Dela upp en aktivitet som utför komplex bearbetningen i en serie olika element som kan återanvändas. Detta kan förbättra prestanda, skalbarhet och återanvändning av inledande steg genom att tillåta att uppgiftselement som utför bearbetningen distribueras och skalas oberoende av varandra. Mönster för rör och filter har stöd för en hög modularitetsnivå.
Kontext och problem
Du har en pipeline med sekventiella uppgifter som du behöver bearbeta. En enkel men oflexibel metod för att implementera det här programmet är att utföra den här bearbetningen i en monolitisk modul. Den här metoden kommer dock sannolikt att minska möjligheterna att omstrukturera koden, optimera den eller återanvända den om delar av samma bearbetning krävs någon annanstans i programmet.
Följande diagram illustrerar ett av problemen med att bearbeta data med hjälp av en monolitisk metod, oförmågan att återanvända kod över flera pipelines. I det här exemplet tar ett program emot och bearbetar data från två källor. En separat modul bearbetar data från varje källa genom att utföra en serie uppgifter för att transformera data innan resultatet skickas till programmets affärslogik.
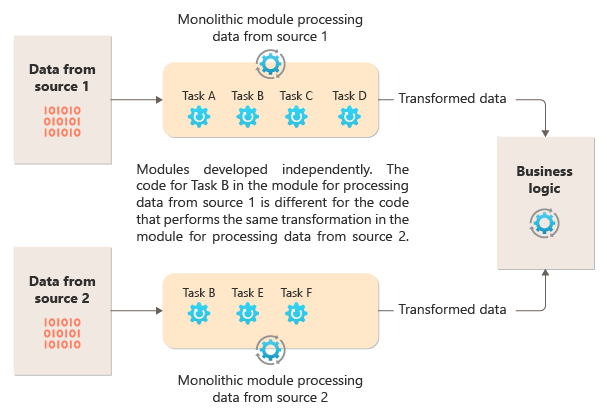
Vissa av de uppgifter som de monolitiska modulerna utför är funktionellt lika, men koden måste upprepas i båda modulerna och är sannolikt nära kopplad till modulen. Förutom att logiken inte kan återanvändas medför den här metoden en risk när kraven ändras. Du måste komma ihåg att uppdatera koden på båda platserna.
Det finns andra utmaningar med en monolitisk implementering som inte är relaterad till flera pipelines eller återanvändning. Med en monolit har du inte möjlighet att köra specifika uppgifter i olika miljöer eller skala dem oberoende av varandra. Vissa uppgifter kan vara beräkningsintensiva och kan ha nytta av att köra på kraftfull maskinvara eller köra flera instanser parallellt. Andra uppgifter kanske inte har samma krav. Med monoliter är det dessutom svårt att ordna om uppgifter eller mata in nya uppgifter i pipelinen. Dessa ändringar kräver att hela pipelinen testas igen.
Lösning
Bryt ned den bearbetning som krävs för varje dataström till en uppsättning med olika komponenter (eller filter) som var och en utför en enskild uppgift. Sammansatta uppgifter bör använda flera filter i stället för ett. Filtren består av pipelines genom att filtren ansluts med rör. Filter är oberoende, fristående och vanligtvis tillståndslösa. Filter tar emot meddelanden från ett inkommande rör och publicerar meddelanden till ett annat utgående rör. Filter kan transformera meddelandet eller testa det mot ett eller flera villkor för att inkludera villkorslogik. Pipes utför inte routning eller någon annan logik. De ansluter bara filter och skickar utdatameddelandet från ett filter som indata till nästa.
Filter fungerar oberoende av varandra och känner inte till andra filter. De är bara medvetna om sina indata- och utdatascheman. Därför kan filtren ordnas i valfri ordning så länge indataschemat för ett filter matchar utdataschemat för föregående filter. Om du använder ett standardiserat schema för alla filter kan du ändra ordning på filtren. Arkitekturen rör och filter uppmuntrar till återanvändning av sammansättning.
Den lösa kopplingen av filter gör det enkelt att:
- Skapa nya pipelines som består av befintliga filter
- Uppdatera eller ersätta logik i enskilda filter
- Ändra ordning på filter vid behov
- Kör filter på olika maskinvara, där det krävs
- Köra filter parallellt
Det här diagrammet visar en lösning som implementerats med rör och filter:
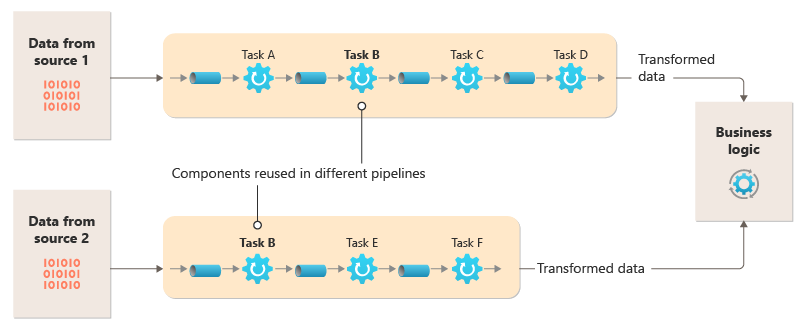
Hur lång tid det tar att bearbeta en enskild begäran beror på hastigheten för de långsammaste filtren i pipelinen. Ett eller flera filter kan vara flaskhalsar, särskilt om ett stort antal begäranden visas i en ström från en viss datakälla. Möjligheten att köra parallella instanser av långsamma filter gör att systemet kan sprida belastningen och förbättra dataflödet.
Möjligheten att köra filter på olika beräkningsinstanser gör att de kan skalas separat och dra nytta av den elasticitet som många molnmiljöer tillhandahåller. Ett filter som är beräkningsintensivt kan köras på maskinvara med höga prestanda, medan andra mindre krävande filter kan hanteras på billigare maskinvara. Filtren behöver inte ens finnas i samma datacenter eller geografiska plats, vilket gör att varje element i en pipeline kan köras i en miljö som är nära de resurser som krävs. Dessa ansträngningar kräver specifika designtekniker som meddelanden, multitrådning och så vidare för att maximera elasticiteten för varje rör eller filter. Det här diagrammet visar ett exempel som tillämpas på pipelinen för data från källa 1:
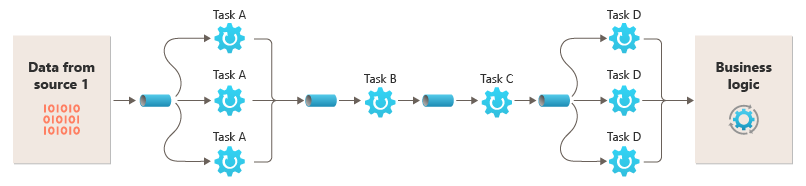
Om indata och utdata för ett filter är strukturerade som en ström kan du utföra bearbetningen för varje filter parallellt. Det första filtret i pipelinen kan starta sitt arbete och mata ut resultatet, som skickas direkt till nästa filter i sekvensen innan det första filtret slutför sitt arbete.
Att använda mönstret Pipes och Filter tillsammans med mönstret Kompenserande transaktion är en alternativ metod för att implementera distribuerade transaktioner. Du kan dela upp en distribuerad transaktion i separata, kompenserbara uppgifter, som var och en kan implementeras via ett filter som även implementerar mönstret Kompenserande transaktion. Du kan implementera filtren i en pipeline som separata värdbaserade uppgifter som körs nära de data som de underhåller.
Problem och överväganden
Tänk på följande när du bestämmer dig för hur du implementerar det här mönstret:
Monolitisk natur. Det här mönstret implementeras vanligtvis som en monolitisk pipeline, så för alla ändringar bör hela filterkedjan testas från slutpunkt till slutpunkt. Dessutom måste feltolerans för hela processen beaktas. Om ett filter eller rör misslyckas misslyckas sannolikt hela pipelinen.
Komplexitet. Den ökade flexibilitet som det här mönstret ger kan också introducera komplexitet, i synnerhet om filtren i en pipeline är fördelade på olika servrar.
Tillförlitlighet. Använd en infrastruktur som säkerställer att data som flödar mellan filter i ett rör inte går förlorade.
Idempotens. Om ett filter i en pipeline misslyckas när ett meddelande har tagits emot och arbetet har schemalagts om till en annan instans av filtret kanske en del av arbetet redan är klart. Om arbetet uppdaterar någon aspekt av det globala tillståndet (till exempel information som lagras i en databas) kan en enskild uppdatering upprepas. Ett liknande problem kan uppstå om ett filter misslyckas när det har publicerat sina resultat till nästa filter, men innan det anger att det har slutfört sitt arbete. I dessa fall kan en annan instans av filtret upprepa det här arbetet, vilket gör att samma resultat publiceras två gånger. Det här scenariot kan resultera i efterföljande filter i pipelinen som bearbetar samma data två gånger. Därför bör filter i en pipeline utformas för att vara idempotent. Mer information finns i Idempotensmönster på Jonathan Olivers blogg.
Upprepade meddelanden. Om ett filter i en pipeline misslyckas efter att ett meddelande har skickats till nästa steg i pipelinen kan en annan instans av filtret köras och en kopia av samma meddelande skickas till pipelinen. Det här scenariot kan leda till att två instanser av samma meddelande skickas till nästa filter. För att undvika det här problemet bör pipelinen identifiera och eliminera duplicerade meddelanden.
Kommentar
Om du implementerar pipelinen med hjälp av meddelandeköer (till exempel Azure Service Bus-köer) kan infrastrukturen för meddelandeköer ge automatisk identifiering och borttagning av dubbletter av meddelanden.
Kontext och tillstånd. I en pipeline körs varje filter i stort sett i isolerat och bör inte göra några antaganden om hur den anropades. Därför bör varje filter ha tillräcklig kontext för att utföra sitt arbete. Den här kontexten kan innehålla en betydande mängd tillståndsinformation. Om filter använder externt tillstånd, till exempel data i en databas eller extern lagring, måste du ta hänsyn till prestandapåverkan. Varje filter måste läsa in, använda och bevara det tillståndet, vilket lägger till omkostnader för lösningar som läser in det externa tillståndet en gång.
Meddelandetolerans. Filter måste vara toleranta mot data i det inkommande meddelandet som de inte arbetar mot. De arbetar på data som är relevanta för dem och ignorerar andra data och skickar dem oförändrade i utdatameddelandet.
Felhantering – Varje filter måste avgöra vad som ska göras om ett fel uppstår. Filtret måste avgöra om pipelinen misslyckas eller om undantaget sprids.
När du ska använda det här mönstret
Använd det här mönstret i sådana här scenarier:
Den bearbetning som krävs av ett program kan enkelt delas upp i en uppsättning fristående steg.
De bearbetningssteg som utförs av ett program har olika skalbarhetskrav.
Kommentar
Du kan gruppera filter som ska skalas tillsammans i samma process. Mer information finns i Compute Resource Consolidation pattern (Mönster för konsolidering av beräkningsresurser).
Du behöver flexibiliteten för att tillåta omordning av de bearbetningssteg som programmet utför, eller för att tillåta att funktionen lägger till och tar bort steg.
Systemet kan dra nytta av att distribuera bearbetningen för steg mellan olika servrar.
Du behöver en tillförlitlig lösning som minimerar effekterna av fel i ett steg medan data bearbetas.
Det här mönstret är kanske inte användbart om:
Programmet följer ett mönster för begärandesvar.
Uppgiftsbearbetningen måste slutföras som en del av en inledande begäran, till exempel ett scenario för begäran/svar.
Bearbetningsstegen som utförs av ett program är inte oberoende, eller så måste de utföras tillsammans som en del av en enda transaktion.
Mängden kontext- eller tillståndsinformation som ett steg kräver gör den här metoden ineffektiv. Du kanske kan spara tillståndsinformation till en databas, men använd inte den här strategin om den extra belastningen på databasen orsakar överdriven konkurrens.
Design av arbetsbelastning
En arkitekt bör utvärdera hur mönstret Pipes och Filter kan användas i arbetsbelastningens design för att uppfylla de mål och principer som beskrivs i grundpelarna i Azure Well-Architected Framework. Till exempel:
| Grundpelare | Så här stöder det här mönstret pelarmål |
|---|---|
| Beslut om tillförlitlighetsdesign hjälper din arbetsbelastning att bli motståndskraftig mot fel och se till att den återställs till ett fullt fungerande tillstånd när ett fel inträffar. | Det enda ansvaret för varje steg möjliggör fokuserad uppmärksamhet och undviker distraktion av blandat databehandling. - RE:01 Enkelhet - RE:07 Bakgrundsjobb |
Som med alla designbeslut bör du överväga eventuella kompromisser mot målen för de andra pelarna som kan införas med det här mönstret.
Exempel
Du kan använda en sekvens av meddelandeköer för att tillhandahålla den infrastruktur som krävs för att implementera en pipeline. En första meddelandekö tar emot obearbetade meddelanden som blir början på implementeringen av rör- och filtermönstret. En komponent som implementeras som en filteruppgift lyssnar efter ett meddelande i den här kön, utför sitt arbete och publicerar sedan ett nytt eller transformerat meddelande till nästa kö i sekvensen. En annan filteruppgift kan lyssna efter meddelanden i den här kön, bearbeta dem, publicera resultaten i en annan kö och så vidare tills det sista steget som avslutar rör- och filterprocessen. Det här diagrammet illustrerar en pipeline som använder meddelandeköer:

En pipeline för bildbearbetning kan implementeras med det här mönstret. Om din arbetsbelastning tar en avbildning kan avbildningen passera genom en serie i stort sett oberoende och omordningsbara filter för att utföra åtgärder som:
- con tältläge ration
- ändra storlek
- Vattenmärkning
- Reorientation
- Exif metadataborttagning
- Cdn-publikation (Content Delivery Network)
I det här exemplet kan filtren implementeras som individuellt distribuerade Azure Functions eller till och med en enda Azure-funktionsapp som innehåller varje filter som en isolerad distribution. Användningen av Azure-funktionsutlösare, indatabindningar och utdatabindningar kan förenkla filterkoden och fungera automatiskt med ett köbaserat rör med hjälp av en anspråkskontroll till avbildningen som ska bearbetas.

Här är ett exempel på hur ett filter, implementerat som en Azure-funktion, utlöses från ett Queue Storage-rör med en anspråkskontroll till avbildningen och att skriva en ny anspråkskontroll till en annan Kölagringspipa kan se ut. Vi har ersatt implementeringen med pseudokod i kommentarer för korthet. Mer kod som den här finns i demonstrationen av mönstret Pipes and Filters som är tillgängligt på GitHub.
// This is the "Resize" filter. It handles claim checks from input pipe, performs the
// resize work, and places a claim check in the next pipe for anther filter to handle.
[Function(nameof(ResizeFilter))]
[QueueOutput("pipe-fjur", Connection = "pipe")] // Destination pipe claim check
public async Task<string> RunAsync(
[QueueTrigger("pipe-xfty", Connection = "pipe")] string imageFilePath, // Source pipe claim check
[BlobInput("{QueueTrigger}", Connection = "pipe")] BlockBlobClient imageBlob) // Image to process
{
_logger.LogInformation("Processing image {uri} for resizing.", imageBlob.Uri);
// Idempotency checks
// ...
// Download image based on claim check in queue message body
// ...
// Resize the image
// ...
// Write resized image back to storage
// ...
// Create claim check for image and place in the next pipe
// ...
_logger.LogInformation("Image resizing done or not needed. Adding image {filePath} into the next pipe.", imageFilePath);
return imageFilePath;
}
Kommentar
Spring Integration Framework har en implementering av mönster för rör och filter.
Nästa steg
Följande resurser kan vara användbara när du implementerar det här mönstret:
- En demonstration av mönster för rör och filter med hjälp av bildbearbetningsscenariot finns på GitHub.
- Idempotensmönster, på Jonathan Olivers blogg.
Relaterade resurser
Följande mönster kan också vara relevanta när du implementerar det här mönstret:
- Mönster för anspråkskontroll. En pipeline som implementeras med hjälp av en kö kanske inte innehåller det faktiska objektet som skickas via filtren, utan en pekare till de data som behöver bearbetas. I exemplet används en anspråkskontroll i Azure Queue Storage för avbildningar som lagras i Azure Blob Storage.
- Mönster för konkurrerande förbrukare. En pipeline kan innehålla flera instanser av ett eller flera filter. Den här metoden är användbar för att köra parallella instanser av långsamma filter. Det gör att systemet kan sprida belastningen och förbättra dataflödet. Varje instans av ett filter konkurrerar om indata med de andra instanserna, men två instanser av ett filter bör inte kunna bearbeta samma data. I den här artikeln beskrivs metoden.
- Mönster för konsolidering av beräkningsresurser. Det kan vara möjligt att gruppera filter som ska skalas samman till en enda process. Den här artikeln innehåller mer information om fördelarna och kompromisserna med den här strategin.
- Kompenserande transaktionsmönster. Du kan implementera ett filter som en åtgärd som kan ångras eller som har en kompenserande åtgärd som återställer tillståndet till en tidigare version om det uppstår ett fel. Den här artikeln förklarar hur du kan implementera det här mönstret för att upprätthålla eller uppnå slutlig konsekvens.
- Pipes och filter – Företagsintegreringsmönster.