Redundans och korrigering för Azure Managed Redis (förhandsversion)
För att skapa motståndskraftiga och lyckade klientprogram är det viktigt att förstå redundans i Tjänsten Azure Managed Redis (förhandsversion). En redundansväxling kan vara en del av planerade hanteringsåtgärder eller orsakas av oplanerade maskinvaru- eller nätverksfel. En vanlig användning av cacheredundans kommer när hanteringstjänsten korrigerar Binärfilerna för Azure Managed Redis.
I den här artikeln hittar du den här informationen:
- Vad är en redundansväxling?
- Hur redundansväxling sker under korrigeringen.
- Så här skapar du ett motståndskraftigt klientprogram.
Vad är en redundansväxling?
Vi börjar med en översikt över redundans för Azure Managed Redis.
En snabb sammanfattning av cachearkitekturen
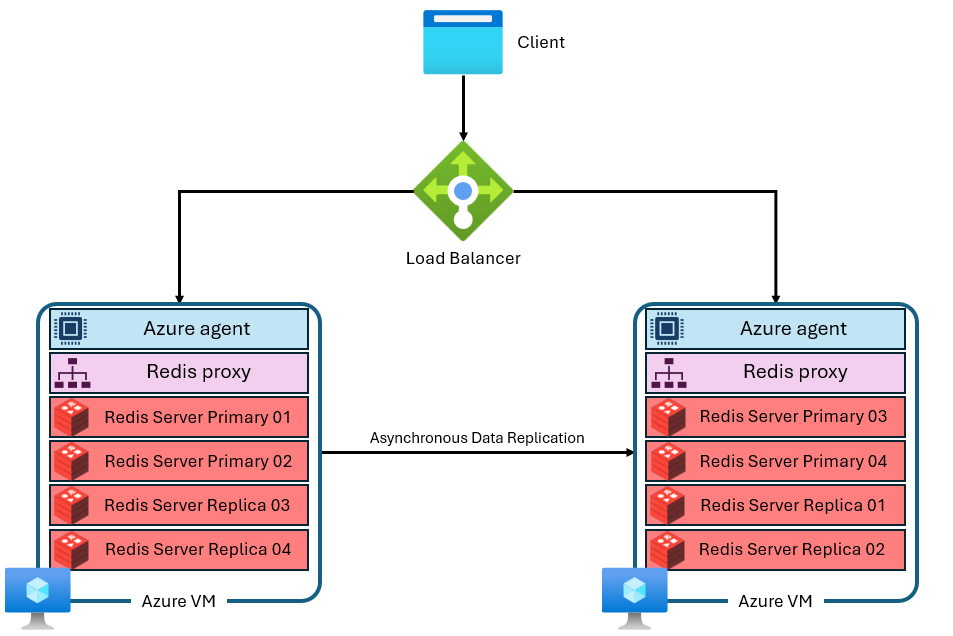
En cache skapas av flera virtuella datorer med separata och privata IP-adresser. Varje virtuell dator (eller "nod") kör flera Redis-serverprocesser (kallas "shards") parallellt. Flera shards möjliggör effektivare användning av vCPU:er på varje virtuell dator och högre prestanda. Alla primära Redis-shards finns inte på samma virtuella dator/nod. I stället distribueras primära fragment och replikskärvor över båda noderna. Eftersom primära shards använder fler CPU-resurser än replikskärvor gör den här metoden att fler primära shards kan köras parallellt. Varje nod har en proxyprocess med höga prestanda för att hantera shards, hantera anslutningshantering och utlösa självåterställning. En shard kan vara nere medan de andra förblir tillgängliga.
Mer detaljerad information om Azure Managed Redis-arkitekturen finns här.
Förklaring av en redundansväxling
En redundansväxling inträffar när en eller flera replikskärvor befordrar sig till primära shards och de gamla primära fragmenten stänger befintliga anslutningar. En redundansväxling kan vara planerad eller oplanerad.
En planerad redundansväxling sker under två olika tider:
- Systemuppdateringar, till exempel Redis-korrigeringar eller OS-uppgraderingar.
- Hanteringsåtgärder, till exempel skalning och omstart.
Eftersom noderna får förhandsmeddelande om uppdateringen kan de kooperativt byta roller och snabbt uppdatera lastbalanseraren för ändringen. En planerad redundans slutar vanligtvis på mindre än 1 sekund.
En oplanerad redundansväxling kan inträffa på grund av maskinvarufel, nätverksfel eller andra oväntade avbrott för en eller flera noder i klustret. Replikskärvorna på de återstående noderna befordras till primära för att upprätthålla tillgängligheten, men processen tar längre tid. En replikshard måste först identifiera att dess primära shard inte är tillgänglig innan den kan starta redundansväxlingen. Replikskärvan måste också kontrollera att det här oplanerade felet inte är tillfälligt eller lokalt för att undvika onödig redundans. Den här fördröjningen i identifieringen innebär att en oplanerad redundans normalt avslutas inom 10 till 15 sekunder.
Hur sker korrigeringar?
Azure Managed Redis-tjänsten uppdaterar regelbundet din cache med de senaste plattformsfunktionerna och korrigeringarna. För att korrigera en cache följer tjänsten dessa steg:
- Tjänsten skapar nya uppdaterade virtuella datorer som ersätter alla virtuella datorer som korrigeras.
- Sedan befordras en av de nya virtuella datorerna som klusterledare.
- En i taget tas alla noder som korrigeras bort från klustret. Alla shards på dessa virtuella datorer degraderads och migreras till en av de nya virtuella datorerna.
- Slutligen tas alla virtuella datorer som ersattes bort.
Varje fragment i en klustrad cache korrigeras separat och stänger inte anslutningar till en annan shard.
Flera cacheminnen i samma resursgrupp och region korrigeras också en i taget. Cacheminnen som finns i olika resursgrupper eller olika regioner kan korrigeras samtidigt.
Eftersom fullständig datasynkronisering sker innan processen upprepas är det osannolikt att dataförlust sker för cacheminnet. Du kan skydda dig ytterligare mot dataförlust genom att exportera data och aktivera beständighet.
Ytterligare cacheinläsning
När en redundansväxling sker måste cacheminnena replikera data från en nod till en annan. Den här replikeringen orsakar en viss belastningsökning i både serverminnet och PROCESSORn. Om cacheinstansen redan är kraftigt inläst kan klientprogrammen få ökad svarstid. I extrema fall kan klientprogram få timeout-undantag.
Hur påverkar redundansen mitt klientprogram?
Klientprogram kan få vissa fel från sin Azure Managed Redis-instans. Antalet fel som visas av ett klientprogram beror på hur många åtgärder som väntade på anslutningen vid tidpunkten för redundansväxlingen. Alla anslutningar som dirigeras via noden som stängde dess anslutningar ser fel.
Många klientbibliotek kan utlösa olika typer av fel när anslutningarna bryts, inklusive:
- Timeout-undantag
- Anslutningsfel
- Socket-undantag
Antalet och typen av undantag beror på var begäran finns i kodsökvägen när cachen stänger sina anslutningar. En åtgärd som till exempel skickar en begäran men inte har fått något svar när redundansväxlingen inträffar kan få ett timeout-undantag. Nya begäranden om det stängda anslutningsobjektet tar emot anslutningsfel tills återanslutningen lyckas.
De flesta klientbibliotek försöker återansluta till cacheminnet om de är konfigurerade för att göra det. Oförutsedda buggar kan dock ibland placera biblioteksobjekten i ett oåterkalleligt tillstånd. Om felen kvarstår längre än en förkonfigurerad tid ska anslutningsobjektet återskapas. I Microsoft.NET och andra objektorienterade språk kan du återskapa anslutningen utan att starta om programmet med hjälp av ett ForceReconnect-mönster.
Vilka uppdateringar ingår under underhåll?
Underhållet omfattar följande uppdateringar:
- Redis Server-uppdateringar: Alla uppdateringar eller korrigeringar av Redis-serverns binärfiler.
- Uppdateringar av virtuell dator (VM): Alla uppdateringar av den virtuella datorn som är värd för Redis-tjänsten. Vm-uppdateringar omfattar korrigering av programvarukomponenter i värdmiljön för uppgradering av nätverkskomponenter eller inaktivering.
Visas underhåll i tjänstens hälsotillstånd i Azure Portal före en korrigering?
Nej, underhåll visas inte under tjänstens hälsa i portalen eller någon annan plats.
Ändringar i klientnätverkskonfigurationen
Vissa ändringar i nätverkskonfigurationen på klientsidan kan utlösa Inga tillgängliga anslutningsfel. Sådana ändringar kan vara:
- Växla ett klientprograms virtuella IP-adress mellan mellanlagrings- och produktionsplatser.
- Skala storleken eller antalet instanser av ditt program.
Sådana ändringar kan orsaka ett anslutningsproblem som vanligtvis varar mindre än en minut. Klientprogrammet förlorar förmodligen anslutningen till andra externa nätverksresurser, men även till Azure Managed Redis-tjänsten.
Skapa återhämtning
Du kan inte undvika redundans helt. Skriv i stället dina klientprogram för att vara motståndskraftiga mot anslutningsavbrott och misslyckade begäranden. De flesta klientbibliotek återansluter automatiskt till cacheslutpunkten, men få av dem försöker försöka utföra misslyckade begäranden igen. Beroende på programscenariot kan det vara klokt att använda logik för återförsök med backoff.
Hur gör jag för att göra mitt program motståndskraftigt?
Se dessa designmönster för att skapa motståndskraftiga klienter, särskilt kretsbrytaren och återförsöksmönster:
- Tillförlitlighetsmönster – Mönster för molndesign
- Återförsöksvägledning för Azure-tjänster – Metodtips för molnprogram
- Implementera återförsök med exponentiell backoff