Översikt över failovergrupper & bästa metoder (Azure SQL Database)
gäller för:![]() Azure SQL Database
Azure SQL Database
Med funktionen redundansgrupper kan du hantera replikering och redundans för vissa eller alla databaser på en logisk server till en logisk server i en annan region. Den här artikeln innehåller en översikt över funktionen för redundansgrupper med metodtips och rekommendationer för att använda den med Azure SQL Database.
Kom igång med funktionen genom att läsa Konfigurera en redundansgrupp för Azure SQL Database.
Anteckning
Den här artikeln beskriver redundansgrupper för Azure SQL Database. För Azure SQL Managed Instance, se Översikt och bästa praxis för failover-grupper - Azure SQL Managed Instance.
Om du vill veta mer om haveriberedskap för Azure SQL Database kan du titta på den här videon:
Överblick
Med funktionen redundansgrupper kan du hantera replikering och redundans för databaser till en annan Azure-region. Du kan välja alla eller en delmängd av användardatabaser på en logisk server som ska replikeras till en annan logisk server. Det är en deklarativ abstraktion ovanpå aktiv geo-replikering funktion, utformad för att förenkla distribution och hantering av geo-replikerade databaser i stor skala.
Information om geo-failover, RPO och RTO finns i översikt över affärskontinuitet.
Omdirigering av slutpunkt
Failovergrupper tillhandahåller läs-skriv och läs-skyddade slutpunkter som förblir oförändrade under geo-failover. Du behöver inte ändra anslutningssträngen för ditt program efter en geo-failover, eftersom anslutningar automatiskt dirigeras till den aktuella primära servern. En geo-failover ändrar rollen för alla sekundära databaser i gruppen till primär. När geo-failover har slutförts uppdateras DNS-posten automatiskt för att omdirigera slutpunkterna till den nya regionen.
Avlasta läs-intensiva arbetsbelastningar
Om du vill minska trafiken till dina primära databaser kan du också använda de sekundära databaserna i en failovergrupp för att avlasta endast läsbara arbetsbelastningar. Använd den skrivskyddade lyssnaren för att dirigera skrivskyddad trafik till en läsbar sekundär databas.
Återställa ett program
För att uppnå fullständig affärskontinuitet är det bara en del av lösningen att lägga till regional databasredundans. Återställning av ett program (tjänst) från slutpunkt till slutpunkt efter ett oåterkalleligt fel kräver återställning av alla komponenter som utgör tjänsten och alla beroende tjänster. Exempel på dessa komponenter är klientprogramvaran (till exempel en webbläsare med ett anpassat JavaScript), webbklientdelar, lagring och DNS. Det är viktigt att alla komponenter är motståndskraftiga mot samma fel och blir tillgängliga inom programmets mål för återställningstid (RTO). Därför måste du identifiera alla beroende tjänster och förstå de garantier och funktioner som de tillhandahåller. Sedan måste du vidta lämpliga åtgärder för att säkerställa att tjänsten fungerar under redundansväxlingen av de tjänster som den är beroende av.
Övergångspolicy
Failover-grupper stöder två failover-policyer:
-
Kundhanterad (rekommenderas) – Kunder kan utföra en failover av en grupp när de upptäcker ett oväntat avbrott som påverkar en eller flera databaser i failovergruppen. När du använder kommandoradsverktyg som PowerShell, Azure CLI eller REST API, är värdet för failover-policy för kundhanterad
manual. -
Microsoft-hanterade – I händelse av ett omfattande avbrott som påverkar en primär region startar Microsoft en övergång av alla berörda övergångsgrupper som har sin övergångspolicy konfigurerad för Microsoft-hantering. Microsoft-hanterad failover kommer inte att initieras för enskilda failover-grupper eller en delmängd av failover-grupper inom en region. När du använder kommandoradsverktyg som PowerShell, Azure CLI eller REST-API:et, är redundansprincipens värde för Microsoft-hanterad
automatic.
Varje redundansprincip har en unik uppsättning användningsfall och motsvarande förväntningar på redundansomfånget och dataförlusten, som följande tabell sammanfattar:
| Felhanteringspolicy | Redundansomfång | Användningsfall | Potentiell dataförlust |
|---|---|---|---|
| Administreras av kund (rekommenderas) |
Failover-grupp(er) | En eller flera databaser i en redundansgrupp påverkas av ett avbrott och blir otillgängliga. Du kan välja att göra en failover. | Ja |
| Microsoft hanterad | Alla failovergrupper i regionen | Ett omfattande avbrott i ett datacenter, en tillgänglighetszon eller en region orsakar otillgänglighet för databaser och Microsoft Azure SQL-tjänstteamet bestämmer sig för att utlösa en tvingad redundansväxling. Använd endast det här alternativet om du vill delegera ansvaret för haveriberedskap till Microsoft och programmet är tolerant mot RTO (stilleståndstid) på minst en timme eller mer. |
Ja |
Hanterad av kunden
I sällsynta fall räcker inte den inbyggda tillgänglighet eller hög tillgänglighet för att minska ett avbrott, och dina databaser i en redundansgrupp kan vara otillgängliga under en tid som inte är acceptabel för serviceavtalet (SLA) för de program som använder databaserna. Databaser kan inte vara tillgängliga på grund av ett lokaliserat problem som påverkar bara några få databaser, eller på datacenter-, tillgänglighetszon- eller regionnivå. I något av dessa fall kan du initiera en tvingad omkoppling för att återställa affärskontinuiteten.
Att ställa in din failover-policy till kundhanterad rekommenderas starkteftersom det ger dig kontroll över när failover ska initieras och säkerställa fortsatt affärsverksamhet. Du kan initiera en redundansväxling när du märker ett oväntat avbrott som påverkar en eller flera databaser i redundansgruppen.
Microsoft hanterad
Med en Microsoft-hanterad redundansprincip delegeras ansvaret för haveriberedskap till Azure SQL-tjänsten. För att Azure SQL-tjänsten ska kunna initiera en tvingad redundansväxling måste följande villkor uppfyllas:
- Avbrott på datacenter-, tillgänglighetszon- eller regionnivå som orsakas av en naturkatastrof, konfigurationsändringar, programvarubuggar eller maskinvarukomponentfel och många databaser i regionen påverkas.
- Respitperioden har upphört att gälla. Eftersom verifiering av omfattningen och mildring av avbrottet beror på mänskliga åtgärder, kan tidsfristen inte sättas till mindre än en timme.
När dessa villkor uppfylls initierar Azure SQL-tjänsten framtvingade överflyttningar för alla failovergrupper i regionen som har failoverpolicyn inställd på Microsoft hanterad.
Viktig
Använd kundhanterad redundansprincip för att testa och implementera din haveriberedskapsplan. Förlita dig inte på Microsofts hanterade redundans, som kanske bara körs av Microsoft under extrema omständigheter. En Microsoft-hanterad redundansväxling initieras för alla redundansgrupper i regionen som har en redundansprincip inställd på Microsoft hanterad. Det kan inte initieras för en enskild failover-grupp. Om du behöver möjligheten att selektivt hantera failover för din failover-grupp, använd en kundstyrd failover-policy.
Ange failover-policy till Microsoft hanterad endast när:
- Du vill delegera ansvaret för haveriberedskap till Azure SQL-tjänsten.
- Programmet är tolerant mot att databasen inte är tillgänglig i minst en timme eller mer.
- Det är acceptabelt att utlösa framtvingade redundansväxlingar en tid efter att respitperioden upphör att gälla eftersom den faktiska tiden för den framtvingade redundansväxlingen kan variera avsevärt.
- Det är acceptabelt att alla databaserna i växlingsgruppen växlar över, oavsett zonspecifik redundanskonfiguration eller tillgänglighetsstatus. Även om databaser som konfigurerats för zonredundans är motståndskraftiga mot zonfel och kanske inte påverkas av ett avbrott, kommer de fortfarande att redundansväxlas om de ingår i en redundansgrupp med en Microsoft-hanterad redundansprincip.
- Det är acceptabelt att ha framtvingade redundansväxlingar av databaser i redundansgruppen utan att ta hänsyn till programmets beroende av andra Azure-tjänster eller komponenter som används av programmet, vilket kan orsaka prestandaförsämring eller otillgänglighet för programmet.
- Det är acceptabelt att ådra sig en okänd mängd dataförlust eftersom den exakta tiden för tvingad redundans inte kan kontrolleras och ignorerar synkroniseringsstatusen för de sekundära databaserna.
- Alla primära och sekundära databaser i redundansgruppen och eventuella geo-replikeringsrelationer har samma tjänstnivå, beräkningsnivå (etablerad eller serverlös) & beräkningsstorlek (DTU:er eller virtuella kärnor). Om servicenivåmålet (SLO) för alla databaser inte matchar uppdateras redundanspolicyn så småningom från Microsoft Managed to Customer Managed by Azure SQL Service.
När en failover utlöses av Microsoft läggs en post för operationen Failover i Azure SQL-failovergruppen till i Azure Monitor-aktivitetsloggen. Posten innehåller namnet på redundansgruppen under Resurs och Händelse initierad av visar ett enda bindestreck (-) som anger att redundansväxlingen initierades av Microsoft. Den här informationen finns också på sidan aktivitetslogg på den nya primära servern eller instansen i Azure-portalen.
Terminologi och funktioner
redundansgrupp (FOG)
En redundansgrupp är en namngiven grupp med databaser som hanteras av en enda logisk server i Azure som kan redundansväxla som en enhet till en annan Azure-region om alla eller vissa primära databaser blir otillgängliga på grund av ett avbrott i den primära regionen.
Viktig
Namnet på redundansgruppen måste vara globalt unikt inom den
.database.windows.netdomänen.servrar
Vissa eller alla användardatabaser på en logisk server kan placeras i en redundansgrupp. Dessutom stöder en server flera redundansgrupper på en enskild server.
primära
Den logiska server som är värd för de primära databaserna i redundansgruppen.
sekundär
Den logiska server som är värd för de sekundära databaserna i redundansgruppen. Den sekundära kan inte finnas i samma Azure-region som den primära.
Failover (ingen dataförlust)
Failover utför fullständig datasynkronisering mellan primära och sekundära databaser innan den sekundära databasen växlar till den primära rollen. Detta garanterar ingen dataförlust. Redundans är bara möjligt när den primära är tillgänglig. Failover används i följande scenarier:
- Genomför katastrofåterställningsövningar (DR) i produktion om dataförlust inte är acceptabel.
- Flytta arbetsbelastningen till en annan region
- Returnera arbetsbördan till den primära regionen efter att avbrottet har åtgärdats (återställning)
Tvingad övergång (potentiell dataförlust)
Tvingad omkoppling byter omedelbart roll från sekundär till primär utan att invänta spridning av de senaste ändringarna från den primära servern. Den här åtgärden kan leda till potentiell dataförlust. Tvingad failover används som en återhämtningsmetod under avbrott när den primära servern inte är tillgänglig. När avbrotten har åtgärdats återansluter den gamla primära automatiskt och blir en ny sekundär. En redundansväxling kan utföras för att återgå till det ursprungliga tillståndet, vilket återställer replikerna till sina ursprungliga primära och sekundära roller.
respitperiod med dataförlust
Eftersom data replikeras till den sekundära noden med asynkron replikering kan en tvingad failover av grupper med Microsofts hanterade failover-policyer leda till dataförlust. Du kan anpassa redundanspolicyn så att den återspeglar programmets tolerans mot dataförlust. Genom att konfigurera
GracePeriodWithDataLossHourskan du styra hur länge Azure SQL-tjänsten väntar innan du påbörjar en tvingad redundansväxling, vilket kan leda till dataförlust.
Lägga till enkla databaser i redundansgrupp
Du kan placera flera enskilda databaser på samma logiska server i samma redundansgrupp. Om du lägger till en enskild databas i redundansgruppen skapas automatiskt en sekundär databas med samma utgåva och beräkningsstorlek på den sekundära server som du angav när redundansgruppen skapades. Om du lägger till en databas som redan har en sekundär databas på den sekundära servern ärvs den geo-replikeringslänken av gruppen. När du lägger till en databas som redan har en sekundär databas på en server som inte ingår i redundansgruppen skapas en ny sekundär databas på den sekundära servern.
Viktig
- Kontrollera att den sekundära logiska servern inte har en databas med samma namn om den inte är en befintlig sekundär databas.
- Om en databas innehåller minnesinterna OLTP-objekt måste den primära databasen och den sekundära geo-replikdatabasen ha matchande tjänstnivåer, eftersom minnesinterna OLTP-objekt finns i minnet. En lägre tjänstnivå på geo-replikdatabasen kan leda till problem med minnesbrist. Om detta inträffar kan geo-repliken misslyckas med att återställa databasen, vilket orsakar otillgänglighet för den sekundära databasen tillsammans med minnesinterna OLTP-objekt på den geo-sekundära. Detta kan i sin tur också leda till att redundansväxlingar misslyckas. Undvik detta genom att se till att tjänstnivån för den geo-sekundära databasen matchar den primära databasens. Uppgraderingar på tjänstnivå kan vara datastorleksåtgärder och kan ta ett tag att slutföra.
Lägga till databaser i elastisk pool till redundansgrupp
Du kan placera alla eller flera databaser i en elastisk pool i samma redundansgrupp. Om den primära databasen finns i en elastisk pool skapas den sekundära automatiskt i den elastiska poolen med samma namn (sekundär pool). Du måste se till att den sekundära servern innehåller en elastisk pool med samma exakta namn och tillräckligt med ledig kapacitet som värd för de sekundära databaser som ska skapas av redundansgruppen. Om du lägger till en databas i poolen som redan har en sekundär databas i den sekundära poolen ärvs den geo-replikeringslänken av gruppen. När du lägger till en databas som redan har en sekundär databas på en server som inte ingår i redundansgruppen skapas en ny sekundär databas i den sekundära poolen.
Failovergruppens skriv-läs lyssnare
En DNS CNAME-post som pekar på den aktuella primära posten. Den skapas automatiskt när failover-gruppen skapas och gör att läs-och skriv-arbetsbelastningen transparent kan återansluta till den primära instansen när den primära instansen ändras efter en failover. När redundansgruppen skapas på en server skapas DNS CNAME-posten för lyssnarens URL som
<fog-name>.database.windows.net. Efter failover uppdateras DNS-posten automatiskt för att omdirigera lyssnaren till den nya primära.Endast läsbar lyssnare för failover-grupp
En DNS CNAME-post som pekar på den aktuella sekundära posten. Den skapas automatiskt när redundansgruppen skapas och tillåter att den skrivskyddade SQL-arbetsbelastningen transparent ansluter till den sekundära när den sekundära ändras efter redundansväxlingen. När redundansgruppen skapas på en server skapas DNS CNAME-posten för lyssnarens URL som
<fog-name>.secondary.database.windows.net. Som standardinställning är failover-funktionen för den skrivskyddade lyssnaren inaktiverad eftersom detta säkerställer att huvudnodens prestanda inte påverkas när den sekundära noden är offline. Men det innebär också att läs-skrivskyddade sessioner inte kan ansluta förrän den sekundära har återställts. Om du inte kan tolerera stilleståndstid för skrivskyddade sessioner och kan använda den primära servern för både skrivskyddad och skrivbar trafik, på bekostnad av den potentiella prestandaförsämringen av den primära servern, kan du aktivera failover för den skrivskyddade lyssnaren genom att konfigurera egenskapenAllowReadOnlyFailoverToPrimary. I det fallet omdirigeras den skrivskyddade trafiken automatiskt till primärservern om sekundärservern inte är tillgänglig.Notera
Egenskapen
AllowReadOnlyFailoverToPrimarygäller endast om Microsofts hanterade redundansprincip är aktiverad och en tvingad redundans har utlösts. I så fall, om egenskapen är inställd på True, kommer den nya primären att hantera både skriv- och lässkyddade sessioner.Flera redundansgrupper
Du kan konfigurera flera failovergrupper för samma par servrar för att styra omfånget för geografiska failovers. Varje grupp växlar över oberoende. Om ditt klient-per-databas-program distribueras i flera regioner och använder elastiska pooler kan du använda den här funktionen för att blanda primära och sekundära databaser i varje pool. På så sätt kanske du kan minska effekten av ett avbrott till endast vissa klientdatabaser.
Arkitektur för redundanskluster
En redundansgrupp i Azure SQL Database kan innehålla en eller flera databaser, som vanligtvis används av samma program. En redundansgrupp måste konfigureras på den primära servern, som ansluter den till den sekundära servern i en annan Azure-region. Redundansgruppen kan innehålla alla eller vissa databaser på den primära servern. Följande diagram illustrerar en typisk konfiguration av ett geo-redundant molnprogram med flera databaser i en redundansgrupp:
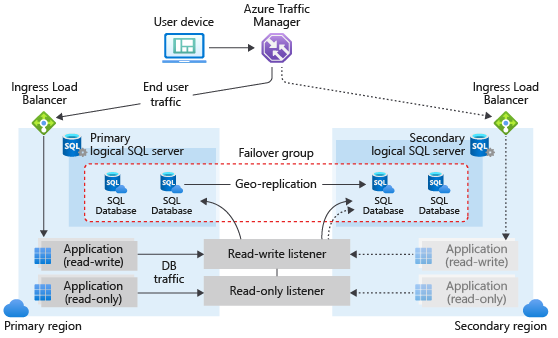
När du utformar en tjänst med affärskontinuitet i åtanke följer du de allmänna riktlinjer och metodtips som beskrivs i den här artikeln. När du konfigurerar en failover-grupp, säkerställ att autentisering och nätverksåtkomst på den sekundära noden är inställda för att fungera korrekt efter geo-failover, när den geo-sekundära noden blir den nya primära noden. För mer information, se Konfigurera och hantera Azure SQL Database-säkerhet för geo-återställning eller överbelastningsskydd. Mer information finns i Designa globalt tillgängliga tjänster med hjälp av Azure SQL Database och Geografisk återställning för Azure SQL Database.
Använda parkopplade regioner
När du skapar din failovergrupp mellan den primära och sekundära servern, använd parkopplade regioner eftersom failovergrupper i parkopplade regioner har bättre prestanda jämfört med icke-parkopplade regioner.
Med hjälp av säkra distributionsmetoder uppdaterar Azure SQL Database vanligtvis inte kopplade regioner samtidigt. Det går dock inte att förutsäga vilken region som ska uppgraderas först, så distributionsordningen är inte garanterad. Ibland uppgraderas den primära servern först, och ibland uppgraderas den till en andra.
Om du har geo-replikering eller redundansgrupper konfigurerade för databaser som inte överensstämmer med Azure-regionparkopplinganvänder du olika underhållsfönsterscheman för dina primära och sekundära databaser. Du kan till exempel välja underhållsfönstret Vardag för den sekundära databasen och underhållsfönstret Helg för den primära databasen.
Inledande seedning
När du lägger till databaser eller elastiska pooler i en redundansgrupp finns det en inledande seeding-fas innan datareplikeringen startar. Den inledande seeding-fasen är den längsta och dyraste åtgärden. När den första seedingen är klar synkroniseras data och sedan replikeras endast efterföljande dataändringar. Den tid det tar för den första seedingen att slutföras beror på storleken på dina data, antalet replikerade databaser, belastningen på de primära databaserna och hastigheten på nätverkslänken mellan den primära och sekundära databasen. Under normala omständigheter är den möjliga seedinghastigheten upp till 500 GB i timmen för SQL Database. Seeding utförs för alla databaser parallellt.
Antal databaser i redundansgrupp
Antalet databaser i en redundansgrupp påverkar direkt varaktigheten för både redundans och tvingad redundans.
- Under en failover (kallas även planerad failover) ser vi till att alla primära databaser är helt synkroniserade med sina sekundära och når ett beredskapsläge. För att undvika att överbelasta kontrollplanet förbereds databaser i batchar. Därför rekommenderar vi starkt att du begränsar antalet databaser i en redundansgrupp.
- När det gäller en tvingad redundans påskyndas förberedelsefasen eftersom datasynkronisering inte initieras. För att uppnå snabbare och mer förutsägbara omkopplingstider kan det vara fördelaktigt att begränsa antalet databaser i failover-gruppen till ett mindre antal.
Använd flera failover-grupper för att växla över flera databaser
En eller flera redundansgrupper kan skapas mellan två servrar i olika regioner (primära och sekundära servrar). Varje grupp kan innehålla en eller flera databaser som återställs som en enhet om alla eller vissa primära databaser blir otillgängliga på grund av ett avbrott i den primära regionen. När du skapar en redundansgrupp skapas geo-sekundära databaser med samma tjänstmål som det primära. Om du lägger till en befintlig geo-replikeringsrelation till en redundansgrupp kontrollerar du att den geo-sekundära är konfigurerad med samma tjänstnivå och beräkningsstorlek som den primära.
Använd läs-och-skriv-lyssnaren (primär)
För läs- och skrivarbetsbelastningar använder du <fog-name>.database.windows.net som servernamn i anslutningssträngen. Anslutningar dirigeras automatiskt till den primära. Det här namnet ändras inte efter övergången. Observera att redundansväxlingen innebär att DNS-posten uppdateras så att klientanslutningarna omdirigeras till den nya primära posten först efter att klientens DNS-cache har uppdaterats. Livstiden (TTL) för den primära och sekundära lyssnarens DNS-post är 30 sekunder.
Använd den skrivskyddade lyssnaren (sekundär)
Om du har logiskt isolerade skrivskyddade arbetsbelastningar som är toleranta mot datafördröjning kan du köra dem på den geografiska sekundära instansen. För skrivskyddade sessioner använder du <fog-name>.secondary.database.windows.net som servernamn i anslutningssträngen. Anslutningar dirigeras automatiskt till den geo-sekundära noden. Vi rekommenderar också att du anger avsikt för läsning i anslutningssträngen med hjälp av ApplicationIntent=ReadOnly.
På tjänstnivåerna Premium, Affärskritisk och Hyperskala stöder SQL Database användningen av skrivskyddade repliker för att hantera skrivskyddade frågebelastningar med hjälp av parametern ApplicationIntent=ReadOnly i anslutningssträngen. När du har konfigurerat en geosekundär enhet kan du använda denna funktion för att ansluta till antingen en läs-skyddad replik på den primära platsen eller på den geosekundära platsen.
Om du vill ansluta till en skrivskyddad replik på den sekundära platsen använder du ApplicationIntent=ReadOnly och <fog-name>.secondary.database.windows.net.
Potentiell prestandaförsämring efter failover
Ett typiskt Azure-program använder flera Azure-tjänster och består av flera komponenter. Failöver av en grupp utlöses enbart baserat på tillståndet för Azure SQL Database. Andra Azure-tjänster i den primära regionen kanske inte påverkas av avbrotten och deras komponenter kan fortfarande vara tillgängliga i den regionen. När de primära databaserna växlar till den sekundära regionen (DR) kan svarstiden mellan beroende komponenter öka. För att undvika effekten av högre svarstid på programmets prestanda kontrollerar du redundansen för alla programmets komponenter i DR-regionen, följer dessa riktlinjer för nätverkssäkerhetoch samordnar geo-redundans för relevanta programkomponenter tillsammans med databasen.
Potentiell dataförlust efter tvingad redundans
Om ett avbrott inträffar i den primära regionen kanske de senaste transaktionerna inte har replikerats till den geo-sekundära och det kan uppstå dataförlust om en tvingad redundans utförs.
Viktig
Elastiska pooler med 800 eller färre DTU eller 8 eller färre virtuella kärnor, och mer än 250 databaser kan stöta på problem som längre planerade geo-failovers och försämrad prestanda. Dessa problem är mer benägna att uppstå vid skrivintensiva arbetsbelastningar när geo-repliker är geografiskt spridda, eller när flera sekundära geo-repliker används för varje databas. Ett symptom på dessa problem är en ökning av geo-replikeringsfördröjning över tid, vilket kan leda till en mer omfattande dataförlust i ett avbrott. Den här fördröjningen kan övervakas med hjälp av sys.dm_geo_replication_link_status. Om dessa problem uppstår kan du skala upp poolen för att få fler DTU:er eller virtuella kärnor, eller minska antalet geo-replikerade databaser i poolen.
Återställning efter fel
När redundansgrupper konfigureras med en Microsoft-hanterad redundansprincip initieras tvingad redundans till den geo-sekundära servern under ett katastrofscenario enligt den definierade respitperioden. Återgång till den ursprungliga primära servern måste initieras manuellt.
Behörigheter och begränsningar
I guiden för att konfigurera redundansgrupp finns en lista över behörigheter och begränsningar.
Hantera redundansgrupper programmatiskt
Redundansgrupper kan också hanteras programmatiskt med hjälp av Azure PowerShell, Azure CLI och REST API. Mer information finns i Konfigurera en redundansgrupp för Azure SQL Database.
Aktivera hög tillgänglighet (zonredundans)
Tillgänglighet genom redundans förbättrar motståndskraften ytterligare som skydd mot avbrott i en tillgänglighetszon inom en region.
När du skapar en redundansgrupp som innehåller en eller flera databaser finns det inget alternativ för att aktivera hög tillgänglighet för de sekundära databaserna, oavsett inställningarna för hög tillgänglighet för de primära databaserna.
Zonredundans med icke-Hyperskala-databaser
Sekundära databaser som skapas via redundansgruppen har inte hög tillgänglighet aktiverad som standard. När redundansgruppen har skapats aktiverar du hög tillgänglighet för databaserna i gruppen. Det här beteendet gäller även om du skapar Active Geo-Replication först och sedan lägger till databaserna i en redundansgrupp.
Zonredundans med Hyperskala
Sekundära databaser som skapas via redundansgruppen ärver inställningarna för hög tillgänglighet för sina respektive primära databaser. Om den primära databasen har hög tillgänglighet aktiverad kommer den sekundära databasen därför också att ha den aktiverad. Om den primära databasen inte har hög tillgänglighet aktiverad har den inte heller aktiverats för den sekundära databasen.
Regionalt stöd för tillgänglighetszoner
I ett scenario där hög tillgänglighet är aktiverat på den primära databasen och den sekundära databasen som läggs till finns i en region som ännu inte stöder tillgänglighetszoner, misslyckas arbetsflödet med ett felmeddelande med kod 45122: "Åtgärden Skapa eller uppdatera redundansgrupper har slutförts. Det gick dock inte att lägga till eller ta bort några av databaserna från redundansgruppen. Etablering av zonredundant databas/pool stöds inte för din aktuella begäran." Undvik det här problemet genom att använda Aktiv geo-replikering där du aktiverar eller inaktiverar hög tillgänglighet när du skapar den sekundära databasen. Du kan sedan lägga till dessa databaser i en redundansgrupp.
Relaterat innehåll
- Exempelskript finns i:
- En översikt och scenarier för affärskontinuitet finns i Översikt över affärskontinuitet
- Mer information om automatiserade säkerhetskopieringar i Azure SQL Database finns i automatiserade säkerhetskopieringar i SQL Database.
- Mer information om hur du använder automatiserade säkerhetskopieringar för återställning finns i Återställa en databas från tjänstinitierade säkerhetskopior.
- Mer information om autentiseringskrav för en ny primär server och databas finns i SQL Database-säkerhet efter katastrofåterställning.