Konvertera en befintlig databas till Hyperskala
Du kan konvertera en befintlig databas i Azure SQL Database till Hyperskala med hjälp av Azure-portalen, Azure CLI, PowerShell eller Transact-SQL.
Övergång
Konverteringsprocessen är uppdelad i två steg – konverteringen av databasen, som sker medan den befintliga databasen är online, och sedan en snabb övergång till den nya Hyperskala-databasen.
- Den tid som krävs för att flytta en befintlig databas till Hyperskala består av tiden för att kopiera data och tiden för att spela upp de ändringar som gjorts i källdatabasen vid kopiering av data. Datakopieringstiden är proportionell mot datastorleken. Vi rekommenderar att du konverterar till Hyperskala under en lägre skrivaktivitetsperiod så att tiden för att spela upp ackumulerade ändringar blir kortare.
- Du kommer endast att uppleva en kort period av stilleståndstid, vanligtvis mindre än en minut, under den sista övergången till Hyperskala. Du har möjlighet att välja när övergången inträffar – så snart databasen är klar, eller manuellt vid en tidpunkt som du väljer. Som standardinställning sker övergångsprocessen till Hyperscale automatiskt.
Not
Möjligheten att initiera en manuell snabbinitiering för en konvertering till Hyperskala är en förhandsversionsfunktion.
I den aktuella förhandsversionen har du tre dagar på dig att initiera den manuella övergången efter det att databasen är klar för övergång under konverteringen till Hyperscale. Du kan initiera en manuell snabbväxling via Azure-portalen, Azure CLI, PowerShell eller T-SQL.
Förutsättningar
Om du vill konvertera en databas som är en del av en geo-replikering relation, antingen som primär eller sekundär, till Hyperskala, måste du först avsluta geo-replikering mellan den primära och sekundära repliken. Databaser i en redundansgrupp måste tas bort från gruppen först.
När en databas har flyttats till Hyperskala kan du skapa en ny hyperskala-geo-replik för databasen eller lägga till databasen i en redundansgrupp.
Direktkonvertering från basic-tjänstnivån till Hyperskala stöds inte. Om du vill utföra den här konverteringen ändrar du först databasen till någon annan tjänstnivå än Basic (till exempel Generell användning) och fortsätter sedan med konverteringen till Hyperskala.
Konvertera en databas till Hyperskala
Om du vill konvertera en befintlig Azure SQL Database till Hyperskala ska du först identifiera måltjänstmålet.
Granska resursgränser för enskilda databaser om du inte är säker på vilket tjänstmål som passar din databas. I många fall kan du välja ett tjänstmål med samma antal virtuella kärnor och samma maskinvarugenerering som den ursprungliga databasen. Om det behövs kan du ändra tjänstmålet senare med minimal stilleståndstid. Faktureringen för Hyperskala börjar först efter övergången.
Välj fliken för den metod som du föredrar för att konvertera databasen:
Med Azure-portalen kan du konvertera till Hyperskala genom att ändra tjänstnivån för databasen.

- Gå till den databas som du vill konvertera i Azure-portalen.
- I det vänstra navigeringsfältet väljer du Compute + storage.
- Välj rullgardinsmenyn tjänstenivå för att visa alternativen för tjänstenivåer.
- Om du använder det kostnadsfria azure SQL Database-erbjudandetväljer du knappen för att ta bort kostnadsfria databaserbjudandet. Sedan visas servicenivålistrutan .
- Välj Hyperskala i listrutan.
- Granska Compute-nivån och välj Etablerad eller Serverlös.
- Granska övergångsläge, ett val som är specifikt för konvertering till Hyperskala.
- Övergången sker efter att databasen har förberetts för konvertering till Hyperskala.
snabbläge avgör när anslutningen till den befintliga Azure SQL Database tillfälligt avbryts för konverteringen till Hyperskala:
- Automatisk övergång utför omkopplingen så snart Hyperscale-databasen är klar.
- Manuell övergång uppmanar dig att initiera övergången vid valfri tidpunkt i Azure-portalen. Det här alternativet är mest användbart för att tidsplanera övergången för minimala störningar i verksamheten.
- Övergången sker efter att databasen har förberetts för konvertering till Hyperskala.
snabbläge avgör när anslutningen till den befintliga Azure SQL Database tillfälligt avbryts för konverteringen till Hyperskala:
- Granska Maskinvarukonfiguration som anges. Om du vill väljer du Ändra konfiguration för att välja lämplig maskinvarukonfiguration för din arbetsbelastning.
- Välj skjutreglaget för att ändra antalet virtuella kärnor som är tillgängliga för din databas under tjänstnivån Hyperskala.
- Välj skjutreglaget High-Availability Sekundära Repliker om du vill ändra antalet repliker under Hyperscale-tjänstnivån.
- Välj Använd.
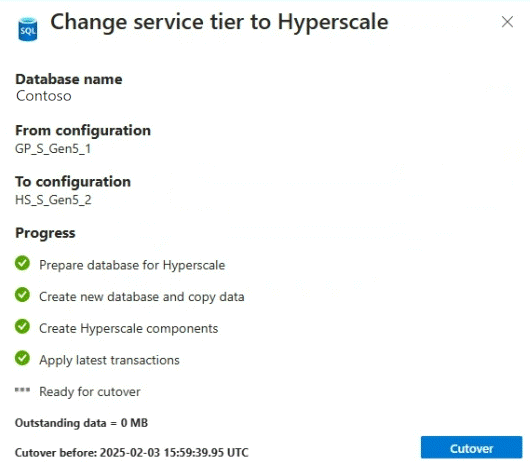
- Övervaka konverteringen i Azure-portalen.
- Gå till databasen i Azure-portalen.
- I det vänstra navigeringsfältet väljer du Översikt.
- Granska avsnittet Meddelanden längst ned i det högra fönstret. Om åtgärder pågår visas en meddelanderuta.
- Välj meddelanderutan för att visa information.
- Fönstret Pågående åtgärder öppnas. Granska informationen om de pågående åtgärderna.
Om du har valt Manuell övergång, visas en övergångsknapp för när det är klart i Azure-portalen.