Förstå volymspråk i Azure NetApp Files
Volymspråk (liknar systemspråk på klientoperativsystem) på en Azure NetApp Files-volym styr de språk och teckenuppsättningar som stöds när NFS- och SMB-protokoll används. Azure NetApp Files använder standardvolymspråket C.UTF-8, som tillhandahåller POSIX-kompatibel UTF-8-kodning för teckenuppsättningar. C.UTF-8-språket stöder inbyggt tecken med en storlek på 0-3 byte, vilket inkluderar en majoritet av världens språk på det grundläggande flerspråkiga planet (BMP) (inklusive japanska, tyska och de flesta hebreiska och kyrilliska). Mer information om BMP finns i Unicode.
Tecken utanför BMP överskrider ibland storleken på 3 byte som stöds av Azure NetApp Files. De måste därför använda surrogatparlogik, där byteuppsättningar med flera tecken kombineras för att skapa nya tecken. Emojisymboler ingår till exempel i den här kategorin och stöds i Azure NetApp Files i scenarier där UTF-8 inte tillämpas: till exempel Windows-klienter som använder UTF-16-kodning eller NFSv3 som inte tillämpar UTF-8. NFSv4.x framtvingar UTF-8, vilket innebär att surrogatpartecken inte visas korrekt när du använder NFSv4.x.
Icke-standardkodning, till exempel Skift-JIS och mindre vanliga CJK-tecken, visas inte heller korrekt när UTF-8 tillämpas i Azure NetApp Files.
Dricks
Du bör skicka och ta emot text med UTF-8 för att undvika situationer där tecken inte kan översättas korrekt, vilket kan orsaka scenarier med filskapande/namnbyte eller kopieringsfel.
Volymspråkinställningarna kan för närvarande inte ändras i Azure NetApp Files. Mer information finns i Protokollbeteenden med specialteckenuppsättningar.
Metodtips finns i Metodtips för teckenuppsättning.
Teckenkodning i Azure NetApp Files NFS- och SMB-volymer
I en Azure NetApp Files-fildelningsmiljö representeras fil- och mappnamn av en serie tecken som slutanvändarna läser och tolkar. Hur dessa tecken visas beror på hur klienten skickar och tar emot kodning av dessa tecken. Om en klient till exempel skickar äldre ASCII-kodning (American Standard Code for Information Interchange) till Azure NetApp Files-volymen när den används, är den begränsad till att endast visa tecken som stöds i ASCII-format.
Till exempel är det japanska tecknet för data 資. Eftersom det här tecknet inte kan representeras i ASCII visar en klient som använder ASCII-kodning ett "?" i stället för 資.
ASCII stöder endast 95 utskrivbara tecken, främst de som finns på engelska. Vart och ett av dessa tecken använder 1 byte, vilket räknas in i den totala filsökvägslängden på en Azure NetApp Files-volym. Detta begränsar internationaliseringen av datauppsättningar, eftersom filnamn kan ha en mängd tecken som inte känns igen av ASCII, från japanska till kyrilliska till emoji. En internationell standard (ISO/IEC 8859) försökte stödja fler internationella tecken, men hade också sina begränsningar. De flesta moderna klienter skickar och tar emot tecken med någon form av Unicode.
Unicode
Som ett resultat av begränsningarna i ASCII- och ISO/IEC 8859-kodningar etablerades Unicode-standarden så att vem som helst kan visa hemregionens språk från sina enheter.
- Unicode stöder över en miljon teckenuppsättningar genom att öka både antalet tillåtna byte per tecken (upp till 4 byte) och det totala antalet tillåtna byte i en filsökväg i stället för äldre kodningar, till exempel ASCII.
- Unicode stöder bakåtkompatibilitet genom att reservera de första 128 tecknen för ASCII, samtidigt som de första 256 kodpunkterna är identiska med ISO/IEC 8859-standarder.
- I Unicode-standarden delas teckenuppsättningar upp i plan. Ett plan är en kontinuerlig grupp på 65 536 kodpunkter. Totalt finns det 17 plan (0–16) i Unicode-standarden. Gränsen är 17 på grund av begränsningarna i UTF-16.
- Plan 0 är BMP (Basic Multilingual Plane). Det här planet innehåller de vanligaste tecknen på flera språk.
- Av de 17 planen har endast fem för närvarande tilldelats teckenuppsättningar från och med Unicode version 15.1.
- Plan 1-17 kallas kompletterande flerspråkiga plan (SMP) och innehåller mindre använda teckenuppsättningar, till exempel forntida skrivsystem som cuneiform och hieroglyphs, samt speciella kinesiska/japanska/koreanska tecken (CJK).
- Metoder för att se teckenlängder och sökvägsstorlekar och för att styra kodningen som skickas till ett system finns i Konvertera filer till olika kodningar.
Unicode använder Unicode Transformation Format som standard, där UTF-8 och UTF-16 är de två huvudformaten.
Unicode-plan
Unicode utnyttjar 17 plan med 65 536 tecken (256 kodpunkter multiplicerat med 256 rutor i planet), med plan 0 som BMP (Basic Multilingual Plane). Det här planet innehåller de vanligaste tecknen på flera språk. Eftersom världens språk och teckenuppsättningar överskrider 65536 tecken behövs fler plan för att stödja mindre vanliga teckenuppsättningar.
Till exempel innehåller Plane 1 (Den kompletterande flerspråkiga planen (SMP)) historiska skript som cuneiform och egyptiska hieroglyphs samt vissa Osage, Warang Citi, Adlam, Wancho och Toto. Planet 1 innehåller även vissa symboler och uttryckssymboler .
Plan 2 – det kompletterande Ideographic Plane (SIP) – innehåller kinesiska/japanska/koreanska (CJK) enhetliga Ideografier. Tecken i plan 1 och 2 är vanligtvis 4 byte i storlek.
Till exempel:
- Den "flinande ansikte med stora ögon" uttryckssymbol "😃" i plan 1 är 4 byte i storlek.
- Den egyptiska hieroglyfen "𓀀" i plan 1 är 4 byte i storlek.
- Osage-tecknet "𐒸" i plan 1 är 4 byte i storlek.
- CJK-tecknet "𫝁" i plan 2 är 4 byte i storlek.
Eftersom dessa tecken är alla >3 byte i storlek, kräver de användning av surrogatpar för att fungera korrekt. Azure NetApp Files har inbyggt stöd för surrogatpar, men teckenvisningen varierar beroende på vilket protokoll som används, klientens nationella inställningar och inställningarna för fjärrklientåtkomstprogrammet.
UTF-8
UTF-8 använder 8-bitars kodning och kan ha upp till 1 112 064 kodpunkter (eller tecken). UTF-8 är standardkodningen för alla språk i Linux-baserade operativsystem. Eftersom UTF-8 använder 8-bitars kodning är maximalt osignerat heltal möjligt 255 (2^8 – 1), vilket också är den maximala filnamnslängden för den kodningen. UTF-8 används på över 98 % av sidorna på Internet, vilket gör det till den överlägset mest antagna kodningsstandarden. Web Hypertext Application Technology Working Group (WHATWG) anser att UTF-8 är "den obligatoriska kodningen för all [text]" och att webbläsarprogram av säkerhetsskäl inte bör använda UTF-16.
Tecken i UTF-8-format använder vardera 1 till 4 byte, men nästan alla tecken på alla språk använder mellan 1 och 3 byte. Till exempel:
- Den latinska alfabetsbeteckningen "A" använder 1 byte. (Ett av de 128 reserverade ASCII-tecknen)
- En copyrightsymbol "©" använder 2 byte.
- Tecknet "ä" använder 2 byte. (1 byte för "a" + 1 byte för umlaut)
- Den japanska Kanji-symbolen för data (資) använder 3 byte.
- En flinande ansikts-emoji (😃) använder 4 byte.
Språkvarianter kan använda antingen datorstandard-UTF-8 (C.UTF-8) eller ett mer regionspecifikt format, till exempel en_US. UTF-8, ja. UTF-8 osv. Du bör använda UTF-8-kodning för Linux-klienter när du kommer åt Azure NetApp Files när det är möjligt. Från och med OS X använder macOS-klienter också UTF-8 för sin standardkodning och bör inte justeras.
Windows-klienter använder UTF-16. I de flesta fall bör den här inställningen lämnas som standard för operativsystemets nationella inställningar, men nyare klienter erbjuder betastöd för UTF-8-tecken via en kryssruta. Terminalklienter i Windows kan också justeras för att använda UTF-8 i PowerShell eller CMD efter behov. Mer information finns i Dubbla protokollbeteenden med specialteckenuppsättningar.
UTF-16
UTF-16 använder 16-bitars kodning och kan koda alla 1 112 064 kodpunkter i Unicode. Kodningen för UTF-16 kan använda en eller två 16-bitars kodenheter, var och en av 2 byte i storlek. Alla tecken i UTF-16 använder storlekar på 2 eller 4 byte. Tecken i UTF-16 som använder 4 byte utnyttjar surrogatpar, som kombinerar två separata 2-bytestecken för att skapa ett nytt tecken. Dessa kompletterande tecken faller utanför BMP-standardplanet och i ett av de andra flerspråkiga planen.
UTF-16 används i Windows-operativsystem och API:er, Java och JavaScript. Eftersom den inte stöder bakåtkompatibilitet med ASCII-format blev den aldrig populär på webben. UTF-16 utgör bara cirka 0,002 % av alla sidor på Internet. Web Hypertext Application Technology Working Group (WHATWG) anser att UTF-8 är "den obligatoriska kodningen för all text" och rekommenderar att program inte använder UTF-16 för webbläsarsäkerhet.
Azure NetApp Files stöder de flesta UTF-16 tecken, inklusive surrogatpar. I fall där tecknet inte stöds rapporterar Windows-klienter ett fel om att "filnamnet som du har angett inte är giltigt eller för långt".
Hantering av teckenuppsättningar över fjärrklienter
Fjärranslutningar till klienter som monterar Azure NetApp Files-volymer (till exempel SSH-anslutningar till Linux-klienter för åtkomst till NFS-monteringar) kan konfigureras för att skicka och ta emot specifika volymspråkkodningar. Språkkodningen som skickas till klienten via fjärranslutningsverktyget styr hur teckenuppsättningar skapas och visas. Därför kan en fjärranslutning som använder en annan språkkodning än en annan fjärranslutning (till exempel två olika PuTTY-fönster) visa olika resultat för tecken när fil- och mappnamn visas i Azure NetApp Files-volymen. I de flesta fall skapar detta inte avvikelser (till exempel för latinska/engelska tecken), men när det gäller specialtecken, till exempel emojis, kan resultaten variera.
Om du till exempel använder en kodning av UTF-8 för fjärranslutningen visas förutsägbara resultat för tecken i Azure NetApp Files-volymer eftersom C.UTF-8 är volymspråket. Det japanska tecknet för "data" (資) visar olika beroende på vilken kodning som skickas av terminalen.
Teckenkodning i PuTTY
När ett PuTTY-fönster använder UTF-8 (som finns i Windows översättningsinställningar) representeras tecknet korrekt för en NFSv3-monterad volym i Azure NetApp Files:

Om PuTTY-fönstret använder en annan kodning, till exempel ISO-8859-1:1998 (Latin-1, Europa, västra), visas samma tecken annorlunda även om filnamnet är detsamma.

PuTTY innehåller som standard inte CJK-kodningar. Det finns korrigeringar tillgängliga för att lägga till dessa språkuppsättningar i PuTTY.
Teckenkodningar i Bastion
Microsoft Azure rekommenderar att du använder Bastion för fjärranslutning till virtuella datorer i Azure. När du använder Bastion exponeras inte språkkodningen som skickas och tas emot i konfigurationen, men använder standard-UTF-8-kodning. Därför bör de flesta teckenuppsättningar som visas i PuTTY med UTF-8 också vara synliga i Bastion, förutsatt att teckenuppsättningarna stöds i protokollet som används.

Dricks
Andra SSH-terminaler kan användas, till exempel TeraTerm. TeraTerm tillhandahåller ett bredare utbud av teckenuppsättningar som stöds som standard, inklusive CJK-kodningar och icke-standardkodningar som Skift-JIS.
Protokollbeteenden med specialteckenuppsättningar
Azure NetApp Files-volymer använder UTF-8-kodning och har inbyggt stöd för tecken som inte överstiger 3 byte. Alla tecken i ASCII- och UTF-8-uppsättningen visas korrekt eftersom de ligger inom intervallet 1 till 3 byte. Till exempel:
- Det latinska alfabetet "A" använder 1 byte (ett av de 128 reserverade ASCII-tecknen).
- En upphovsrättssymbol © använder 2 byte.
- Tecknet "ä" använder 2 byte (1 byte för "a" och 1 byte för umlaut).
- Den japanska Kanji-symbolen för data (資) använder 3 byte.
Azure NetApp Files stöder även vissa tecken som överskrider 3 byte via surrogatparlogik (till exempel emoji), förutsatt att klientkodning och protokollversion stöder dem. Mer information om protokollbeteenden finns i:
SMB-beteenden
I SMB-volymer skapar och underhåller Azure NetApp Files två namn för filer eller kataloger i alla kataloger som har åtkomst från en SMB-klient: det ursprungliga långa namnet och ett namn i 8.3-format.
Filnamn i SMB med Azure NetApp Files
När fil- eller katalognamn överskrider tillåtna teckenbyte eller använder tecken som inte stöds genererar Azure NetApp Files ett 8,3-formatnamn på följande sätt:
- Den trunkerar den ursprungliga filen eller katalognamnet.
- Den lägger till en tilde (~) och en siffra (1–5) i fil- eller katalognamn som inte längre är unika efter att ha trunkerats. Om det finns fler än fem filer med icke-unika namn skapar Azure NetApp Files ett unikt namn utan relation till det ursprungliga namnet. För filer trunkerar Azure NetApp Files filnamnstillägget till tre tecken.
Om en NFS-klient till exempel skapar en fil med namnet specifications.htmlskapar Azure NetApp Files filnamnet specif~1.htm efter 8.3-formatet. Om det här namnet redan finns använder Azure NetApp Files ett annat nummer i slutet av filnamnet. Om en NFS-klient till exempel skapar en annan fil med namnet specifications\_new.htmlär specif~2.htmformatet 8.3 specifications\_new.html .
Specialtecken i SMB med Azure NetApp Files
När du använder SMB med Azure NetApp Files-volymer tillåts tecken som överskrider 3 byte som används i fil- och mappnamn (inklusive uttryckssymboler) på grund av stöd för surrogatpar. Följande är vad Utforskaren ser för tecken utanför BMP på en mapp som skapats från en Windows-klient när du använder engelska med standardkodningen UTF-16.
Kommentar
Standardteckensnittet i Utforskaren är Segoe UI. Teckensnittsändringar kan påverka hur vissa tecken visas på klienter.

Hur tecknen visas på klienten beror på systemets teckensnitt och språk- och språkinställningar. I allmänhet stöds tecken som hamnar i BMP i alla protokoll, oavsett om kodningen är UTF-8 eller UTF-16.
När du använder antingen CMD eller PowerShell beror teckenuppsättningsvisningen på teckensnittsinställningarna. Dessa verktyg har som standard begränsade teckensnittsalternativ. CMD använder Consolas som standardteckensnitt.
Filnamn kanske inte visas som förväntat beroende på teckensnittet som används eftersom vissa konsoler inte har inbyggt stöd för Segoe-användargränssnittet eller andra teckensnitt som återger specialtecken korrekt.
Det här problemet kan åtgärdas på Windows-klienter med hjälp av PowerShell ISE, vilket ger mer robust teckensnittsstöd. Om du till exempel ställer in PowerShell ISE på Segoe-användargränssnittet visas filnamnen med tecken som stöds korrekt.

PowerShell ISE är dock utformat för skript i stället för att hantera resurser. Nyare Windows-versioner erbjuder Windows-terminal, vilket ger kontroll över teckensnitt och kodningsvärden.
Kommentar
chcp Använd kommandot för att visa kodningen för terminalen. En fullständig lista över kodsidor finns i Kodsideidentifierare.

Om volymen är aktiverad för dubbla protokoll (både NFS och SMB) kan du observera olika beteenden. Mer information finns i Beteenden med dubbla protokoll med specialteckenuppsättningar.
NFS-beteenden
Hur NFS visar specialtecken beror på vilken version av NFS som används, klientens nationella inställningar, installerade teckensnitt och inställningarna för fjärranslutningsklienten som används. Om du till exempel använder Bastion för att komma åt ett Ubuntu-klienthandtag visas tecknet annorlunda än en PuTTY-klient inställd på ett annat språk på samma virtuella dator. De efterföljande NFS-exemplen förlitar sig på dessa nationella inställningar för den virtuella Ubuntu-datorn:
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
NFSv3-beteende
NFSv3 tillämpar inte UTF-kodning på filer och mappar. I de flesta fall bör specialteckenuppsättningar inte ha några problem. Den anslutningsklient som används kan dock påverka hur tecken skickas och tas emot. Om du till exempel använder Unicode-tecken utanför BMP för ett mappnamn i Azure-anslutningsklienten Bastion kan det leda till ett oväntat beteende på grund av hur klientkodningen fungerar.
I följande skärmbild kan Bastion inte kopiera och klistra in värdena i CLI-prompten utanför webbläsaren när du namnger en katalog över NFSv3. När du försöker kopiera och klistra in värdet för NFSv3Bastion𓀀𫝁😃𐒸visas specialtecken som citattecken i indata.

Kommandot copy-paste tillåts över NFSv3, men tecknen skapas som deras numeriska värden, vilket påverkar deras visning:
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
Den här visningen beror på den kodning som används av Bastion för att skicka textvärden vid kopiering och klistra in.
När du använder PuTTY för att skapa en mapp med samma tecken över NFSv3, är mappnamnet annorlunda i Bastion än när Bastion användes för att skapa den. Uttryckssymbolen visas som förväntat (på grund av de installerade teckensnitten och språkinställningen), men de andra tecknen (till exempel Osage "𐒸") gör det inte.

Från ett PuTTY-fönster visas tecknen korrekt:

NFSv4.x-beteende
NFSv4.x framtvingar UTF-8-kodning i fil- och mappnamn enligt internationaliseringsspecifikationerna för RFC-8881.
Om ett specialtecken skickas med icke-UTF-8-kodning kanske NFSv4.x inte tillåter värdet.
I vissa fall kan ett kommando tillåtas med ett tecken utanför BMP (Basic Multilingual Plane), men det kanske inte visar värdet när det har skapats.
Till exempel verkar utfärdande mkdir med ett mappnamn inklusive tecknen "𓀀𫝁😃𐒸" (tecken i SMP (Supplement Multilingual Planes) och Supplement Ideographic Plane (SIP)) lyckas i NFSv4.x. Mappen visas inte när kommandot körs ls .
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
Mappen finns i volymen. Att ändra till det dolda katalognamnet fungerar från PuTTY-klienten och en fil kan skapas inuti katalogen.
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
Ett stat-kommando från PuTTY bekräftar också att mappen finns:
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
Även om mappen har bekräftats finnas fungerar inte jokerteckenkommandon, eftersom klienten inte officiellt kan "se" mappen i visningen.
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
NFSv4.1 skickar ett fel till klienten när det påträffar ett tecken som inte förlitar sig på UTF-8-kodning.
När du till exempel använder Bastion för att försöka komma åt samma katalog som vi skapade med Hjälp av PuTTY via NFSv4.1 är detta resultatet:
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
NFS4ERR_INVAL omfattas av RFC-8881.
Eftersom mappen kan nås från PuTTY (på grund av att kodningen skickas och tas emot) kan den kopieras om namnet anges. När du har kopierat mappen från volymen NFSv4.1 Azure NetApp Files till volymen NFSv3 Azure NetApp Files visas mappnamnet:
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
Samma NFS4ERR\_INVAL fel kan visas om en filkonvertering (med hjälp av "iconv") till ett icke-UTF-8-format görs, till exempel Skift-JIS.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Mer information finns i Konvertera filer till olika kodningar.
Beteenden med dubbla protokoll
Med Azure NetApp Files kan volymer nås av både NFS och SMB via dubbel protokollåtkomst. På grund av de stora skillnaderna i språkkodning som används av NFS (UTF-8) och SMB (UTF-16), kan teckenuppsättningar, fil- och mappnamn och sökvägslängder ha mycket olika beteenden mellan protokoll.
Visa NFS-skapade filer och mappar från SMB
När Azure NetApp Files används för dubbelprotokollåtkomst (SMB och NFS) kan en teckenuppsättning som inte stöds av UTF-16 användas i ett filnamn som skapats med UTF-8 via NFS. I dessa scenarier, när SMB kommer åt en fil med tecken som inte stöds, trunkeras namnet i SMB med hjälp av 8.3-konventionen för kort filnamn.
NFSv3-skapade filer och SMB-beteenden med teckenuppsättningar
NFSv3 tillämpar inte UTF-8-kodning. Tecken med icke-standardspråkkodningar (till exempel Skift-JIS) fungerar med Azure NetApp Files när du använder NFSv3.
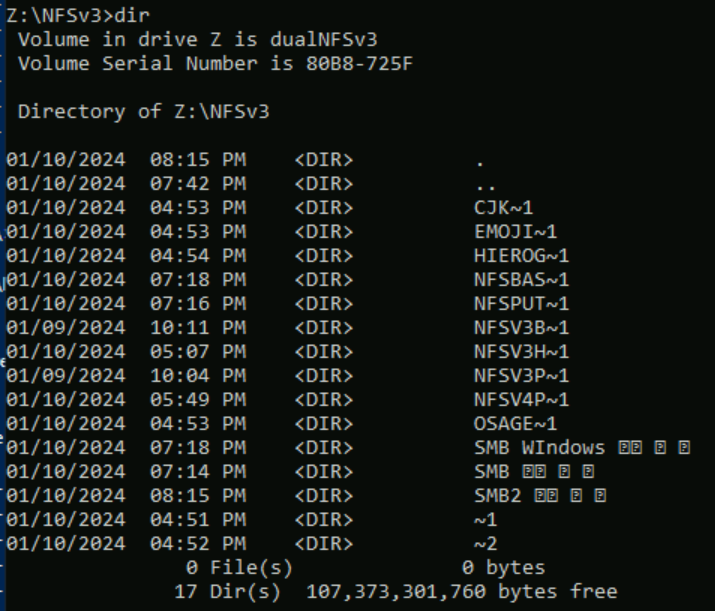
I följande exempel skapades en serie mappnamn med olika teckenuppsättningar från olika plan i Unicode i en Azure NetApp Files-volym med NFSv3. När de visas från NFSv3 visas dessa korrekt.
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
Från Windows SMB visas mapparna med tecken som finns i BMP korrekt, men tecken utanför planet visas med 8.3-namnformatet på grund av att UTF-8/UTF-16-konverteringen är inkompatibel för dessa tecken.
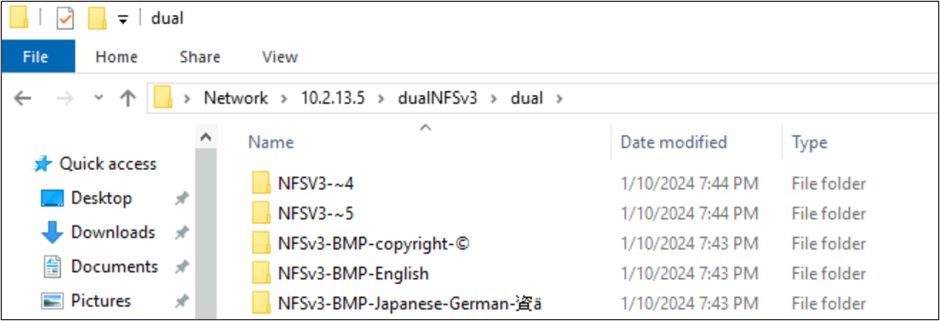
NFSv4.1-skapade filer och SMB-beteenden med teckenuppsättningar
I föregående exempel skapades en mapp med namnet NFSv4 Putty 𓀀𫝁😃𐒸 på en Azure NetApp Files-volym över NFSv4.1, men kunde inte visas med NFSv4.1. Det kan dock ses med hjälp av SMB. Namnet trunkeras i SMB till ett 8.3-format som stöds på grund av teckenuppsättningar som inte stöds som skapats från NFS-klienten och den inkompatibla UTF-8/UTF-16-konverteringen för tecken i olika Unicode-plan.
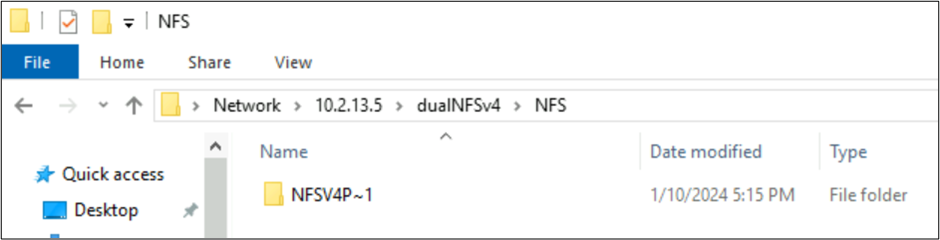
När ett mappnamn använder standard-UTF-8-tecken som finns i BMP (engelska eller på annat sätt) översätter SMB namnen korrekt.
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
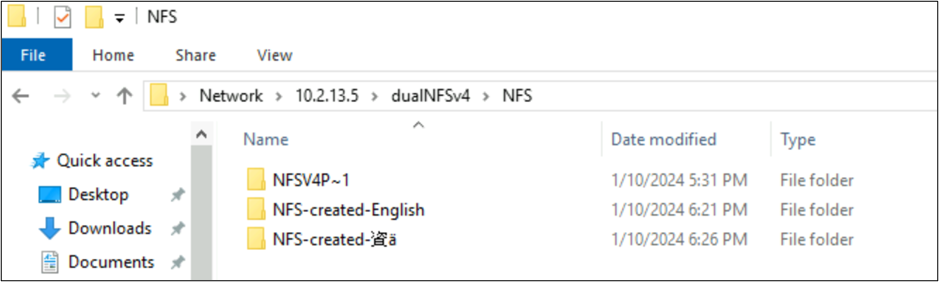
SMB-skapade filer och mappar över NFS
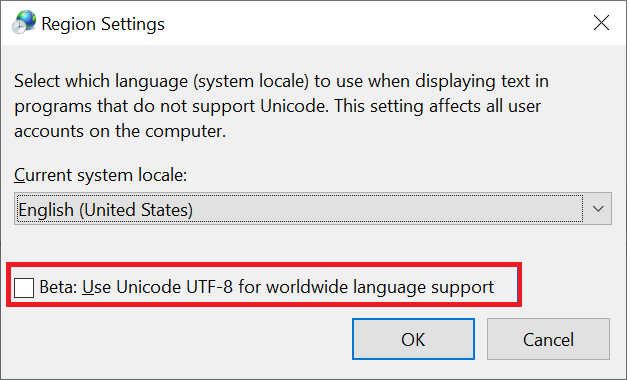
Windows-klienter är den primära typen av klienter som används för att komma åt SMB-resurser. Dessa klienter är som standard UTF-16-kodning. Det går att stödja vissa UTF-8-kodade tecken i Windows genom att aktivera det i regioninställningarna:
När en fil eller mapp skapas över en SMB-resurs i Azure NetApp Files kodas teckenuppsättningen som UTF-16. Därför kanske klienter som använder UTF-8-kodning (till exempel Linux-baserade NFS-klienter) kanske inte kan översätta vissa teckenuppsättningar korrekt – särskilt tecken som ligger utanför BMP (Basic Multilingual Plane).
Teckenbeteende som inte stöds
I dessa scenarier, när en NFS-klient kommer åt en fil som skapats med SMB med tecken som inte stöds, visas namnet som en serie numeriska värden som representerar Unicode-värdena för tecknet.
Den här mappen skapades till exempel i Utforskaren i Windows med hjälp av tecken utanför BMP.
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
Över NFSv3 visas den SMB-skapade mappen:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Över NFSv4.1 visas den SMB-skapade mappen på följande sätt:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Teckenbeteende som stöds
När tecknen finns i BMP finns det inga problem mellan SMB- och NFS-protokollen och deras versioner.
Till exempel visas ett mappnamn som skapats med hjälp av SMB på en Azure NetApp Files-volym med tecken som finns i BMP på flera språk (engelska, tyska, kyrilliska, runic) i alla protokoll och versioner.
- Grundläggande latinsk "SMB"
- Grekiska "ͶΘΩ"
- Kyrillisk "ЁЄЊ"
- Runic "ᚠᚱᛯ"
- CJK Compatibility Ideographs "豈滑虜"
Så här visas namnet i SMB:
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Så här visas namnet från NFSv3:
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Så här visas namnet från NFSv4.1:
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Konvertera filer till olika kodningar
Fil- och mappnamn är inte de enda delarna av filsystemobjekt som använder språkkodningar. Filinnehåll (till exempel specialtecken i en textfil) kan också spela en roll. Om en fil till exempel försöker sparas med specialtecken i ett inkompatibelt format kan ett felmeddelande visas. I det här fallet kan en fil med Katagana-tecken inte sparas i ANSI, eftersom dessa tecken inte finns i den kodningen.
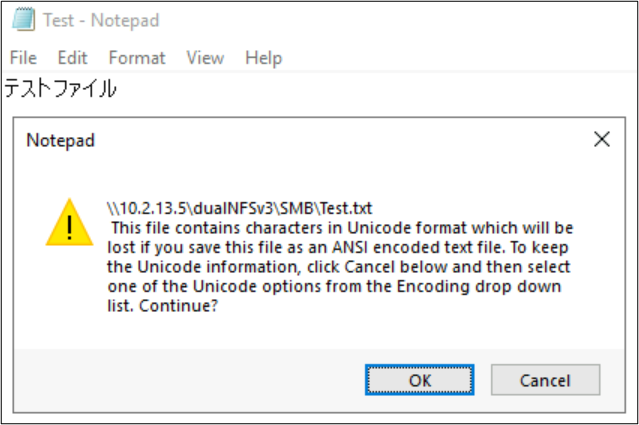
När filen har sparats i det formatet konverteras tecknen till frågetecken:
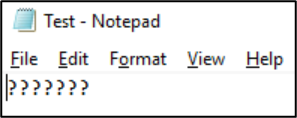
Filkodningar kan visas från NAS-klienter. På Windows-klienter kan du använda ett program som Anteckningar eller Anteckningar++ för att visa en kodning av en fil. Om Windows-undersystem för Linux (WSL) eller Git är installerade på klienten file kan kommandot användas.
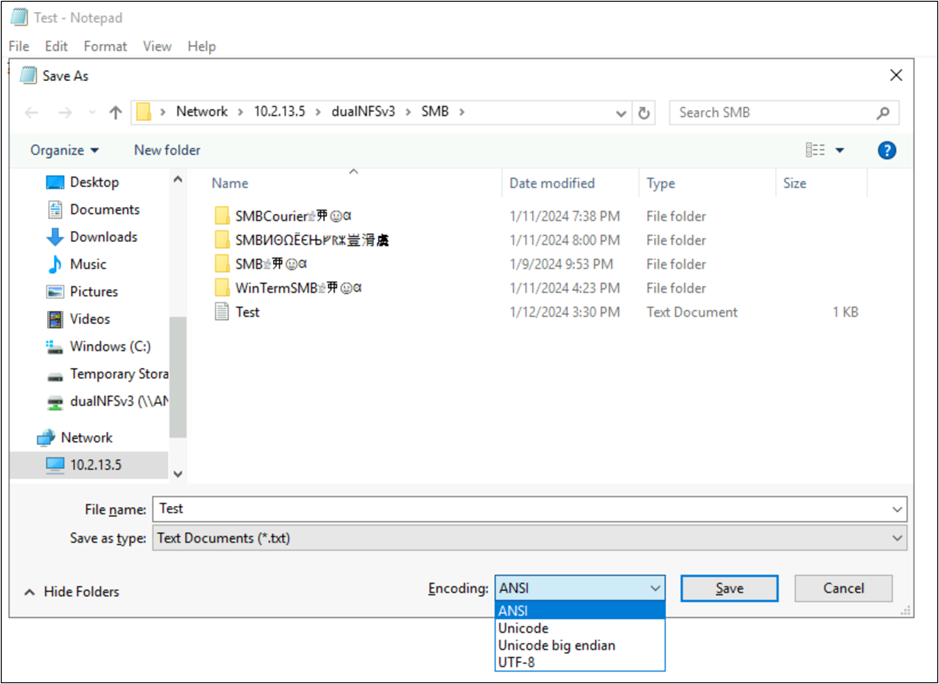
Med de här programmen kan du också ändra filens kodning genom att spara som olika kodningstyper. Dessutom kan PowerShell användas för att konvertera kodning på filer med Get-Content cmdletarna och Set-Content .
Till exempel kodas filen utf8-text.txt som UTF-8 och innehåller tecken utanför BMP. Eftersom UTF-8 används visas tecknen korrekt.
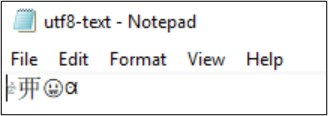
Om kodningen konverteras till UTF-32 visas inte tecknen korrekt.
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
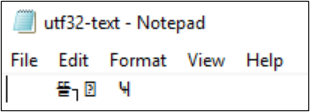
Get-Content kan också användas för att visa filinnehållet. Som standard använder PowerShell UTF-16-kodning (kodsida 437) och teckensnittsvalen för konsolen är begränsade, så den UTF-8-formaterade filen med specialtecken kan inte visas korrekt:
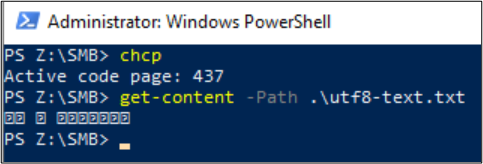
Linux-klienter kan använda file kommandot för att visa kodningen av filen. Om en fil skapas med SMB i miljöer med dubbla protokoll kan Linux-klienten med hjälp av NFS kontrollera filkodningen.
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
Filkodningskonvertering kan utföras på Linux-klienter med hjälp av iconv kommandot . Om du vill se listan över kodningsformat som stöds använder du iconv -l.
Den UTF-8-kodade filen kan till exempel konverteras till UTF-16.
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
Om tecknet som anges på filens namn eller i filens innehåll inte stöds av målkodningen tillåts inte konvertering. Skift-JIS kan till exempel inte stödja tecknen i filens innehåll.
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
Om en fil har tecken som stöds av kodningen lyckas konverteringen. Om filen till exempel innehåller Katagana-tecknen ストファイル, lyckas Skift-JIS-konverteringen över NFS. Eftersom NFS-klienten som används här inte förstår Shift-JIS på grund av nationella inställningar, visar kodningen "unknown-8bit".
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
Eftersom Azure NetApp Files-volymer endast stöder UTF-8-kompatibel formatering konverteras Katagana-tecknen till ett oläsbart format.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
När du använder NFSv4.x tillåts konvertering när icke-kompatibla tecken finns i filens innehåll, även om NFSv4.x framtvingar UTF-8-kodning. I det här exemplet visar en UTF-8-kodad fil med Katagana-tecken som finns på en Azure NetApp Files-volym innehållet i en fil korrekt.
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
Men när den har konverterats visas tecknen i filen felaktigt på grund av den inkompatibla kodningen.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Om filens namn innehåller tecken som inte stöds för UTF-8 lyckas konverteringen över NFSv3, men redundansväxlar NFSv4.x på grund av protokollversionens UTF-8-tillämpning.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Metodtips för teckenuppsättning
När du använder specialtecken eller tecken utanför standardvolymerna Basic Multilingual Plane (BMP) på Azure NetApp Files bör vissa metodtips beaktas.
- Eftersom Azure NetApp Files-volymer använder UTF-8-volymspråk bör filkodningen för NFS-klienter också använda UTF-8-kodning för konsekventa resultat.
- Teckenuppsättningar i filnamn eller i filinnehållet ska vara UTF-8-kompatibla för korrekt visning och funktionalitet.
- Eftersom SMB använder UTF-16-teckenkodning kanske tecken utanför BMP inte visas korrekt över NFS i volymer med dubbla protokoll. Minimera som möjligt användningen av specialtecken i filinnehållet.
- Undvik att använda specialtecken utanför BMP i filnamn, särskilt när du använder NFSv4.1 eller volymer med dubbla protokoll.
- För teckenuppsättningar som inte finns i BMP bör UTF-8-kodning tillåta visning av tecknen i Azure NetApp Files när du använder ett enda filprotokoll (endast SMB eller endast NFS). Volymer med dubbla protokoll kan dock inte hantera dessa teckenuppsättningar i de flesta fall.
- Icke-standardkodning (till exempel Skift-JIS) stöds inte på Azure NetApp Files-volymer.
- Surrogatpartecken (till exempel emoji) stöds på Azure NetApp Files-volymer.