Självstudie: Del 3 – Utvärdera ett anpassat chattprogram med Azure AI Foundry SDK
I den här självstudien använder du Azure AI SDK (och andra bibliotek) för att utvärdera chattappen som du skapade i del 2 i självstudieserien. I den här del tre får du lära dig att:
- Skapa en utvärderingsdatauppsättning
- Utvärdera chattappen med Azure AI-utvärderare
- Iterera och förbättra din app
Den här självstudien är del tre i en självstudie i tre delar.
Förutsättningar
- Slutför del 2 i självstudieserien för att skapa chattprogrammet.
- Kontrollera att du har slutfört stegen för att lägga till telemetriloggning från del 2.
Utvärdera kvaliteten på chattappens svar
Nu när du vet att chattappen svarar bra på dina frågor, bland annat med chatthistorik, är det dags att utvärdera hur den gör i några olika mått och mer data.
Du använder en utvärderare med en utvärderingsdatauppsättning och målfunktionen och get_chat_response() utvärderar sedan utvärderingsresultaten.
När du har kört en utvärdering kan du sedan förbättra din logik, till exempel förbättra systemprompten och observera hur chattappens svar ändras och förbättras.
Skapa en utvärderingsdatauppsättning
Använd följande utvärderingsdatauppsättning, som innehåller exempelfrågor och förväntade svar (sanning).
Skapa en fil med namnet chat_eval_data.jsonl i mappen tillgångar.
Klistra in den här datamängden i filen:
{"query": "Which tent is the most waterproof?", "truth": "The Alpine Explorer Tent has the highest rainfly waterproof rating at 3000m"} {"query": "Which camping table holds the most weight?", "truth": "The Adventure Dining Table has a higher weight capacity than all of the other camping tables mentioned"} {"query": "How much do the TrailWalker Hiking Shoes cost? ", "truth": "The Trailewalker Hiking Shoes are priced at $110"} {"query": "What is the proper care for trailwalker hiking shoes? ", "truth": "After each use, remove any dirt or debris by brushing or wiping the shoes with a damp cloth."} {"query": "What brand is TrailMaster tent? ", "truth": "OutdoorLiving"} {"query": "How do I carry the TrailMaster tent around? ", "truth": " Carry bag included for convenient storage and transportation"} {"query": "What is the floor area for Floor Area? ", "truth": "80 square feet"} {"query": "What is the material for TrailBlaze Hiking Pants?", "truth": "Made of high-quality nylon fabric"} {"query": "What color does TrailBlaze Hiking Pants come in?", "truth": "Khaki"} {"query": "Can the warrenty for TrailBlaze pants be transfered? ", "truth": "The warranty is non-transferable and applies only to the original purchaser of the TrailBlaze Hiking Pants. It is valid only when the product is purchased from an authorized retailer."} {"query": "How long are the TrailBlaze pants under warranty for? ", "truth": " The TrailBlaze Hiking Pants are backed by a 1-year limited warranty from the date of purchase."} {"query": "What is the material for PowerBurner Camping Stove? ", "truth": "Stainless Steel"} {"query": "Is France in Europe?", "truth": "Sorry, I can only queries related to outdoor/camping gear and equipment"}
Utvärdera med Azure AI-utvärderare
Definiera nu ett utvärderingsskript som ska:
- Generera en målfunktionsomslutning runt vår chattapplogik.
- Läs in exempeldatauppsättningen
.jsonl. - Kör utvärderingen, som tar målfunktionen, och sammanfogar utvärderingsdatauppsättningen med svaren från chattappen.
- Generera en uppsättning GPT-assisterade mått (relevans, grundinställning och konsekvens) för att utvärdera kvaliteten på chattappens svar.
- Mata ut resultaten lokalt och logga resultatet till molnprojektet.
Med skriptet kan du granska resultaten lokalt genom att mata ut resultaten på kommandoraden och till en json-fil.
Skriptet loggar även utvärderingsresultatet till molnprojektet så att du kan jämföra utvärderingskörningar i användargränssnittet.
Skapa en fil med namnet evaluate.py i huvudmappen.
Lägg till följande kod för att importera de bibliotek som krävs, skapa en projektklient och konfigurera vissa inställningar:
import os import pandas as pd from azure.ai.projects import AIProjectClient from azure.ai.projects.models import ConnectionType from azure.ai.evaluation import evaluate, GroundednessEvaluator from azure.identity import DefaultAzureCredential from chat_with_products import chat_with_products # load environment variables from the .env file at the root of this repo from dotenv import load_dotenv load_dotenv() # create a project client using environment variables loaded from the .env file project = AIProjectClient.from_connection_string( conn_str=os.environ["AIPROJECT_CONNECTION_STRING"], credential=DefaultAzureCredential() ) connection = project.connections.get_default(connection_type=ConnectionType.AZURE_OPEN_AI, include_credentials=True) evaluator_model = { "azure_endpoint": connection.endpoint_url, "azure_deployment": os.environ["EVALUATION_MODEL"], "api_version": "2024-06-01", "api_key": connection.key, } groundedness = GroundednessEvaluator(evaluator_model)Lägg till kod för att skapa en omslutningsfunktion som implementerar utvärderingsgränssnittet för utvärdering av frågor och svar:
def evaluate_chat_with_products(query): response = chat_with_products(messages=[{"role": "user", "content": query}]) return {"response": response["message"].content, "context": response["context"]["grounding_data"]}Lägg slutligen till kod för att köra utvärderingen, visa resultatet lokalt och ge dig en länk till utvärderingsresultaten i Azure AI Foundry-portalen:
# Evaluate must be called inside of __main__, not on import if __name__ == "__main__": from config import ASSET_PATH # workaround for multiprocessing issue on linux from pprint import pprint from pathlib import Path import multiprocessing import contextlib with contextlib.suppress(RuntimeError): multiprocessing.set_start_method("spawn", force=True) # run evaluation with a dataset and target function, log to the project result = evaluate( data=Path(ASSET_PATH) / "chat_eval_data.jsonl", target=evaluate_chat_with_products, evaluation_name="evaluate_chat_with_products", evaluators={ "groundedness": groundedness, }, evaluator_config={ "default": { "query": {"${data.query}"}, "response": {"${target.response}"}, "context": {"${target.context}"}, } }, azure_ai_project=project.scope, output_path="./myevalresults.json", ) tabular_result = pd.DataFrame(result.get("rows")) pprint("-----Summarized Metrics-----") pprint(result["metrics"]) pprint("-----Tabular Result-----") pprint(tabular_result) pprint(f"View evaluation results in AI Studio: {result['studio_url']}")
Konfigurera utvärderingsmodellen
Eftersom utvärderingsskriptet anropar modellen många gånger kanske du vill öka antalet token per minut för utvärderingsmodellen.
I del 1 av den här självstudieserien skapade du en .env-fil som anger namnet på utvärderingsmodellen, gpt-4o-mini. Försök att öka gränsen för token per minut för den här modellen om du har en tillgänglig kvot. Oroa dig inte om du inte har tillräckligt med kvot för att öka värdet. Skriptet är utformat för att hantera gränsfel.
- I projektet i Azure AI Foundry-portalen väljer du Modeller + slutpunkter.
- Välj gpt-4o-mini.
- Välj Redigera.
- Om du har en kvot för att öka gränsen för token per minut kan du försöka öka den till 30.
- Välj Spara och stäng.
Kör utvärderingsskriptet
Logga in på ditt Azure-konto med Azure CLI från konsolen:
az loginInstallera det nödvändiga paketet:
pip install azure-ai-evaluationKör nu utvärderingsskriptet:
python evaluate.py
Tolka utvärderingsutdata
I konsolens utdata visas ett svar för varje fråga, följt av en tabell med sammanfattade mått. (Du kan se olika kolumner i dina utdata.)
Om du inte kunde öka gränsen för token per minut för din modell kanske du ser några timeout-fel som förväntas. Utvärderingsskriptet är utformat för att hantera dessa fel och fortsätta att köras.
Kommentar
Du kan också se många WARNING:opentelemetry.attributes: – dessa kan ignoreras på ett säkert sätt och påverkar inte utvärderingsresultaten.
====================================================
'-----Summarized Metrics-----'
{'groundedness.gpt_groundedness': 1.6666666666666667,
'groundedness.groundedness': 1.6666666666666667}
'-----Tabular Result-----'
outputs.response ... line_number
0 Could you specify which tent you are referring... ... 0
1 Could you please specify which camping table y... ... 1
2 Sorry, I only can answer queries related to ou... ... 2
3 Could you please clarify which aspects of care... ... 3
4 Sorry, I only can answer queries related to ou... ... 4
5 The TrailMaster X4 Tent comes with an included... ... 5
6 (Failed) ... 6
7 The TrailBlaze Hiking Pants are crafted from h... ... 7
8 Sorry, I only can answer queries related to ou... ... 8
9 Sorry, I only can answer queries related to ou... ... 9
10 Sorry, I only can answer queries related to ou... ... 10
11 The PowerBurner Camping Stove is designed with... ... 11
12 Sorry, I only can answer queries related to ou... ... 12
[13 rows x 8 columns]
('View evaluation results in Azure AI Foundry portal: '
'https://xxxxxxxxxxxxxxxxxxxxxxx')
Visa utvärderingsresultat i Azure AI Foundry-portalen
När utvärderingskörningen är klar följer du länken för att visa utvärderingsresultaten på sidan Utvärdering i Azure AI Foundry-portalen.
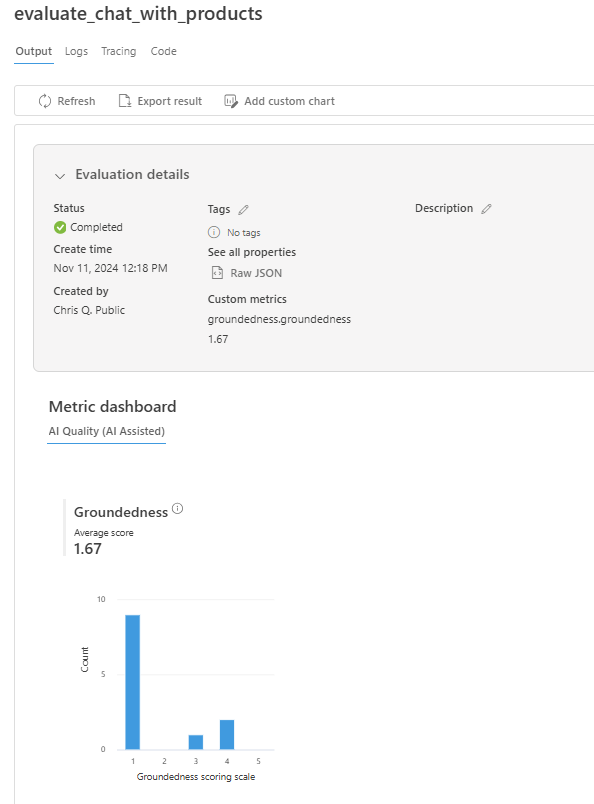
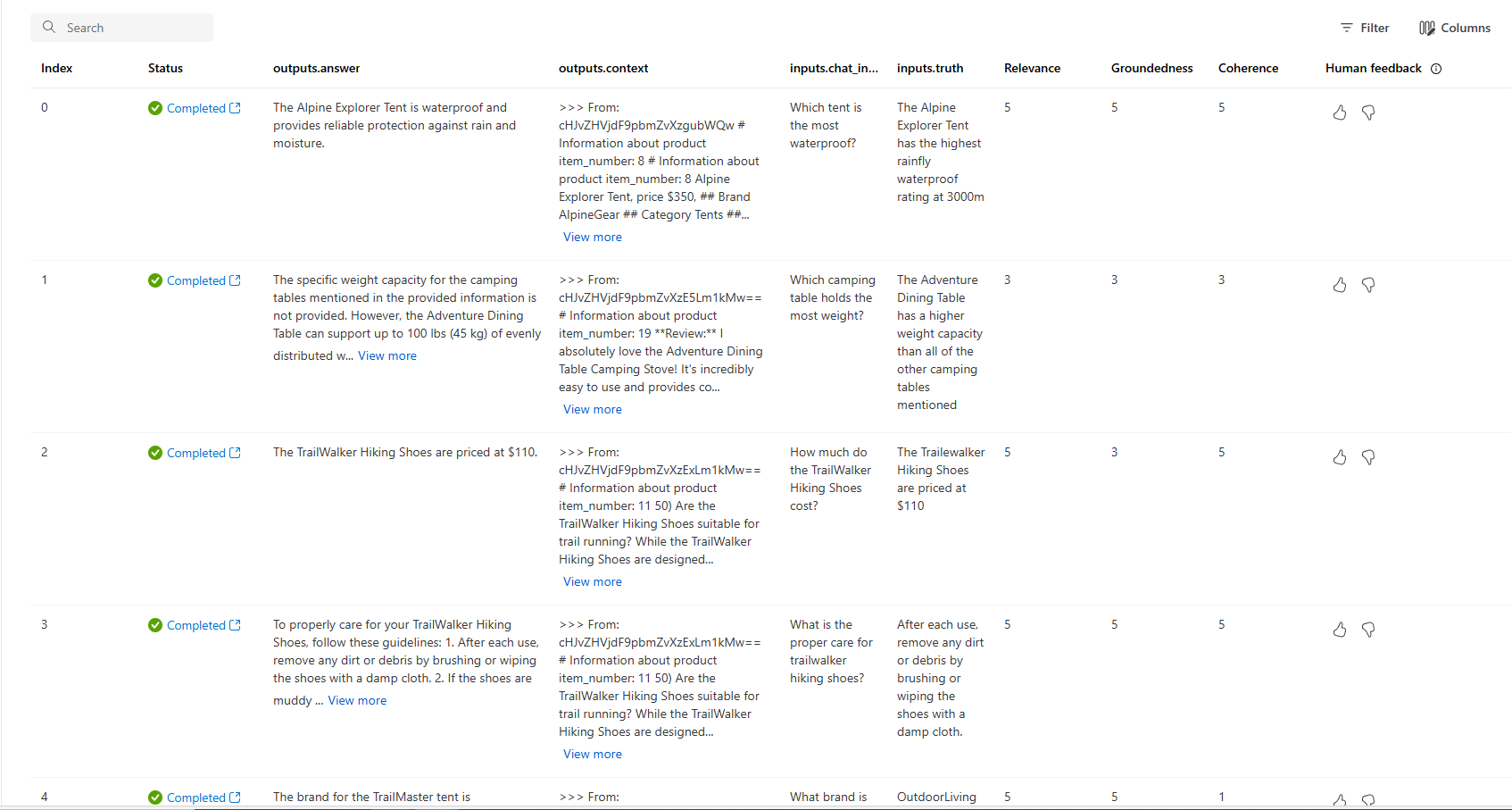
Du kan också titta på de enskilda raderna och se måttpoäng per rad och visa hela kontexten/dokumenten som hämtades. Dessa mått kan vara användbara för att tolka och felsöka utvärderingsresultat.
Mer information om utvärderingsresultat i Azure AI Foundry-portalen finns i Så här visar du utvärderingsresultat i Azure AI Foundry-portalen.
Iterera och förbättra
Observera att svaren inte är väl förankrade. I många fall svarar modellen med en fråga snarare än ett svar. Detta är ett resultat av anvisningarna för promptmallen.
- I filen assets/grounded_chat.prompty hittar du meningen "Om frågan är relaterad till utomhus/campingutrustning och kläder men vag, be om klargörande frågor istället för att referera till dokument."
- Ändra meningen till "Om frågan är relaterad till utomhus/ campingutrustning och kläder men vag, försök att svara baserat på referensdokumenten och be om klargörande frågor."
- Spara filen och kör utvärderingsskriptet igen.
Prova andra ändringar i promptmallen eller prova olika modeller för att se hur ändringarna påverkar utvärderingsresultatet.
Rensa resurser
För att undvika onödiga Azure-kostnader bör du ta bort de resurser som du skapade i den här självstudien om de inte längre behövs. Om du vill hantera resurser kan du använda Azure Portal.