CLI |
| Elastisk resurspool | Invoke-AzSqlElasticPoolFailover | Felflyttning i elastisk databaspool | az rest kan användas för att anropa ett REST API-anrop från Azure CLI |
Viktig
Redundanskommandot är inte tillgängligt för läsbara sekundära repliker av Hyperskala-databaser.
Slutsats
Azure SQL Database har en inbyggd lösning med hög tillgänglighet som är djupt integrerad med Azure-plattformen. Det är beroende av Service Fabric för felidentifiering och återställning, för Azure Blob Storage för dataskydd och på tillgänglighetszoner för högre feltolerans. Dessutom använder SQL Database alwayson-tillgänglighetsgruppens teknik från SQL Server för datasynkronisering och redundans. Kombinationen av dessa tekniker gör det möjligt för program att fullt ut utnyttja fördelarna med en modell för blandad lagring och har stöd för de mest krävande serviceavtalen.
Relaterat innehåll
Mer information finns i: