Övervaka kvalitet och tokenanvändning för distribuerade program för promptflöde
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Övervakning av program som distribueras till produktion är en viktig del av den generativa AI-programlivscykeln. Ändringar i data och konsumentbeteenden kan påverka ditt program över tid, vilket resulterar i inaktuella system som negativt påverkar affärsresultat och utsätter organisationer för efterlevnadsrisker, ekonomiska risker och ryktesrisker.
Kommentar
Om du vill ha ett bättre sätt att utföra kontinuerlig övervakning av distribuerade program (förutom promptflöde) bör du överväga att använda Azure AI Online-utvärdering.
Med Azure AI-övervakning för generativa AI-program kan du övervaka dina program i produktion för tokenanvändning, produktionskvalitet och driftmått.
Med integreringar för övervakning av en distribution av ett promptflöde kan du:
- Samla in produktionsinferensdata från ditt distribuerade promptflödesprogram.
- Tillämpa mått för ansvarsfull AI-utvärdering, till exempel grund, konsekvens, flyt och relevans, som är kompatibla med mått för snabbflödesutvärdering.
- Övervaka prompter, slutförande och total tokenanvändning för varje modelldistribution i ditt promptflöde.
- Övervaka driftmått, till exempel antal förfrågningar, svarstid och felfrekvens.
- Använd förkonfigurerade aviseringar och standardvärden för att köra övervakning regelbundet.
- Använda datavisualiseringar och konfigurera avancerat beteende i Azure AI Foundry-portalen.
Förutsättningar
Innan du följer stegen i den här artikeln kontrollerar du att du har följande förutsättningar:
En Azure-prenumeration med en giltig betalningsmetod. Kostnadsfria azure-prenumerationer eller utvärderingsprenumerationer stöds inte för det här scenariot. Om du inte har en Azure-prenumeration skapar du ett betalt Azure-konto för att börja.
Ett promptflöde som är redo för distribution. Om du inte har något läser du Utveckla ett promptflöde.
Rollbaserade åtkomstkontroller i Azure (Azure RBAC) används för att ge åtkomst till åtgärder i Azure AI Foundry-portalen. Om du vill utföra stegen i den här artikeln måste ditt användarkonto tilldelas rollen Azure AI Developer i resursgruppen. Mer information om behörigheter finns i Rollbaserad åtkomstkontroll i Azure AI Foundry-portalen.
Krav för övervakning av mått
Övervakningsmått genereras av vissa toppmoderna GPT-språkmodeller som konfigurerats med specifika utvärderingsinstruktioner (promptmallar). Dessa modeller fungerar som utvärderarmodeller för sekvens-till-sekvens-uppgifter. Användning av den här tekniken för att generera övervakningsmått visar starka empiriska resultat och hög korrelation med mänsklig bedömning jämfört med standardmått för generativ AI-utvärdering. Mer information om utvärdering av promptflöde finns i skicka masstest och utvärdera ett flöde och utvärderings- och övervakningsmått för generativ AI.
DE GPT-modeller som genererar övervakningsmått är följande. Dessa GPT-modeller stöds med övervakning och konfigureras som din Azure OpenAI-resurs:
- GPT-3.5 Turbo
- GPT-4
- GPT-4-32k
Mått som stöds för övervakning
Följande mått stöds för övervakning:
| Mätvärde | Beskrivning |
|---|---|
| Grundstötning | Mäter hur väl modellens genererade svar överensstämmer med information från källdata (användardefinierad kontext.) |
| Relevans | Mäter i vilken utsträckning modellens genererade svar är relevanta och direkt relaterade till de aktuella frågorna. |
| Koherens | Mäter i vilken utsträckning modellens genererade svar är logiskt konsekventa och anslutna. |
| Flyt | Mäter den grammatiska kompetensen hos en generativ AI:s förutsagda svar. |
Mappning av kolumnnamn
När du skapar flödet måste du se till att kolumnnamnen mappas. Följande kolumnnamn för indata används för att mäta genereringens säkerhet och kvalitet:
| Namn på indatakolumn | Definition | Obligatoriskt/valfritt |
|---|---|---|
| Fråga | Den ursprungliga prompten (kallas även "indata" eller "fråga") | Obligatoriskt |
| Svar | Det slutliga slutförandet från API-anropet som returneras (kallas även "utdata" eller "svar") | Obligatoriskt |
| Kontext | Alla kontextdata som skickas till API-anropet, tillsammans med den ursprungliga prompten. Om du till exempel bara vill hämta sökresultat från vissa certifierade informationskällor eller webbplatser kan du definiera den här kontexten i utvärderingsstegen. | Valfritt |
Parametrar som krävs för mått
Parametrarna som är konfigurerade i datatillgången avgör vilka mått du kan producera, enligt den här tabellen:
| Mått | Fråga | Svar | Kontext |
|---|---|---|---|
| Koherens | Obligatoriskt | Obligatoriskt | - |
| Flyt | Obligatoriskt | Obligatoriskt | - |
| Grundstötning | Obligatoriskt | Obligatoriskt | Obligatoriskt |
| Relevans | Obligatoriskt | Obligatoriskt | Obligatoriskt |
Mer information om specifika datamappningskrav för varje mått finns i Krav för fråge- och svarsmått.
Konfigurera övervakning för promptflöde
Om du vill konfigurera övervakning för ditt program för promptflöde måste du först distribuera ditt prompt flow-program med slutsatsdragning av datainsamling, sedan kan du konfigurera övervakning för det distribuerade programmet.
Distribuera ditt program för promptflöde med slutsatsdragning av datainsamling
I det här avsnittet lär du dig att distribuera ditt promptflöde med inferensdatainsamling aktiverad. Detaljerad information om hur du distribuerar ditt promptflöde finns i Distribuera ett flöde för slutsatsdragning i realtid.
Logga in på Azure AI Foundry.
Om du inte redan är med i projektet väljer du det.
Välj Fråga flöde i det vänstra navigeringsfältet.
Välj det promptflöde som du skapade tidigare.
Kommentar
Den här artikeln förutsätter att du redan har skapat ett promptflöde som är redo för distribution. Om du inte har något läser du Utveckla ett promptflöde.
Bekräfta att flödet körs korrekt och att nödvändiga indata och utdata har konfigurerats för de mått som du vill utvärdera.
Om du anger de minsta obligatoriska parametrarna (fråga/indata och svar/utdata) får du bara två mått: konsekvens och flyt. Du måste konfigurera ditt flöde enligt beskrivningen i avsnittet krav för övervakningsmått. I det här exemplet används (
questionfråga) ochchat_history(kontext) som flödesindata ochanswer(Svar) som flödesutdata.Välj Distribuera för att börja distribuera flödet.
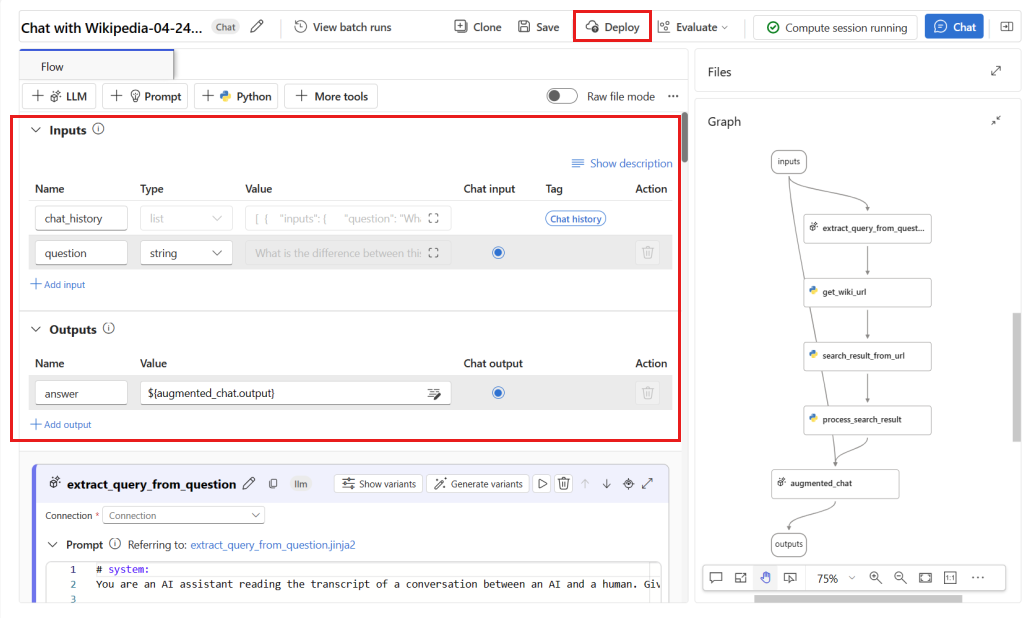
I distributionsfönstret ser du till att Inferencing-datainsamling är aktiverat, vilket sömlöst samlar in programmets slutsatsdragningsdata till Blob Storage. Den här datainsamlingen krävs för övervakning.
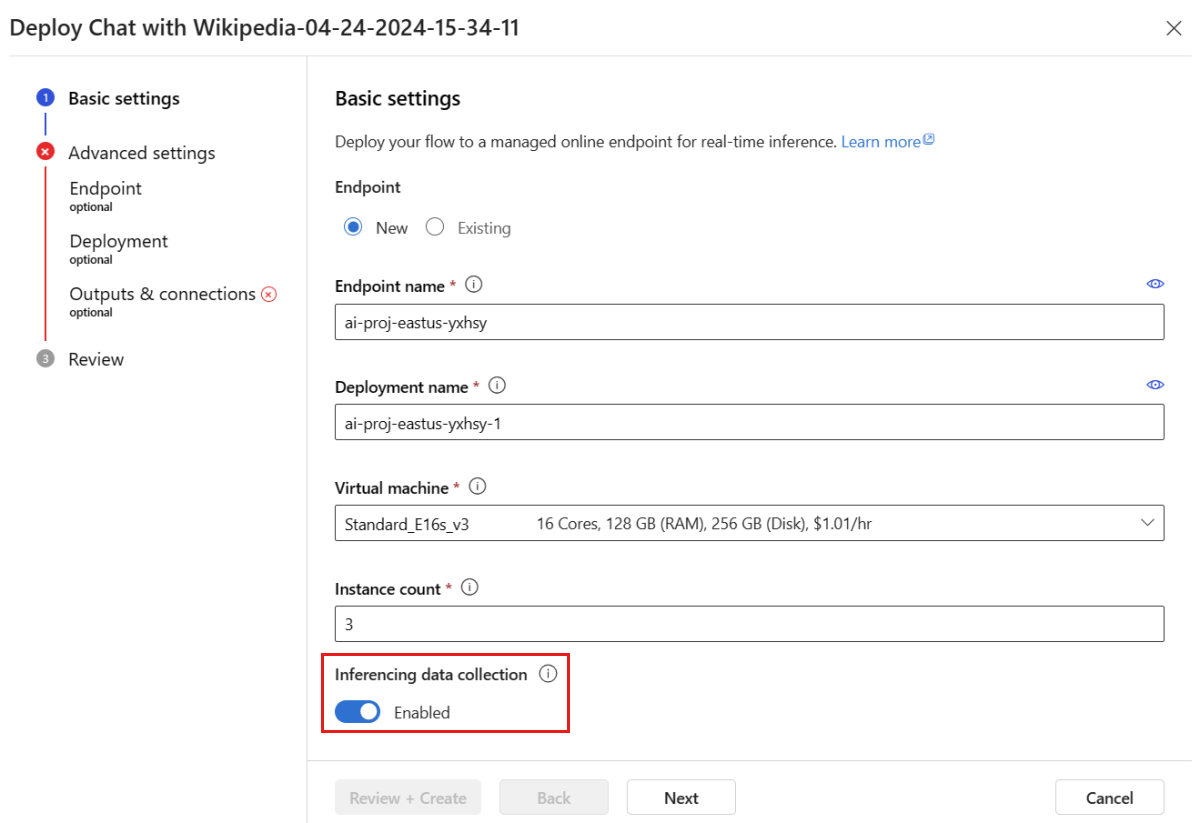
Gå igenom stegen i distributionsfönstret för att slutföra de avancerade inställningarna.
På sidan Granska granskar du distributionskonfigurationen och väljer Skapa för att distribuera flödet.
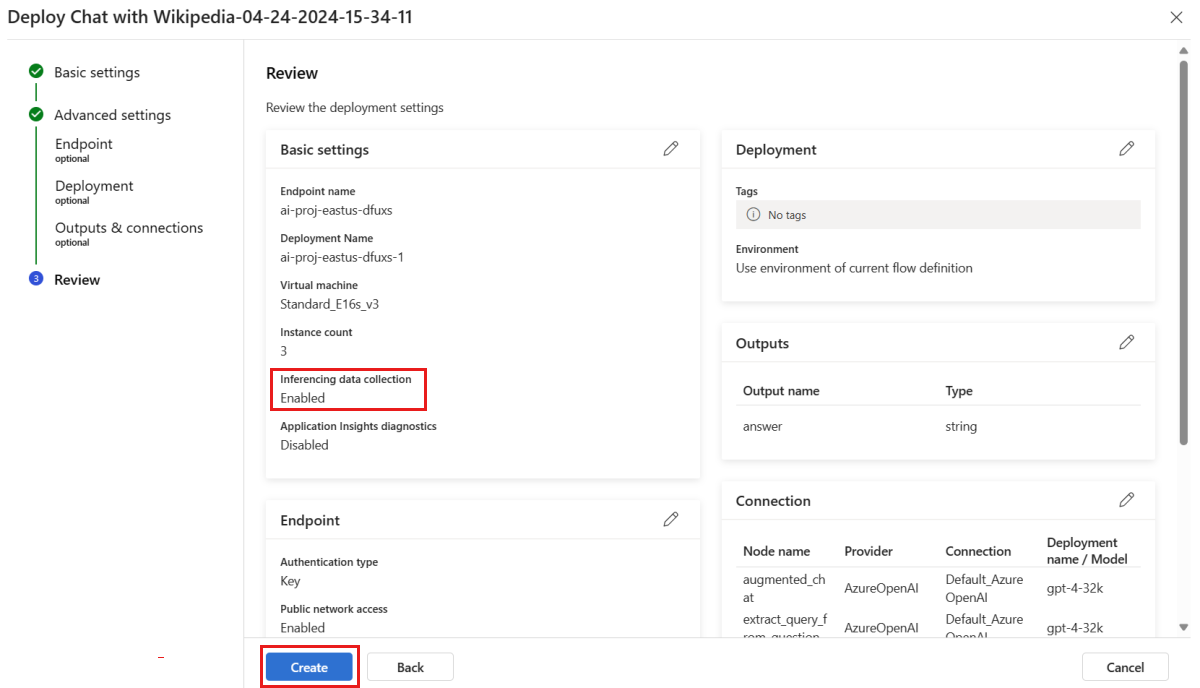
Kommentar
Som standard samlas alla indata och utdata från ditt distribuerade promptflödesprogram in till bloblagringen. När distributionen anropas av användare samlas data in för att användas av övervakaren.
Välj fliken Test på distributionssidan och testa distributionen för att säkerställa att den fungerar korrekt.
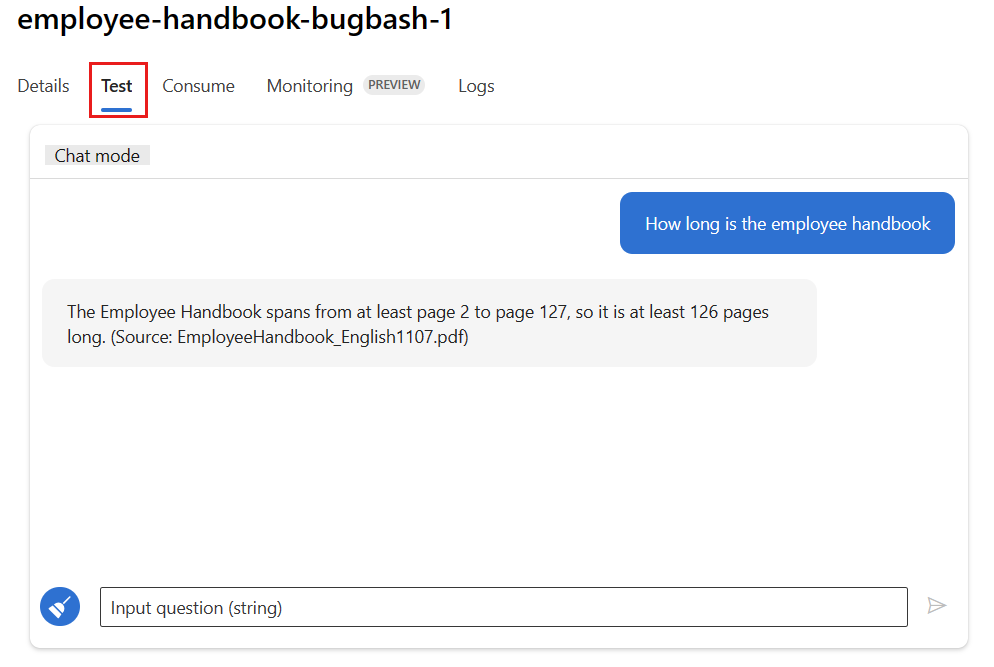
Kommentar
Övervakning kräver att minst en datapunkt kommer från en annan källa än fliken Test i distributionen. Vi rekommenderar att du använder rest-API:et som är tillgängligt på fliken Förbruka för att skicka exempelbegäranden till distributionen. Mer information om hur du skickar exempelbegäranden till distributionen finns i Skapa en onlinedistribution.




Konfigurera övervakning
I det här avsnittet får du lära dig hur du konfigurerar övervakning för ditt distribuerade promptflödesprogram.
I det vänstra navigeringsfältet går du till Mina tillgångar>Modeller + slutpunkter.
Välj den distribution av promptflöde som du skapade.
Välj Aktivera i rutan Aktivera kvalitetsövervakning för generation.
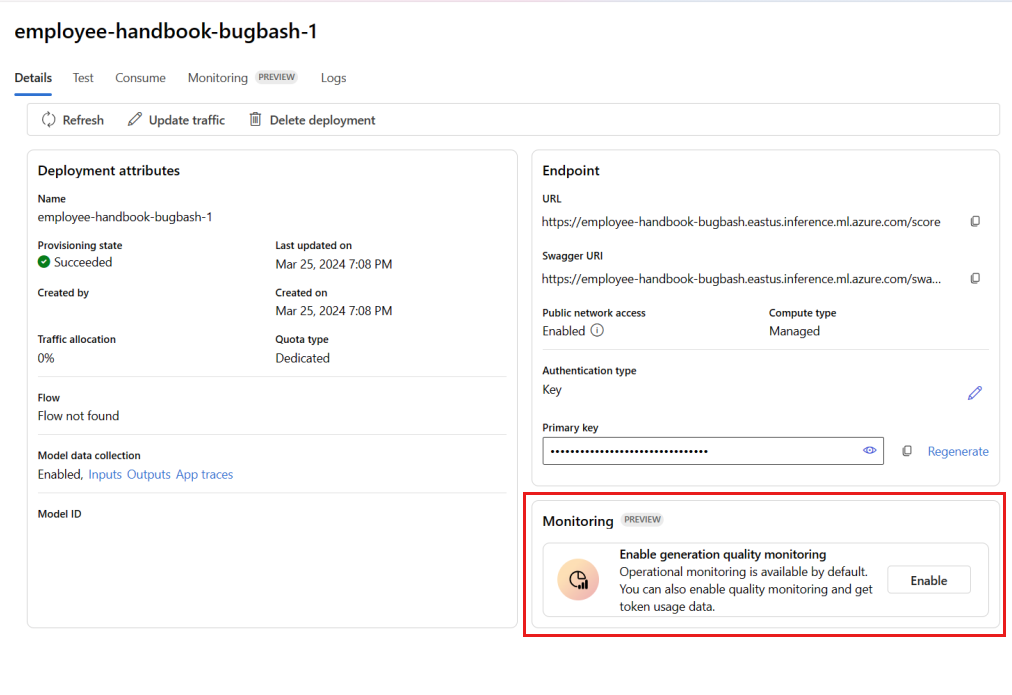
Börja konfigurera övervakning genom att välja önskade mått.
Bekräfta att kolumnnamnen mappas från ditt flöde enligt definitionen i Mappning av kolumnnamn.
Välj den Azure OpenAI-anslutning och -distribution som du vill använda för att utföra övervakning för ditt promptflödesprogram.
Välj Avancerade alternativ om du vill se fler alternativ att konfigurera.
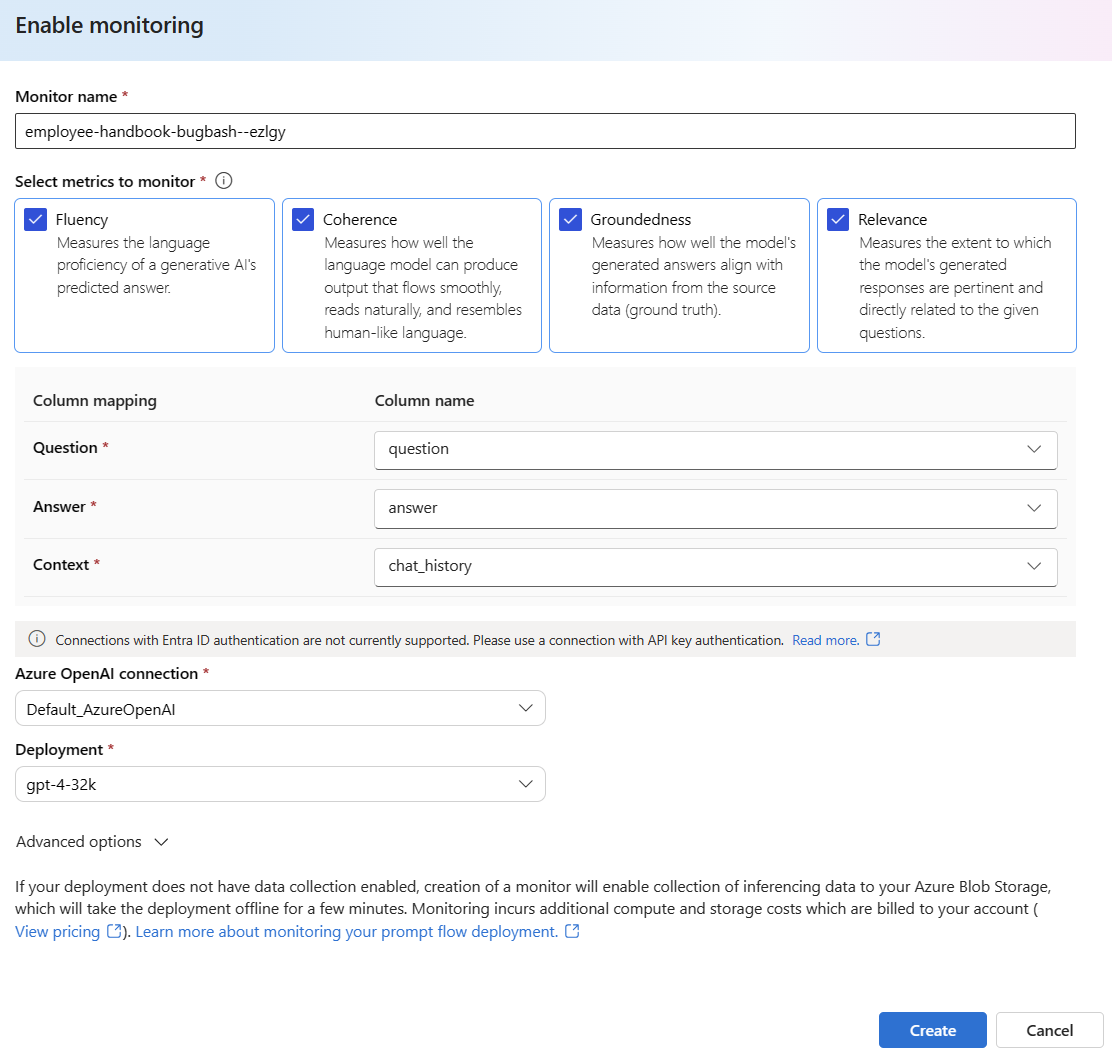
Justera samplingsfrekvensen, tröskelvärdena för dina konfigurerade mått och ange de e-postadresser som ska ta emot aviseringar när genomsnittspoängen för ett visst mått understiger tröskelvärdet.
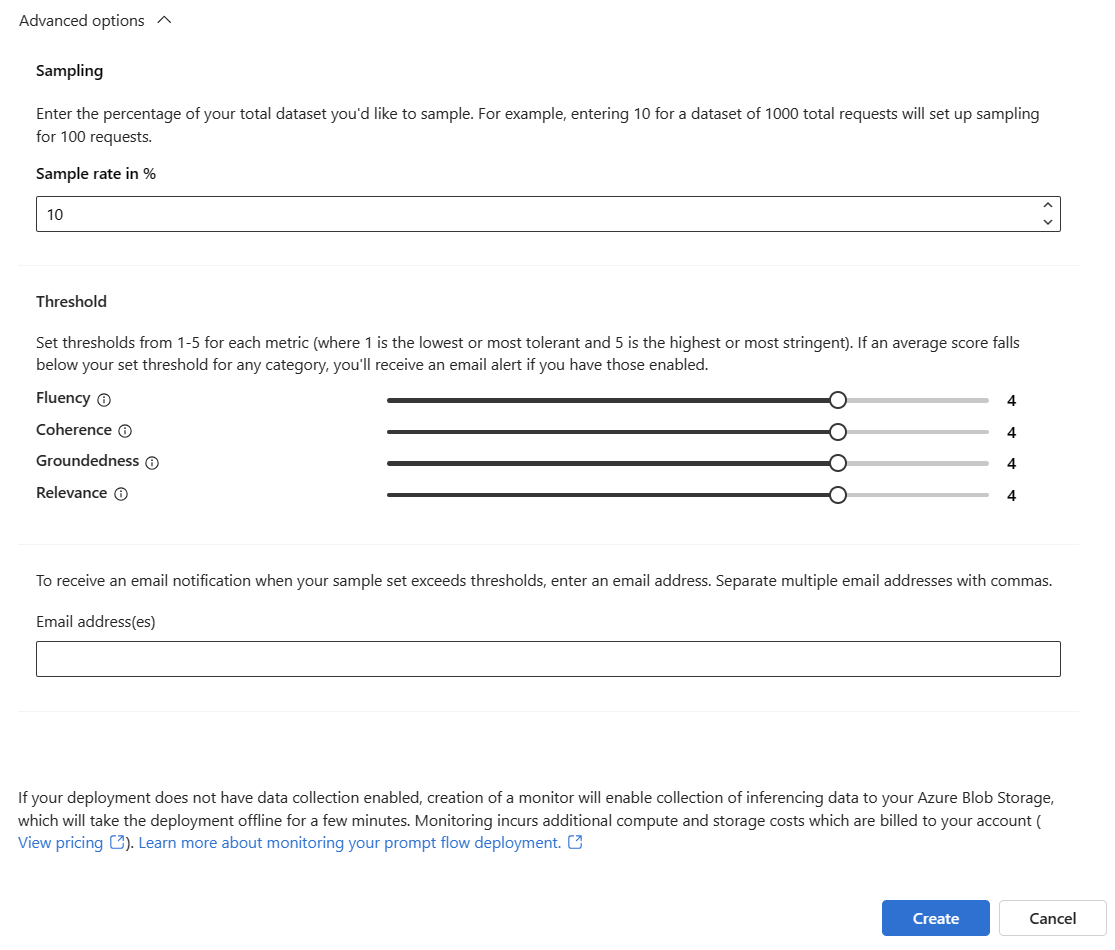
Kommentar
Om din distribution inte har aktiverat datainsamling aktiverar skapandet av en övervakare insamling av slutsatsdragningsdata till Azure Blob Storage, vilket tar distributionen offline i några minuter.
Välj Skapa för att skapa övervakaren.



Använda övervakningsresultat
När du har skapat övervakaren körs den dagligen för att beräkna tokenanvändning och kvalitetsmått för generering.
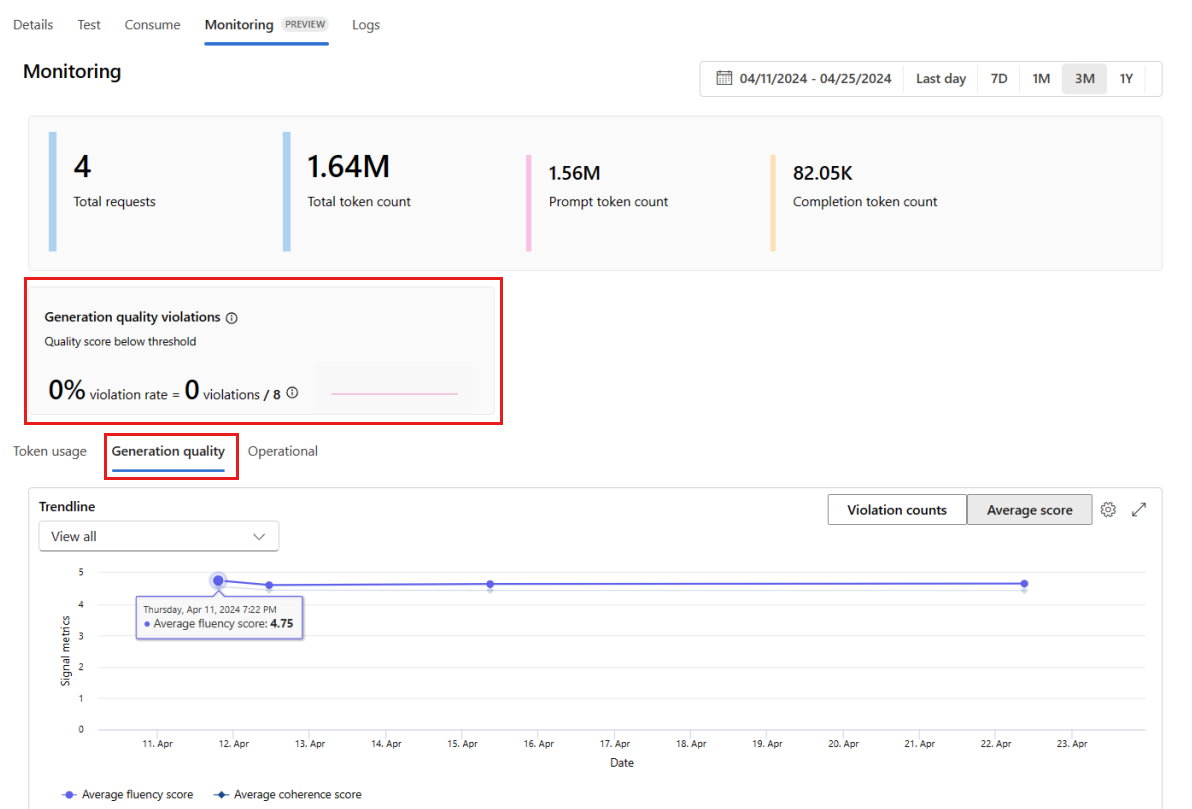
Gå till fliken Övervakning (förhandsversion) inifrån distributionen för att visa övervakningsresultaten. Här visas en översikt över övervakningsresultat under det valda tidsfönstret. Du kan använda datumväljaren för att ändra tidsfönstret för data som du övervakar. Följande mått är tillgängliga i den här översikten:
- Totalt antal begäranden: Det totala antalet begäranden som skickats till distributionen under det valda tidsfönstret.
- Totalt antal token: Det totala antalet token som används av distributionen under det valda tidsfönstret.
- Antal prompttoken: Antalet prompttoken som används av distributionen under det valda tidsfönstret.
- Antal slutförandetoken: Antalet slutförandetoken som används av distributionen under det valda tidsfönstret.
Visa måtten på fliken Tokenanvändning (den här fliken är markerad som standard). Här kan du visa tokenanvändningen för ditt program över tid. Du kan också visa fördelningen av prompt- och slutförandetoken över tid. Du kan ändra Trendline-omfånget för att övervaka alla token i hela programmet eller tokenanvändningen för en viss distribution (till exempel gpt-4) som används i ditt program.
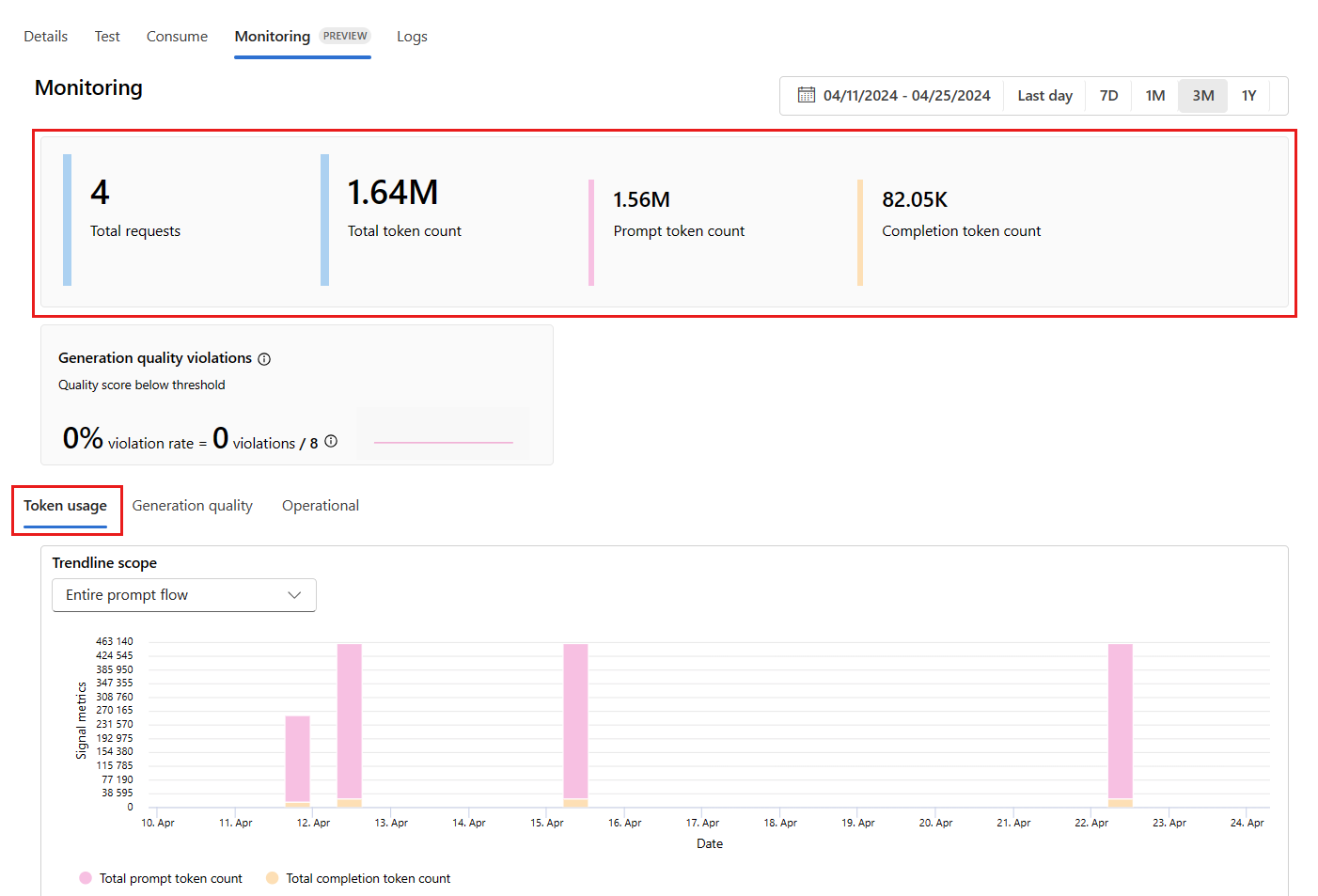
Gå till fliken Generation-kvalitet för att övervaka programmets kvalitet över tid. Följande mått visas i tidsschemat:
- Antal överträdelser: Antalet överträdelser för ett visst mått (till exempel Fluency) är summan av överträdelser under det valda tidsfönstret. En överträdelse inträffar för ett mått när måtten beräknas (standardvärdet är dagligen) om det beräknade värdet för måttet understiger det angivna tröskelvärdet.
- Genomsnittlig poäng: Genomsnittspoängen för ett visst mått (till exempel Fluency) är summan av poängen för alla instanser (eller begäranden) dividerat med antalet instanser (eller begäranden) under det valda tidsfönstret.
Kortet Kvalitetsöverträdelser för generation visar överträdelsefrekvensen under det valda tidsfönstret. Överträdelsefrekvensen är antalet överträdelser dividerat med det totala antalet möjliga överträdelser. Du kan justera tröskelvärdena för mått i inställningarna. Som standard beräknas måtten dagligen. den här frekvensen kan också justeras i inställningarna.
På fliken Övervakning (förhandsversion) kan du också visa en omfattande tabell över alla exempelbegäranden som skickas till distributionen under det valda tidsfönstret.
Kommentar
Övervakning anger standardsamplingshastigheten till 10 %. Det innebär att om 100 begäranden skickas till distributionen, får 10 samplas och används för att beräkna genereringens kvalitetsmått. Du kan justera samplingsfrekvensen i inställningarna.
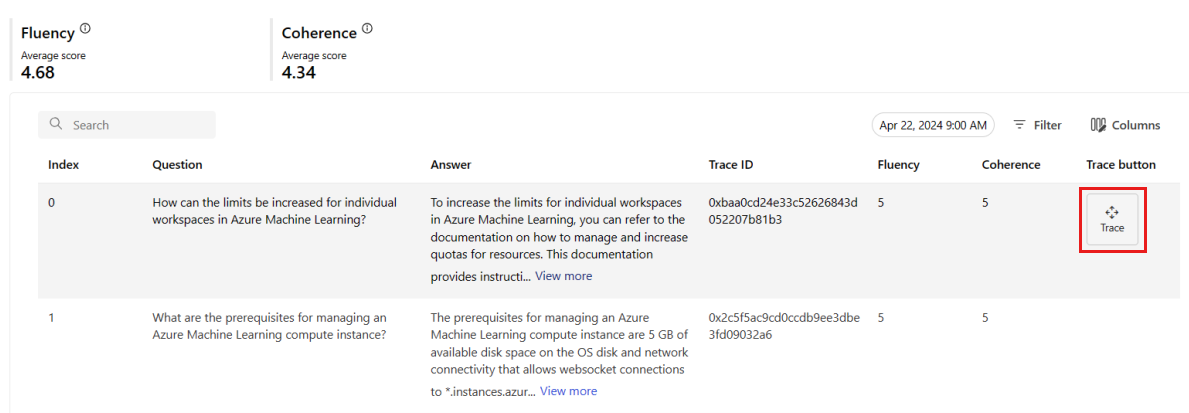
Välj knappen Spåra till höger på en rad i tabellen för att se spårningsinformation för en viss begäran. Den här vyn innehåller omfattande spårningsinformation för begäran till ditt program.
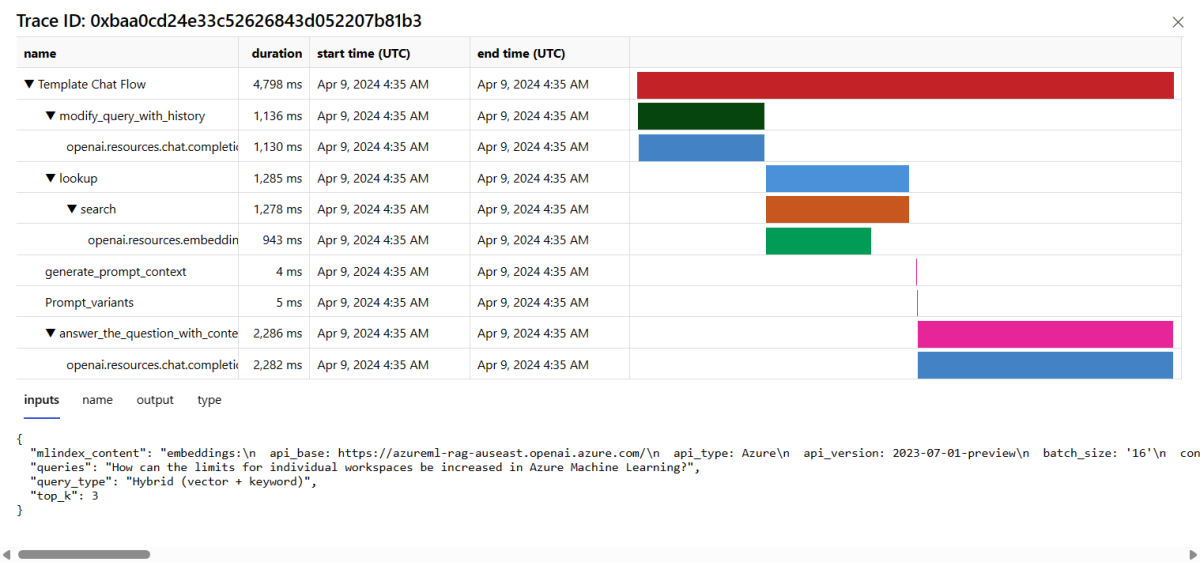
Stäng spårningsvyn.
Gå till fliken Drift för att visa driftmåtten för distributionen nästan i realtid. Vi stöder följande driftsmått:
- Antal förfrågningar
- Svarstid
- Felfrekvens
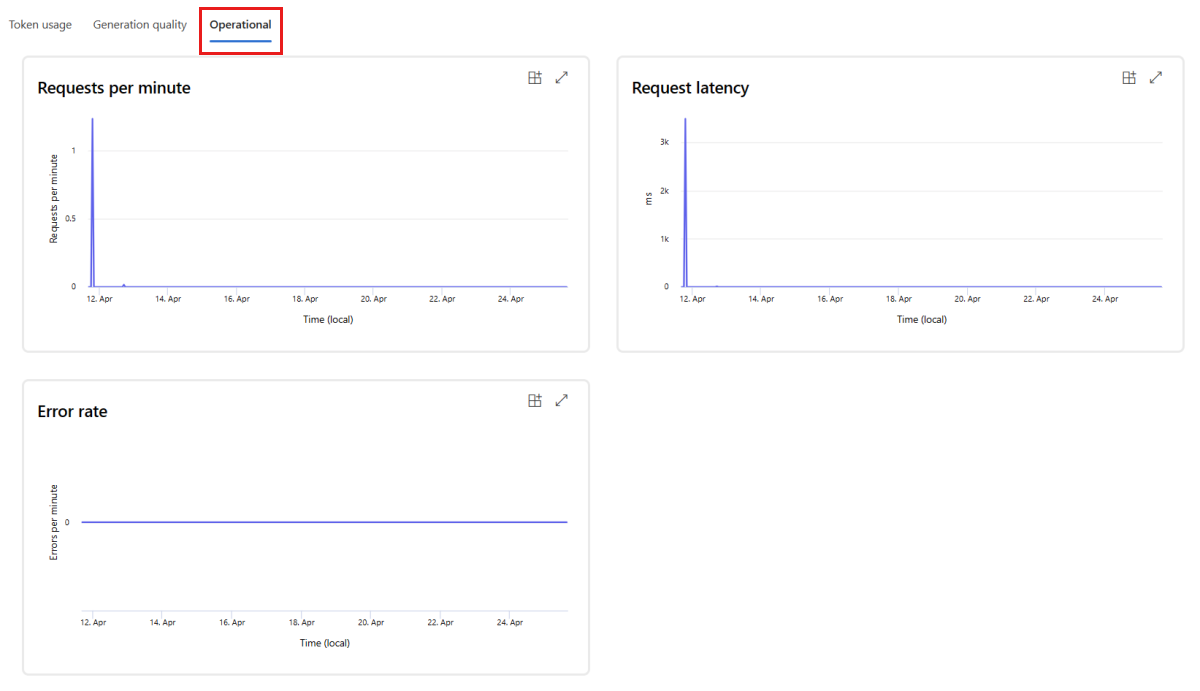





Resultatet på fliken Övervakning (förhandsversion) i distributionen ger insikter som hjälper dig att proaktivt förbättra prestandan för ditt program för snabbflöde.
Avancerad övervakningskonfiguration med SDK v2
Övervakning stöder även avancerade konfigurationsalternativ med SDK v2. Följande scenarier stöds:
Aktivera övervakning för tokenanvändning
Om du bara är intresserad av att aktivera övervakning av tokenanvändning för ditt distribuerade promptflödesprogram kan du anpassa följande skript till ditt scenario:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationTokenStatisticsSignal,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
# These variables can be renamed but it is not necessary
monitor_name ="gen_ai_monitor_tokens"
defaulttokenstatisticssignalname ="token-usage-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Create an instance of token statistic signal
token_statistic_signal = GenerationTokenStatisticsSignal()
monitoring_signals = {
defaulttokenstatisticssignalname: token_statistic_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Aktivera övervakning för generationskvalitet
Om du bara är intresserad av att aktivera kvalitetsövervakning av generation för ditt distribuerade promptflödesprogram kan du anpassa följande skript till ditt scenario:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationSafetyQualityMonitoringMetricThreshold,
GenerationSafetyQualitySignal,
BaselineDataRange,
LlmData,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
aoai_deployment_name ="INSERT YOUR AOAI DEPLOYMENT NAME"
aoai_connection_name = "INSERT YOUR AOAI CONNECTION NAME"
# These variables can be renamed but it is not necessary
app_trace_name = "app_traces"
app_trace_Version = "1"
monitor_name ="gen_ai_monitor_generation_quality"
defaultgsqsignalname ="gsq-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Set thresholds for passing rate (0.7 = 70%)
aggregated_groundedness_pass_rate = 0.7
aggregated_relevance_pass_rate = 0.7
aggregated_coherence_pass_rate = 0.7
aggregated_fluency_pass_rate = 0.7
# Create an instance of gsq signal
generation_quality_thresholds = GenerationSafetyQualityMonitoringMetricThreshold(
groundedness = {"aggregated_groundedness_pass_rate": aggregated_groundedness_pass_rate},
relevance={"aggregated_relevance_pass_rate": aggregated_relevance_pass_rate},
coherence={"aggregated_coherence_pass_rate": aggregated_coherence_pass_rate},
fluency={"aggregated_fluency_pass_rate": aggregated_fluency_pass_rate},
)
input_data = Input(
type="uri_folder",
path=f"{endpoint_name}-{deployment_name}-{app_trace_name}:{app_trace_Version}",
)
data_window = BaselineDataRange(lookback_window_size="P7D", lookback_window_offset="P0D")
production_data = LlmData(
data_column_names={"prompt_column": "question", "completion_column": "answer", "context_column": "context"},
input_data=input_data,
data_window=data_window,
)
gsq_signal = GenerationSafetyQualitySignal(
connection_id=f"/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{project_name}/connections/{aoai_connection_name}",
metric_thresholds=generation_quality_thresholds,
production_data=[production_data],
sampling_rate=1.0,
properties={
"aoai_deployment_name": aoai_deployment_name,
"enable_action_analyzer": "false",
"azureml.modelmonitor.gsq_thresholds": '[{"metricName":"average_fluency","threshold":{"value":4}},{"metricName":"average_coherence","threshold":{"value":4}}]',
},
)
monitoring_signals = {
defaultgsqsignalname: gsq_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
När du har skapat din övervakare från SDK:n kan du använda övervakningsresultaten i Azure AI Foundry-portalen.
Relaterat innehåll
- Läs mer om vad du kan göra i Azure AI Foundry.
- Få svar på vanliga frågor och svar i artikeln vanliga frågor och svar om Azure AI.