Den här artikeln beskriver hur ett utvecklingsteam använde mått för att hitta flaskhalsar och förbättra prestandan för ett distribuerat system. Artikeln baseras på faktisk belastningstestning som utfördes för ett exempelprogram. Programmet kommer från Azure Kubernetes Service-baslinjen (AKS) för mikrotjänster, tillsammans med ett Visual Studio-belastningstestprojekt som används för att generera resultaten.
Den här artikeln ingår i en serie. Läs den första delen här.
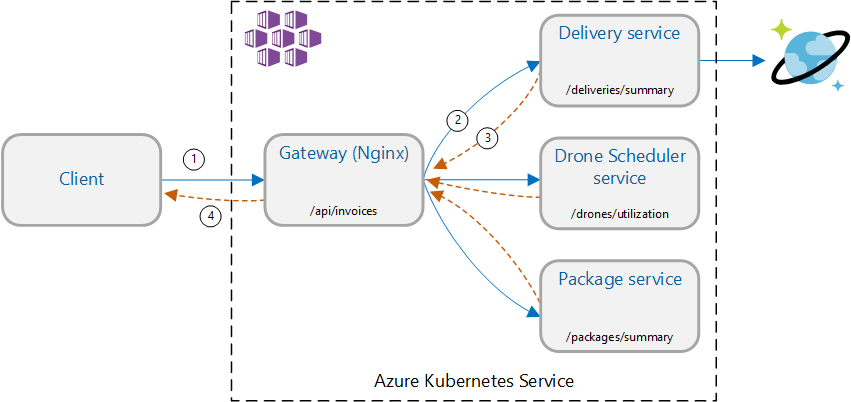
Scenario: Anropa flera serverdelstjänster för att hämta information och aggregera sedan resultaten.
Det här scenariot omfattar ett drönarleveransprogram. Klienter kan fråga ett REST-API för att hämta den senaste fakturainformationen. Fakturan innehåller en sammanfattning av kundens leveranser, paket och totala drönaranvändning. Det här programmet använder en mikrotjänstarkitektur som körs på AKS och den information som behövs för fakturan sprids över flera mikrotjänster.
I stället för att klienten anropar varje tjänst direkt implementerar programmet mönstret Gateway-sammansättning . Med det här mönstret gör klienten en enda begäran till en gatewaytjänst. Gatewayen anropar i sin tur serverdelstjänsterna parallellt och aggregerar sedan resultatet till en enda svarsnyttolast.
Test 1: Baslinjeprestanda
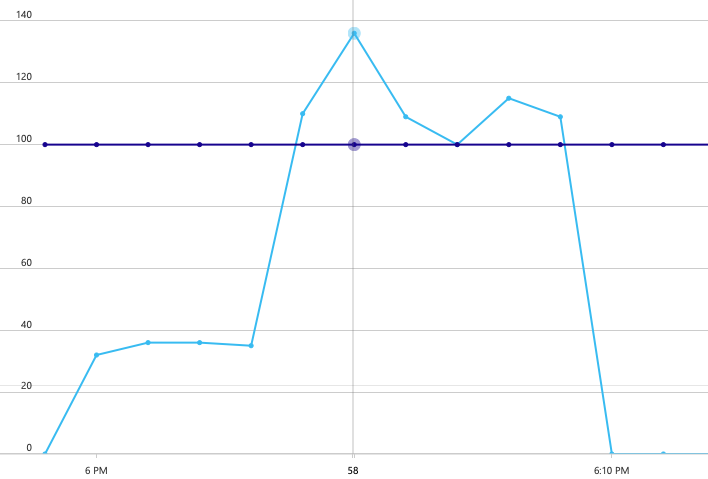
För att upprätta en baslinje började utvecklingsteamet med ett steg-belastningstest, vilket ökade belastningen från en simulerad användare upp till 40 användare, under en total varaktighet på 8 minuter. Följande diagram, hämtat från Visual Studio, visar resultatet. Den lila linjen visar användarbelastningen och den orange linjen visar dataflöde (genomsnittliga begäranden per sekund).
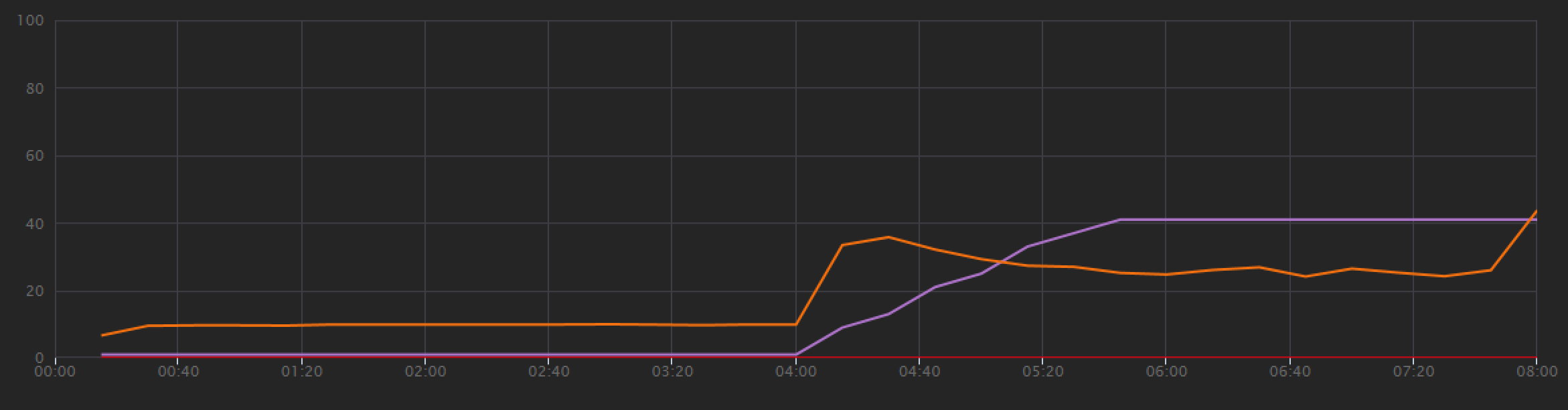
Den röda linjen längst ned i diagrammet visar att inga fel returnerades till klienten, vilket är uppmuntrande. Det genomsnittliga dataflödet toppar dock ungefär halvvägs genom testet och sjunker sedan för resten, även om belastningen fortsätter att öka. Det indikerar att serverdelen inte kan hänga med. Mönstret som visas här är vanligt när ett system börjar nå resursgränser – efter att ha nått ett maximalt dataflöde minskar faktiskt avsevärt. Resurskonkurration, tillfälliga fel eller en ökning av undantagsfrekvensen kan alla bidra till det här mönstret.
Nu ska vi gå igenom övervakningsdata för att lära oss vad som händer i systemet. Nästa diagram hämtas från Application Insights. Den visar den genomsnittliga varaktigheten för HTTP-anropen från gatewayen till serverdelstjänsterna.
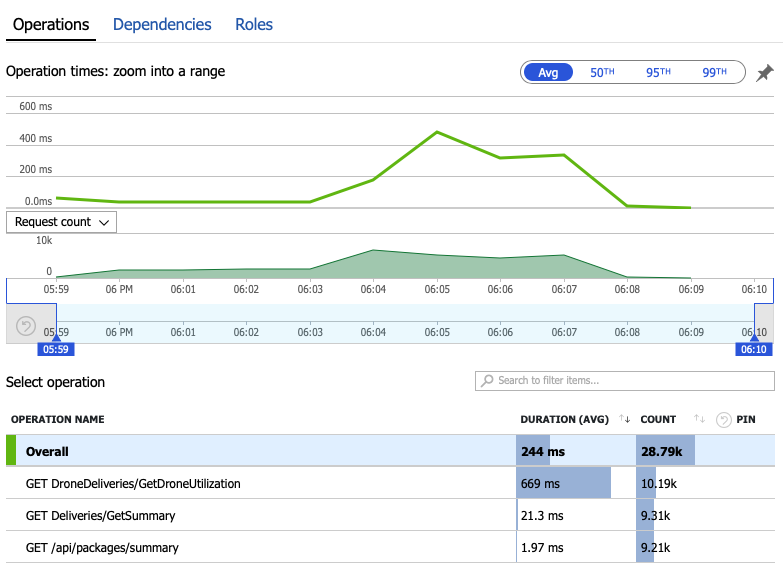
Det här diagrammet visar att en åtgärd i synnerhet , GetDroneUtilizationtar mycket längre tid i genomsnitt – i storleksordning. Gatewayen gör dessa anrop parallellt, så den långsammaste åtgärden avgör hur lång tid det tar för hela begäran att slutföras.
Det är tydligt att nästa steg är att gräva i GetDroneUtilization åtgärden och leta efter flaskhalsar. En möjlighet är resursöverbelastning. Kanske börjar just den här serverdelstjänsten få slut på processor eller minne. För ett AKS-kluster är den här informationen tillgänglig i Azure Portal via azure monitor-containerinsiktsfunktionen. Följande diagram visar resursutnyttjande på klusternivå:
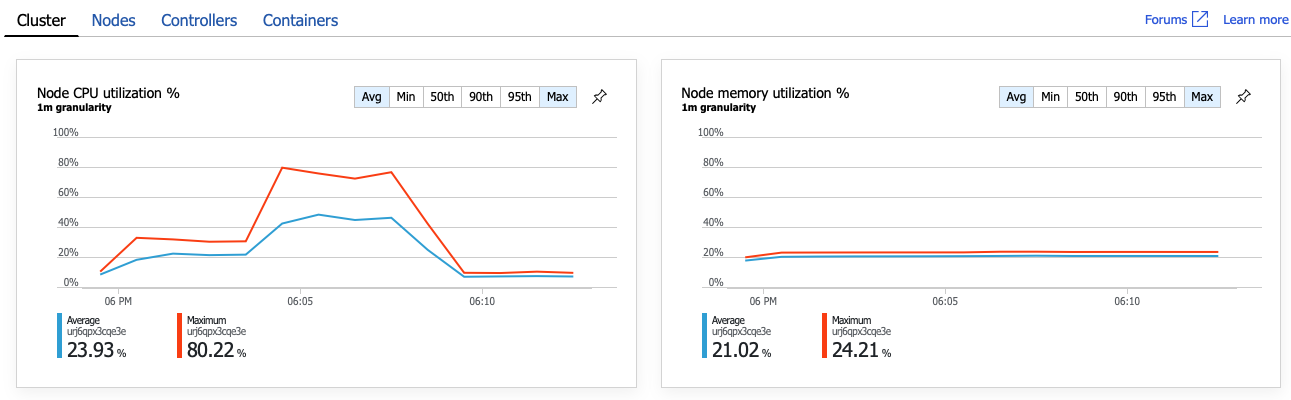
I den här skärmbilden visas både medelvärdet och maxvärdena. Det är viktigt att titta på mer än bara genomsnittet, eftersom genomsnittet kan dölja toppar i data. Här ligger den genomsnittliga CPU-användningen under 50 %, men det finns ett par toppar på 80 %. Det är nära kapaciteten men fortfarande inom toleranser. Något annat orsakar flaskhalsen.
Nästa diagram visar den sanna boven. Det här diagrammet visar HTTP-svarskoder från leveranstjänstens serverdelsdatabas, som i det här fallet är Azure Cosmos DB. Den blå linjen representerar framgångskoder (HTTP 2xx), medan den gröna linjen representerar HTTP 429-fel. En HTTP 429-returkod innebär att Azure Cosmos DB tillfälligt begränsar begäranden, eftersom anroparen förbrukar fler resursenheter (RU) än vad som har etablerats.
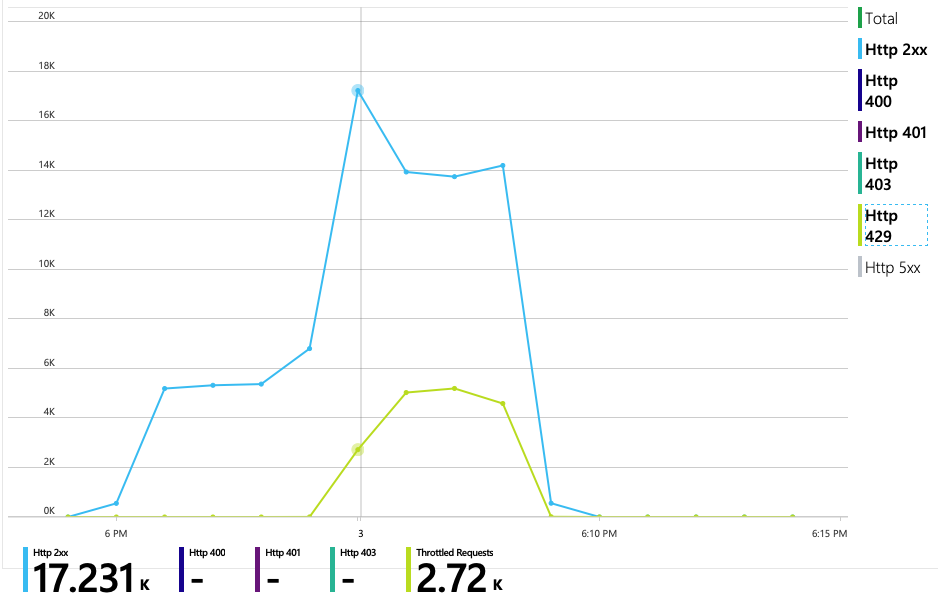
För att få ytterligare insikter använde utvecklingsteamet Application Insights för att visa telemetri från slutpunkt till slutpunkt för ett representativt urval av begäranden. Här är en instans:

Den här vyn visar anrop som är relaterade till en enskild klientbegäran, tillsammans med tidsinformation och svarskoder. Toppnivåanropen kommer från gatewayen till serverdelstjänsterna. Anropet till GetDroneUtilization expanderas för att visa anrop till externa beroenden – i det här fallet till Azure Cosmos DB. Anropet i rött returnerade ett HTTP 429-fel.
Observera det stora gapet mellan HTTP 429-felet och nästa anrop. När Azure Cosmos DB-klientbiblioteket får ett HTTP 429-fel säkerhetskopieras det automatiskt och väntar på att försöka utföra åtgärden igen. Vad den här vyn visar är att under de 672 ms som den här åtgärden tog ägnades större delen av den tiden åt att vänta på att försöka igen i Azure Cosmos DB.
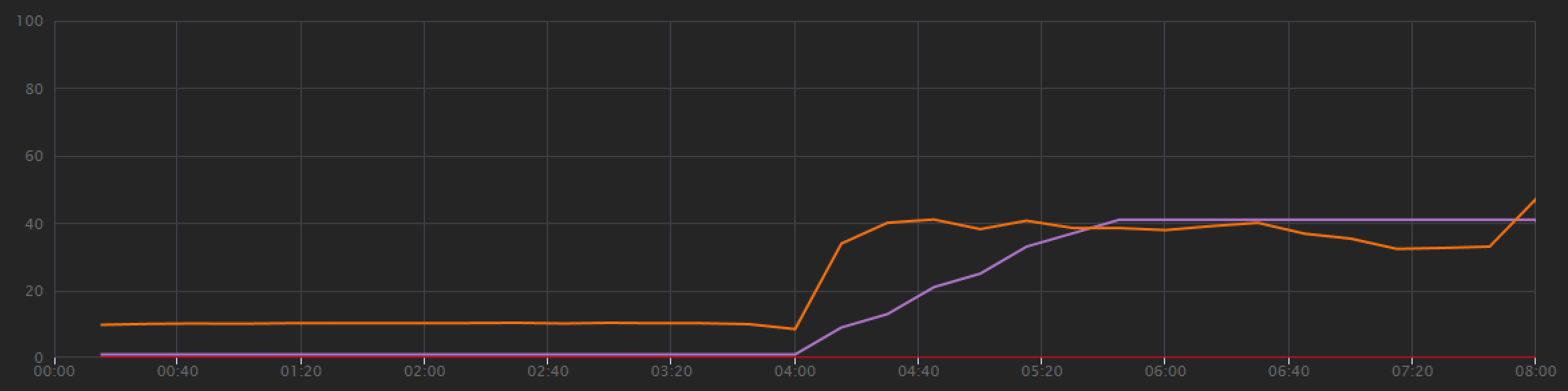
Här är ett annat intressant diagram för den här analysen. Den visar RU-förbrukning per fysisk partition jämfört med etablerade RU:er per fysisk partition:
För att förstå det här diagrammet måste du förstå hur Azure Cosmos DB hanterar partitioner. Samlingar i Azure Cosmos DB kan ha en partitionsnyckel. Varje möjligt nyckelvärde definierar en logisk partition av data i samlingen. Azure Cosmos DB distribuerar dessa logiska partitioner över en eller flera fysiska partitioner. Hanteringen av fysiska partitioner hanteras automatiskt av Azure Cosmos DB. När du lagrar mer data kan Azure Cosmos DB flytta logiska partitioner till nya fysiska partitioner för att sprida belastningen över de fysiska partitionerna.
För det här belastningstestet etablerades Azure Cosmos DB-samlingen med 900 RU:er. Diagrammet visar 100 RU per fysisk partition, vilket innebär totalt nio fysiska partitioner. Även om Azure Cosmos DB automatiskt hanterar horisontell partitionering av fysiska partitioner, kan det ge insikt i prestanda med vetskapen om antalet partitioner. Utvecklingsteamet kommer att använda den här informationen senare när de fortsätter att optimera. Om den blå linjen korsar den lila vågräta linjen har RU-förbrukningen överskridit de etablerade RU:erna. Det är den punkt där Azure Cosmos DB börjar begränsa anrop.
Test 2: Öka resursenheter
För det andra belastningstestet skalade teamet ut Azure Cosmos DB-samlingen från 900 RU till 2 500 RU. Dataflödet ökade från 19 begäranden/sekund till 23 begäranden/sekund och den genomsnittliga svarstiden minskade från 669 ms till 569 ms.
| Metric | Test 1 | Test 2 |
|---|---|---|
| Dataflöde (req/s) | 19 | 23 |
| Genomsnittlig svarstid (ms) | 669 | 569 |
| Lyckade begäranden | 9,8 K | 11 K |
Det här är inte stora vinster, men om du tittar på diagrammet över tid visas en mer fullständig bild:
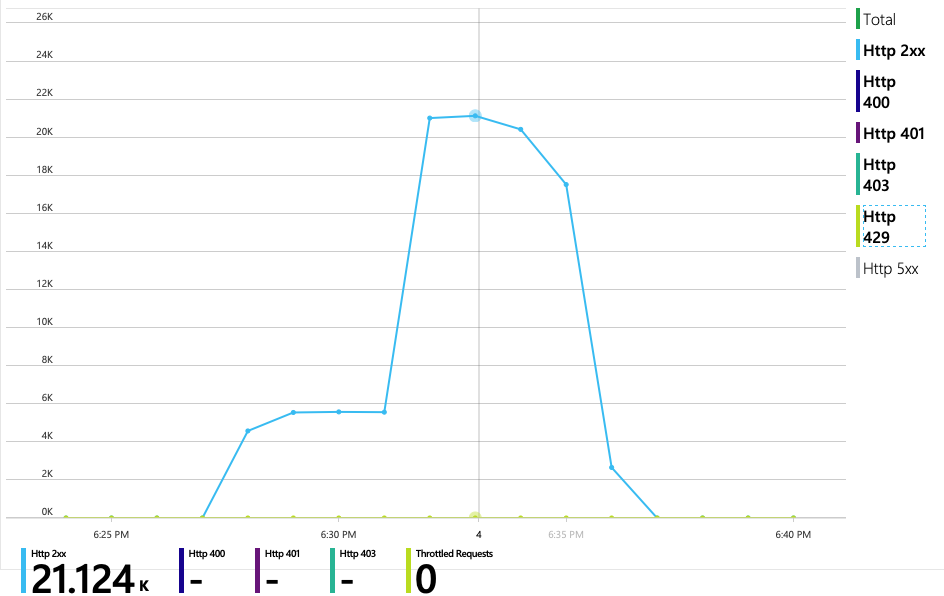
Medan det föregående testet visade en inledande topp följt av en kraftig minskning, visar det här testet mer konsekvent dataflöde. Det maximala dataflödet är dock inte betydligt högre.
Alla begäranden till Azure Cosmos DB returnerade en 2xx-status och HTTP 429-felen försvann:
Diagrammet över RU-förbrukning jämfört med etablerade RU:er visar att det finns gott om utrymme. Det finns cirka 275 RU:er per fysisk partition och belastningstestet nådde en topp på cirka 100 RU:er per sekund.
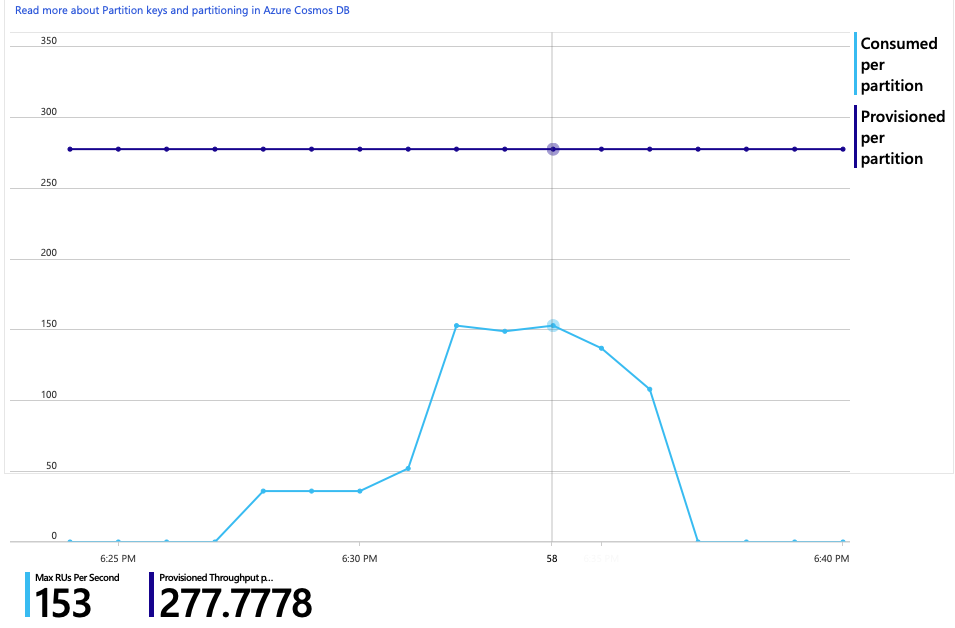
Ett annat intressant mått är antalet anrop till Azure Cosmos DB per lyckad åtgärd:
| Metric | Test 1 | Test 2 |
|---|---|---|
| Anrop per åtgärd | 11 | 9 |
Om det inte finns några fel ska antalet anrop matcha den faktiska frågeplanen. I det här fallet omfattar åtgärden en fråga mellan partitioner som träffar alla nio fysiska partitioner. Det högre värdet i det första belastningstestet återspeglar antalet anrop som returnerade ett 429-fel.
Det här måttet beräknades genom att köra en anpassad Log Analytics-fråga:
let start=datetime("2020-06-18T20:59:00.000Z");
let end=datetime("2020-07-24T21:10:00.000Z");
let operationNameToEval="GET DroneDeliveries/GetDroneUtilization";
let dependencyType="Azure DocumentDB";
let dataset=requests
| where timestamp > start and timestamp < end
| where success == true
| where name == operationNameToEval;
dataset
| project reqOk=itemCount
| summarize
SuccessRequests=sum(reqOk),
TotalNumberOfDepCalls=(toscalar(dependencies
| where timestamp > start and timestamp < end
| where type == dependencyType
| summarize sum(itemCount)))
| project
OperationName=operationNameToEval,
DependencyName=dependencyType,
SuccessRequests,
AverageNumberOfDepCallsPerOperation=(TotalNumberOfDepCalls/SuccessRequests)
Sammanfattnings är att det andra belastningstestet visar förbättring. Åtgärden tar dock GetDroneUtilization fortfarande ungefär en storleksordning längre än den näst långsammaste åtgärden. Om du tittar på transaktionerna från slutpunkt till slutpunkt kan du förklara varför:
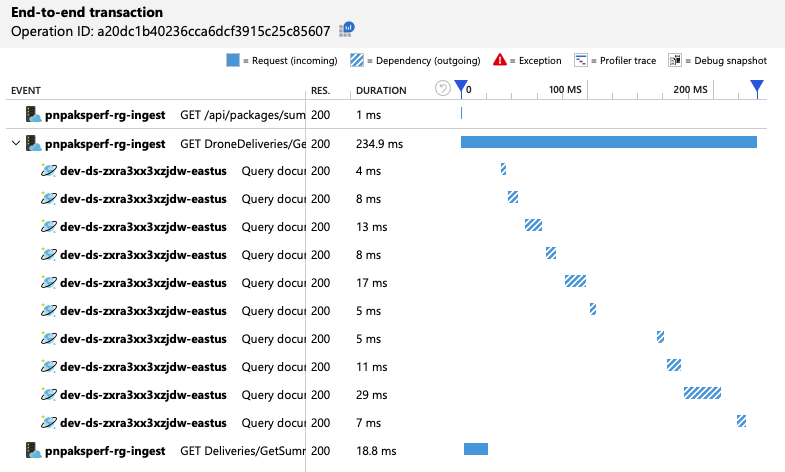
Som tidigare nämnts omfattar åtgärden GetDroneUtilization en fråga mellan partitioner till Azure Cosmos DB. Det innebär att Azure Cosmos DB-klienten måste förgrena frågan till varje fysisk partition och samla in resultaten. Som transaktionsvyn från slutpunkt till slutpunkt visar utförs dessa frågor i seriellt läge. Åtgärden tar så lång tid som summan av alla frågor – och det här problemet blir bara värre när datastorleken växer och fler fysiska partitioner läggs till.
Test 3: Parallella frågor
Baserat på föregående resultat är ett uppenbart sätt att minska svarstiden att köra frågor parallellt. Azure Cosmos DB-klient-SDK:et har en inställning som styr den maximala graden av parallellitet.
| Värde | Beskrivning |
|---|---|
| 0 | Ingen parallellitet (standard) |
| > 0 | Maximalt antal parallella anrop |
| -1 | Klient-SDK:et väljer en optimal grad av parallellitet |
För det tredje belastningstestet ändrades den här inställningen från 0 till -1. I följande tabell sammanfattas resultatet:
| Metric | Test 1 | Test 2 | Test 3 |
|---|---|---|---|
| Dataflöde (req/sek) | 19 | 23 | 42 |
| Genomsnittlig svarstid (ms) | 669 | 569 | 215 |
| Lyckade begäranden | 9,8 K | 11 K | 20 K |
| Begränsade begäranden | 2,72 K | 0 | 0 |
Från belastningstestdiagrammet är det övergripande dataflödet inte bara mycket högre (den orange linjen), utan dataflödet håller också jämna steg med belastningen (den lila linjen).
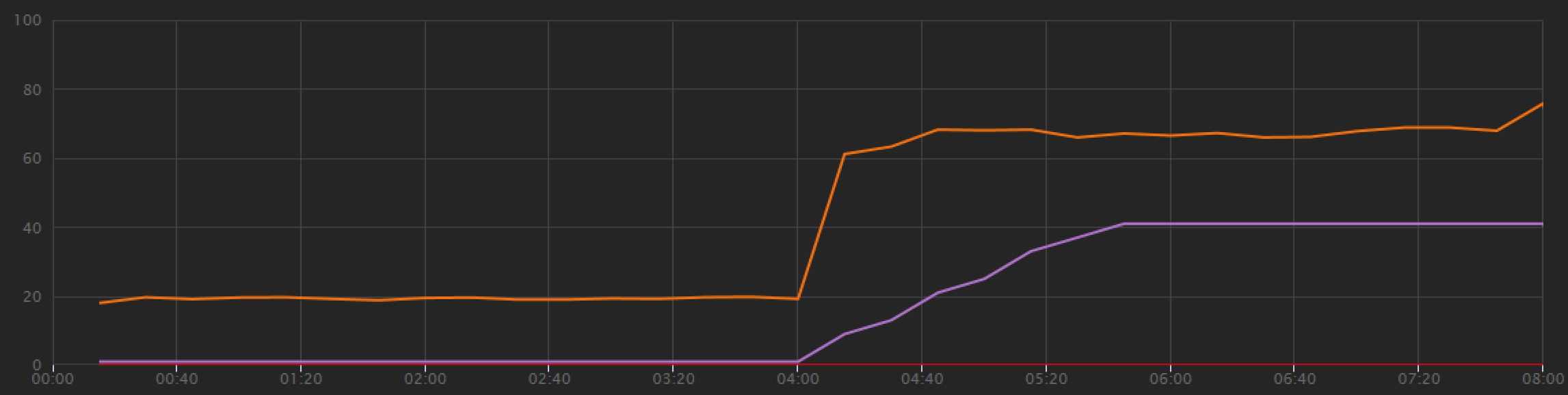
Vi kan kontrollera att Azure Cosmos DB-klienten kör frågor parallellt genom att titta på transaktionsvyn från slutpunkt till slutpunkt:
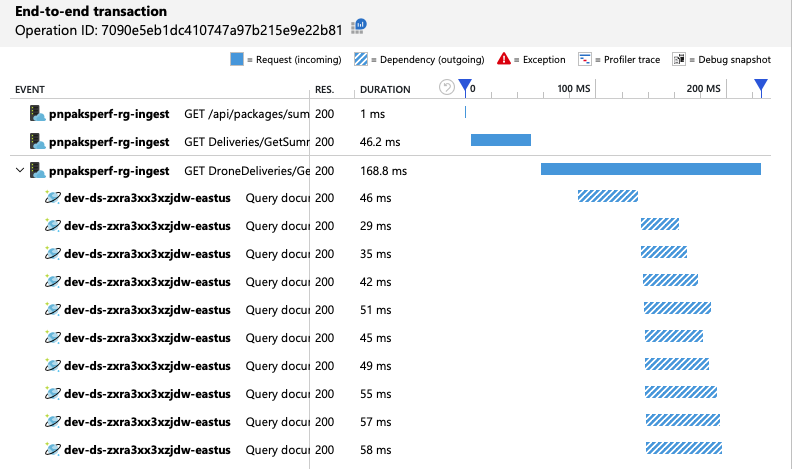
Intressant nog är en bieffekt av att öka dataflödet att antalet förbrukade RU:er per sekund också ökar. Även om Azure Cosmos DB inte begränsade några begäranden under det här testet var förbrukningen nära den etablerade RU-gränsen:
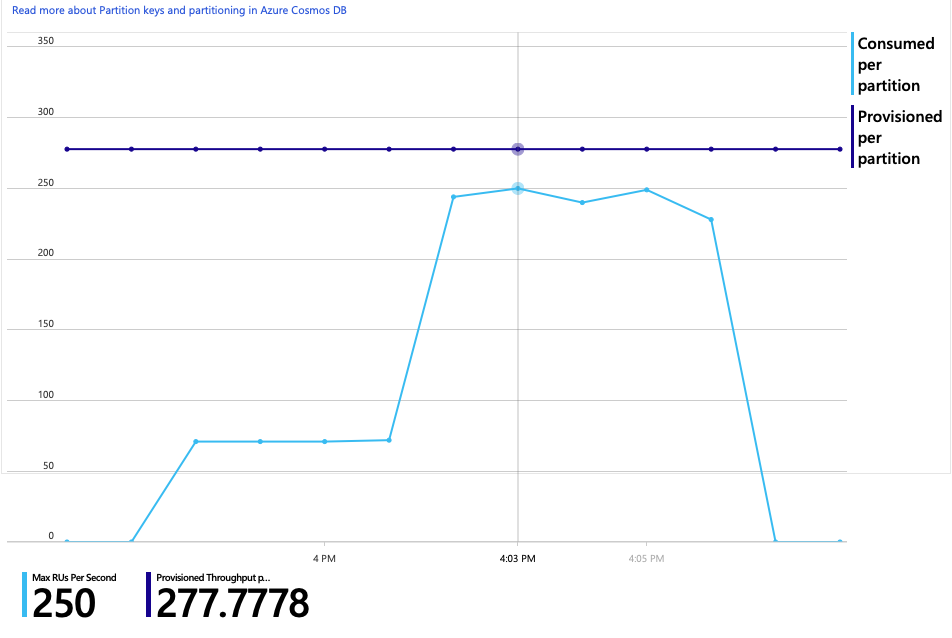
Det här diagrammet kan vara en signal för att ytterligare skala ut databasen. Det visar sig dock att vi kan optimera frågan i stället.
Steg 4: Optimera frågan
Föregående belastningstest visade bättre prestanda vad gäller svarstid och dataflöde. Den genomsnittliga svarstiden för begäran minskade med 68 % och dataflödet ökade med 220 %. Frågan mellan partitioner är dock ett problem.
Problemet med frågor mellan partitioner är att du betalar för RU för varje partition. Om frågan bara körs ibland, till exempel en gång i timmen, kanske det inte spelar någon roll. Men när du ser en läsintensiv arbetsbelastning som omfattar en fråga mellan partitioner bör du se om frågan kan optimeras genom att inkludera en partitionsnyckel. (Du kan behöva göra om samlingen för att använda en annan partitionsnyckel.)
Här är frågan för det här scenariot:
SELECT * FROM c
WHERE c.ownerId = <ownerIdValue> and
c.year = <yearValue> and
c.month = <monthValue>
Den här frågan väljer poster som matchar ett visst ägar-ID och månad/år. I den ursprungliga designen är ingen av dessa egenskaper partitionsnyckeln. Det kräver att klienten fläktar ut frågan till varje fysisk partition och samlar in resultaten. För att förbättra frågeprestandan ändrade utvecklingsteamet designen så att ägar-ID är partitionsnyckeln för samlingen. På så sätt kan frågan rikta in sig på en specifik fysisk partition. (Azure Cosmos DB hanterar detta automatiskt. Du behöver inte hantera mappningen mellan partitionsnyckelvärden och fysiska partitioner.)
När samlingen hade bytts till den nya partitionsnyckeln skedde en dramatisk förbättring av RU-förbrukningen, vilket innebär direkt lägre kostnader.
| Metric | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| RU:er per åtgärd | 29 | 29 | 29 | 3.4 |
| Anrop per åtgärd | 11 | 9 | 10 | 1 |
Transaktionsvyn från slutpunkt till slutpunkt visar att frågan som förutsagt endast läser en fysisk partition:
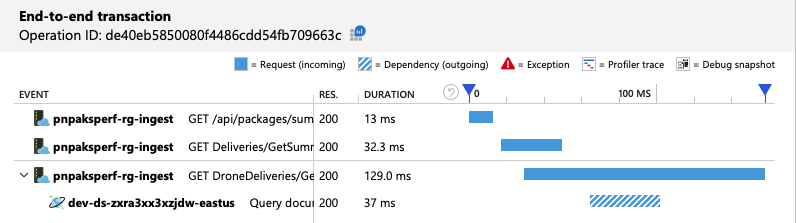
Belastningstestet visar förbättrat dataflöde och svarstid:
| Metric | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| Dataflöde (req/sek) | 19 | 23 | 42 | 59 |
| Genomsnittlig svarstid (ms) | 669 | 569 | 215 | 176 |
| Lyckade begäranden | 9,8 K | 11 K | 20 K | 29 K |
| Begränsade begäranden | 2,72 K | 0 | 0 | 0 |
En följd av den förbättrade prestandan är att nodens processoranvändning blir mycket hög:
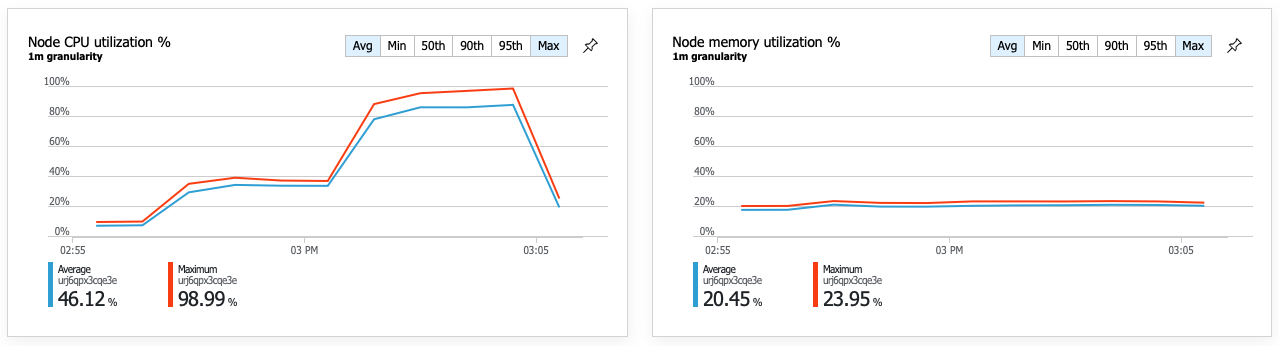
Mot slutet av belastningstestet nådde den genomsnittliga processorn cirka 90 % och den maximala PROCESSORn nådde 100 %. Det här måttet anger att CPU är nästa flaskhals i systemet. Om du behöver ett högre dataflöde kan nästa steg vara att skala ut leveranstjänsten till fler instanser.
Sammanfattning
I det här scenariot identifierades följande flaskhalsar:
- Azure Cosmos DB-begränsningsbegäranden på grund av otillräckligt etablerade RU:er.
- Långa svarstider som orsakas av frågor mot flera databaspartitioner i seriellt format.
- Ineffektiv fråga mellan partitioner eftersom frågan inte innehöll partitionsnyckeln.
Dessutom identifierades processoranvändningen som en potentiell flaskhals i högre skala. För att diagnostisera dessa problem har utvecklingsteamet tittat på:
- Svarstid och dataflöde från belastningstestet.
- Azure Cosmos DB-fel och RU-förbrukning.
- Transaktionsvyn från slutpunkt till slutpunkt i Application Insight.
- Processor- och minnesanvändning i Azure Monitor containerinsikter.
Nästa steg
Granska prestandaantimönster