Lösningsidéer
I den här artikeln beskrivs en lösningsidé. Molnarkitekten kan använda den här vägledningen för att visualisera huvudkomponenterna för en typisk implementering av den här arkitekturen. Använd den här artikeln som utgångspunkt för att utforma en välkonstruerad lösning som överensstämmer med arbetsbelastningens specifika krav.
Det här exemplet handlar om hur du utför inkrementell inläsning i en elt-pipeline (extrahering, inläsning och transformering). Den använder Azure Data Factory för att automatisera ELT-pipelinen. Pipelinen flyttar stegvis de senaste OLTP-data från en lokal SQL Server-databas till Azure Synapse. Transaktionsdata omvandlas till en tabellmodell för analys.
Arkitektur

Ladda ned en Visio-fil med den här arkitekturen.
Den här arkitekturen bygger på den som visas i Enterprise BI med Azure Synapse, men lägger till några funktioner som är viktiga för scenarier för informationslager för företag.
- Automatisering av pipelinen med hjälp av Data Factory.
- Inkrementell inläsning.
- Integrera flera datakällor.
- Läser in binära data som geospatiala data och bilder.
Arbetsflöde
Arkitekturen består av följande tjänster och komponenter.
Datakällor
Lokal SQL Server. Källdata finns i en SQL Server-databas lokalt. Simulera den lokala miljön. Wide World Importers OLTP-exempeldatabasen används som källdatabas.
Externa data. Ett vanligt scenario för informationslager är att integrera flera datakällor. Den här referensarkitekturen läser in en extern datauppsättning som innehåller stadspopulationer per år och integrerar den med data från OLTP-databasen. Du kan använda dessa data för insikter som: "Matchar försäljningstillväxten i varje region eller överskrider befolkningstillväxten?"
Inmatning och datalagring
Blob Storage. Blob Storage används som ett mellanlagringsområde för källdata innan de läses in i Azure Synapse.
Azure Synapse. Azure Synapse är ett distribuerat system som är utformat för att utföra analyser på stora data. Det stöder massiv parallell bearbetning (MPP), som gör det lämpligt för att köra analyser med höga prestanda.
Azure Data Factory. Data Factory är en hanterad tjänst som samordnar och automatiserar dataförflyttning och datatransformering. I den här arkitekturen samordnar den de olika stegen i ELT-processen.
Analys och rapportering
Azure Analysis Services. Analysis Services är en fullständigt hanterad tjänst som tillhandahåller datamodelleringsfunktioner. Den semantiska modellen läses in i Analysis Services.
Power BI. Power BI är en uppsättning affärsanalysverktyg för att analysera data för affärsinsikter. I den här arkitekturen frågar den den semantiska modellen som lagras i Analysis Services.
Autentisering
Microsoft Entra ID autentiserar användare som ansluter till Analysis Services-servern via Power BI.
Data Factory kan också använda Microsoft Entra-ID för att autentisera till Azure Synapse med hjälp av tjänstens huvudnamn eller hanterad tjänstidentitet (MSI).
Komponenter
- Azure Blob Storage
- Azure Synapse Analytics
- Azure Data Factory
- Azure Analysis Services
- Power BI
- Microsoft Entra ID
Information om scenario
Datapipeline
I Azure Data Factory är en pipeline en logisk gruppering av aktiviteter som används för att samordna en uppgift – i det här fallet inläsning och transformering av data till Azure Synapse.
Den här referensarkitekturen definierar en överordnad pipeline som kör en sekvens med underordnade pipelines. Varje underordnad pipeline läser in data i en eller flera informationslagertabeller.
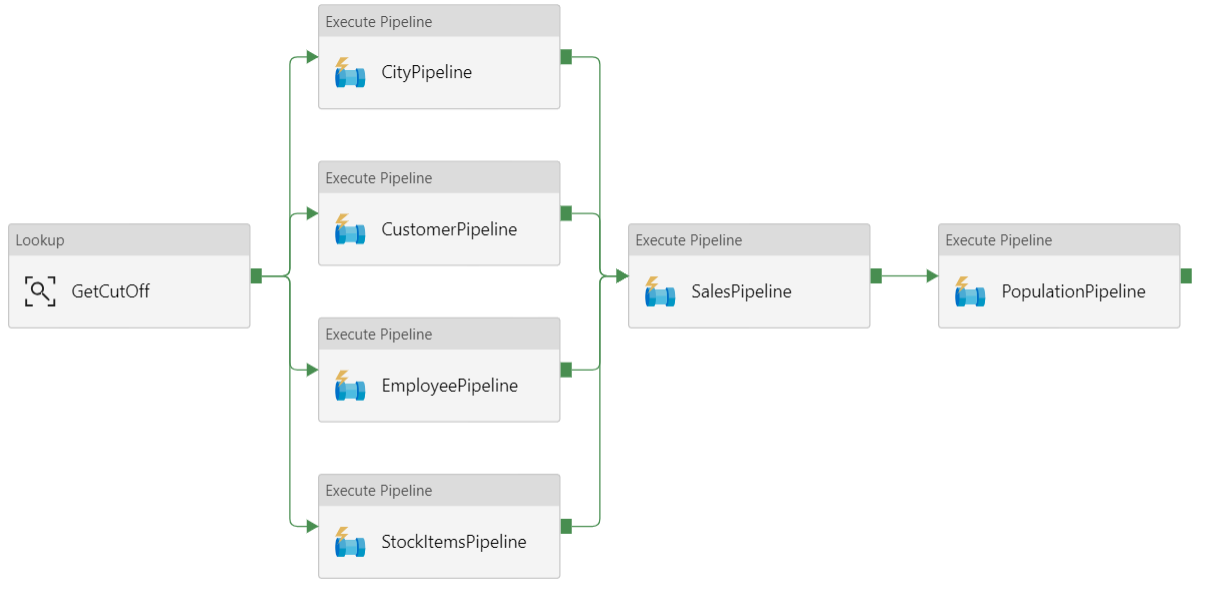
Rekommendationer
Inkrementell inläsning
När du kör en automatiserad ETL- eller ELT-process är det mest effektivt att bara läsa in de data som har ändrats sedan föregående körning. Detta kallas för en inkrementell belastning, till skillnad från en fullständig belastning som läser in alla data. För att utföra en inkrementell belastning behöver du ett sätt att identifiera vilka data som har ändrats. Den vanligaste metoden är att använda ett högt vattenmärkesvärde , vilket innebär att spåra det senaste värdet för en kolumn i källtabellen, antingen en datetime-kolumn eller en unik heltalskolumn.
Från och med SQL Server 2016 kan du använda temporala tabeller. Det här är systemversionstabeller som behåller en fullständig historik över dataändringar. Databasmotorn registrerar automatiskt historiken för varje ändring i en separat historiktabell. Du kan köra frågor mot historiska data genom att lägga till en FOR-SYSTEM_TIME-sats i en fråga. Internt frågar databasmotorn historiktabellen, men det är transparent för programmet.
Kommentar
För tidigare versioner av SQL Server kan du använda Change Data Capture (CDC). Den här metoden är mindre praktisk än tidstabeller eftersom du måste köra frågor mot en separat ändringstabell och ändringar spåras av ett loggsekvensnummer i stället för en tidsstämpel.
Temporala tabeller är användbara för dimensionsdata, som kan ändras över tid. Faktatabeller representerar vanligtvis en oföränderlig transaktion, till exempel en försäljning, i vilket fall det inte är meningsfullt att behålla systemversionshistoriken. I stället har transaktioner vanligtvis en kolumn som representerar transaktionsdatumet, som kan användas som vattenstämpelvärde. I OLTP-databasen Wide World Importers har tabellerna Sales.Invoices och Sales.InvoiceLines till exempel ett LastEditedWhen fält som standardvärdet sysdatetime().
Här är det allmänna flödet för ELT-pipelinen:
För varje tabell i källdatabasen spårar du tidsgränsen när det senaste ELT-jobbet kördes. Lagra den här informationen i informationslagret. (Vid den inledande installationen är alla tider inställda på "1-1-1900".)
Under dataexportsteget skickas tidsgränsen som en parameter till en uppsättning lagrade procedurer i källdatabasen. Dessa lagrade procedurer frågar efter poster som har ändrats eller skapats efter bryttiden. För tabellen
LastEditedWhenSales fact används kolumnen. För dimensionsdata används systemversionsbaserade temporala tabeller.När datamigreringen är klar uppdaterar du tabellen som lagrar bryttiderna.
Det är också användbart att registrera en härstamning för varje ELT-körning. För en viss post associerar ursprunget posten med ELT-körningen som producerade data. För varje ETL-körning skapas en ny ursprungspost för varje tabell som visar start- och slutbelastningstiderna. Ursprungsnycklarna för varje post lagras i dimensions- och faktatabellerna.
När en ny batch med data har lästs in i lagret uppdaterar du Analysis Services-tabellmodellen. Se Asynkron uppdatering med REST-API:et.
Datarensning
Datarensning bör ingå i ELT-processen. I den här referensarkitekturen är en källa till felaktiga data tabellen för stadens befolkning, där vissa städer har noll befolkning, kanske för att inga data var tillgängliga. Under bearbetningen tar ELT-pipelinen bort dessa städer från stadspopulationstabellen. Utför datarensning på mellanlagringstabeller i stället för externa tabeller.
Externa datakällor
Informationslager konsoliderar ofta data från flera källor. Till exempel en extern datakälla som innehåller demografiska data. Den här datamängden är tillgänglig i Azure Blob Storage som en del av Exemplet WorldWideImportersDW .
Azure Data Factory kan kopiera direkt från bloblagring med hjälp av bloblagringsanslutningen. Anslutningsappen kräver dock en anslutningssträng eller en signatur för delad åtkomst, så den kan inte användas för att kopiera en blob med offentlig läsåtkomst. Som en lösning kan du använda PolyBase för att skapa en extern tabell över Blob Storage och sedan kopiera de externa tabellerna till Azure Synapse.
Hantera stora binära data
I källdatabasen har till exempel en stad-tabell en platskolumn som innehåller en geografisk rumslig datatyp. Azure Synapse stöder inte geografitypen internt, så det här fältet konverteras till en varbinär typ under inläsningen. (Se Lösningar för datatyper som inte stöds.)
PolyBase stöder dock en maximal kolumnstorlek på varbinary(8000), vilket innebär att vissa data kan trunkeras. En lösning på det här problemet är att dela upp data i segment under exporten och sedan sätta ihop segmenten igen på följande sätt:
Skapa en tillfällig mellanlagringstabell för kolumnen Plats.
För varje stad delar du upp platsdata i segment på 8 000 byte, vilket resulterar i 1 – N rader för varje stad.
Om du vill sätta ihop segmenten igen använder du T-SQL PIVOT-operatorn för att konvertera rader till kolumner och sammanfogar sedan kolumnvärdena för varje stad.
Utmaningen är att varje stad delas upp i ett annat antal rader, beroende på storleken på geografidata. För att PIVOT-operatorn ska fungera måste varje stad ha samma antal rader. För att det här ska fungera gör T-SQL-frågan några knep för att fylla ut raderna med tomma värden, så att varje stad har samma antal kolumner efter pivoten. Den resulterande frågan visar sig vara mycket snabbare än att loopa igenom raderna en i taget.
Samma metod används för bilddata.
Långsamt föränderliga dimensioner
Dimensionsdata är relativt statiska, men de kan ändras. En produkt kan till exempel tilldelas om till en annan produktkategori. Det finns flera sätt att hantera långsamt föränderliga dimensioner. En vanlig teknik, som kallas typ 2, är att lägga till en ny post när en dimension ändras.
För att implementera metoden Typ 2 behöver dimensionstabeller ytterligare kolumner som anger det gällande datumintervallet för en viss post. Dessutom dupliceras primära nycklar från källdatabasen, så dimensionstabellen måste ha en artificiell primärnyckel.
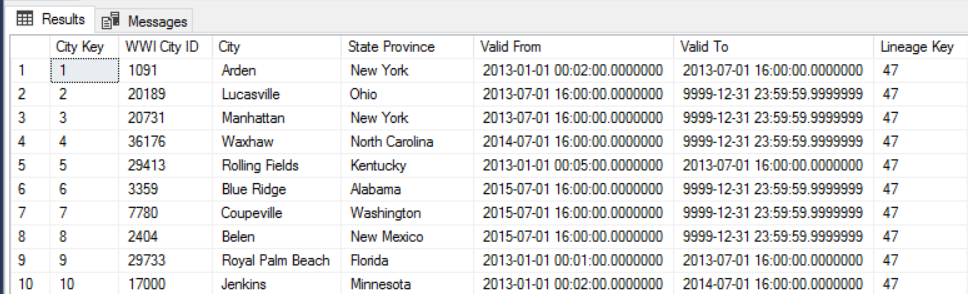
Följande bild visar till exempel tabellen Dimension.City. Kolumnen WWI City ID är den primära nyckeln från källdatabasen. Kolumnen City Key är en artificiell nyckel som genereras under ETL-pipelinen. Observera också att tabellen har Valid From och Valid To kolumner, som definierar intervallet när varje rad var giltig. Aktuella värden är lika med Valid To "9999-12-31".
Fördelen med den här metoden är att den bevarar historiska data, vilket kan vara värdefullt för analys. Men det innebär också att det kommer att finnas flera rader för samma entitet. Här är till exempel de poster som matchar WWI City ID = 28561:
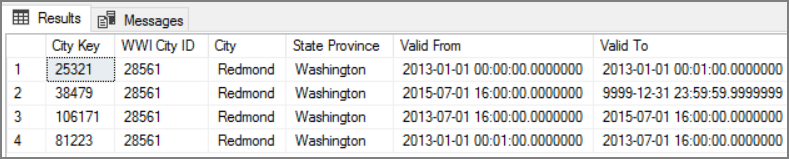
För varje försäljningsfakta vill du associera det med en enskild rad i tabellen City-dimension, motsvarande fakturadatumet.
Att tänka på
Dessa överväganden implementerar grundpelarna i Azure Well-Architected Framework, som är en uppsättning vägledande grundsatser som kan användas för att förbättra kvaliteten på en arbetsbelastning. Mer information finns i Microsoft Azure Well-Architected Framework.
Säkerhet
Säkerhet ger garantier mot avsiktliga attacker och missbruk av dina värdefulla data och system. Mer information finns i checklistan för Designgranskning för Security.
För ytterligare säkerhet kan du använda tjänstslutpunkter för virtuellt nätverk för att skydda Azure-tjänstresurser till endast ditt virtuella nätverk. Detta tar helt bort offentlig Internetåtkomst till dessa resurser, vilket endast tillåter trafik från ditt virtuella nätverk.
Med den här metoden skapar du ett virtuellt nätverk i Azure och skapar sedan privata tjänstslutpunkter för Azure-tjänster. Dessa tjänster begränsas sedan till trafik från det virtuella nätverket. Du kan också nå dem från ditt lokala nätverk via en gateway.
Tänk på följande begränsningar:
Om tjänstslutpunkter är aktiverade för Azure Storage kan PolyBase inte kopiera data från Storage till Azure Synapse. Det finns en åtgärd för det här problemet. Mer information finns i Effekten av att använda VNet-tjänstslutpunkter med Azure Storage.
Om du vill flytta data från en lokal plats till Azure Storage måste du tillåta offentliga IP-adresser från din lokala adress eller ExpressRoute. Mer information finns i Skydda Azure-tjänster till virtuella nätverk.
Om du vill göra det möjligt för Analysis Services att läsa data från Azure Synapse distribuerar du en virtuell Windows-dator till det virtuella nätverk som innehåller Azure Synapse-tjänstslutpunkten. Installera Azure On-premises Data Gateway på den här virtuella datorn. Anslut sedan Azure Analysis-tjänsten till datagatewayen.
Kostnadsoptimering
Kostnadsoptimering handlar om att titta på sätt att minska onödiga utgifter och förbättra drifteffektiviteten. Mer information finns i checklistan Designgranskning för kostnadsoptimering.
Normalt beräknar du kostnader med hjälp av priskalkylatorn för Azure. Här följer några överväganden för tjänster som används i den här referensarkitekturen.
Azure Data Factory
Azure Data Factory automatiserar ELT-pipelinen. Pipelinen flyttar data från en lokal SQL Server-databas till Azure Synapse. Data omvandlas sedan till en tabellmodell för analys. I det här scenariot börjar prissättningen från aktivitetskörningar på 0,001 USD per månad som innehåller aktivitets-, utlösar- och felsökningskörningar. Det priset är endast basavgiften för orkestrering. Du debiteras också för körningsaktiviteter, till exempel kopiering av data, sökningar och externa aktiviteter. Varje aktivitet prissätts individuellt. Du debiteras också för pipelines utan associerade utlösare eller körningar inom månaden. Alla aktiviteter beräknas per minut och avrundas uppåt.
Exempel på kostnadsanalys
Tänk dig ett användningsfall där det finns två uppslagsaktiviteter från två olika källor. En tar 1 minut och 2 sekunder (avrundad upp till 2 minuter) och den andra tar 1 minut vilket resulterar i total tid på 3 minuter. En datakopieringsaktivitet tar 10 minuter. En lagrad proceduraktivitet tar 2 minuter. Totalt antal aktivitetskörningar i 4 minuter. Kostnaden beräknas på följande sätt:
Aktivitetskörningar: 4 * $ 0,001 = $0,004
Uppslag: 3 * ($0.005 / 60) = $0.00025
Lagrad procedur: 2 * ($0.00025 / 60) = $0.000008
Datakopiering: 10 * ($0.25 / 60) * 4 dataintegreringsenhet (DIU) = $0.167
- Total kostnad per pipelinekörning: 0,17 USD.
- Kör en gång per dag i 30 dagar: 5,1 USD i månaden.
- Kör en gång per dag per 100 tabeller i 30 dagar: $ 510
Varje aktivitet har en associerad kostnad. Förstå prismodellen och använd priskalkylatorn för ADF för att få en lösning optimerad inte bara för prestanda utan även för kostnader. Hantera dina kostnader genom att starta, stoppa, pausa och skala dina tjänster.
Azure Synapse
Azure Synapse är perfekt för intensiva arbetsbelastningar med högre frågeprestanda och beräkningsskalbarhetsbehov. Du kan välja modellen betala per användning eller använda reserverade planer på ett år (37 % besparingar) eller 3 år (65 % besparingar).
Datalagring debiteras separat. Andra tjänster som haveriberedskap och hotidentifiering debiteras också separat.
Mer information finns i Prissättning för Azure Synapse.
Analysis Services
Prissättningen för Azure Analysis Services beror på nivån. Referensimplementeringen av den här arkitekturen använder nivån Utvecklare , vilket rekommenderas för utvärderings-, utvecklings- och testscenarier. Andra nivåer är Basic-nivån , som rekommenderas för liten produktionsmiljö, standardnivån för verksamhetskritiska produktionsprogram. Mer information finns i Rätt nivå när du behöver den.
Inga avgifter tillkommer när du pausar instansen.
Mer information finns i Prissättning för Azure Analysis Services.
Blob Storage
Överväg att använda funktionen reserverad kapacitet i Azure Storage för att sänka kostnaden för lagring. Med den här modellen får du rabatt om du kan checka in på reservationen för fast lagringskapacitet i ett eller tre år. Mer information finns i Optimera kostnader för Blob Storage med reserverad kapacitet.
Mer information finns i avsnittet Kostnad i Microsoft Azure Well-Architected Framework.
Operational Excellence
Operational Excellence omfattar de driftsprocesser som distribuerar ett program och håller det igång i produktion. Mer information finns i checklistan för Designgranskning för Operational Excellence.
Skapa separata resursgrupper för produktions-, utvecklings- och testmiljöer. Med separata resursgrupper blir det enklare att hantera distributioner, ta bort testdistributioner och tilldela åtkomsträttigheter.
Placera varje arbetsbelastning i en separat distributionsmall och lagra resurserna i källkontrollsystemen. Du kan distribuera mallarna tillsammans eller individuellt som en del av en CI/CD-process, vilket gör automatiseringsprocessen enklare.
I den här arkitekturen finns det tre huvudsakliga arbetsbelastningar:
- Informationslagerservern, Analysis Services och relaterade resurser.
- Azure Data Factory.
- Ett simulerat scenario lokalt till molnet.
Varje arbetsbelastning har en egen distributionsmall.
Datalagerservern konfigureras med hjälp av Azure CLI-kommandon som följer den imperativa metoden i IaC-metoden. Överväg att använda distributionsskript och integrera dem i automatiseringsprocessen.
Överväg att mellanlagring av dina arbetsbelastningar. Distribuera till olika steg och kör valideringskontroller i varje steg innan du går vidare till nästa steg. På så sätt kan du push-överföra uppdateringar till dina produktionsmiljöer på ett mycket kontrollerat sätt och minimera oväntade distributionsproblem. Använd strategier för blågrön distribution och canary-versioner för att uppdatera liveproduktionsmiljöer.
Ha en bra återställningsstrategi för hantering av misslyckade distributioner. Du kan till exempel automatiskt distribuera om en tidigare lyckad distribution från distributionshistoriken. Se flaggan --rollback-on-error i Azure CLI.
Azure Monitor är det rekommenderade alternativet för att analysera prestanda för ditt informationslager och hela Azure Analytics-plattformen för en integrerad övervakningsupplevelse. Azure Synapse Analytics tillhandahåller en övervakningsupplevelse inom Azure Portal för att visa insikter om din arbetsbelastning i informationslagret. Azure Portal är det rekommenderade verktyget när du övervakar informationslagret eftersom det ger konfigurerbara kvarhållningsperioder, aviseringar, rekommendationer och anpassningsbara diagram och instrumentpaneler för mått och loggar.
Nästa steg
- Introduktion till Azure Synapse Analytics
- Komma igång med Azure Synapse Analytics
- Introduktion till Azure Data Factory
- Vad är Azure Data Factory?
- Självstudier om Azure Data Factory
Relaterade resurser
Du kanske vill granska följande Azure-exempelscenarier som demonstrerar specifika lösningar med hjälp av några av samma tekniker: