Självstudie: Automatiserad valideringstestning
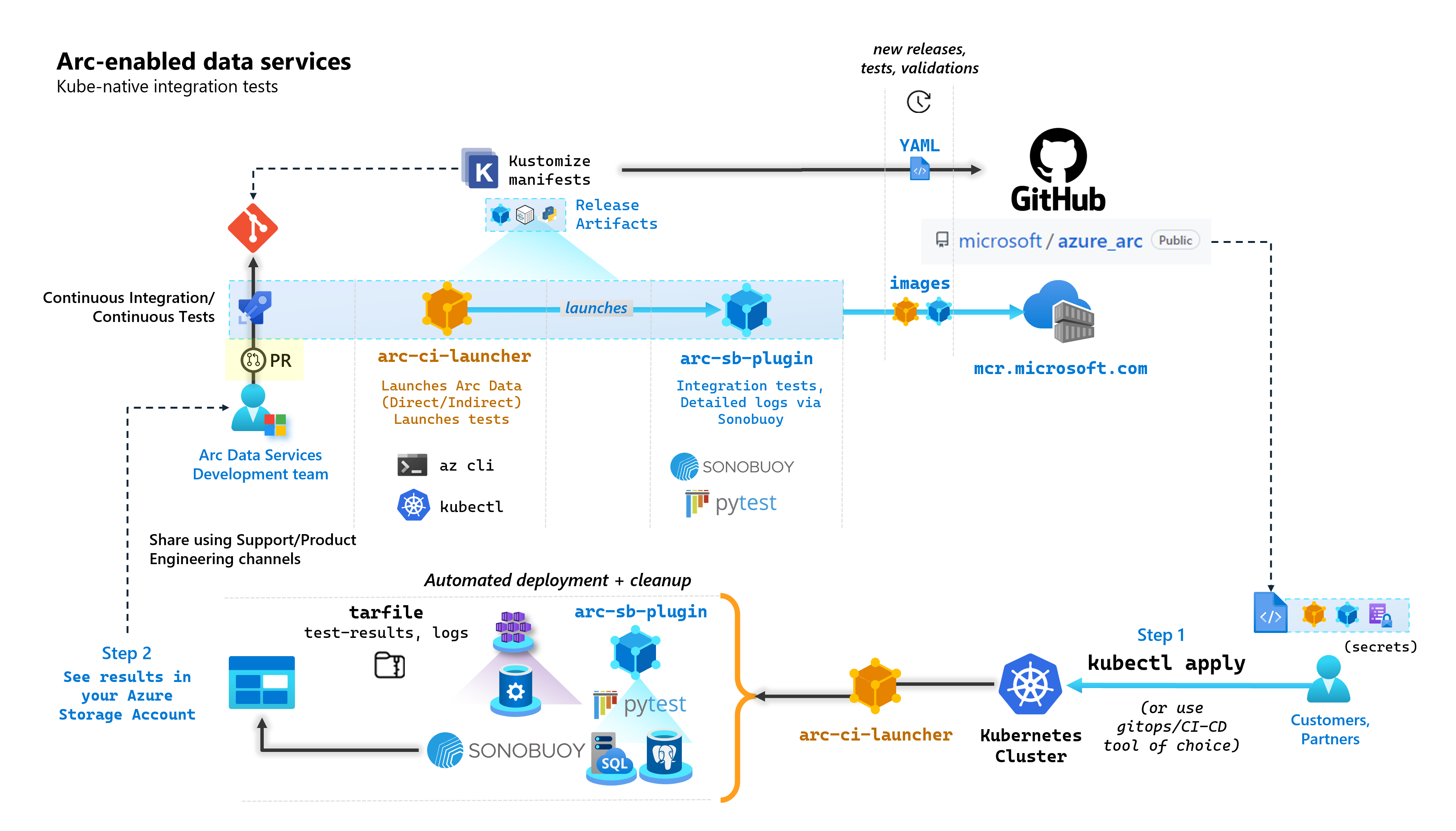
Som en del av varje incheckning som bygger upp Arc-aktiverade datatjänster kör Microsoft automatiserade CI/CD-pipelines som utför tester från slutpunkt till slutpunkt. Dessa tester dirigeras via två containrar som underhålls tillsammans med kärnprodukten (Data Controller, SQL Managed Instance som aktiveras av Azure Arc & PostgreSQL-servern). Dessa containrar är:
arc-ci-launcher: Innehåller distributionsberoenden (till exempel CLI-tillägg) samt produktdistributionskod (med Azure CLI) för både direkta och indirekta anslutningslägen. När Kubernetes har registrerats med datakontrollanten använder containern Sonobuoy för att utlösa parallella integreringstester.arc-sb-plugin: Ett Sonobuoy-plugin-program som innehåller Pytest-baserade integreringstester från slutpunkt till slutpunkt, allt från enkla röktester (distributioner, borttagningar) till komplexa scenarier med hög tillgänglighet, kaostester (resursborttagningar) osv.
Dessa testcontainrar görs offentligt tillgängliga för kunder och partner för att utföra Arc-aktiverade valideringstester för datatjänster i sina egna Kubernetes-kluster som körs var som helst för att verifiera:
- Kubernetes-distribution/versioner
- Värddisto/versioner
- Lagring (
StorageClass/CSI), nätverk (t.ex.LoadBalancers, DNS) - Annan Kubernetes- eller infrastrukturspecifik konfiguration
För kunder som har för avsikt att köra Arc-aktiverade datatjänster på en odokumenterad distribution måste de köra dessa valideringstester för att anses ha stöd. Dessutom kan partner använda den här metoden för att certifiera att deras lösning är kompatibel med Arc-aktiverade datatjänster – se Kubernetes-validering av Azure Arc-aktiverade datatjänster.
I följande diagram beskrivs den här processen på hög nivå:
I den här självstudien lär du dig att:
- Distribuera
arc-ci-launchermed hjälp avkubectl - Granska valideringstestresultatet i ditt Azure Blob Storage-konto
Förutsättningar
Autentiseringsuppgifter:
- Filen
test.env.tmplinnehåller nödvändiga autentiseringsuppgifter som krävs och är en kombination av de befintliga förutsättningar som krävs för att registrera ett Azure Arc-anslutet kluster och direktansluten datakontrollant. Konfigurationen av den här filen beskrivs nedan med exempel. - En kubeconfig-fil till det testade Kubernetes-klustret med
cluster-adminåtkomst (krävs för registrering av anslutet kluster just nu)
- Filen
Klientverktyg:
kubectlinstalled – minimum version (Major:"1", Minor:"21")gitkommandoradsgränssnitt (eller gränssnittsbaserade alternativ)
Förberedelse av Kubernetes-manifest
Startprogrammet görs tillgängligt som en del av microsoft/azure_arc lagringsplatsen, eftersom ett Kustomize-manifest – Kustomize är inbyggt kubectl – så inga ytterligare verktyg krävs.
- Klona lagringsplatsen lokalt:
git clone https://github.com/microsoft/azure_arc.git
- Gå till
azure_arc/arc_data_services/test/launcherför att se följande mappstruktur:
├── base <- Comon base for all Kubernetes Clusters
│ ├── configs
│ │ └── .test.env.tmpl <- To be converted into .test.env with credentials for a Kubernetes Secret
│ ├── kustomization.yaml <- Defines the generated resources as part of the launcher
│ └── launcher.yaml <- Defines the Kubernetes resources that make up the launcher
└── overlays <- Overlays for specific Kubernetes Clusters
├── aks
│ ├── configs
│ │ └── patch.json.tmpl <- To be converted into patch.json, patch for Data Controller control.json
│ └── kustomization.yaml
├── kubeadm
│ ├── configs
│ │ └── patch.json.tmpl
│ └── kustomization.yaml
└── openshift
├── configs
│ └── patch.json.tmpl
├── kustomization.yaml
└── scc.yaml
I den här självstudien ska vi fokusera på steg för AKS, men överläggsstrukturen ovan kan utökas till att omfatta ytterligare Kubernetes-distributioner.
Manifestet redo att distribueras representerar följande:
├── base
│ ├── configs
│ │ ├── .test.env <- Config 1: For Kubernetes secret, see sample below
│ │ └── .test.env.tmpl
│ ├── kustomization.yaml
│ └── launcher.yaml
└── overlays
└── aks
├── configs
│ ├── patch.json.tmpl
│ └── patch.json <- Config 2: For control.json patching, see sample below
└── kustomization.yam
Det finns två filer som måste genereras för att lokalisera startprogrammet för att köras i en specifik miljö. Var och en av dessa filer kan genereras genom att kopiera och klistra in och fylla i var och en av mallfilerna (*.tmpl) ovan:
.test.env: fyll i från.test.env.tmplpatch.json: fyll i frånpatch.json.tmpl
Dricks
.test.env är en enda uppsättning miljövariabler som styr startprogrammets beteende. Om du genererar den med försiktighet för en viss miljö säkerställs återgivningen av startprogrammets beteende.
Konfiguration 1: .test.env
Ett ifyllt exempel på .test.env filen som genereras baserat på .test.env.tmpl delas nedan med infogad kommentar.
Viktigt!
Syntaxen export VAR="value" nedan är inte avsedd att köras lokalt till källmiljövariabler från datorn – men finns där för startprogrammet. Startprogrammet monterar den här .test.env filen som en Kubernetes secret med Kustomizes secretGenerator (Kustomize tar en fil, base64 kodar hela filens innehåll och omvandlar den till en Kubernetes-hemlighet). Under initieringen kör startprogrammet bash-kommandot source , som importerar miljövariablerna från den as-is-monterade .test.env filen till startprogrammets miljö.
Efter kopiering .test.env.tmpl och redigering för att skapa .test.envbör den genererade filen med andra ord se ut ungefär som exemplet nedan. Processen för att fylla i .test.env filen är identisk mellan operativsystem och terminaler.
Dricks
Det finns en handfull miljövariabler som kräver ytterligare förklaring av tydligheten i reproducerbarheten. Dessa kommer att kommenteras med see detailed explanation below [X].
Dricks
Observera att exemplet .test.env nedan är för direktläge . Vissa av dessa variabler, till exempel ARC_DATASERVICES_EXTENSION_VERSION_TAG gäller inte för indirekt läge. För enkelhetens .test.env skull är det bäst att konfigurera filen med variabler i direktläge i åtanke. Om du byter CONNECTIVITY_MODE=indirect kommer startprogrammet att ignorera specifika inställningar för direktläge och använda en delmängd från listan.
Med andra ord kan vi med planering för direktläge uppfylla variabler i indirekt läge.
Färdigt exempel på .test.env:
# ======================================
# Arc Data Services deployment version =
# ======================================
# Controller deployment mode: direct, indirect
# For 'direct', the launcher will also onboard the Kubernetes Cluster to Azure Arc
# For 'indirect', the launcher will skip Azure Arc and extension onboarding, and proceed directly to Data Controller deployment - see `patch.json` file
export CONNECTIVITY_MODE="direct"
# The launcher supports deployment of both GA/pre-GA trains - see detailed explanation below [1]
export ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN="stable"
export ARC_DATASERVICES_EXTENSION_VERSION_TAG="1.11.0"
# Image version
export DOCKER_IMAGE_POLICY="Always"
export DOCKER_REGISTRY="mcr.microsoft.com"
export DOCKER_REPOSITORY="arcdata"
export DOCKER_TAG="v1.11.0_2022-09-13"
# "arcdata" Azure CLI extension version override - see detailed explanation below [2]
export ARC_DATASERVICES_WHL_OVERRIDE=""
# ================
# ARM parameters =
# ================
# Custom Location Resource Provider Azure AD Object ID - this is a single, unique value per Azure AD tenant - see detailed explanation below [3]
export CUSTOM_LOCATION_OID="..."
# A pre-rexisting Resource Group is used if found with the same name. Otherwise, launcher will attempt to create a Resource Group
# with the name specified, using the Service Principal specified below (which will require `Owner/Contributor` at the Subscription level to work)
export LOCATION="eastus"
export RESOURCE_GROUP_NAME="..."
# A Service Principal with "sufficient" privileges - see detailed explanation below [4]
export SPN_CLIENT_ID="..."
export SPN_CLIENT_SECRET="..."
export SPN_TENANT_ID="..."
export SUBSCRIPTION_ID="..."
# Optional: certain integration tests test upload to Log Analytics workspace:
# https://learn.microsoft.com/azure/azure-arc/data/upload-logs
export WORKSPACE_ID="..."
export WORKSPACE_SHARED_KEY="..."
# ====================================
# Data Controller deployment profile =
# ====================================
# Samples for AKS
# To see full list of CONTROLLER_PROFILE, run: az arcdata dc config list
export CONTROLLER_PROFILE="azure-arc-aks-default-storage"
# azure, aws, gcp, onpremises, alibaba, other
export DEPLOYMENT_INFRASTRUCTURE="azure"
# The StorageClass used for PVCs created during the tests
export KUBERNETES_STORAGECLASS="default"
# ==============================
# Launcher specific parameters =
# ==============================
# Log/test result upload from launcher container, via SAS URL - see detailed explanation below [5]
export LOGS_STORAGE_ACCOUNT="<your-storage-account>"
export LOGS_STORAGE_ACCOUNT_SAS="?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=..."
export LOGS_STORAGE_CONTAINER="arc-ci-launcher-1662513182"
# Test behavior parameters
# The test suites to execute - space seperated array,
# Use these default values that run short smoke tests, further elaborate test suites will be added in upcoming releases
export SQL_HA_TEST_REPLICA_COUNT="3"
export TESTS_DIRECT="direct-crud direct-hydration controldb"
export TESTS_INDIRECT="billing controldb kube-rbac"
export TEST_REPEAT_COUNT="1"
export TEST_TYPE="ci"
# Control launcher behavior by setting to '1':
#
# - SKIP_PRECLEAN: Skips initial cleanup
# - SKIP_SETUP: Skips Arc Data deployment
# - SKIP_TEST: Skips sonobuoy tests
# - SKIP_POSTCLEAN: Skips final cleanup
# - SKIP_UPLOAD: Skips log upload
#
# See detailed explanation below [6]
export SKIP_PRECLEAN="0"
export SKIP_SETUP="0"
export SKIP_TEST="0"
export SKIP_POSTCLEAN="0"
export SKIP_UPLOAD="0"
Viktigt!
Om du utför konfigurationsfilens generering på en Windows-dator måste du konvertera sekvensen End-of-Line från CRLF (Windows) till LF (Linux) som arc-ci-launcher körs som en Linux-container. Om du lämnar radslutet som CRLF kan orsaka ett fel vid arc-ci-launcher containerstart , till exempel: /launcher/config/.test.env: $'\r': command not found Utför ändringen med VSCode (längst ned till höger i fönstret):

Detaljerad förklaring av vissa variabler
1. ARC_DATASERVICES_EXTENSION_* – Tilläggsversion och träna
Obligatoriskt: detta krävs för
directlägesdistributioner.
Startprogrammet kan distribuera både GA- och pre-GA-versioner.
Tilläggsversionen till versionstränadsmappningen (ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN) hämtas härifrån:
- GA:
stable- Versionslogg - Pre-GA:
preview- Förhandsversionstestning
2. ARC_DATASERVICES_WHL_OVERRIDE – Url för nedladdning av tidigare version av Azure CLI
Valfritt: lämna detta tomt för
.test.envatt använda det förpaketerade standardvärdet.
Startavbildningen är förpaketerad med den senaste arcdata CLI-versionen vid tidpunkten för varje containeravbildningsversion. För att arbeta med äldre versioner och uppgraderingstestning kan det dock vara nödvändigt att tillhandahålla startprogrammet med nedladdningslänken för Azure CLI-blob-URL:en för att åsidosätta den förpaketerade versionen. Om du till exempel vill instruera startprogrammet att installera version 1.4.3 fyller du i:
export ARC_DATASERVICES_WHL_OVERRIDE="https://azurearcdatacli.blob.core.windows.net/cli-extensions/arcdata-1.4.3-py2.py3-none-any.whl"
CLI-versionen till blob-URL-mappningen finns här.
3. CUSTOM_LOCATION_OID – Objekt-ID för anpassade platser från din specifika Microsoft Entra-klientorganisation
Obligatoriskt: detta krävs för att skapa anpassad plats för anslutna kluster.
Följande steg hämtas från Aktivera anpassade platser i klustret för att hämta det unika objekt-ID:t för anpassad plats för din Microsoft Entra-klientorganisation.
Det finns två metoder för att CUSTOM_LOCATION_OID hämta för din Microsoft Entra-klientorganisation.
Via Azure CLI:
az ad sp show --id bc313c14-388c-4e7d-a58e-70017303ee3b --query objectId -o tsv # 51dfe1e8-70c6-4de... <--- This is for Microsoft's own tenant - do not use, the value for your tenant will be different, use that instead to align with the Service Principal for launcher.
Via Azure Portal – navigera till bladet Microsoft Entra och sök
Custom Locations RPefter :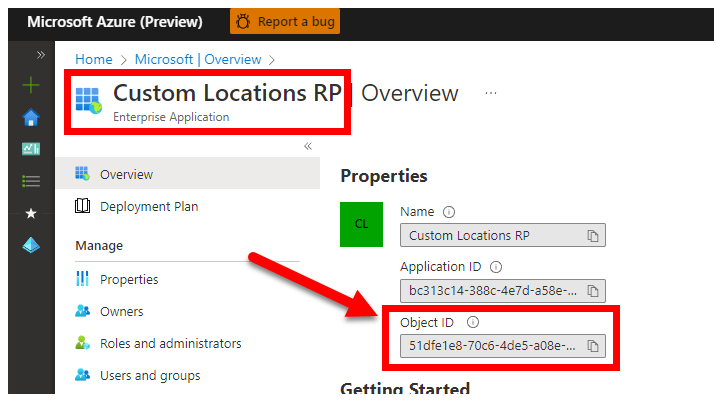
4. SPN_CLIENT_* – Autentiseringsuppgifter för tjänstens huvudnamn
Obligatoriskt: detta krävs för distributioner i direktläge.
Startprogrammet loggar in på Azure med hjälp av dessa autentiseringsuppgifter.
Valideringstestning är tänkt att utföras på Kubernetes-kluster och Azure-prenumerationer som inte är produktionsbaserade/testas – med fokus på funktionell validering av kubernetes/infrastrukturkonfigurationen. För att undvika antalet manuella steg som krävs för att utföra uppskjutningar rekommenderar vi därför att du anger ett SPN_CLIENT_ID/SECRET som har Owner på resursgruppsnivå (eller prenumerationsnivå), eftersom det skapar flera resurser i den här resursgruppen samt tilldelar behörigheter till dessa resurser mot flera hanterade identiteter som skapats som en del av distributionen (dessa rolltilldelningar kräver i sin tur att tjänstens huvudnamn har Owner).
5. LOGS_STORAGE_ACCOUNT_SAS – SAS-URL för Blob Storage-konto
Rekommenderas: om du lämnar detta tomt får du inga testresultat och loggar.
Startprogrammet behöver en beständig plats (Azure Blob Storage) för att ladda upp resultat till, eftersom Kubernetes inte (ännu) tillåter kopiering av filer från stoppade/slutförda poddar – se här. Startprogrammet uppnår anslutning till Azure Blob Storage med hjälp av en SAS-URL med kontoomfattning (till skillnad från container - eller blobomfång ) – en signerad URL med en tidsbunden åtkomstdefinition – se Bevilja begränsad åtkomst till Azure Storage-resurser med hjälp av signaturer för delad åtkomst (SAS) för att:
- Skapa en ny lagringscontainer i det befintliga lagringskontot (
LOGS_STORAGE_ACCOUNT), om den inte finns (namn baserat påLOGS_STORAGE_CONTAINER) - Skapa nya, unikt namngivna blobar (tar-filer för testloggar)
Följande steg kommer från Bevilja begränsad åtkomst till Azure Storage-resurser med hjälp av signaturer för delad åtkomst (SAS).
Dricks
SAS-URL:er skiljer sig från lagringskontonyckeln, en SAS-URL formateras på följande sätt.
?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=...
Det finns flera metoder för att generera en SAS-URL. Det här exemplet visar portalen:
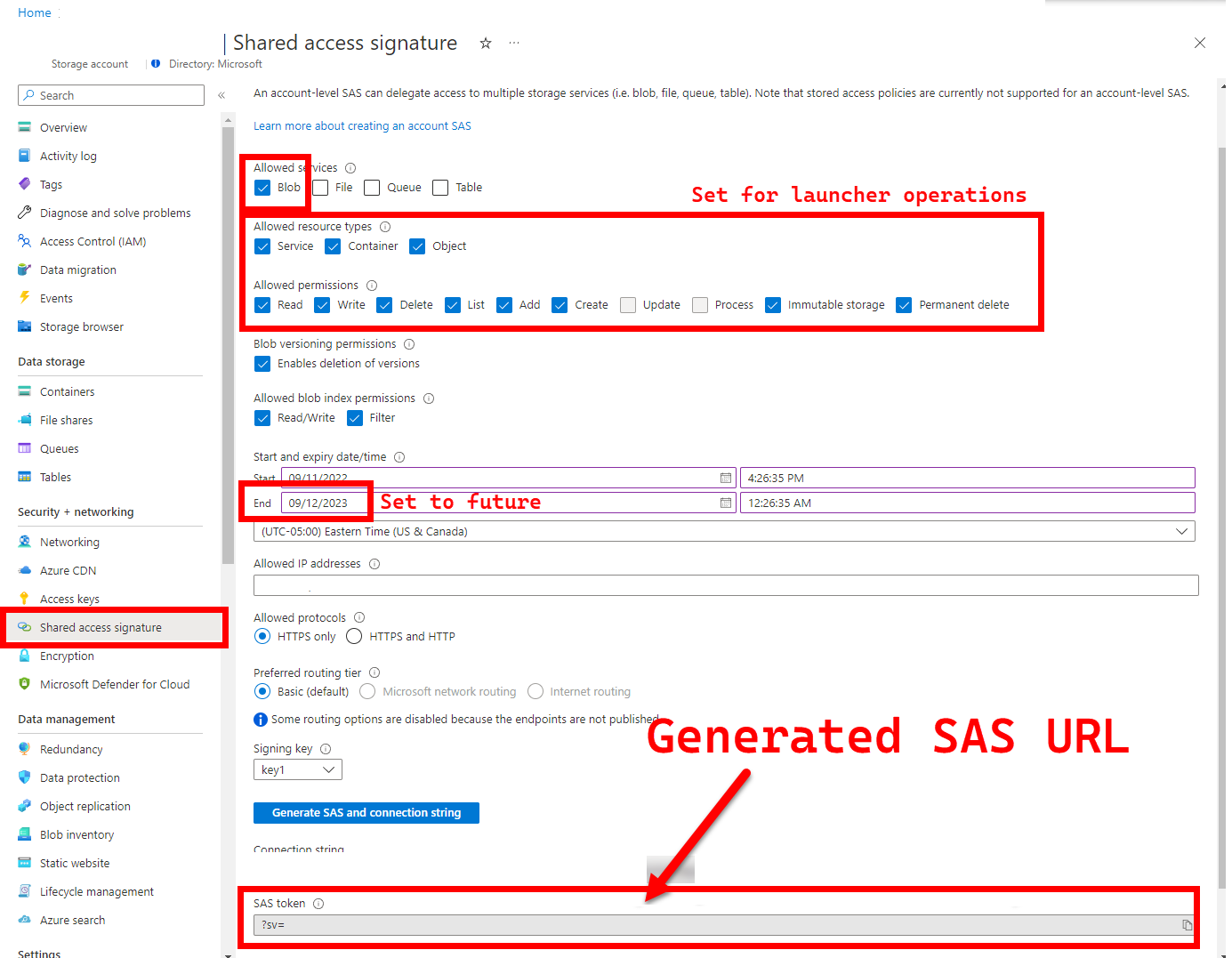
Information om hur du använder Azure CLI i stället finns i az storage account generate-sas
6. SKIP_* – styra startbeteendet genom att hoppa över vissa faser
Valfritt: lämna detta tomt i
.test.envför att köra alla faser (motsvarande0eller tom)
Startprogrammet exponerar SKIP_* variabler för att köra och hoppa över specifika steg , till exempel för att utföra en "endast rensning"-körning.
Även om startprogrammet är utformat för att rensa både i början och slutet av varje körning, är det möjligt för start- och/eller testfel att lämna restresurser bakom sig. Om du vill köra startprogrammet i läget "rensa endast" anger du följande variabler i .test.env:
export SKIP_PRECLEAN="0" # Run cleanup
export SKIP_SETUP="1" # Do not setup Arc-enabled Data Services
export SKIP_TEST="1" # Do not run integration tests
export SKIP_POSTCLEAN="1" # POSTCLEAN is identical to PRECLEAN, although idempotent, not needed here
export SKIP_UPLOAD="1" # Do not upload logs from this run
Inställningarna ovan instruerar startprogrammet att rensa alla Arc- och Arc Data Services-resurser och att inte distribuera/testa/ladda upp loggar.
Konfiguration 2: patch.json
Ett ifyllt exempel på patch.json filen som genereras baserat på patch.json.tmpl delas nedan:
Observera att
spec.docker.registry, repository, imageTagbör vara identiska med värdena i.test.envovan
Färdigt exempel på patch.json:
{
"patch": [
{
"op": "add",
"path": "spec.docker",
"value": {
"registry": "mcr.microsoft.com",
"repository": "arcdata",
"imageTag": "v1.11.0_2022-09-13",
"imagePullPolicy": "Always"
}
},
{
"op": "add",
"path": "spec.storage.data.className",
"value": "default"
},
{
"op": "add",
"path": "spec.storage.logs.className",
"value": "default"
}
]
}
Startdistribution
Vi rekommenderar att du distribuerar startprogrammet i ett icke-produktions-/testkluster eftersom det utför destruktiva åtgärder på Arc och andra använda Kubernetes-resurser.
imageTag specifikation
Startprogrammet definieras i Kubernetes Manifest som ett Job, vilket kräver att du instruerar Kubernetes var startprogrammets avbildning ska hittas. Detta anges i base/kustomization.yaml:
images:
- name: arc-ci-launcher
newName: mcr.microsoft.com/arcdata/arc-ci-launcher
newTag: v1.11.0_2022-09-13
Dricks
För att sammanfatta, vid denna tidpunkt - det finns 3 platser som vi har angett imageTag, för tydlighetens skull, här är en förklaring av de olika användningsområdena för var och en. Vanligtvis – när du testar en viss version är alla 3 värden desamma (justeras till en viss version):
| # | Filnamn | Variabelnamn | Varför? | Används av? |
|---|---|---|---|---|
| 1 | .test.env |
DOCKER_TAG |
Hämta Bootstrapper-avbildningen som en del av tilläggsinstallationen | az k8s-extension create i startprogrammet |
| 2 | patch.json |
value.imageTag |
Källa till datakontrollantens avbildning | az arcdata dc create i startprogrammet |
| 3 | kustomization.yaml |
images.newTag |
Hämta startprogrammets avbildning | kubectl applying av startprogrammet |
kubectl apply
Kontrollera att manifestet har konfigurerats korrekt genom att försöka verifiera på klientsidan med --dry-run=client, som skriver ut kubernetes-resurserna som ska skapas för startprogrammet:
kubectl apply -k arc_data_services/test/launcher/overlays/aks --dry-run=client
# namespace/arc-ci-launcher created (dry run)
# serviceaccount/arc-ci-launcher created (dry run)
# clusterrolebinding.rbac.authorization.k8s.io/arc-ci-launcher created (dry run)
# secret/test-env-fdgfm8gtb5 created (dry run) <- Created from Config 1: `patch.json`
# configmap/control-patch-2hhhgk847m created (dry run) <- Created from Config 2: `.test.env`
# job.batch/arc-ci-launcher created (dry run)
Kör följande för att distribuera start- och tail-loggarna:
kubectl apply -k arc_data_services/test/launcher/overlays/aks
kubectl wait --for=condition=Ready --timeout=360s pod -l job-name=arc-ci-launcher -n arc-ci-launcher
kubectl logs job/arc-ci-launcher -n arc-ci-launcher --follow
I det här läget bör startprogrammet starta – och du bör se följande:
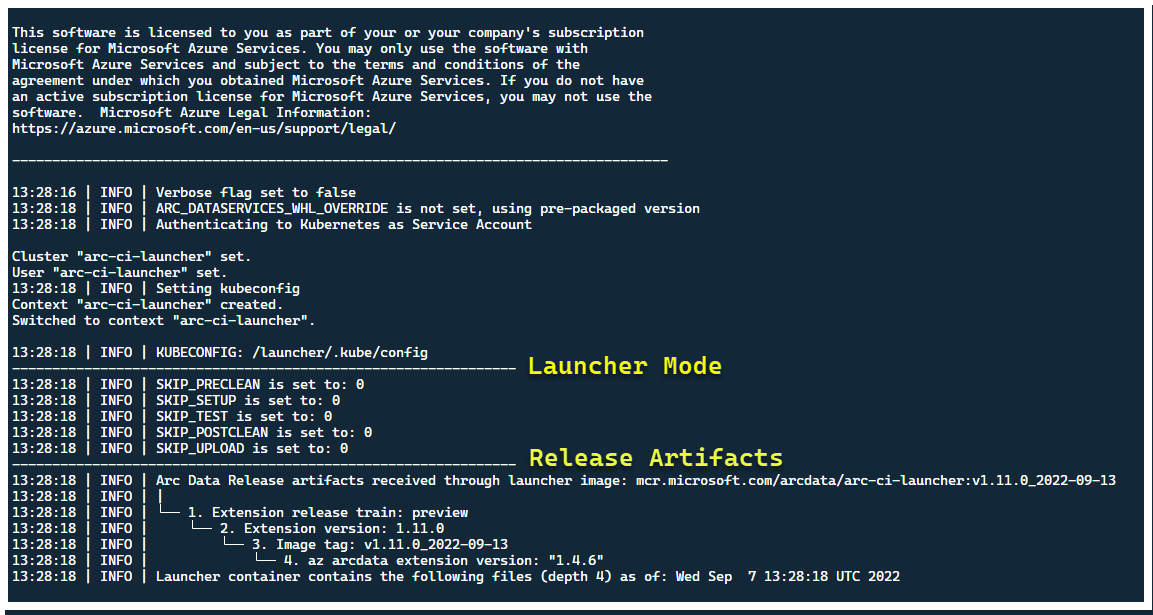
Även om det är bäst att distribuera startprogrammet i ett kluster utan befintliga Arc-resurser, innehåller startprogrammet validering före flygning för att identifiera befintliga Arc- och Arc Data Services CRD och ARM-resurser och försöker rensa dem på bästa sätt (med hjälp av de angivna autentiseringsuppgifterna för tjänstens huvudnamn) innan den nya versionen distribueras:
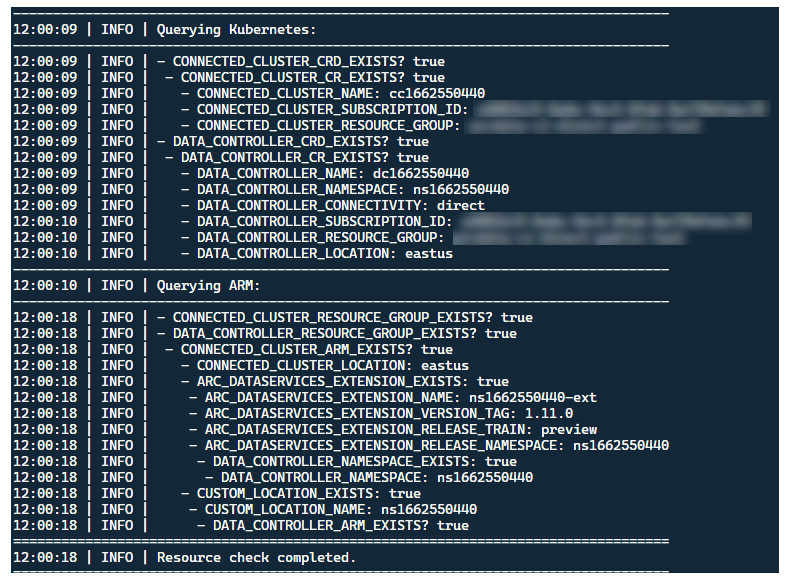
Samma metadataidentifierings- och rensningsprocess körs också när startprogrammet avslutas för att lämna klustret så nära det redan befintliga tillståndet som möjligt före starten.
Steg som utförs av startprogrammet
På hög nivå utför startprogrammet följande stegsekvens:
Autentisera till Kubernetes API med poddmonterat tjänstkonto
Autentisera till ARM API med hemligt monterat tjänsthuvudnamn
Utföra CRD-metadatagenomsökning för att identifiera befintliga anpassade Arc- och Arc Data Services-resurser
Rensa alla befintliga anpassade resurser i Kubernetes och efterföljande resurser i Azure. Om det finns ett matchningsfel mellan autentiseringsuppgifterna i
.test.envjämfört med resurser som finns i klustret avslutar du.Generera en unik uppsättning miljövariabler baserat på tidsstämpel för Arc-klusternamn, datakontrollant och anpassad plats/namnrymd. Skriver ut miljövariablerna och döljer känsliga värden (t.ex. lösenord för tjänstens huvudnamn osv.)
a. För Direktläge – Registrera klustret till Azure Arc distribuerar du sedan kontrollanten.
b. För indirekt läge: distribuera datastyrenheten
När datakontrollanten är
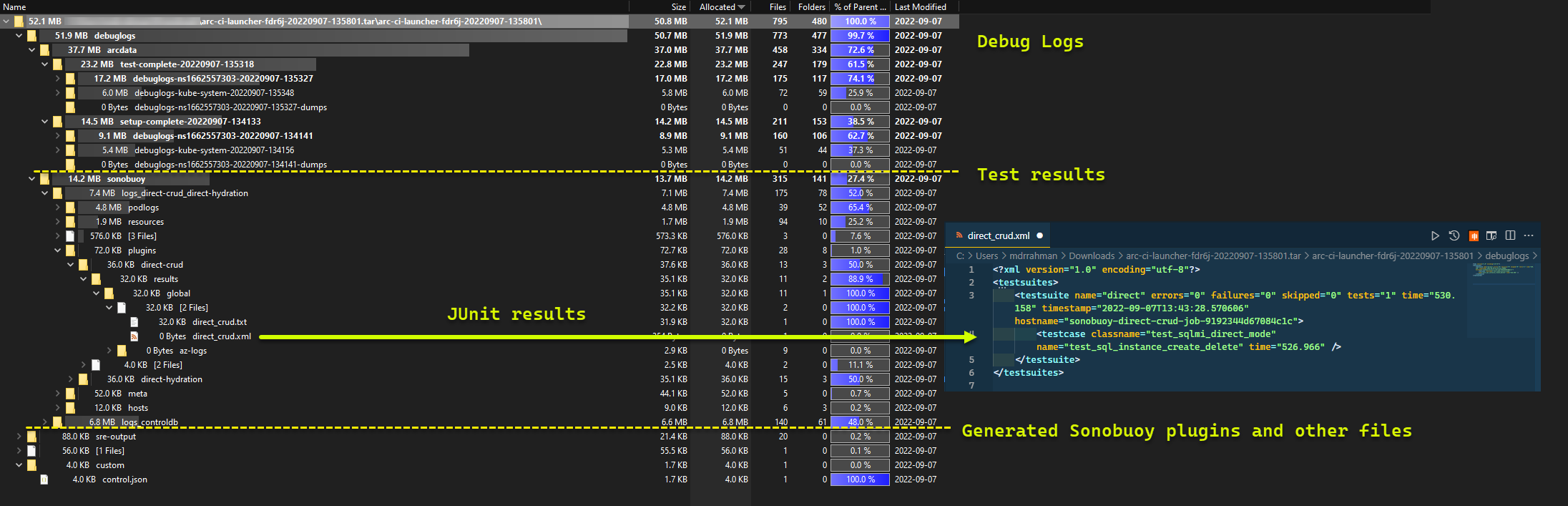
Readygenererar du en uppsättning Azure CLI-loggar (az arcdata dc debug) och lagrar lokalt, märkt somsetup-complete– som en baslinje.TESTS_DIRECT/INDIRECTAnvänd miljövariabeln från.test.envför att starta en uppsättning parallelliserade Sonobuoy-testkörningar baserat på en utrymmesavgränsad matris (TESTS_(IN)DIRECT). Dessa körningar körs i ett nyttsonobuoynamnområde med hjälp avarc-sb-pluginpodden som innehåller Pytest-valideringstesterna.Sonobuoy-aggregatorn ackumulerar testresultaten
junitoch loggarna perarc-sb-plugintestkörning, som exporteras till startpodden.Returnera slutkoden för testerna och genererar en annan uppsättning felsökningsloggar – Azure CLI och
sonobuoy– lagrade lokalt, märkta somtest-complete.Utför en CRD-metadatagenomsökning, liknande steg 3, för att identifiera befintliga anpassade Arc- och Arc Data Services-resurser. Fortsätt sedan med att förstöra alla Arc- och Arc Data-resurser i omvänd ordning från distributionen, samt CRD:er, Roll/KlusterRoller, PV/PVCs osv.
Försök att använda SAS-token
LOGS_STORAGE_ACCOUNT_SASsom tillhandahålls för att skapa en ny container för lagringskonto med namnet baserat påLOGS_STORAGE_CONTAINER, i det befintliga lagringskontotLOGS_STORAGE_ACCOUNT. Om containern för lagringskonto redan finns använder du den. Ladda upp alla lokala testresultat och loggar till den här lagringscontainern som en tarball (se nedan).Utgång.
Tester som utförs per testsvit
Det finns cirka 375 unika integreringstester tillgängliga i 27 testpaket – var och en testar en separat funktion.
| Svit # | Namn på testpaket | Beskrivning av testet |
|---|---|---|
| 1 | ad-connector |
Testar distributionen och uppdateringen av en Active Directory Connector (AD Connector). |
| 2 | billing |
Testning av olika Affärskritisk licenstyper återspeglas i resurstabellen i kontrollanten, som används för faktureringsuppladdning. |
| 3 | ci-billing |
billingLiknar , men med fler processor-/minnespermutationer. |
| 4 | ci-sqlinstance |
Tidskrävande tester för skapande av flera repliker, uppdateringar, GP –> BC Update, validering av säkerhetskopiering och SQL Server-agent. |
| 5 | controldb |
Testkontrolldatabas – SA-hemlig kontroll, verifiering av systeminloggning, skapande av granskning och sanitetskontroller för SQL-versionsversion. |
| 6 | dc-export |
Fakturering och uppladdning av användning i indirekt läge. |
| 7 | direct-crud |
Skapar en SQL-instans med ARM-anrop, validerar i både Kubernetes och ARM. |
| 8 | direct-fog |
Skapar flera SQL-instanser och skapar en redundansgrupp mellan dem med hjälp av ARM-anrop. |
| 9 | direct-hydration |
Skapar SQL-instans med Kubernetes API, validerar närvaro i ARM. |
| 10 | direct-upload |
Validerar faktureringsuppladdning i direktläge |
| 11 | kube-rbac |
Säkerställer att Kubernetes-tjänstkontobehörigheter för Arc Data Services matchar förväntningarna på lägsta privilegier. |
| 12 | nonroot |
Ser till att containrar körs som icke-rotanvändare |
| 13 | postgres |
Slutför olika tester för skapande, skalning, säkerhetskopiering och återställning av Postgres. |
| 14 | release-sanitychecks |
Sanity söker efter versioner från månad till månad, till exempel SQL Server Build-versioner. |
| 15 | sqlinstance |
Kortare version av ci-sqlinstance, för snabb validering. |
| 16 | sqlinstance-ad |
Testar skapandet av SQL-instanser med Active Directory Connector. |
| 17 | sqlinstance-credentialrotation |
Testar automatiserad rotation av autentiseringsuppgifter för både Generell användning och Affärskritisk. |
| 18 | sqlinstance-ha |
Olika stresstester med hög tillgänglighet, inklusive omstarter av poddar, framtvingade redundans och avstängningar. |
| 19 | sqlinstance-tde |
Olika transparent datakryptering tester. |
| 20 | telemetry-elasticsearch |
Validerar logginmatning till Elasticsearch. |
| 21 | telemetry-grafana |
Validerar att Grafana kan nås. |
| 22 | telemetry-influxdb |
Validerar måttinmatning i InfluxDB. |
| 23 | telemetry-kafka |
Olika tester för Kafka med SSL, enkel-/multi-broker-konfiguration. |
| 24 | telemetry-monitorstack |
Testar Övervakningskomponenter, till exempel Fluentbit och Collectd fungerar. |
| 25 | telemetry-telemetryrouter |
Testar Öppna telemetri. |
| 26 | telemetry-webhook |
Testar Data Services Webhooks med giltiga och ogiltiga anrop. |
| 27 | upgrade-arcdata |
Uppgraderar en fullständig uppsättning SQL-instanser (GP, BC 2-replik, BC 3-replik med Active Directory) och uppgraderingar från förra månadens version till den senaste versionen. |
För utförs till exempel sqlinstance-haföljande tester:
test_critical_configmaps_present: Säkerställer att ConfigMaps och relevanta fält finns för en SQL-instans.test_suspended_system_dbs_auto_heal_by_orchestrator: Säkerställer ommasterochmsdbinaktiveras på något sätt (i det här fallet användaren). Orchestrator-underhåll stämma av automatiskt läker det.test_suspended_user_db_does_not_auto_heal_by_orchestrator: Ser till att en användardatabas avsiktligt pausas av användaren, att Orchestrator-underhållsstämmning inte återställer den automatiskt.test_delete_active_orchestrator_twice_and_delete_primary_pod: Tar bort orchestrator-podden flera gånger, följt av den primära repliken, och verifierar att alla repliker synkroniseras. Förväntningarna på redundanstid för 2 repliker är avslappnade.test_delete_primary_pod: Tar bort den primära repliken och verifierar att alla repliker synkroniseras. Förväntningarna på redundanstid för 2 repliker är avslappnade.test_delete_primary_and_orchestrator_pod: Tar bort den primära repliken och orchestrator-podden och verifierar att alla repliker synkroniseras.test_delete_primary_and_controller: Tar bort den primära replik- och datastyrenhetspodden och verifierar att den primära slutpunkten är tillgänglig och att den nya primära repliken synkroniseras. Förväntningarna på redundanstid för 2 repliker är avslappnade.test_delete_one_secondary_pod: Tar bort den sekundära replik- och datastyrenhetspodden och verifierar att alla repliker synkroniseras.test_delete_two_secondaries_pods: Tar bort sekundära repliker och datastyrenhetspodden och verifierar att alla repliker synkroniseras.test_delete_controller_orchestrator_secondary_replica_pods:test_failaway: Tvingar bort tillgänglighetsgruppens redundans från den aktuella primära databasen, vilket säkerställer att den nya primära inte är samma som den gamla primära. Verifierar att alla repliker synkroniseras.test_update_while_rebooting_all_non_primary_replicas: Tester som styrenhetsdrivna uppdateringar är motståndskraftiga med återförsök trots olika turbulenta omständigheter.
Kommentar
Vissa tester kan kräva specifik maskinvara, till exempel privilegierad åtkomst till domänkontrollanter för ad tester för att skapa konto- och DNS-post , vilket kanske inte är tillgängligt i alla miljöer som vill använda arc-ci-launcher.
Undersöka testresultat
En exempellagringscontainer och fil som laddats upp av startprogrammet:
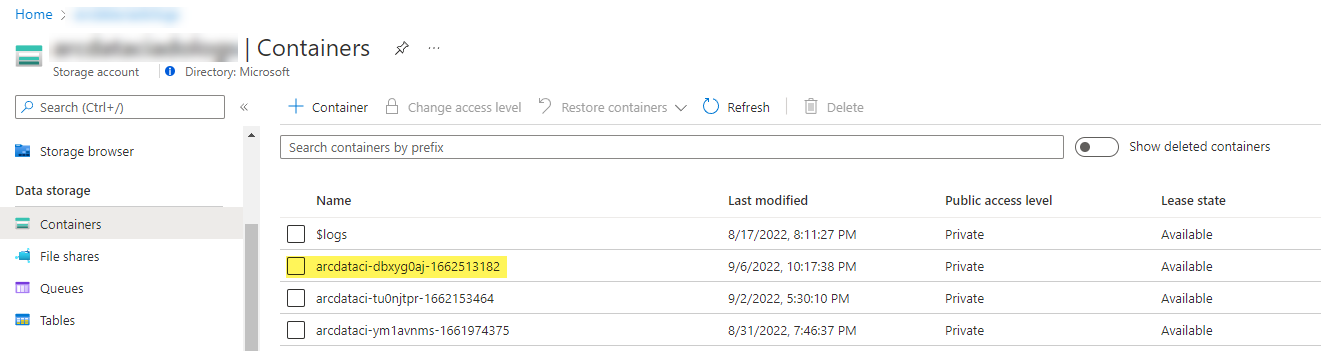
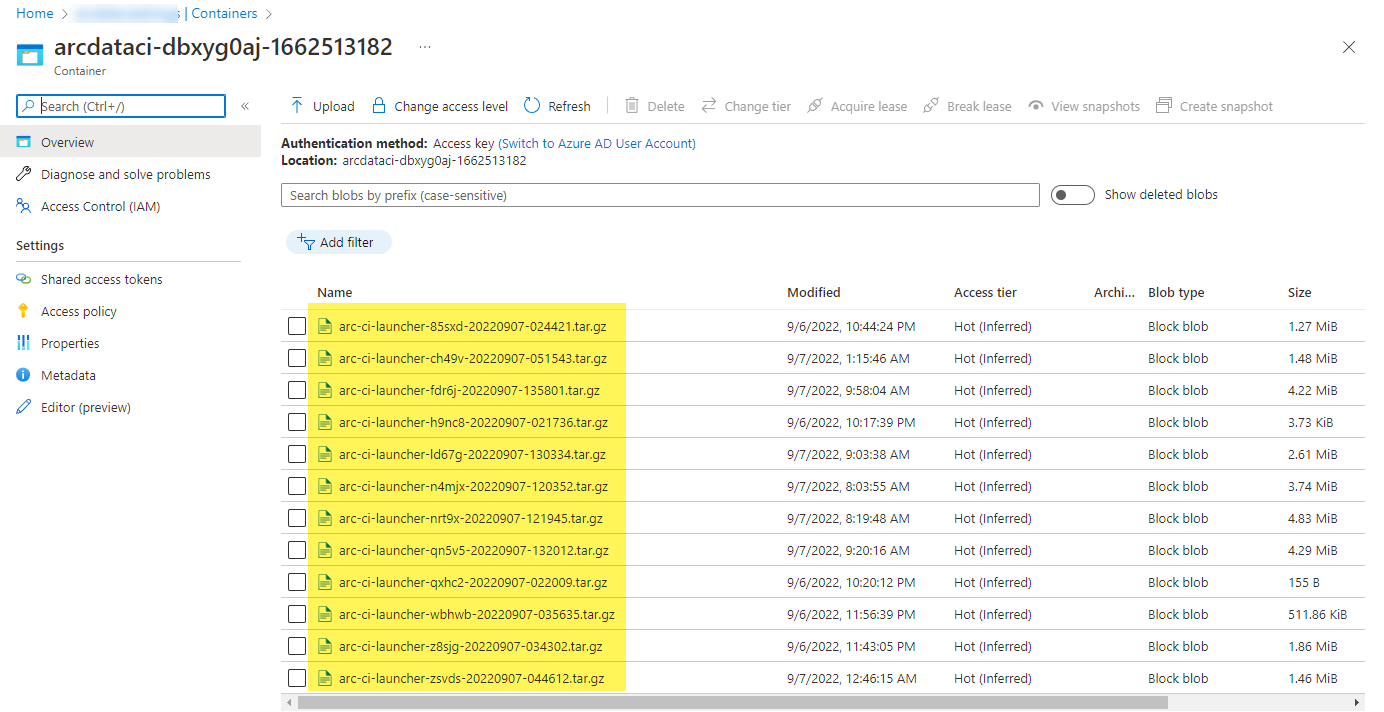
Och testresultaten som genereras från körningen:
Rensa resurser
Om du vill ta bort startprogrammet kör du:
kubectl delete -k arc_data_services/test/launcher/overlays/aks
Detta rensar de resursmanifest som distribueras som en del av startprogrammet.