Översikt över kluster autoskalning i Azure Kubernetes Service (AKS)
För att hänga med i programkraven i Azure Kubernetes Service (AKS) kan du behöva justera antalet noder som kör dina arbetsbelastningar. Komponenten autoskalning av kluster söker efter poddar i klustret som inte kan schemaläggas på grund av resursbegränsningar. När autoskalning av kluster identifierar oplanerade poddar skalar den upp antalet noder i nodpoolen för att uppfylla programbehovet. Den kontrollerar också regelbundet noder som inte har några schemalagda poddar och skalar ned antalet noder efter behov.
Den här artikeln hjälper dig att förstå hur autoskalning av kluster fungerar i AKS. Den innehåller också vägledning, metodtips och överväganden när du konfigurerar autoskalning av kluster för dina AKS-arbetsbelastningar. Om du vill aktivera, inaktivera eller uppdatera klustrets autoskalning för dina AKS-arbetsbelastningar läser du Använda autoskalning av kluster i AKS.
Om autoskalning av kluster
Kluster behöver ofta ett sätt att skala automatiskt för att anpassa sig till ändrade programkrav, till exempel mellan arbetsdagar och kvällar eller helger. AKS-kluster kan skalas på följande sätt:
- Autoskalning av kluster söker regelbundet efter poddar som inte kan schemaläggas på noder på grund av resursbegränsningar. Klustret ökar sedan automatiskt antalet noder. Manuell skalning inaktiveras när du använder autoskalning av kluster. Mer information finns i How does scale up work?.
- Den vågräta autoskalningen av poddar använder måttservern i ett Kubernetes-kluster för att övervaka resursefterfrågan för poddar. Om ett program behöver fler resurser ökar antalet poddar automatiskt för att möta efterfrågan.
- Autoskalning av lodrät podd anger automatiskt resursbegäranden och begränsningar för containrar per arbetsbelastning baserat på tidigare användning för att säkerställa att poddar schemaläggs till noder som har de processor- och minnesresurser som krävs.
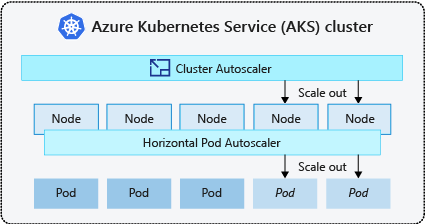
Det är vanligt att aktivera autoskalning av kluster för noder och antingen autoskalning av lodrät podd eller horisontell podd autoskalning för poddar. När du aktiverar autoskalning av kluster tillämpas de angivna skalningsreglerna när nodpoolens storlek är lägre än det minsta antalet noder, upp till det maximala antalet noder. Autoskalning av kluster väntar tills en ny nod behövs i nodpoolen eller tills en nod kan tas bort från den aktuella nodpoolen på ett säkert sätt. Mer information finns i Hur fungerar nedskalning?
Metodtips och överväganden
- När du implementerar tillgänglighetszoner med autoskalning av kluster rekommenderar vi att du använder en enda nodpool för varje zon. Du kan ange parametern
--balance-similar-node-groupstillTrueför att upprätthålla en balanserad fördelning av noder mellan zoner för dina arbetsbelastningar under uppskalningsåtgärder. När den här metoden inte implementeras kan nedskalningsåtgärder störa balansen mellan noder mellan zoner. - För kluster med fler än 400 noder rekommenderar vi att du använder Azure CNI eller Azure CNI Overlay.
- Om du vill köra arbetsbelastningar samtidigt på både spot- och fast nodpooler bör du överväga att använda prioritetsexpanmerare. Med den här metoden kan du schemalägga poddar baserat på nodpoolens prioritet.
- Var försiktig när du tilldelar cpu-/minnesbegäranden på poddar. Autoskalning av kluster skalas upp baserat på väntande poddar i stället för CPU-/minnesbelastning på noder.
- För kluster som samtidigt är värdar för både långvariga arbetsbelastningar, t.ex. webbappar och korta/bursty-jobbarbetsbelastningar, rekommenderar vi att du separerar dem i distinkta nodpooler med tillhörighetsregler/expanderare eller använder PodDisruptionBudget för att förhindra onödig nodavlopp eller nedskalningsåtgärder. Om du anger kommentaren cluster-autoscaler.kubernetes.io/safe-to-evict: "false" i poddspecifikationen förhindras även poddarna från att avlägsnas. Använd den här kommentaren med försiktighet eftersom det kan orsaka problem med autoskalning av kluster när en nod töms med en podd som körs som innehåller den här kommentaren.
- I en autoskalningsaktiverad nodpool skalar du ned noder genom att ta bort arbetsbelastningar i stället för att minska antalet noder manuellt. Detta kan vara problematiskt om nodpoolen redan har maximal kapacitet eller om det finns aktiva arbetsbelastningar som körs på noderna, vilket kan orsaka oväntat beteende av klustrets autoskalning.
- Noder skalas inte upp om poddar har ett PriorityClass-värde under -10. Prioritet -10 är reserverad för överetablering av poddar. Mer information finns i Använda autoskalning av kluster med poddprioritet och preemption.
- Kombinera inte andra autoskalningsmekanismer för noder, till exempel autoskalning av vm-skalningsuppsättningar, med autoskalning av kluster.
- Autoskalning av kluster kanske inte kan skalas ned om poddar inte kan flyttas, till exempel i följande situationer:
- En direkt skapad podd som inte backas upp av ett kontrollantobjekt, till exempel en distribution eller replikuppsättning.
- En budget för poddstörningar (PDB) som är för restriktiv och inte tillåter att antalet poddar hamnar under ett visst tröskelvärde.
- En podd använder nodväljare eller antitillhörighet som inte kan respekteras om de schemaläggs på en annan nod. Mer information finns i Vilka typer av poddar kan förhindra att klustrets autoskalning tar bort en nod?.
Viktigt!
Gör inga ändringar i enskilda noder i nodpoolerna för autoskalning. Alla noder i samma nodgrupp bör ha enhetlig kapacitet, etiketter, taints och systempoddar som körs på dem.
- Autoskalning av kluster ansvarar inte för att framtvinga "maximalt antal noder" i en klusternodpool oavsett överväganden vid poddschemaläggning. Om någon icke-klusterbaserad autoskalningsskådespelare anger antalet nodpooler till ett tal utöver klustrets autoskalningsinställning tar autoskalning av kluster inte automatiskt bort noder. Funktionerna för skalning av kluster autoskalning förblir begränsade till att endast ta bort noder som inte har några schemalagda poddar. Det enda syftet med autoskalningskonfigurationen för kluster autoskalning är att framtvinga en övre gräns för uppskalningsåtgärder. Det har ingen effekt på skalningsöverväganden.
Autoskalningsprofil för kluster
Autoskalningsprofilen för kluster är en uppsättning parametrar som styr beteendet för klustrets autoskalning. Du kan konfigurera autoskalningsprofilen för klustret när du skapar ett kluster eller uppdaterar ett befintligt kluster.
Optimera autoskalningsprofilen för kluster
Du bör finjustera profilinställningarna för autoskalning av kluster enligt dina specifika arbetsbelastningsscenarier samtidigt som du överväger kompromisser mellan prestanda och kostnad. Det här avsnittet innehåller exempel som visar dessa kompromisser.
Observera att profilinställningarna för autoskalning av kluster är klusteromfattande och tillämpas på alla autoskalningsaktiverade nodpooler. Alla skalningsåtgärder som utförs i en nodpool kan påverka autoskalningsbeteendet för andra nodpooler, vilket kan leda till oväntade resultat. Kontrollera att du använder konsekventa och synkroniserade profilkonfigurationer i alla relevanta nodpooler för att säkerställa att du får önskat resultat.
Exempel 1: Optimera prestanda
För kluster som hanterar stora och höga arbetsbelastningar med primärt fokus på prestanda rekommenderar vi att du ökar scan-interval och minskar scale-down-utilization-threshold. De här inställningarna hjälper till att batcha flera skalningsåtgärder i ett enda anrop, vilket optimerar skalningstiden och användningen av läs-/skrivkvoter för beräkning. Det bidrar också till att minska risken för snabba nedskalningsåtgärder på underutnyttjanade noder, vilket förbättrar poddschemaläggningens effektivitet. ok-total-unready-countÖka också och max-total-unready-percentage.
För kluster med daemonset-poddar rekommenderar vi inställningen ignore-daemonsets-utilization till true, som effektivt ignorerar nodanvändning av daemonset-poddar och minimerar onödiga nedskalningsåtgärder. Se profil för bursty-arbetsbelastningar
Exempel 2: Optimera för kostnad
Om du vill ha en kostnadsoptimerad profil rekommenderar vi att du anger följande parameterkonfigurationer:
- Reduce
scale-down-unneeded-time, vilket är hur lång tid en nod ska behövas innan den är berättigad till nedskalning. - Reduce
scale-down-delay-after-add, vilket är hur lång tid det tar att vänta efter att en nod har lagts till innan du överväger att skala ned den. - Öka
scale-down-utilization-threshold, vilket är användningströskelvärdet för att ta bort noder. - Öka
max-empty-bulk-delete, vilket är det maximala antalet noder som kan tas bort i ett enda anrop. - Ställ in
skip-nodes-with-local-storagepå false. - Öka
ok-total-unready-countochmax-total-unready-percentage.
Vanliga problem och minskningsrekommendationer
Visa skalningsfel och uppskalning av händelser som inte utlösts via CLI eller portalen.
Utlöser inte uppskalningsåtgärder
| Vanliga orsaker | Rekommendationer för minskning |
|---|---|
| PersistentVolume-nodtillhörighetskonflikter, som kan uppstå när du använder klustrets autoskalning med flera tillgänglighetszoner eller när en podds eller beständiga volymzon skiljer sig från nodens zon. | Använd en nodpool per tillgänglighetszon och aktivera --balance-similar-node-groups. Du kan också ange fältet volumeBindingMode till WaitForFirstConsumer i poddspecifikationen för att förhindra att volymen binds till en nod tills en podd som använder volymen har skapats. |
| Taints- och Toleranser/Nodtillhörighetskonflikter | Utvärdera de taints som tilldelats dina noder och granska de toleranser som definierats i dina poddar. Om det behövs kan du göra justeringar i taints och toleranser för att säkerställa att dina poddar kan schemaläggas effektivt på noderna. |
Fel vid uppskalningsåtgärd
| Vanliga orsaker | Rekommendationer för minskning |
|---|---|
| IP-adressöverbelastning i undernätet | Lägg till ytterligare ett undernät i samma virtuella nätverk och lägg till ytterligare en nodpool i det nya undernätet. |
| Överbelastning av kärnkvoter | Den godkända kärnkvoten har uttömts. Begär en kvotökning. Autoskalning av kluster anger ett exponentiellt backoff-tillstånd i den specifika nodgruppen när det uppstår flera misslyckade uppskalningsförsök. |
| Maximal storlek på nodpoolen | Öka maxnoderna i nodpoolen eller skapa en ny nodpool. |
| Begäranden/anrop som överskrider hastighetsgränsen | Se fel med 429 för många begäranden. |
Fel vid nedskalningsåtgärd
| Vanliga orsaker | Rekommendationer för minskning |
|---|---|
| Podd som förhindrar nodavlopp/Det går inte att ta bort podden | • Visa vilka typer av poddar som kan förhindra nedskalning. • För poddar som använder lokal lagring, till exempel hostPath och emptyDir, anger du flaggan skip-nodes-with-local-storage för autoskalningsprofil för kluster till false. • I poddspecifikationen anger du kommentaren cluster-autoscaler.kubernetes.io/safe-to-evict till true. • Kontrollera ditt PDB eftersom det kan vara restriktivt. |
| Minsta storlek på nodpool | Minska nodpoolens minsta storlek. |
| Begäranden/anrop som överskrider hastighetsgränsen | Se fel med 429 för många begäranden. |
| Skrivåtgärder låsta | Gör inga ändringar i den fullständigt hanterade AKS-resursgruppen (se AKS-supportprinciper). Ta bort eller återställa eventuella resurslås som du tidigare tillämpade på resursgruppen. |
Andra problem
| Vanliga orsaker | Rekommendationer för minskning |
|---|---|
| PriorityConfigMapNotMatchedGroup | Se till att du lägger till alla nodgrupper som kräver automatisk skalning i expanderkonfigurationsfilen. |
Nodpool i backoff
Nodpoolen i backoff introducerades i version 0.6.2 och gör att klustrets autoskalning säkerhetskopieras från skalning av en nodpool efter ett fel.
Beroende på hur länge skalningsåtgärderna har haft fel kan det ta upp till 30 minuter innan du gör ett nytt försök. Du kan återställa nodpoolens backoff-tillstånd genom att inaktivera och sedan återaktivera automatisk skalning.

Azure Kubernetes Service