Översikt över generativa AI-gatewayfunktioner i Azure API Management
GÄLLER FÖR: Alla API Management-nivåer
Den här artikeln innehåller funktioner i Azure API Management som hjälper dig att hantera generativa AI-API:er, till exempel de som tillhandahålls av Azure OpenAI-tjänsten. Azure API Management tillhandahåller en rad principer, mått och andra funktioner för att förbättra säkerhet, prestanda och tillförlitlighet för API:er som betjänar dina intelligenta appar. Tillsammans kallas dessa funktioner för generativa AI-gatewayfunktioner (GenAI) för dina generativa AI-API:er.
Kommentar
- Den här artikeln fokuserar på funktioner för att hantera API:er som exponeras av Azure OpenAI Service. Många av GenAI-gatewayfunktionerna gäller för andra API:er för stor språkmodell (LLM), inklusive de som är tillgängliga via Azure AI Model Inference API.
- Generativa AI-gatewayfunktioner är funktioner i API Managements befintliga API-gateway, inte en separat API-gateway. Mer information om API Management finns i Översikt över Azure API Management.
Utmaningar med att hantera generativa AI-API:er
En av de viktigaste resurserna du har i generativa AI-tjänster är tokens. Azure OpenAI Service tilldelar kvoter för dina modelldistributioner uttryckta i token per minut (TPM) som sedan distribueras över dina modellkonsumenter – till exempel olika program, utvecklarteam, avdelningar inom företaget osv.
Azure gör det enkelt att ansluta en enskild app till Azure OpenAI Service: du kan ansluta direkt med hjälp av en API-nyckel med en TPM-gräns som konfigurerats direkt på modelldistributionsnivån. Men när du börjar utöka programportföljen visas flera appar som anropar enskilda eller till och med flera Azure OpenAI-tjänstslutpunkter som distribueras som PTU-instanser (Betala per användning) eller Etablerade dataflödesenheter (PTU). Det kommer med vissa utmaningar:
- Hur spåras tokenanvändning i flera program? Kan korsavgifter beräknas för flera program/team som använder Azure OpenAI Service-modeller?
- Hur ser du till att en enskild app inte förbrukar hela TPM-kvoten och lämnar andra appar utan möjlighet att använda Azure OpenAI Service-modeller?
- Hur distribueras API-nyckeln på ett säkert sätt i flera program?
- Hur distribueras belastningen över flera Azure OpenAI-slutpunkter? Kan du se till att den incheckade kapaciteten i PTU:er är uttömd innan du återgår till betala per användning-instanser?
Resten av den här artikeln beskriver hur Azure API Management kan hjälpa dig att hantera dessa utmaningar.
Importera Azure OpenAI Service-resursen som ett API
Importera ett API från en Azure OpenAI-tjänstslutpunkt till Azure API Management med en enkelklicksupplevelse. API Management effektiviserar registreringsprocessen genom att automatiskt importera OpenAPI-schemat för Azure OpenAI-API:et och konfigurerar autentisering till Azure OpenAI-slutpunkten med hjälp av hanterad identitet, vilket tar bort behovet av manuell konfiguration. Inom samma användarvänliga upplevelse kan du förkonfigurera principer för tokengränser och generera tokenmått.

Princip för tokenbegränsning
Konfigurera principen för gräns för Azure OpenAI-token för att hantera och framtvinga gränser per API-konsument baserat på användningen av Azure OpenAI-tjänsttoken. Med den här principen kan du ange gränser, uttryckta i token per minut (TPM).
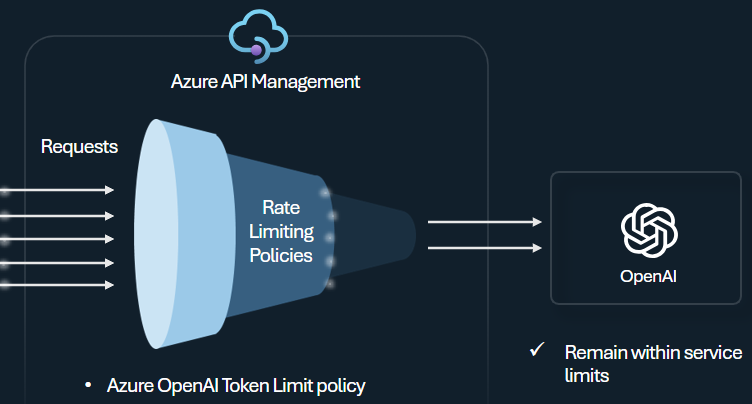
Den här principen ger flexibilitet att tilldela tokenbaserade gränser för alla räknarnycklar, till exempel prenumerationsnyckel, ursprunglig IP-adress eller en godtycklig nyckel som definierats via ett principuttryck. Principen möjliggör också förberäkning av prompttoken på Azure API Management-sidan, vilket minimerar onödiga begäranden till Azure OpenAI-tjänstens serverdel om kommandotolken redan överskrider gränsen.
Följande grundläggande exempel visar hur du anger en TPM-gräns på 500 per prenumerationsnyckel:
<azure-openai-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</azure-openai-token-limit>
Dricks
För att hantera och framtvinga tokengränser för LLM-API:er som är tillgängliga via Azure AI Model Inference API tillhandahåller API Management motsvarande llm-token-limit-policy .
Generera tokenmåttprincip
Azure OpenAI genererar tokenmåttprincipen skickar mått till Application Insights om förbrukning av LLM-token via Azure OpenAI-tjänst-API:er. Principen hjälper till att ge en översikt över användningen av Azure OpenAI-tjänstmodeller för flera program eller API-konsumenter. Den här principen kan vara användbar för återbetalningsscenarier, övervakning och kapacitetsplanering.
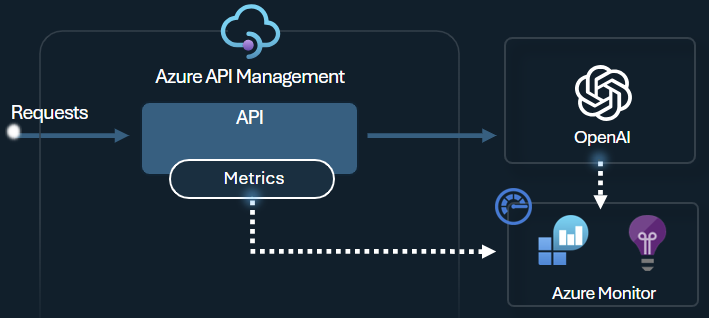
Den här principen samlar in mått för fråga, slutföranden och total tokenanvändning och skickar dem till ett Application Insights-namnområde som du väljer. Dessutom kan du konfigurera eller välja mellan fördefinierade dimensioner för att dela upp tokenanvändningsmått, så att du kan analysera mått efter prenumerations-ID, IP-adress eller en anpassad dimension som du väljer.
Följande princip skickar till exempel mått till Application Insights uppdelade efter klientens IP-adress, API och användare:
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
Dricks
Api Management tillhandahåller motsvarande llm-emit-token-metric-policy för att skicka mått för LLM-API:er som är tillgängliga via Azure AI Model Inference API.
Lastbalanserare för serverdel och kretsbrytare
En av utmaningarna när du skapar intelligenta program är att se till att programmen är motståndskraftiga mot serverdelsfel och kan hantera höga belastningar. Genom att konfigurera dina Azure OpenAI-tjänstslutpunkter med hjälp av serverdelar i Azure API Management kan du balansera belastningen mellan dem. Du kan också definiera regler för kretsbrytare för att sluta vidarebefordra begäranden till Azure OpenAI-tjänstens serverdelar om de inte svarar.
Serverdelslastbalanseraren stöder resursallokering, viktad och prioritetsbaserad belastningsutjämning, vilket ger dig flexibilitet att definiera en strategi för belastningsfördelning som uppfyller dina specifika krav. Definiera till exempel prioriteringar i lastbalanserarens konfiguration för att säkerställa optimal användning av specifika Azure OpenAI-slutpunkter, särskilt de som köpts som PTU:er.
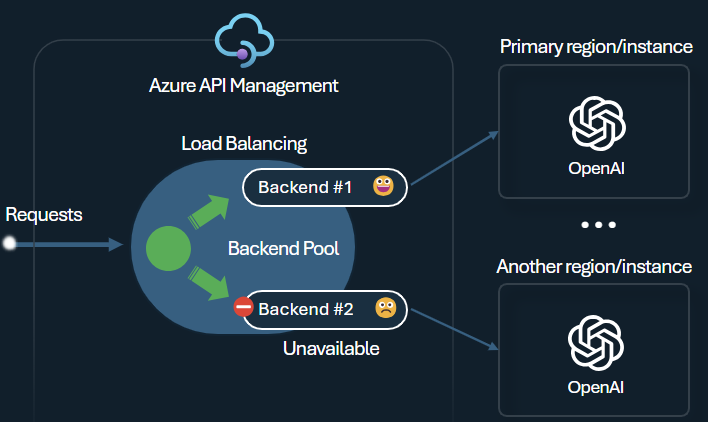
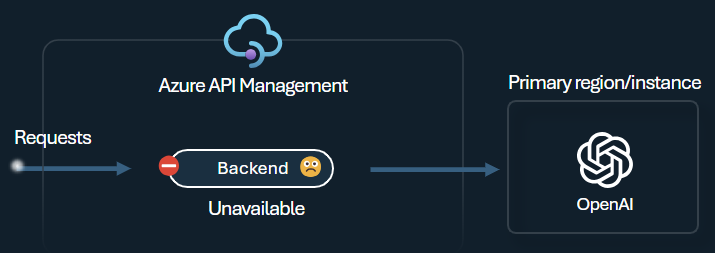
Serverdelskretsens brytare har dynamisk varaktighet för resan och tillämpar värden från återförsöks-efter-huvudet som tillhandahålls av serverdelen. Detta säkerställer exakt och snabb återställning av serverdelarna, vilket maximerar användningen av dina prioriterade serverdelar.
Princip för semantisk cachelagring
Konfigurera semantiska cachelagringsprinciper för Azure OpenAI för att optimera tokenanvändningen genom att lagra slutföranden för liknande frågor.
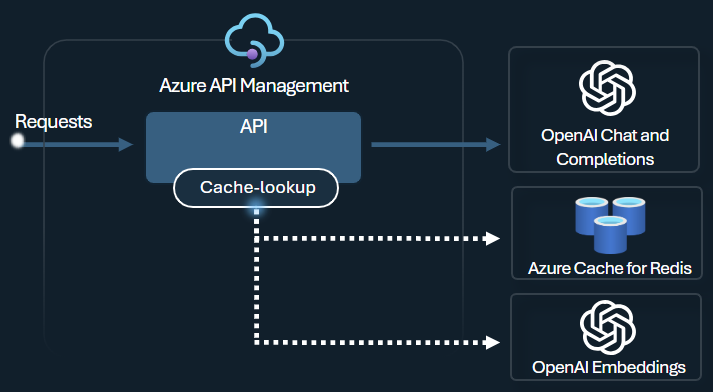
I API Management aktiverar du semantisk cachelagring med hjälp av Azure Redis Enterprise eller en annan extern cache som är kompatibel med RediSearch och registreras i Azure API Management. Med inbäddnings-API:et för Azure OpenAI-tjänsten kan du lagra azure-openai-semantic-cache-store och azure-openai-semantic-cache-lookup policies och hämta semantiskt liknande slutföranden av frågor från cacheminnet. Den här metoden säkerställer återanvändning av slutföranden, vilket resulterar i minskad tokenförbrukning och bättre svarsprestanda.
Dricks
För att aktivera semantisk cachelagring för LLM-API:er som är tillgängliga via AZURE AI Model Inference API tillhandahåller API Management motsvarande principer för llm-semantic-cache-store-policy och llm-semantic-cache-lookup-policy .
Labb och exempel
- Labb för GenAI-gatewayfunktionerna i Azure API Management
- Azure API Management (APIM) – Azure OpenAI-exempel (Node.js)
- Python-exempelkod för att använda Azure OpenAI med API Management
Arkitektur- och designöverväganden
- Referensarkitektur för GenAI-gateway med API Management
- Accelerator för AI Hub Gateway-landningszon
- Utforma och implementera en gateway-lösning med Azure OpenAI-resurser
- Använda en gateway framför flera Azure OpenAI-distributioner eller instanser
Relaterat innehåll
- Blogg: Introduktion till GenAI-funktioner i Azure API Management
- Blogg: Integrera Azure Content Safety med API Management för Azure OpenAI-slutpunkter
- Utbildning: Hantera dina generativa AI-API:er med Azure API Management
- Smart belastningsutjämning för OpenAI-slutpunkter och Azure API Management
- Autentisera och auktorisera åtkomst till Azure OpenAI-API:er med Hjälp av Azure API Management