Många tjänster använder ett begränsningsmönster för att kontrollera de resurser de använder, vilket begränsar hur snabbt andra program eller tjänster kan komma åt dem. Du kan använda ett hastighetsbegränsningsmönster som hjälper dig att undvika eller minimera begränsningsfel relaterade till dessa begränsningsgränser och för att hjälpa dig att mer exakt förutsäga dataflödet.
Ett frekvensbegränsningsmönster är lämpligt i många scenarier, men det är särskilt användbart för storskaliga repetitiva automatiserade uppgifter, till exempel batchbearbetning.
Kontext och problem
Att utföra ett stort antal åtgärder med hjälp av en begränsad tjänst kan leda till ökad trafik och dataflöde, eftersom du måste både spåra avvisade begäranden och sedan försöka utföra dessa åtgärder igen. När antalet åtgärder ökar kan en begränsningsgräns kräva flera passering av data som skickas om, vilket resulterar i en större prestandapåverkan.
Tänk till exempel på följande naiva återförsök i felprocessen för att mata in data i Azure Cosmos DB:
- Ditt program måste mata in 10 000 poster i Azure Cosmos DB. Varje post kostar 10 enheter för begäran (RU: er) att mata in, vilket kräver totalt 100 000 RU:er för att slutföra jobbet.
- Azure Cosmos DB-instansen har 20 000 RU:er etablerad kapacitet.
- Du skickar alla 10 000 poster till Azure Cosmos DB. 2 000 poster skrivs och 8 000 poster avvisas.
- Du skickar de återstående 8 000 posterna till Azure Cosmos DB. 2 000 poster skrivs och 6 000 poster avvisas.
- Du skickar de återstående 6 000 posterna till Azure Cosmos DB. 2 000 poster skrivs och 4 000 poster avvisas.
- Du skickar de återstående 4 000 posterna till Azure Cosmos DB. 2 000 poster skrivs och 2 000 poster avvisas.
- Du skickar de återstående 2 000 posterna till Azure Cosmos DB. Alla skrivs korrekt.
Inmatningsjobbet slutfördes, men först efter att 30 000 poster skickats till Azure Cosmos DB trots att hela datamängden bara bestod av 10 000 poster.
Det finns ytterligare faktorer att tänka på i exemplet ovan:
- Ett stort antal fel kan också resultera i ytterligare arbete för att logga dessa fel och bearbeta resulterande loggdata. Den här naiva metoden har hanterat 20 000 fel, och loggning av dessa fel kan medföra en kostnad för bearbetning, minne eller lagringsresurs.
- Utan att känna till begränsningarna för inmatningstjänsten har den naiva metoden inget sätt att ställa in förväntningar på hur lång tid databearbetningen kommer att ta. Med hastighetsbegränsning kan du beräkna den tid som krävs för inmatning.
Lösning
Hastighetsbegränsning kan minska din trafik och potentiellt förbättra dataflödet genom att minska antalet poster som skickas till en tjänst under en viss tidsperiod.
En tjänst kan begränsas baserat på olika mått över tid, till exempel:
- Antalet åtgärder (till exempel 20 begäranden per sekund).
- Mängden data (till exempel 2 GiB per minut).
- Den relativa kostnaden för åtgärder (till exempel 20 000 RU:er per sekund).
Oavsett vilket mått som används för begränsning innebär din hastighetsbegränsningsimplementering att kontrollera antalet och/eller storleken på åtgärder som skickas till tjänsten under en viss tidsperiod, vilket optimerar din användning av tjänsten utan att överskrida dess begränsningskapacitet.
I scenarier där dina API:er kan hantera begäranden snabbare än vad några begränsade inmatningstjänster tillåter måste du hantera hur snabbt du kan använda tjänsten. Det är dock riskabelt att bara behandla begränsningen som ett matchningsproblem med datahastigheten och bara buffrar dina inmatningsbegäranden tills den begränsade tjänsten kan komma ikapp. Om ditt program kraschar i det här scenariot riskerar du att förlora någon av dessa buffrade data.
För att undvika den här risken bör du överväga att skicka dina poster till ett beständigt meddelandesystem som kan hantera din fullständiga inmatningshastighet. (Tjänster som Azure Event Hubs kan hantera miljontals åtgärder per sekund. Du kan sedan använda en eller flera jobbprocessorer för att läsa posterna från meddelandesystemet med en kontrollerad hastighet som ligger inom den begränsade tjänstens gränser. Om du skickar poster till meddelandesystemet kan du spara internt minne genom att endast ta bort de poster som kan bearbetas under ett visst tidsintervall.
Azure tillhandahåller flera hållbara meddelandetjänster som du kan använda med det här mönstret, inklusive:
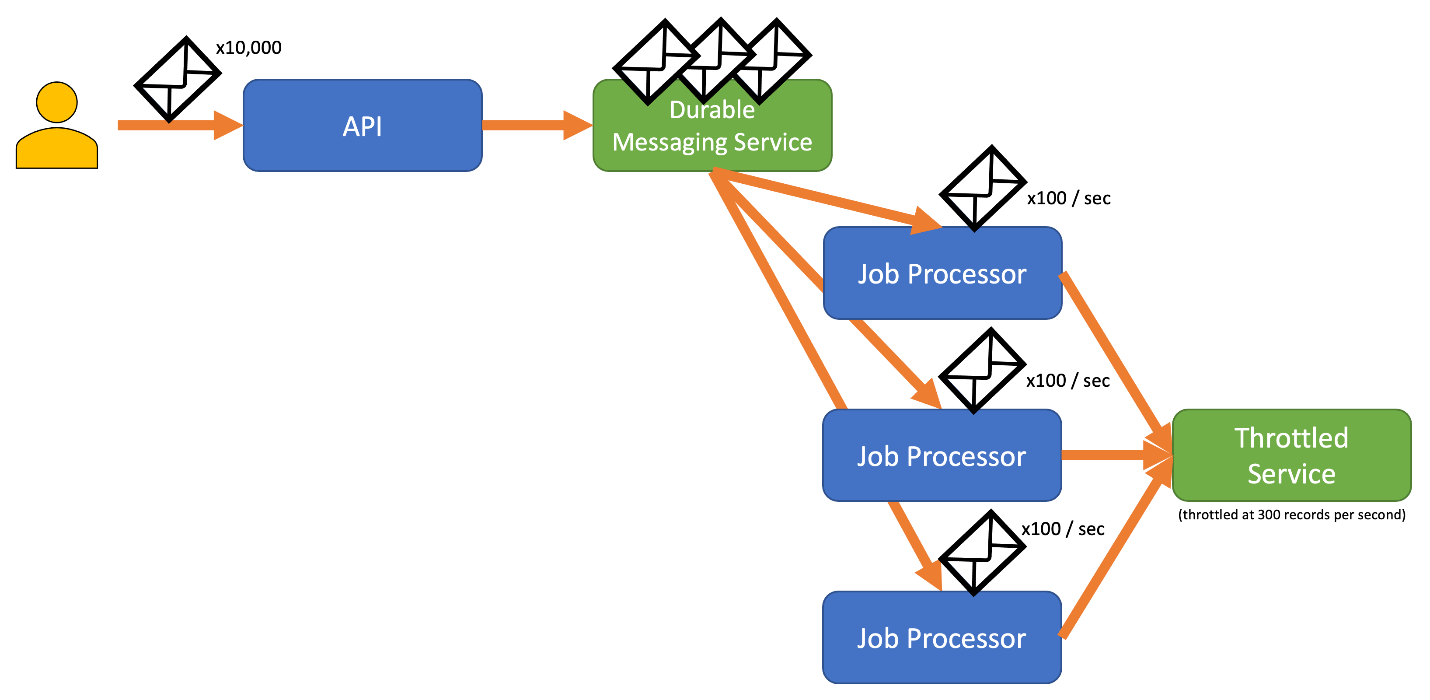
När du skickar poster kan tidsperioden som du använder för att släppa poster vara mer detaljerad än den period då tjänsten begränsas. System ställer ofta in begränsningar baserat på tidsintervall som du enkelt kan förstå och arbeta med. För den dator som kör en tjänst kan dessa tidsramar dock vara mycket långa jämfört med hur snabbt den kan bearbeta information. Ett system kan till exempel begränsas per sekund eller minut, men vanligtvis bearbetas koden i ordningen nanosekunder eller millisekunder.
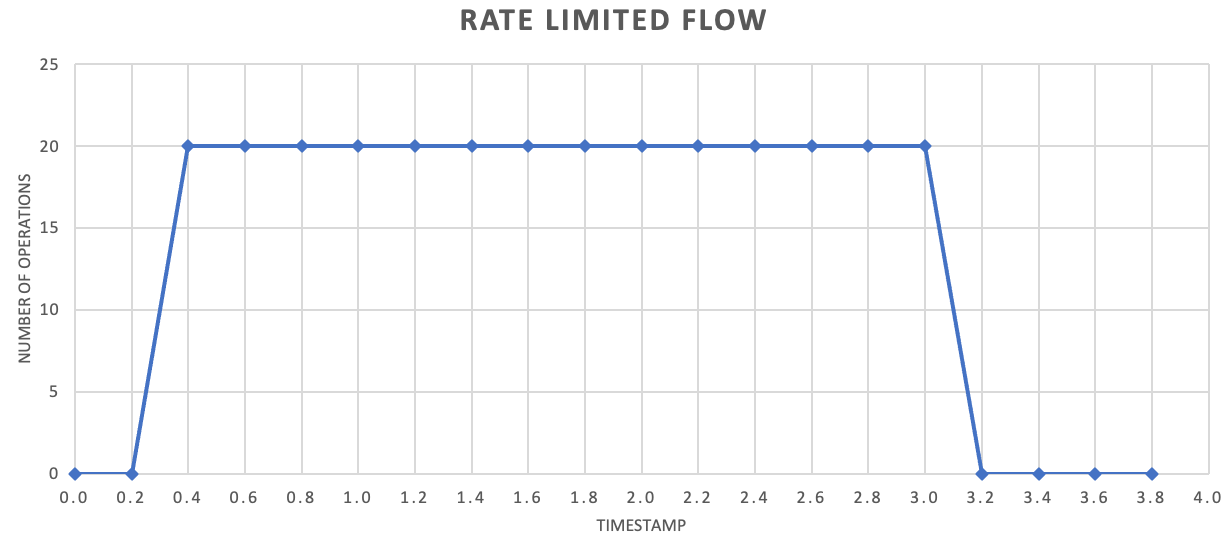
Även om det inte behövs rekommenderar vi ofta att du skickar mindre mängder poster oftare för att förbättra dataflödet. Så i stället för att försöka batcha upp saker för en version en gång i sekunden eller en gång i minuten kan du vara mer detaljerad än så för att hålla din resursförbrukning (minne, CPU, nätverk och så vidare) flytande i en jämnare takt, vilket förhindrar potentiella flaskhalsar på grund av plötsliga utbrott av begäranden. Om en tjänst till exempel tillåter 100 åtgärder per sekund kan implementeringen av en hastighetsbegränsare jämna ut begäranden genom att släppa 20 åtgärder var 200:e millisekunder, enligt följande diagram.
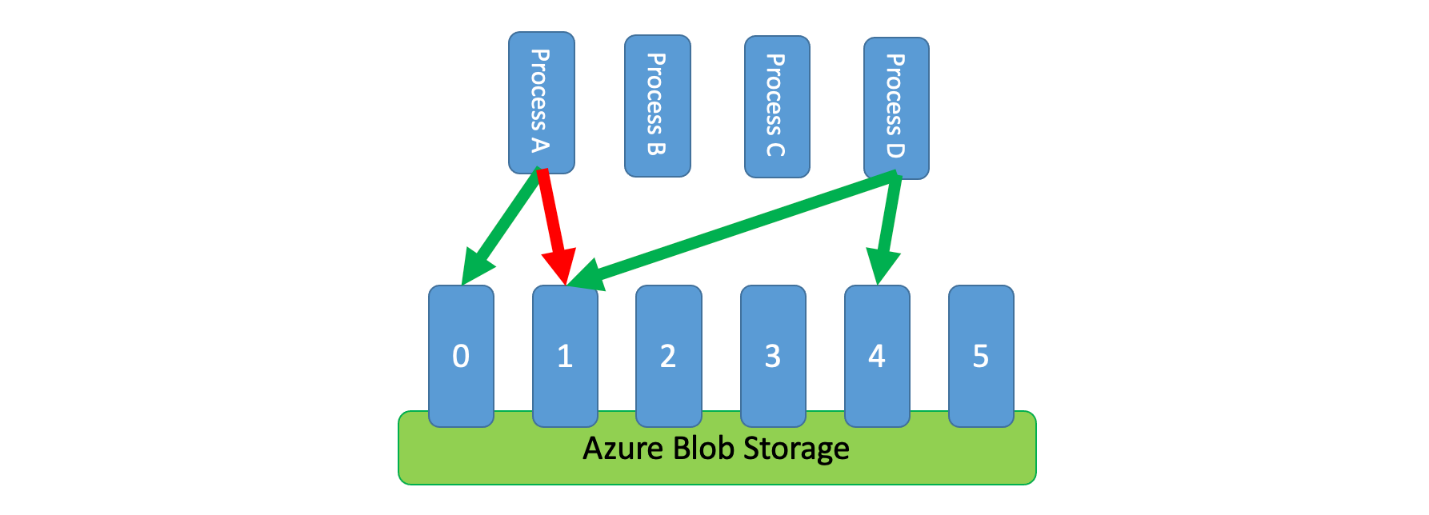
Dessutom är det ibland nödvändigt att flera okoordinerade processer delar en begränsad tjänst. Om du vill implementera hastighetsbegränsning i det här scenariot kan du logiskt partitionera tjänstens kapacitet och sedan använda ett distribuerat system för ömsesidig uteslutning för att hantera exklusiva lås på dessa partitioner. De okoordinerade processerna kan sedan konkurrera om lås på dessa partitioner när de behöver kapacitet. För varje partition som en process har ett lås för beviljas den en viss mängd kapacitet.
Om det begränsade systemet till exempel tillåter 500 begäranden per sekund kan du skapa 20 partitioner värda 25 begäranden per sekund vardera. Om en process behövs för att utfärda 100 begäranden kan den be det distribuerade systemet för ömsesidig uteslutning om fyra partitioner. Systemet kan bevilja två partitioner i 10 sekunder. Processen skulle sedan betygsätta gränsen till 50 begäranden per sekund, slutföra uppgiften på två sekunder och sedan släppa låset.
Ett sätt att implementera det här mönstret är att använda Azure Storage. I det här scenariot skapar du en 0-bytes blob per logisk partition i en container. Dina program kan sedan erhålla exklusiva lån direkt mot dessa blobar under en kort tidsperiod (till exempel 15 sekunder). För varje lån som ett program beviljas kan det använda den partitionens kapacitet. Programmet måste sedan spåra lånetiden så att det, när det upphör att gälla, kan sluta använda den kapacitet som det beviljades. När du implementerar det här mönstret vill du ofta att varje process ska försöka leasa en slumpmässig partition när den behöver kapacitet.
Om du vill minska svarstiden ytterligare kan du allokera en liten mängd exklusiv kapacitet för varje process. En process skulle då bara försöka få ett lån på delad kapacitet om den behövde överskrida sin reserverade kapacitet.
Som ett alternativ till Azure Storage kan du även implementera den här typen av lånehanteringssystem med hjälp av tekniker som Zookeeper, Consul, etcd, Redis/Redsync och andra.
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera det här mönstret:
- Även om hastighetsbegränsningsmönstret kan minska antalet begränsningsfel måste programmet fortfarande hantera eventuella begränsningsfel korrekt.
- Om ditt program har flera arbetsströmmar som har åtkomst till samma begränsade tjänst måste du integrera dem alla i din strategi för hastighetsbegränsning. Du kan till exempel ha stöd för massinläsning av poster i en databas men även frågor om poster i samma databas. Du kan hantera kapaciteten genom att se till att alla arbetsströmmar är gated genom samma hastighetsbegränsningsmekanism. Du kan också reservera separata kapacitetspooler för varje arbetsström.
- Den begränsade tjänsten kan användas i flera program. I vissa – men inte alla – fall är det möjligt att samordna användningen (som du ser ovan). Om du börjar se ett större antal begränsningsfel än förväntat kan det vara ett tecken på konkurrens mellan program som har åtkomst till en tjänst. I så fall kan du behöva överväga att tillfälligt minska det dataflöde som införts av din hastighetsbegränsningsmekanism tills användningen från andra program minskar.
När du ska använda det här mönstret
Använd det här mönstret om du vill:
- Minska begränsningsfel som genereras av en begränsningsbegränsad tjänst.
- Minska trafiken jämfört med ett naivt återförsök på felmetoden.
- Minska minnesförbrukningen genom att endast dequeuera poster när det finns kapacitet att bearbeta dem.
Design av arbetsbelastning
En arkitekt bör utvärdera hur mönstret Hastighetsbegränsning kan användas i arbetsbelastningens design för att uppfylla de mål och principer som beskrivs i grundpelarna i Azure Well-Architected Framework. Till exempel:
| Grundpelare | Så här stöder det här mönstret pelarmål |
|---|---|
| Beslut om tillförlitlighetsdesign hjälper din arbetsbelastning att bli motståndskraftig mot fel och se till att den återställs till ett fullt fungerande tillstånd när ett fel inträffar. | Den här taktiken skyddar klienten genom att erkänna och respektera begränsningarna och kostnaderna för att kommunicera med en tjänst när tjänsten vill undvika överdriven användning. - RE:07 Självbevarande |
Som med alla designbeslut bör du överväga eventuella kompromisser mot målen för de andra pelarna som kan införas med det här mönstret.
Exempel
I följande exempelprogram kan användare skicka poster av olika typer till ett API. Det finns en unik jobbprocessor för varje posttyp som utför följande steg:
- Validering
- Berikning
- Infoga posten i databasen
Alla komponenter i programmet (API, jobbprocessor A och jobbprocessor B) är separata processer som kan skalas separat. Processerna kommunicerar inte direkt med varandra.
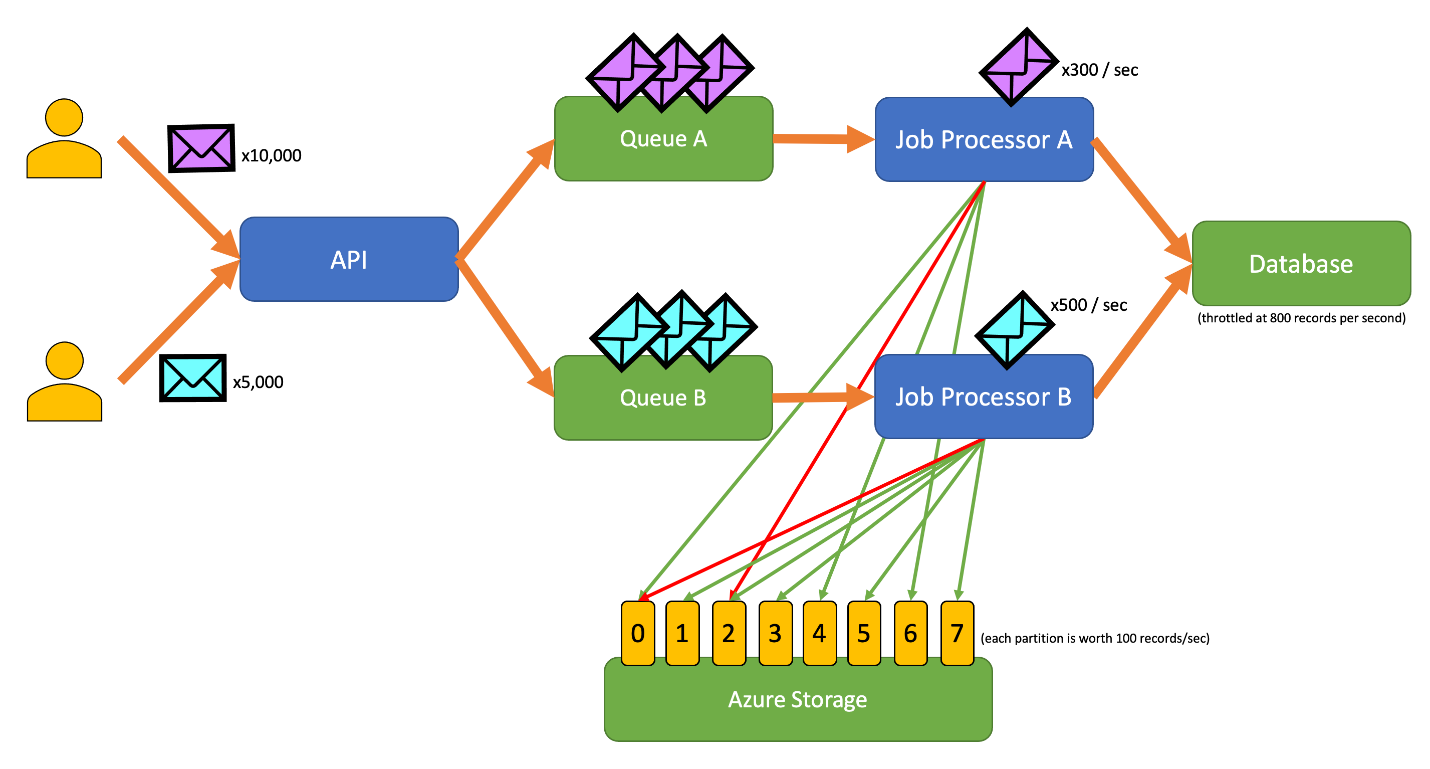
Det här diagrammet innehåller följande arbetsflöde:
- En användare skickar 10 000 poster av typen A till API:et.
- API:et anger dessa 10 000 poster i kö A.
- En användare skickar 5 000 poster av typen B till API:et.
- API:et anger dessa 5 000 poster i kö B.
- Jobbprocessor A ser kö A har poster och försöker få ett exklusivt lån på blob 2.
- Jobbprocessor B ser att kö B har poster och försöker få ett exklusivt lån på blob 2.
- Jobbprocessor A kan inte hämta lånet.
- Jobbprocessor B hämtar lånet på blob 2 i 15 sekunder. Den kan nu hastighetsgränsa begäranden till databasen med en hastighet av 100 per sekund.
- Jobbprocessor B lämnar 100 poster från kö B och skriver dem.
- En sekund passerar.
- Jobbprocessor A ser att kö A har fler poster och försöker få ett exklusivt lån på blob 6.
- Jobbprocessor B ser att kö B har fler poster och försöker få ett exklusivt lån på blob 3.
- Jobbprocessor A hämtar lånet på blob 6 i 15 sekunder. Den kan nu hastighetsgränsa begäranden till databasen med en hastighet av 100 per sekund.
- Jobbprocessor B hämtar lånet på blob 3 i 15 sekunder. Den kan nu hastighetsgränsa begäranden till databasen med en hastighet av 200 per sekund. (Den innehåller även lånet för blob 2.)
- Jobbprocessor En tar bort 100 poster från kö A och skriver dem.
- Jobbprocessor B lämnar 200 poster från kö B och skriver dem.
- En sekund passerar.
- Jobbprocessor A ser kö A har fler poster och försöker få ett exklusivt lån på blob 0.
- Jobbprocessor B ser att kö B har fler poster och försöker få ett exklusivt lån på blob 1.
- Jobbprocessor A hämtar lånet på blob 0 i 15 sekunder. Den kan nu hastighetsgränsa begäranden till databasen med en hastighet av 200 per sekund. (Den innehåller även lånet för blob 6.)
- Jobbprocessor B hämtar lånet på blob 1 i 15 sekunder. Den kan nu hastighetsgränsa begäranden till databasen med en hastighet av 300 per sekund. (Den innehåller även lånet för blobarna 2 och 3.)
- Jobbprocessor En tar bort 200 poster från kö A och skriver dem.
- Jobbprocessor B lämnar 300 poster från kö B och skriver dem.
- Och så vidare...
Efter 15 sekunder slutförs fortfarande inte ett eller båda jobben. När lånen upphör att gälla bör en processor också minska antalet begäranden som den tar bort och skriver.
 Implementeringar av det här mönstret finns på olika programmeringsspråk:
Implementeringar av det här mönstret finns på olika programmeringsspråk:
Relaterade resurser
Följande mönster och riktlinjer kan vara relevanta när du implementerar det här mönstret:
- Begränsning. Det hastighetsbegränsningsmönster som beskrivs här implementeras vanligtvis som svar på en tjänst som är begränsad.
- Försöka igen. När begäranden till begränsad tjänst resulterar i begränsningsfel är det vanligtvis lämpligt att försöka igen efter ett lämpligt intervall.
Köbaserad belastningsutjämning är liknande men skiljer sig från mönstret Hastighetsbegränsning på flera viktiga sätt:
- Hastighetsbegränsning behöver inte nödvändigtvis använda köer för att hantera belastningen, men den behöver använda en beständig meddelandetjänst. Ett frekvensbegränsningsmönster kan till exempel använda tjänster som Apache Kafka eller Azure Event Hubs.
- Mönstret för hastighetsbegränsning introducerar begreppet distribuerat system för ömsesidig uteslutning på partitioner, vilket gör att du kan hantera kapacitet för flera okoordinerade processer som kommunicerar med samma begränsade tjänst.
- Ett köbaserat belastningsutjämningsmönster är tillämpligt när det uppstår ett prestandamatchningsfel mellan tjänster eller för att förbättra motståndskraften. Detta gör det till ett bredare mönster än hastighetsbegränsning, vilket mer specifikt handlar om att effektivt komma åt en begränsad tjänst.