Hantera filutrymme för databaser i Azure SQL Database
gäller för:![]() Azure SQL Database
Azure SQL Database
I den här artikeln beskrivs olika typer av lagringsutrymme för databaser i Azure SQL Database. Även om det är ovanligt innehåller den här artikeln steg som kan vidtas när det allokerade filutrymmet måste hanteras explicit.
Överblick
Med Azure SQL Database finns det arbetsbelastningsmönster där allokeringen av underliggande datafiler för databaser kan bli större än antalet använda datasidor. Det här villkoret kan inträffa när utrymmet som används ökar och data tas bort senare. Orsaken är att det allokerade filutrymmet inte frigörs automatiskt när data tas bort.
Övervakning av filutrymmesanvändning och krympande datafiler kan vara nödvändigt i följande scenarier:
- Tillåt datatillväxt i en elastisk pool när filutrymmet som allokerats för dess databaser når poolens maxstorlek.
- Tillåt att du minskar maxstorleken för en enskild databas eller elastisk pool.
- Tillåt ändring av en enskild databas eller elastisk pool till en annan tjänstnivå eller prestandanivå med en lägre maxstorlek.
Not
Krympningsåtgärder bör inte betraktas som en vanlig underhållsåtgärd. Data och loggfiler som växer på grund av regelbundna, återkommande affärsåtgärder kräver inte krympningsåtgärder.
Övervaka filutrymmesanvändning
De flesta mått för lagringsutrymme som visas i följande API:er mäter bara storleken på använda datasidor:
- Azure Resource Manager-baserade metrik-API:er, inklusive PowerShell get-metrics
Men följande API:er mäter också storleken på det utrymme som allokerats för databaser och elastiska pooler:
- T-SQL: sys.resource_stats
- T-SQL: sys.elastic_pool_resource_stats
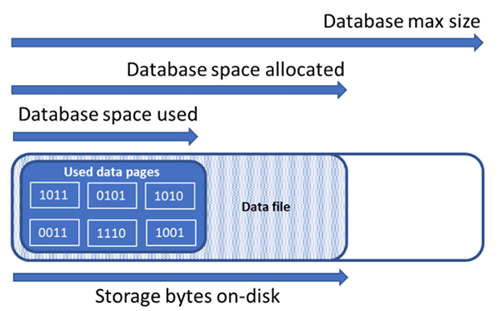
Förstå typer av lagringsutrymme för en databas
Det är viktigt att förstå följande lagringsutrymmeskvantiteter för att hantera filutrymmet i en databas.
| Databaskvantitet | Definition | Kommentarer |
|---|---|---|
| Datautrymme som används | Mängden utrymme som används för att lagra databasdata. | I allmänhet ökar utrymmet som används (minskar) vid infogningar (borttagningar). I vissa fall ändras inte det utrymme som används vid infogningar eller borttagningar beroende på mängden och mönstret för data som ingår i åtgärden och eventuell fragmentering. Om du till exempel tar bort en rad från varje datasida minskar inte nödvändigtvis det utrymme som används. |
| Allokerat datautrymme | Mängden formaterat filutrymme som görs tillgängligt för lagring av databasdata. | Mängden allokerat utrymme växer automatiskt, men minskar aldrig efter borttagningar. Det här beteendet säkerställer att framtida infogningar går snabbare eftersom utrymmet inte behöver formateras om. |
| Allokerat datautrymme men oanvänt | Skillnaden mellan mängden allokerat datautrymme och det datautrymme som används. | Den här kvantiteten representerar den maximala mängden ledigt utrymme som kan frigöras genom krympande databasdatafiler. |
| Data maxstorlek | Den maximala mängden utrymme som kan användas för att lagra databasdata. | Mängden allokerat datautrymme kan inte öka utöver data maxstorleken. |
Följande diagram illustrerar relationen mellan de olika typerna av lagringsutrymme för en databas.
Fråga en enskild databas om information om filutrymme
Använd följande fråga på sys.database_files för att returnera mängden allokerat databasfilutrymme och mängden oanvänt utrymme som allokerats. Enheter i frågeresultatet är i MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Förstå typer av lagringsutrymme för en elastisk pool
Det är viktigt att förstå följande lagringsutrymmeskvantiteter för att hantera filutrymmet i en elastisk pool.
| Elastiskt poolantal | Definition | Kommentarer |
|---|---|---|
| Datautrymme som används | Sammanfattningen av datautrymme som används av alla databaser i den elastiska poolen. | |
| Allokerat datautrymme | Sammanfattningen av datautrymme som allokerats av alla databaser i den elastiska poolen. | |
| Allokerat datautrymme men oanvänt | Skillnaden mellan mängden allokerat datautrymme och det datautrymme som används av alla databaser i den elastiska poolen. | Den här kvantiteten representerar den maximala mängden utrymme som allokerats för den elastiska poolen som kan frigöras genom krympande databasdatafiler. |
| Maximal storlek på data | Den maximala mängden datautrymme som kan användas av den elastiska poolen för alla dess databaser. | Det utrymme som allokerats för den elastiska poolen får inte överskrida maxstorleken för den elastiska poolen. Om det här villkoret inträffar kan det utrymme som allokeras som inte används frigöras genom krympande databasdatafiler. |
Not
Felmeddelandet "Den elastiska poolen har nått sin lagringsgräns" anger att databasobjekten har allokerats tillräckligt med utrymme för att uppfylla lagringsgränsen för elastisk pool, men det kan finnas outnyttjat utrymme i allokeringen av datautrymme. Överväg att öka den elastiska poolens lagringsgräns, eller som en kortsiktig lösning, frigöra datautrymme med hjälp av exemplen i Frigöra oanvänt allokerat utrymme. Du bör också vara medveten om den potentiella negativa prestandapåverkan av krympande databasfiler. Se underhåll av index efter krympning.
Fråga efter information om lagringsutrymme i en elastisk pool
Följande frågor kan användas för att fastställa lagringsutrymmeskvantiteter för en elastisk pool.
Elastiskt pooldatautrymme som används
Ändra följande fråga för att returnera mängden elastiskt pooldatautrymme som används. Enheter i frågeresultatet är i MB.
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Elastiskt pooldatautrymme allokerat och oanvänt allokerat utrymme
Ändra följande exempel för att returnera en tabell som visar det allokerade och oanvända allokerade utrymmet för varje databas i en elastisk pool. Tabellen beställer databaser från dessa databaser med den största mängden oanvänt allokerat utrymme till den minsta mängden oanvänt allokerat utrymme. Enheter i frågeresultatet är i MB.
Frågeresultaten för att fastställa det tilldelade utrymmet för varje databas i poolen kan läggas till tillsammans för att fastställa det totala utrymmet som allokerats för den elastiska poolen. Det elastiska poolutrymme som allokerats får inte överskrida maxstorleken för den elastiska poolen.
Viktig
AzureRM-modulen för PowerShell Azure Resource Manager blev avvecklad den 29 februari 2024. All framtida utveckling bör använda Az.Sql-modulen. Användare rekommenderas att migrera från AzureRM till Az PowerShell-modulen för att säkerställa fortsatt support och uppdateringar. AzureRM-modulen underhålls inte längre eller stöds inte längre. Argumenten för kommandona i Az PowerShell-modulen och i AzureRM-modulerna är i stort sätt identiska. Mer information om deras kompatibilitet finns i Introduktion till den nya Az PowerShell-modulen.
PowerShell-skriptet kräver SQL Server PowerShell-modul. Mer information finns i SQL Server PowerShell-modulen.
Följande PowerShell-skript slutför dessa steg:
- Deklarera variabler. Ersätt dessa värden med dina värden.
- Hämta en lista över databaser i elastisk pool.
- För varje databas i den elastiska poolen får du utrymme allokerat i MB och utrymme som allokerats oanvänt i MB.
- Visa databaser i fallande ordning efter oanvänt allokerat utrymme.
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of unused allocated space
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
Följande skärmbild är ett exempel på utdata från skriptet:

Maximal storlek för data i elastisk pool
Ändra följande T-SQL-fråga för att returnera den senast registrerade maximala storleken för elastiska pooldata. Enheter i frågeresultatet är i MB.
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Frigöra oanvänt allokerat utrymme
Viktig
Krympa kommandon påverkar databasens prestanda vid körning och bör om möjligt köras under perioder med låg användning.
Krympa datafiler
På grund av en potentiell inverkan på databasprestandan krymper inte Azure SQL Database automatiskt datafiler. Kunder kan dock krympa datafiler via självbetjäning vid valfri tidpunkt. Detta bör inte vara en regelbundet schemalagd åtgärd, utan snarare en engångshändelse som svar på en stor minskning av datafilens användning av utrymmesförbrukning.
Tips
Slösa inte tid på att krympa datafiler om den vanliga programarbetsbelastningen gör att filerna växer till samma allokerade storlek igen. Händelser för filtillväxt kan försämra applikationens prestanda.
Om du vill krympa filer i Azure SQL Database kan du använda kommandona DBCC SHRINKDATABASE eller DBCC SHRINKFILE:
-
DBCC SHRINKDATABASEkrymper alla data och loggfiler i en databas med ett enda kommando. Kommandot krymper en datafil i taget, vilket kan ta lång tid för större databaser. Det också krymper loggfilen, vilket vanligtvis är onödigt eftersom Azure SQL Database krymper loggfilerna automatiskt efter behov. -
DBCC SHRINKFILE-kommandot stöder mer avancerade scenarier:- Den kan rikta in sig på enskilda filer efter behov i stället för att krympa alla filer i databasen.
- Varje
DBCC SHRINKFILEkommando kan köras parallellt med andraDBCC SHRINKFILEkommandon för att krympa flera filer samtidigt och minska den totala tiden för krympning, på bekostnad av högre resursanvändning och en högre chans att blockera användarfrågor, om de körs under krympning.- Om du krymper flera datafiler samtidigt kan du slutföra krympningsåtgärden snabbare. Om du använder samtidig datafilskrympning kan du observera tillfällig blockering av en krympningsbegäran av en annan.
- Om filens svans inte innehåller data kan den minska den allokerade filstorleken snabbare genom att ange argumentet
TRUNCATEONLY. Detta kräver inte dataförflyttning i filen.
- Mer information om dessa krympningskommandon finns i DBCC SHRINKDATABASE och DBCC SHRINKFILE.
Följande exempel måste köras när man är ansluten till målanvändardatabasen, inte den master-databasen.
Så här använder du DBCC SHRINKDATABASE för att krympa alla data och loggfiler i en viss databas:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
I Azure SQL Database kan en databas ha en eller flera datafiler som skapas automatiskt när data växer. För att fastställa fillayouten för din databas, inklusive den använda och tilldelade storleken för varje fil, anropar du katalogvisningen "sys.database_files" med hjälp av följande exempelskript:
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
Du kan bara köra en krympning mot en fil via kommandot DBCC SHRINKFILE, till exempel:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
Tänk på den potentiella negativa prestandapåverkan av krympande databasfiler. Mer information finns i indexunderhåll efter krympning.
Krymp transaktionsloggfil
Till skillnad från datafiler krymper Azure SQL Database automatiskt transaktionsloggfilen för att undvika överdriven utrymmesanvändning som kan leda till out-of-space-fel. Det är vanligtvis inte nödvändigt för kunder att krympa transaktionsloggfilen.
Om transaktionsloggen blir stor i premium- och affärskritiska tjänstnivåer kan den avsevärt bidra till den lokala lagringsförbrukningen mot den maximala gränsen för lokal lagring. Om den lokala lagringsförbrukningen ligger nära gränsen kan kunderna välja att krympa transaktionsloggen med hjälp av kommandot DBCC SHRINKFILE enligt följande exempel. Detta frigör lokal lagring så snart kommandot har slutförts, utan att vänta på den periodiska automatiska krympningsåtgärden.
Följande exempel ska köras när du är ansluten till målanvändardatabasen, inte den master-databasen.
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
Krymp automatiskt
Som ett alternativ till att krympa datafiler manuellt kan automatisk krympning aktiveras för en databas. Automatisk krympning kan dock vara mindre effektivt när det gäller att frigöra filutrymme än DBCC SHRINKDATABASE och DBCC SHRINKFILE.
Som standard inaktiveras automatisk krympning, vilket rekommenderas för de flesta databaser. Om det blir nödvändigt att aktivera automatisk krympning rekommenderar vi att du inaktiverar det när målen för utrymmeshantering har uppnåtts, i stället för att behålla det permanent. Mer information finns i Överväganden för AUTO_SHRINK.
Till exempel kan automatisk krympning vara användbart i det specifika scenariot där en elastisk pool innehåller många databaser som upplever betydande tillväxt och minskning av det datafilutrymme som används, vilket gör att poolen närmar sig sin maximala storleksgräns. Detta är inte ett vanligt scenario.
Om du vill aktivera automatisk krympning kör du följande kommando när du är ansluten till databasen (inte den master databasen).
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
Mer information om det här kommandot finns i DATABASE SET-alternativ.
Indexunderhåll efter krympning
När en krympningsåtgärd har slutförts mot datafiler kan index bli fragmenterade. Detta minskar deras prestandaoptimeringseffektivitet för vissa arbetsbelastningar, till exempel frågor som använder stora genomsökningar. Om prestandaförsämringen inträffar när krympningsåtgärden är klar bör du överväga indexunderhåll för att återskapa index. Tänk på att återskapade index kräver ledigt utrymme i databasen, vilket kan leda till att det allokerade utrymmet ökar, vilket motverkar effekten av krympning.
Mer information om indexunderhåll finns i Optimera indexunderhåll för att förbättra frågeprestanda och minska resursförbrukningen.
Krympa stora databaser
När databasens allokerade utrymme är i hundratals gigabyte eller högre kan krympning kräva en betydande tid att slutföra, ofta mätt i timmar eller dagar för databaser med flera terabyte. Det finns processoptimeringar och metodtips som du kan använda för att göra den här processen mer effektiv och mindre påverkande för programarbetsbelastningar.
Upprätta baslinje för utrymmesanvändning
Innan du börjar krympa samlar du in aktuellt använt och allokerat utrymme i varje databasfil genom att köra följande fråga om utrymmesanvändning:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
När krympningen har slutförts kan du köra den här frågan igen och jämföra resultatet med den första baslinjen.
Trunkera datafiler
Vi rekommenderar att du först kör shrink för varje datafil med parametern TRUNCATEONLY. På så sätt, om det finns något allokerat men oanvänt utrymme i slutet av filen, tas det bort snabbt och utan någon dataflytt. Följande exempelkommando förkortar datafilen med fil_id 4.
DBCC SHRINKFILE (4, TRUNCATEONLY);
När det här kommandot har körts för varje datafil kan du köra frågan om utrymmesanvändning igen för att se minskningen av allokerat utrymme, om det finns några. Du kan också visa allokerat utrymme för databasen i Azure-portalen.
Utvärdera indexsidans densitet
Om trunkering av datafiler inte resulterade i en tillräcklig minskning av allokerat utrymme måste du krympa datafiler. Men som ett valfritt men rekommenderat steg bör du först bestämma genomsnittlig sidtäthet för index i databasen. För samma mängd data slutförs krympningsåtgärderna snabbare om sidtätheten är hög, eftersom den måste flytta färre sidor. Om sidtätheten är låg för vissa index bör du överväga att utföra underhåll på dessa index för att öka sidtätheten innan datafilerna krymps. Detta gör också att krympning kan minska det allokerade lagringsutrymmet djupare.
Använd följande fråga för att fastställa hur täta sidorna är för alla index i databasen. Siddensitet rapporteras i kolumnen avg_page_space_used_in_percent.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Om det finns index med högt sidantal som har sidtäthet som är lägre än 60–70%kan du överväga att återskapa eller omorganisera dessa index innan du krymper datafilerna.
Not
För större databaser kan det ta lång tid (timmar) att slutföra frågan för att bestämma sidtätheten. Dessutom kräver återskapande eller omorganisering av stora index också betydande tids- och resursanvändning. Det finns en kompromiss mellan att spendera extra tid på att öka sidtätheten å ena sidan och minska krympningstiden och uppnå högre utrymmesbesparingar på en annan.
Om det finns flera index med låg sidtäthet kanske du kan återskapa dem parallellt på flera databassessioner för att påskynda processen. Kontrollera dock att du inte närmar dig databasresursgränserna genom att göra det och lämna tillräckligt med resursutrymme för programarbetsbelastningar som kan köras. Övervaka resursförbrukning (CPU, data-I/O, logg-I/O) i Azure-portalen eller med hjälp av vyn sys.dm_db_resource_stats. Starta ytterligare parallella återskapanden endast om resursutnyttjandet för var och en av dessa dimensioner fortfarande är betydligt lägre än 100%. Om processor-, data-I/O- eller logg-I/O-användningen är 100%kan du skala upp databasen så att den har fler CPU-kärnor och öka I/O-dataflödet. Detta kan möjliggöra ytterligare parallella återskapanden för att slutföra processen snabbare.
Exempel på återskapningskommando för index
Följande är ett exempelkommando för att återskapa ett index och öka dess sidtäthet med hjälp av instruktionen ALTER INDEX:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Det här kommandot initierar en online- och återupptagningsbar indexåterbyggnad. På så sätt kan samtidiga arbetsbelastningar fortsätta använda tabellen medan återskapningen pågår, och du kan återuppta återskapandet om det avbryts oavsett orsak. Den här typen av återskapande är dock långsammare än en offline-återskapande, vilket blockerar åtkomsten till tabellen. Om inga andra arbetsbelastningar behöver komma åt tabellen under återuppbyggnaden ställer du in ONLINE- och RESUMABLE-alternativen till OFF och tar bort WAIT_AT_LOW_PRIORITY-villkoret.
Mer information om indexunderhåll finns i Optimera indexunderhåll för att förbättra frågeprestanda och minska resursförbrukningen.
Krymp flera datafiler
Som tidigare nämnts är krympning med dataförflyttning en tidskrävande process. Om databasen har flera datafiler kan du påskynda processen genom att krympa flera datafiler parallellt. Du gör detta genom att öppna flera databassessioner och använda DBCC SHRINKFILE på varje session med olika file_id värde. Likt tidigare indexåterbyggnad, se till att du har tillräckligt med resurser (CPU, data-I/O, logg-I/O) innan du startar varje nytt parallellt krympningskommando.
Följande exempelkommando krymper datafilen med file_id 4 och försöker minska den allokerade storleken till 52 000 MB genom att flytta sidor i filen:
DBCC SHRINKFILE (4, 52000);
Om du vill minska det allokerade utrymmet för filen så mycket som möjligt kör du -instruktionen utan att ange målstorleken:
DBCC SHRINKFILE (4);
Om en arbetsbelastning körs samtidigt med krympning kan den börja använda lagringsutrymmet som frigörs genom krympning innan krympningen slutförs och trunkerar filen. I det här fallet kan krympning inte minska allokerat utrymme till det angivna målet.
Du kan minimera detta genom att krympa varje fil i mindre steg. Det innebär att i kommandot DBCC SHRINKFILE anger du målet som är något mindre än det aktuella allokerade utrymmet för filen, enligt resultatet av baslinjeutrymmesanvändningsfråga. Om till exempel allokerat utrymme för fil med file_id 4 är 200 000 MB och du vill minska det till 100 000 MB, kan du först ange målet till 170 000 MB:
DBCC SHRINKFILE (4, 170000);
När det här kommandot har slutförts har den trunkerat filen och minskat dess allokerade storlek till 170 000 MB. Du kan sedan upprepa det här kommandot och först ange målet till 140 000 MB, sedan till 110 000 MB och så vidare tills filen krymps till önskad storlek. Om kommandot slutförs men filen inte trunkeras använder du mindre steg, till exempel 15 000 MB i stället för 30 000 MB.
Om du vill övervaka krympningsstatus för alla samtidiga krympningssessioner kan du använda följande fråga:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Not
Krympningsförloppet kan vara icke-linjärt och värdet i kolumnen percent_complete kan förbli oförändrat under långa tidsperioder, även om krympning fortfarande pågår.
När krympningen är klar för alla datafiler kör du frågan utrymmesanvändning (eller kontrollerar i Azure-portalen) för att fastställa den resulterande minskningen av tilldelad lagringskapacitet. Om det fortfarande finns en stor skillnad mellan använt utrymme och allokerat utrymme återskapa index. Detta kan tillfälligt öka allokerat utrymme ytterligare, men krympande datafiler igen efter återskapande av index bör resultera i en djupare minskning av allokerat utrymme.
Tillfälliga fel under krympning
Ibland kan ett krympningskommando misslyckas med olika fel, till exempel tidsgränser och dödlägen. I allmänhet är dessa fel tillfälliga och inträffar inte igen om samma kommando upprepas. Om krympning misslyckas med ett fel behålls de framsteg som gjorts hittills när det gäller att flytta datasidor och samma krympningskommando kan köras igen för att fortsätta krympa filen.
Följande exempelskript visar hur du kan köra kommandot 'shrink' i en loop för återförsök för att automatiskt försöka igen upp till ett konfigurerbart antal gånger när ett timeoutfel eller ett dödlägesfel inträffar. Den här metoden för återförsök gäller för många andra fel som kan uppstå under krympning.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
Förutom tidsgränser och dödlägen kan optimeringsprocessen stöta på fel på grund av vissa kända problem.
De fel som returneras och åtgärdsstegen är följande:
- Felnummer: 49503, felmeddelande: %.*ls: Sida %d:%d kunde inte flyttas eftersom det är en beständig versionsarkivsida utanför rad. Orsak till sidfördröjning: %ls. Fördröjningstidsstämpel: %I64d.
Det här felet uppstår när det finns långvariga aktiva transaktioner som har genererat radversioner i det beständiga versionsarkivet (PVS). Sidorna som innehåller dessa radversioner kan inte flyttas genom krympning och resulterar i detta fel.
För att minimera måste du vänta tills de här långvariga transaktionerna har slutförts. Du kan också identifiera och avsluta dessa långvariga transaktioner, men det kan påverka ditt program om det inte hanterar transaktionsfel på ett korrekt sätt. Ett sätt att hitta långvariga transaktioner är genom att köra följande fråga i databasen där du körde kommandot shrink:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
Du kan avsluta en transaktion med hjälp av kommandot KILL och ange det associerade session_id värdet från frågeresultatet:
KILL 4242; -- replace 4242 with the session_id value from query results
Försiktighet
Att avsluta en transaktion kan påverka arbetsbelastningar negativt.
När långvariga transaktioner har avslutats eller slutförts kommer en intern bakgrundsprocess att rensa bort radversioner som inte längre behövs efter ett tag. Du kan övervaka PVS-storleken för att mäta rensningsstatusen med hjälp av följande fråga. Kör frågan i databasen där du körde krympningskommandot:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
När PVS-storleken som rapporteras i kolumnen persistent_version_store_size_gb har minskats avsevärt jämfört med dess ursprungliga storlek, bör det lyckas att köra om krympningen.
- Felnummer: 5223, felmeddelande: %.*ls: Tom sida %d:%d kunde inte frigöras.
Det här felet kan inträffa om det finns pågående indexunderhållsåtgärder, till exempel ALTER INDEX. Försök förminska kommandot igen när de här åtgärderna har slutförts.
Om det här felet kvarstår kan det associerade indexet behöva återskapas. Kör följande fråga i samma databas där du körde krympningskommandot för att hitta indexet som ska återskapas:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
Innan du kör den här frågan ersätter du platshållarna <file_id> och <page_id> med de faktiska värdena från felmeddelandet du fick. Om meddelandet till exempel är Tom sida 1:62669 inte kunde frigöras, så är <file_id>1 och <page_id> är 62669.
Återskapa indexet som identifieras av frågan och försök igen med krympningskommandot.
- Felnummer: 5201, felmeddelande: DBCC SHRINKDATABASE: Fil-ID %d databas-ID %d hoppades över eftersom filen inte har tillräckligt med ledigt utrymme att frigöra.
Det här felet innebär att datafilen inte kan krympas ytterligare. Du kan gå vidare till nästa datafil.
Relaterat innehåll
Information om databasens maxstorlekar finns i:
- Azure SQL Database vCore-baserade inköpsmodellgränser för en enskild databas
- Resursgränser för enskilda databaser med hjälp av den DTU-baserade inköpsmodellen
- Azure SQL Database-gränser för inköpsmodellen baserad på vCore för elastiska pooler
- Resursbegränsningar för elastiska pooler med hjälp av den DTU-baserade inköpsmodellen