Strategier för haveriberedskap för program som använder elastiska Azure SQL Database-pooler
gäller för:![]() Azure SQL Database
Azure SQL Database
Azure SQL Database har flera funktioner för att tillhandahålla affärskontinuitet för ditt program när katastrofala incidenter inträffar. Elastiska pooler och enskilda databaser har stöd för samma typ av katastrofåterställning (DR). Den här artikeln beskriver flera DR-strategier för elastiska pooler som utnyttjar dessa funktioner för affärskontinuitet i Azure SQL Database.
Den här artikeln använder följande kanoniska Programmönster för oberoende SaaS-programvaruleverantör (ISV):
En modern molnbaserad webbapp etablerar en databas för varje slutanvändare. ISV har många kunder och använder därför många databaser, så kallade klientdatabaser. Eftersom klientdatabaserna vanligtvis har oförutsägbara aktivitetsmönster använder ISV en elastisk pool för att göra databaskostnaden mycket förutsägbar under längre tidsperioder. Den elastiska poolen förenklar även prestandahanteringen när användaraktiviteten ökar. Förutom klientdatabaserna använder programmet även flera databaser för att hantera användarprofiler, säkerhet, samla in användningsmönster osv. Tillgängligheten för enskilda klientorganisationer påverkar inte programmets tillgänglighet som helhet. Tillgängligheten och prestandan för hanteringsdatabaser är dock avgörande för programmets funktion och om hanteringsdatabaserna är offline är hela programmet offline.
Den här artikeln beskriver DR-strategier som täcker en rad scenarier från kostnadskänsliga startprogram till sådana med stränga tillgänglighetskrav.
Note
Om du använder Premium- eller Affärskritiska databaser och elastiska pooler kan du göra dem motståndskraftiga mot regionala avbrott genom att konvertera dem till zonredundant distributionskonfiguration. Se zon-redundanta databaser.
Scenario 1. Kostnadskänslig start
Jag är ett nystartade företag och är extremt kostnadskänslig. Jag vill förenkla distributionen och hanteringen av programmet och jag kan ha ett begränsat serviceavtal för enskilda kunder. Men jag vill se till att programmet som helhet aldrig är offline.
För att uppfylla enkelhetskravet distribuerar du alla klientdatabaser till en elastisk pool i valfri Azure-region och distribuerar hanteringsdatabaser som geo-replikerade enskilda databaser. För katastrofåterställning av hyresgäster, använd geo-återställning, som inte medför någon extra kostnad. För att säkerställa tillgängligheten för hanteringsdatabaserna kan du geo-replikera dem till en annan region med hjälp av en redundansgrupp (steg 1). Den löpande kostnaden för konfigurationen av haveriberedskap i det här scenariot är lika med den totala kostnaden för de sekundära databaserna. Den här konfigurationen visas i nästa diagram.
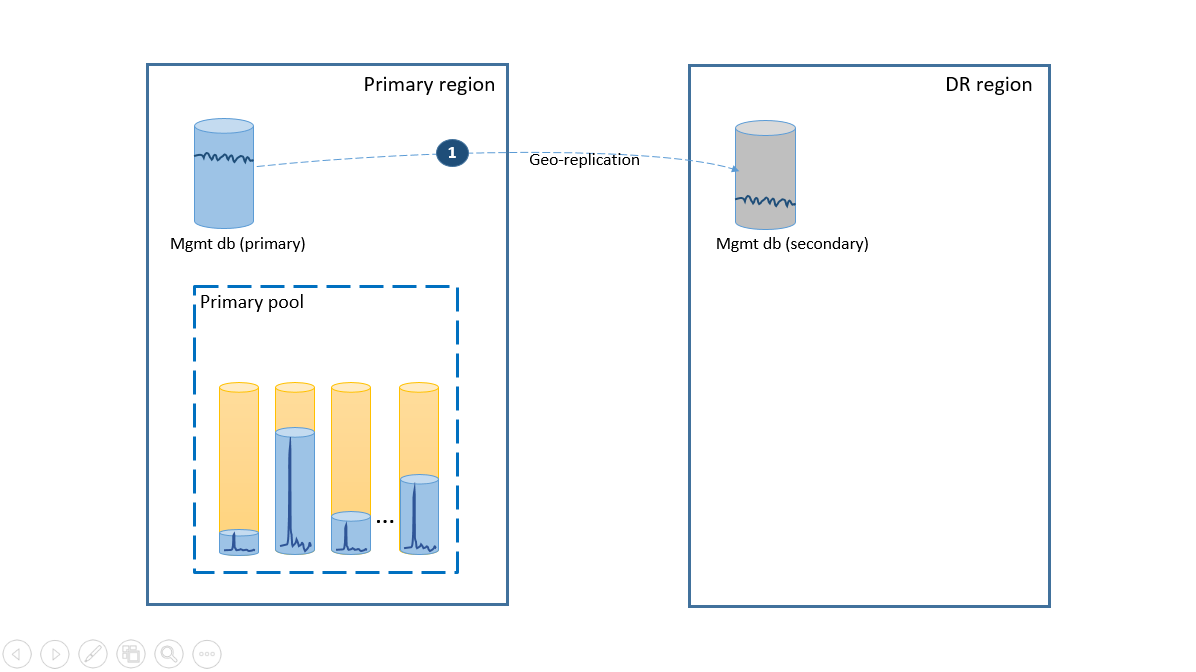
Om ett avbrott inträffar i den primära regionen visas återställningsstegen för att få programmet online i nästa diagram.
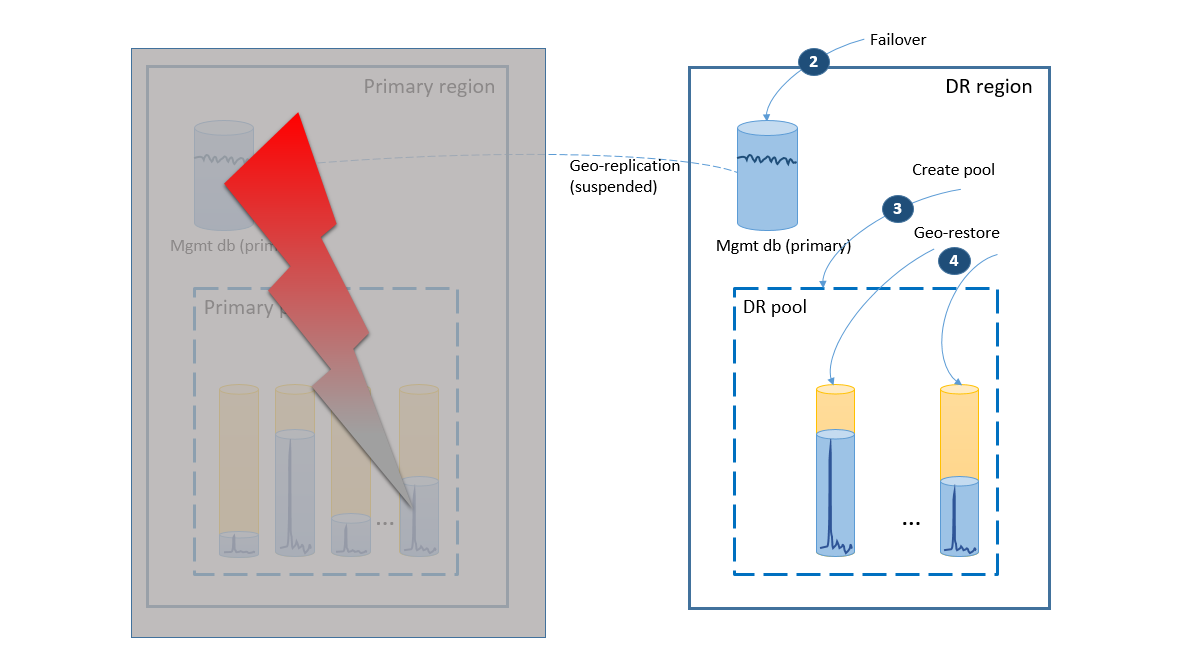
- Redundansgruppen initierar automatisk redundansväxling av hanteringsdatabasen till DR-regionen. Programmet återansluts automatiskt till den nya primära databasen och alla nya konton och klientdatabaser skapas i DR-regionen. De befintliga kunderna ser att deras data är tillfälligt otillgängliga.
- Skapa den elastiska poolen med samma konfiguration som den ursprungliga poolen (2).
- Använd geo-återställning för att skapa kopior av klientdatabaserna (3). Du kan överväga att utlösa enskilda återställningar av slutanvändaranslutningarna eller använda något annat programspecifikt prioritetsschema.
I det här läget är programmet online igen i DR-regionen, men vissa kunder upplever fördröjningar när de kommer åt sina data.
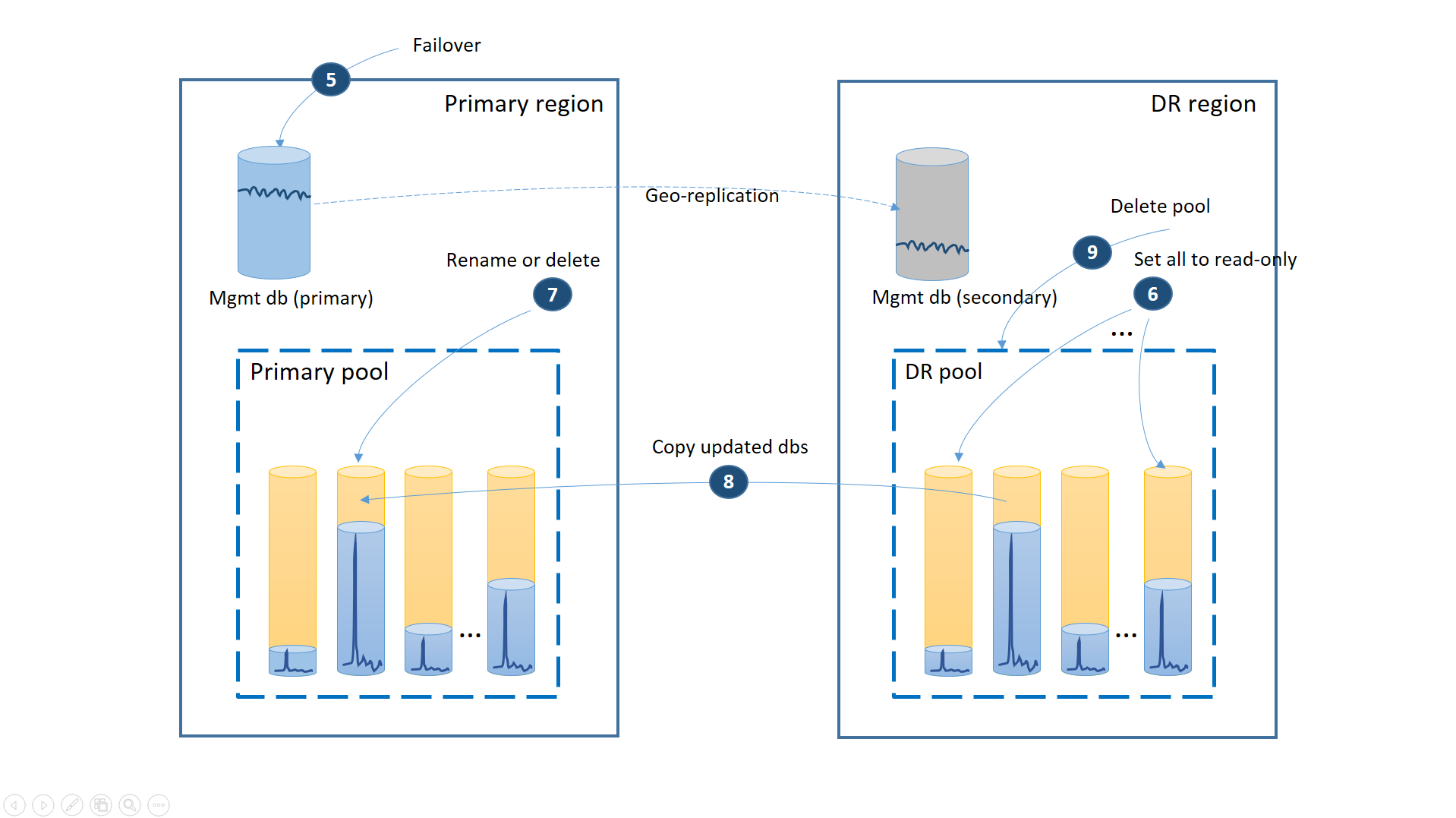
Om avbrottet var tillfälligt är det möjligt att den primära regionen återställs av Azure innan alla databasåterställningar har slutförts i DR-regionen. I det här fallet ska du orkestrera att flytta tillbaka programmet till den primära regionen. Processen utför de steg som illustreras i nästa diagram.
- Avbryt alla utestående geo-återställningsbegäranden.
- Växla över hanteringsdatabaserna till den primära regionen (5). Efter regionens återställning har de gamla primärerna automatiskt blivit sekundärer. Nu byter de roller igen.
- Ändra programmets anslutningssträng så att den pekar tillbaka till den primära regionen. Nu skapas alla nya konton och klientdatabaser i den primära regionen. Vissa befintliga kunder ser att deras data är tillfälligt otillgängliga.
- Ange alla databaser i DR-poolen till skrivskyddade för att säkerställa att de inte kan ändras i DR-regionen (6).
- För varje databas i DR-poolen som har ändrats sedan återställningen byter du namn på eller tar bort motsvarande databaser i den primära poolen (7).
- Kopiera de uppdaterade databaserna från DR-poolen till den primära poolen (8).
- Ta bort DR-poolen (9)
Nu är programmet online i den primära regionen med alla klientdatabaser tillgängliga i den primära poolen.
Fördel
Den viktigaste fördelen med den här strategin är låg löpande kostnad för redundans på datanivå. Azure SQL Database säkerhetskopierar automatiskt databaser utan programomskrivning utan extra kostnad. Kostnaden uppstår endast när de elastiska databaserna återställs.
Kompromiss
Kompromissen är att den fullständiga återställningen av alla klientdatabaser tar mycket tid. Hur lång tid det tar beror på det totala antalet återställningar som du initierar i DR-regionen och klientdatabasernas totala storlek. Även om du prioriterar vissa hyresgästers återställningar framför andra, konkurrerar du med alla andra återställningar som initieras i samma region där tjänsten fördelar och stryper för att minimera den övergripande påverkan på befintliga kunders databaser. Dessutom kan återställningen av klientdatabaserna inte starta förrän den nya elastiska poolen i DR-regionen har skapats.
Scenario 2. Mogna program med nivåindelad tjänst
Jag är ett moget SaaS-program med nivåindelade tjänsterbjudanden och olika serviceavtal för utvärderingskunder och för betalande kunder. För utvärderingskunderna måste jag minska kostnaden så mycket som möjligt. Utvärderingskunder kan ha nedtid, men jag vill minska sannolikheten för det. För de betalande kunderna är all stilleståndstid en flyktrisk. Så jag vill se till att betalande kunder alltid kan komma åt sina data.
För att stödja det här scenariot separerar du utvärderingsklienterna från betalda klienter genom att placera dem i separata elastiska pooler. Utvärderingskunderna har lägre eDTU:er eller vCores per klientorganisation och en lägre nivå av SLA med längre återställningstid. De betalande kunderna finns i en pool med högre eDTU eller virtuella kärnor per hyresgäst och ett högre SLA. För att garantera den lägsta återställningstiden är de betalande kundernas klientdatabaser geo-replikerade. Den här konfigurationen visas i nästa diagram.
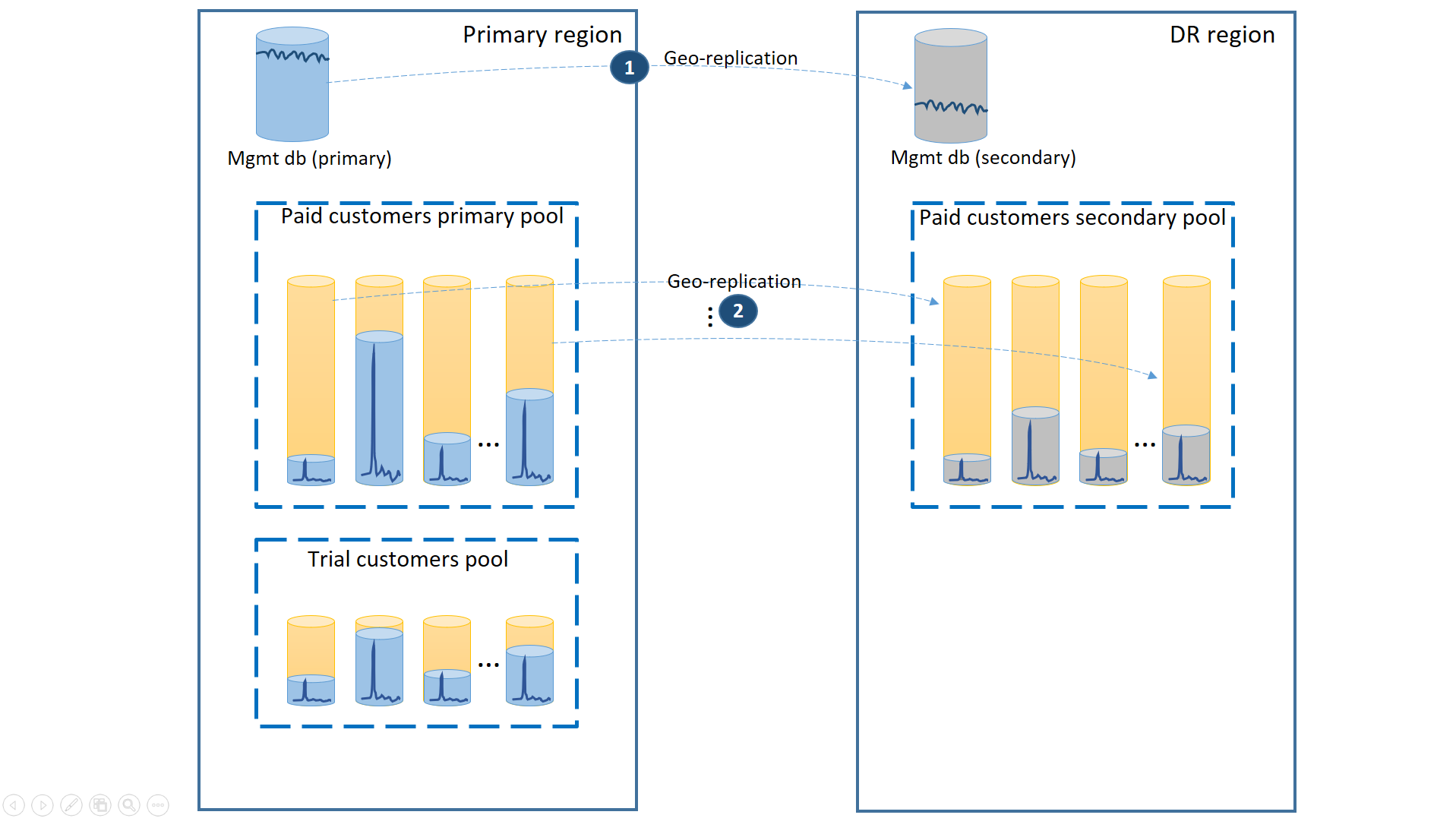
Precis som i det första scenariot är hanteringsdatabaserna ganska aktiva så du använder en enda geo-replikerad databas för den (1). Detta säkerställer förutsägbara prestanda för nya kundprenumerationer, profiluppdateringar och andra hanteringsåtgärder. Den region där primärvärdena för hanteringsdatabaserna finns är den primära regionen och den region där de sekundära hanteringsdatabaserna finns är DR-regionen.
De betalande kundernas klientdatabaser har aktiva databaser i betalda pool som etablerats i den primära regionen. Etablera en sekundär pool med samma namn i DR-regionen. Varje klientorganisation är geo-replikerad till den sekundära poolen (2). Detta möjliggör snabb återställning av alla klientdatabaser med hjälp av redundans.
Om ett avbrott inträffar i den primära regionen visas återställningsstegen för att få programmet online i nästa diagram:
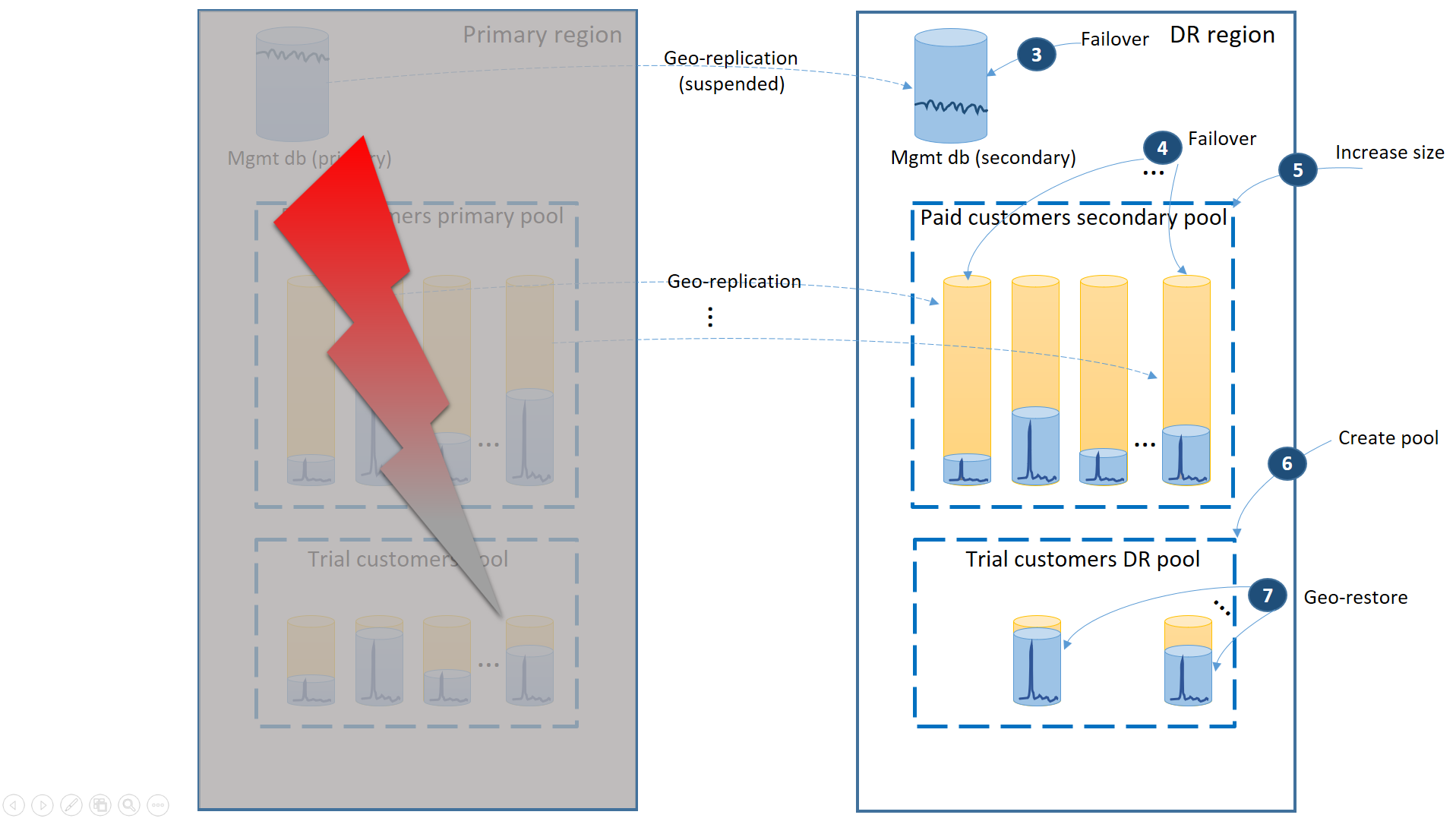
- Växla omedelbart över hanteringsdatabaserna till DR-regionen (3).
- Ändra programmets anslutningssträng så att den pekar på DR-regionen. Nu skapas alla nya konton och klientdatabaser i DR-regionen. De befintliga utvärderingskunderna ser att deras data är tillfälligt otillgängliga.
- Flytta över den betalande hyresgästens databaser till poolen i nödsituationsregionen för att omedelbart återställa deras tillgänglighet (4). Eftersom redundansväxlingen är en snabb ändring på metadatanivå bör du överväga en optimering där de enskilda redundansväxlingarna utlöses på begäran av slutanvändaranslutningarna.
- Om storleken på eDTU eller värdet för virtuell kärna i den sekundära poolen var lägre än i den primära, eftersom de sekundära databaserna endast behövde kapacitet för att bearbeta ändringsloggarna medan de var i sekundärroll, öka då genast poolkapaciteten för att hantera den fullständiga arbetsbelastningen för alla klienter (5).
- Skapa den nya elastiska poolen med samma namn och samma konfiguration i DR-regionen för utvärderingskundernas databaser (6).
- När utvärderingskundernas pool har skapats använder du geo-återställning för att återställa de enskilda klientdatabaserna för utvärderingsversionen till den nya poolen (7). Överväg att utlösa enskilda återställningar av slutanvändaranslutningarna eller använd något annat programspecifikt prioritetsschema.
Nu är programmet online igen i DR-regionen. Alla betalande kunder har åtkomst till sina data medan utvärderingskunderna får fördröjningar vid åtkomst till sina data.
När den primära regionen återställs av Azure efter du har återställt programmet i DR-regionen kan du fortsätta köra programmet i den regionen eller så kan du välja att växla tillbaka till den primära regionen. Om den primära regionen återställs innan redundansväxlingen har slutförts kan du överväga att återställa direkt. Återställning efter fel utför de steg som visas i nästa diagram:
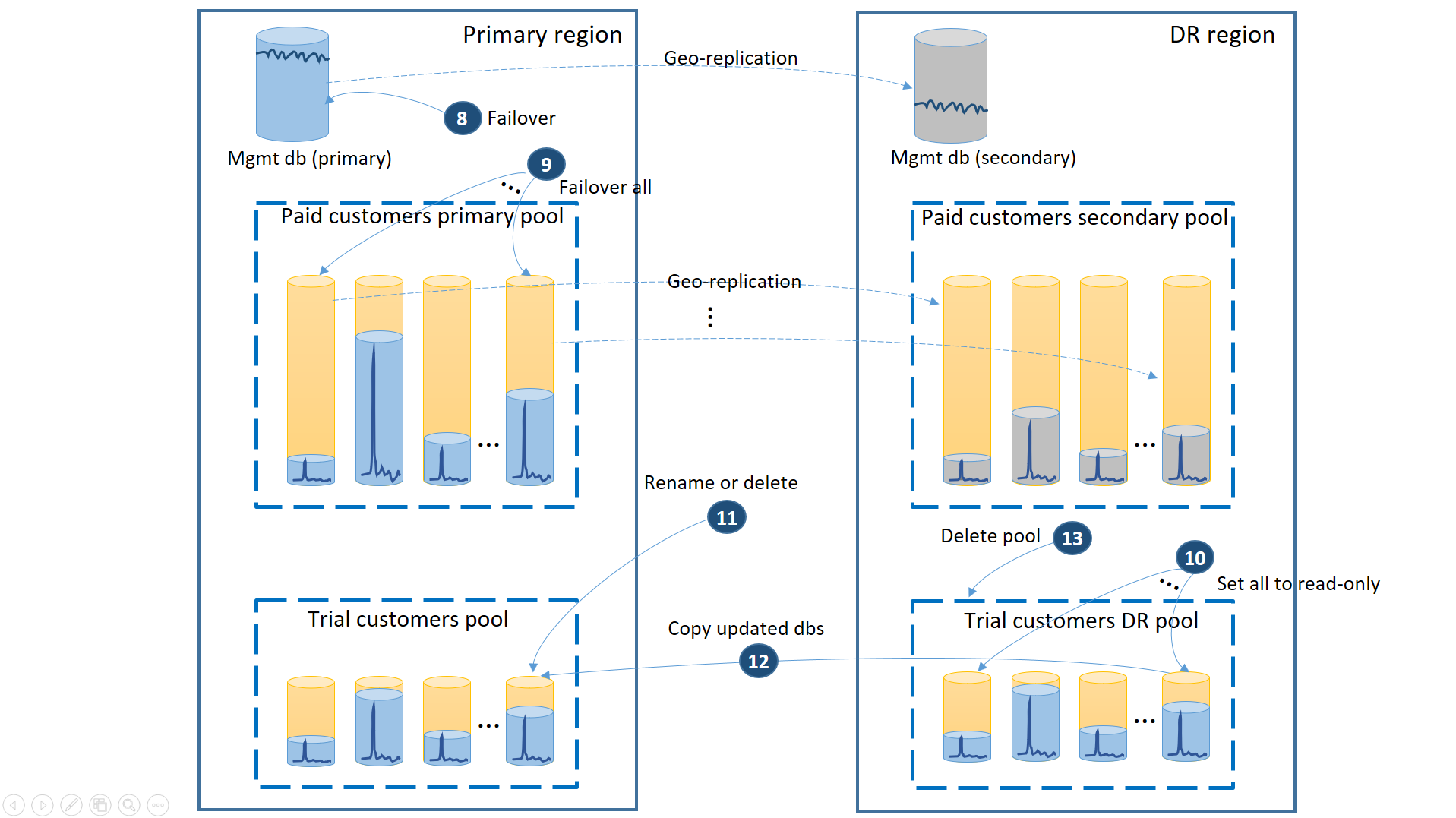
- Avbryt alla utestående geo-återställningsbegäranden.
- Växla över hanteringsdatabaserna (8). Efter regionens återställning blir den gamla primära automatiskt den sekundära. Nu blir det den primära igen.
- Växla över till redundans för de betalda hyresdatabaserna (9). På samma sätt blir de gamla primärerna automatiskt sekundärerna efter regionens återhämtning. Nu blir de primärvalen igen.
- Ange de återställde utvärderingsdatabaserna som har ändrats i DR-regionen till skrivskyddade (10).
- För varje databas i utvärderingsversionens kund-DR-pool som har ändrats sedan återställningen byter du namn på eller tar bort motsvarande databas i utvärderingskundernas primära pool (11).
- Kopiera de uppdaterade databaserna från DR-poolen till den primära poolen (12).
- Ta bort DR-poolen (13).
Obs
Redundansåtgärden är asynkron. För att minimera återställningstiden är det viktigt att du kör klientdatabasernas redundanskommando i batchar med minst 20 databaser.
Fördel
Den viktigaste fördelen med den här strategin är att den ger det högsta serviceavtalet för de betalande kunderna. Det garanterar också att de nya testerna avblockeras så snart DR-provpoolen har skapats.
Kompromiss
Kompromissen är att den här konfigurationen ökar den totala kostnaden för klientdatabaserna med kostnaden för den sekundära DR-poolen för betalda kunder. Om den sekundära poolen dessutom har en annan storlek får de betalande kunderna lägre prestanda efter redundansväxlingen tills pooluppgradering i DR-regionen har slutförts.
Scenario 3. Geografiskt distribuerat program med nivåindelad tjänst
Jag har ett moget SaaS-program med nivåindelade tjänsterbjudanden. Jag vill erbjuda ett mycket aggressivt serviceavtal till mina betalda kunder och minimera risken för påverkan när avbrott inträffar eftersom även korta avbrott kan orsaka kundernas missnöje. Det är viktigt att de betalande kunderna alltid kan komma åt sina data. Utvärderingsversionerna är kostnadsfria och ett serviceavtal erbjuds inte under utvärderingsperioden.
Använd tre separata elastiska pooler för att stödja det här scenariot. Etablera två pooler med samma storlek med höga eDTU:er eller virtuella kärnor per databas i två olika regioner för att innehålla de betalda kundernas klientdatabaser. Den tredje poolen som innehåller utvärderingsklienterna kan ha lägre eDTU:er eller virtuella kärnor per databas och etableras i en av de två regionerna.
För att garantera den lägsta återställningstiden vid avbrott geo-replikeras de betalande kundernas klientdatabaser med 50% av de primära databaserna i var och en av de två regionerna. På samma sätt har varje region 50% av de sekundära databaserna. På så sätt påverkas endast 50% av de betalda kundernas databaser när en region är offline och behöver växla över till redundans. De andra databaserna förblir intakta. Den här konfigurationen visas i följande diagram:
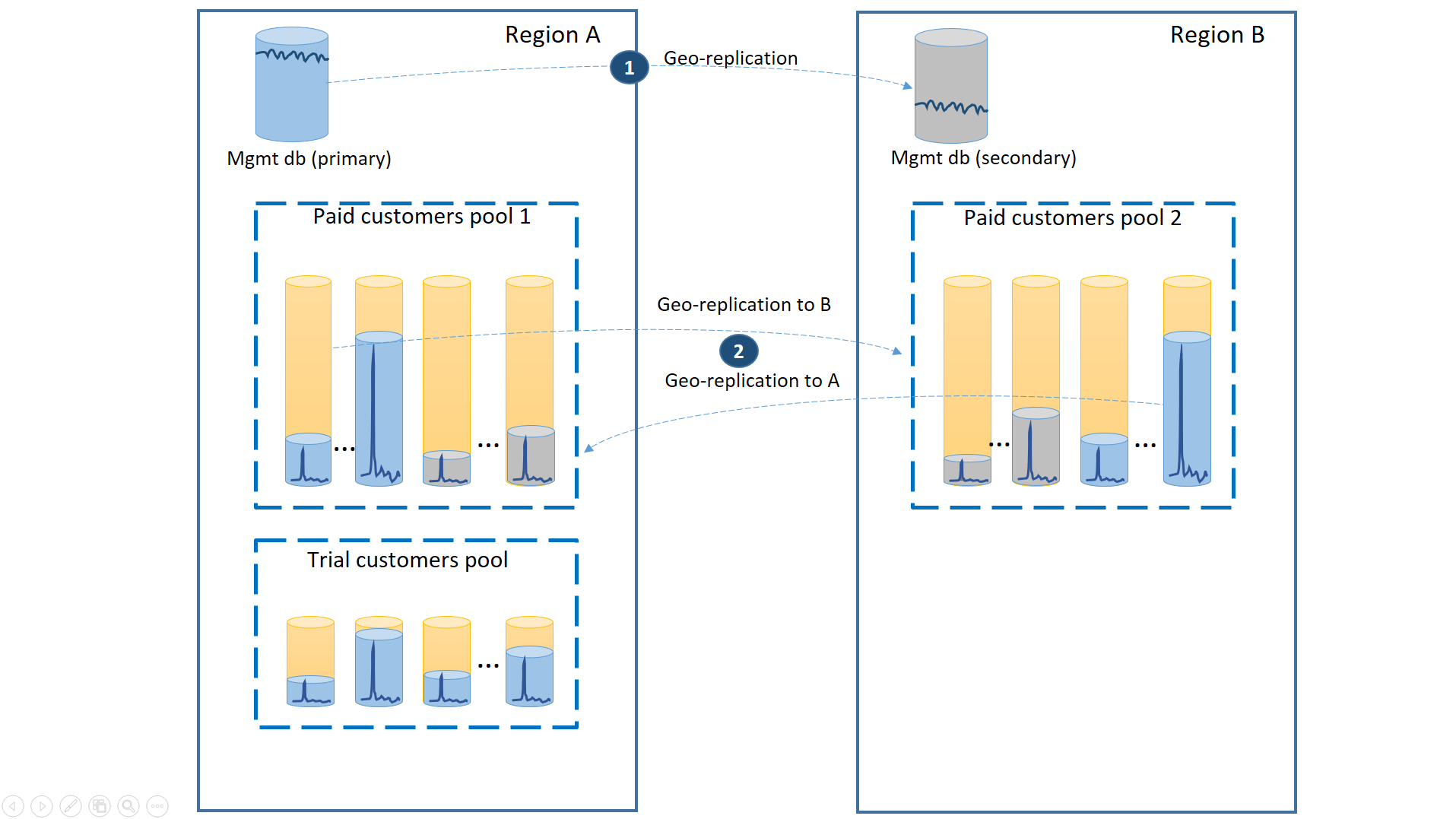
Precis som i tidigare scenarier är hanteringsdatabaserna ganska aktiva, så konfigurera dem som enskilda geo-replikerade databaser (1). Detta säkerställer förutsägbara prestanda för de nya kundprenumerationerna, profiluppdateringarna och andra hanteringsåtgärder. Region A är den primära regionen för hanteringsdatabaserna och region B används för återställning av hanteringsdatabaserna.
De betalande kundernas hyresgästdatabaser är också geo-replikerade men med primärer och sekundärer uppdelade mellan region A och region B (2). På så sätt kan hyresgästernas primära databaser som påverkas av driftstoppet växla över till den andra regionen och bli tillgängliga. Den andra hälften av klientdatabaserna påverkas inte alls.
Nästa diagram visar de återställningssteg som ska utföras om ett avbrott inträffar i region A.
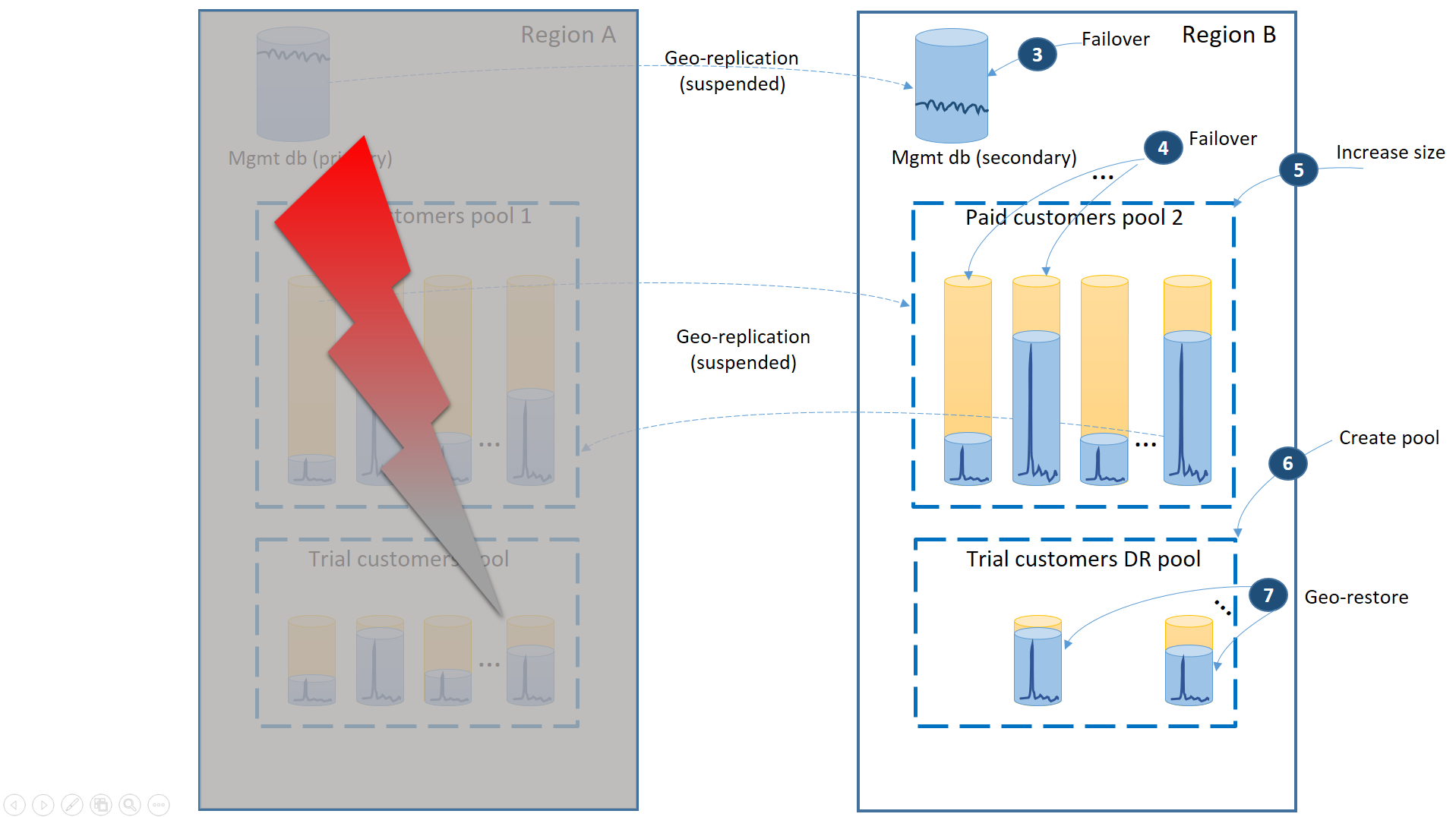
- Utför omedelbar felövergång av hanteringsdatabaserna till region B (3).
- Ändra programmets anslutningssträng så att den pekar på hanteringsdatabaserna i region B. Ändra hanteringsdatabaserna så att de nya kontona och klientdatabaserna skapas i region B och att även de befintliga klientdatabaserna finns där. De befintliga utvärderingskunderna ser att deras data är tillfälligt otillgängliga.
- Överför betalande klientens databaser till pool 2 i region B för att återställa deras tillgänglighet omedelbart (4). Eftersom redundansväxlingen är en snabb ändring på metadatanivå kan du överväga en optimering där de enskilda redundansväxlingarna utlöses på begäran av slutanvändaranslutningarna.
- Eftersom pool 2 nu endast innehåller primära databaser ökar den totala arbetsbelastningen i poolen och kan omedelbart öka eDTU-storleken (5) eller antalet virtuella kärnor.
- Skapa den nya elastiska poolen med samma namn och samma konfiguration i region B för databaserna hos utvärderingskunderna (6).
- När poolen har skapats använder du geo-återställning för att återställa den enskilda utvärderingsklientdatabasen till poolen (7). Du kan överväga att utlösa enskilda återställningar av slutanvändaranslutningarna eller använda något annat programspecifikt prioritetsschema.
Not
Failover-åtgärden är asynkron. För att minimera återställningstiden är det viktigt att du kör klientdatabasernas redundanskommando i batchar med minst 20 databaser.
Nu är programmet online igen i region B. Alla betalande kunder har åtkomst till sina data medan utvärderingskunderna får fördröjningar vid åtkomst till sina data.
När region A har återställts måste du bestämma om du vill använda region B för utvärderingskunder eller återgå till att använda poolen av utvärderingskunder i region A. Ett kriterium kan vara % för utvärderingsdatabaser som ändrats sedan återställningen. Oavsett det beslutet måste du balansera om de betalda hyresgästerna mellan två pooler. Nästa diagram illustrerar processen när utvärderingsklientdatabaserna växlar tillbaka till region A.
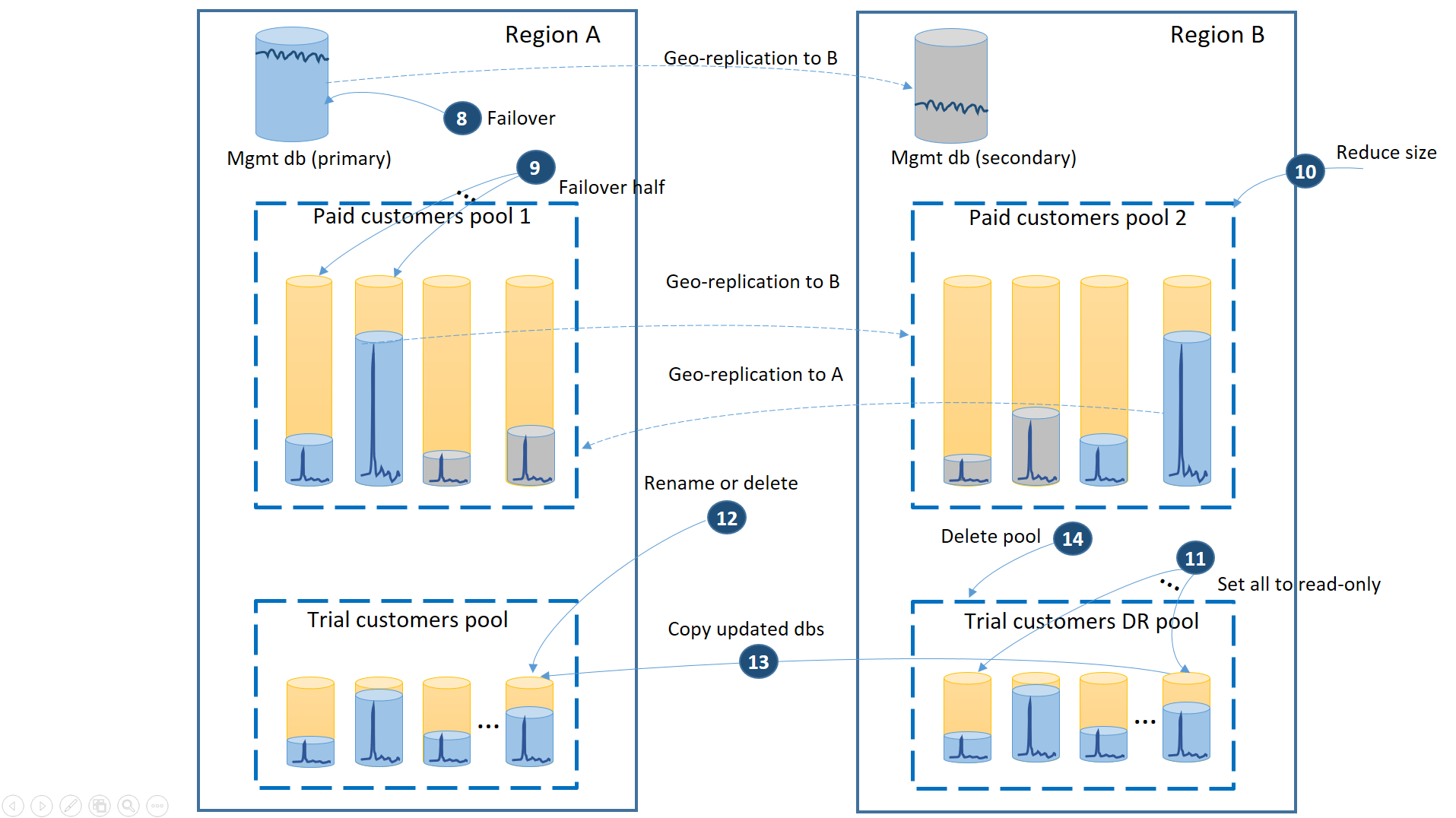
- Avbryt alla utestående geo-återställningsbegäranden till dr-utvärderingspoolen.
- Överlåt hanteringsdatabasen (8). Efter regionens återställning blev den gamla primära automatiskt den sekundära. Nu blir det det primära igen.
- Välj vilka betalda klientdatabaser som återställs till pool 1 och initiera redundansväxling till sina sekundärservrar (9). Efter regionens återställning blev alla databaser i pool 1 automatiskt sekundärfiler. Nu blir 50% av dem primära igen.
- Minska storleken på pool 2 till den ursprungliga eDTU:n (10) eller antalet virtuella kärnor.
- Ställ in alla återställda utvärderingsdatabaser i region B som skrivskyddade (11).
- För varje databas i utvärderings-DR-poolen som har ändrats sedan återställningen byter du namn på eller tar bort motsvarande databas i den primära utvärderingspoolen (12).
- Kopiera de uppdaterade databaserna från DR-poolen till den primära poolen (13).
- Ta bort DR-poolen (14).
Fördel
De viktigaste fördelarna med den här strategin är:
- Det stöder det mest aggressiva serviceavtalet för de betalande kunderna eftersom det säkerställer att ett avbrott inte kan påverka mer än 50% av klientdatabaserna.
- Det garanterar att de nya prövningarna avblockeras så snart DR-poolen skapas under återställningen.
- Det möjliggör effektivare användning av poolkapaciteten eftersom 50% av sekundära databaser i pool 1 och pool 2 garanteras vara mindre aktiva än de primära databaserna.
Kompromisser
De viktigaste kompromisserna är:
- CRUD-åtgärderna mot hanteringsdatabaserna har lägre svarstid för slutanvändare som är anslutna till region A än för slutanvändare som är anslutna till region B eftersom de körs mot den primära av hanteringsdatabaserna.
- Det kräver mer komplex design av hanteringsdatabasen. Till exempel har varje hyresgästpost en platstagg som måste ändras vid omställning och återställning.
- De betalande kunderna kan få lägre prestanda än vanligt tills pooluppgradningen i region B har slutförts.
Sammanfattning
Den här artikeln fokuserar på strategier för haveriberedskap för databasnivån som används av ett SaaS ISV-program med flera klientorganisationer. Den strategi du väljer baseras på programmets behov, till exempel affärsmodellen, det serviceavtal som du vill erbjuda dina kunder, budgetbegränsningar osv. Varje beskriven strategi beskriver fördelarna och kompromissen så att du kan fatta ett välgrundat beslut. Dessutom innehåller ditt specifika program sannolikt andra Azure-komponenter. Därför granskar du deras vägledning om affärskontinuitet och samordnar återställningen av databasnivån med dem. Mer information om hur du hanterar återställning av databasprogram i Azure finns i Utforma molnlösningar för haveriberedskap.
Nästa steg
- Mer information om automatiserade säkerhetskopieringar i Azure SQL Database finns i automatiserade säkerhetskopieringar i Azure SQL Database.
- En översikt och scenarier för affärskontinuitet finns i Översikt över affärskontinuitet.
- Mer information om hur du använder automatiserade säkerhetskopieringar för återställning finns i återställa en databas från de tjänstinitierade säkerhetskopiorna.
- Mer information om snabbare återställningsalternativ finns i Aktiv geo-replikering och redundansgrupper.
- Mer information om hur du använder automatiserade säkerhetskopior för arkivering finns i databaskopiering.