Utveckla program med LangChain och Azure AI Foundry
LangChain är ett utvecklingsekosystem som gör det enkelt för utvecklare att skapa program av den anledningen. Ekosystemet består av flera komponenter. De flesta av dem kan användas av sig själva, så att du kan välja och välja vilka komponenter du vill bäst.
Modeller som distribueras till Azure AI Foundry kan användas med LangChain på två sätt:
Med inferens-API:et för Azure AI-modellen: Alla modeller som distribueras till Azure AI Foundry stöder Azure AI-modellinferens-API:et, som erbjuder en gemensam uppsättning funktioner som kan användas för de flesta modeller i katalogen. Fördelen med det här API:et är att eftersom det är samma sak för alla modeller är det lika enkelt att byta från en till en annan som att ändra den modelldistribution som används. Inga ytterligare ändringar krävs i koden. När du arbetar med LangChain installerar du tilläggen
langchain-azure-ai.Använda modellens providerspecifika API: Vissa modeller, till exempel OpenAI, Cohere eller Mistral, erbjuder en egen uppsättning API:er och tillägg för LlamaIndex. Dessa tillägg kan innehålla specifika funktioner som modellen stöder och därför är lämpliga om du vill utnyttja dem. När du arbetar med LangChain installerar du tillägget som är specifikt för den modell som du vill använda, till exempel
langchain-openaiellerlangchain-cohere.
I den här självstudien får du lära dig hur du använder paketen langchain-azure-ai för att skapa program med LangChain.
Förutsättningar
Om du vill köra den här självstudien behöver du:
En modelldistribution som stöder azure AI-modellinferens-API :et som distribueras. I det här exemplet använder vi en
Mistral-Large-2407distribution i Azure AI-modellinferensen.Python 3.9 eller senare installerat, inklusive pip.
LangChain installerat. Du kan göra det med:
pip install langchain-coreI det här exemplet arbetar vi med Azure AI-modellinferens-API:et, och därför installerar vi följande paket:
pip install -U langchain-azure-ai
Konfigurera miljön
Om du vill använda LLM:er som distribuerats i Azure AI Foundry-portalen behöver du slutpunkten och autentiseringsuppgifterna för att ansluta till den. Följ dessa steg för att hämta den information du behöver från den modell som du vill använda:
Gå till Azure AI Foundry.
Öppna projektet där modellen distribueras, om den inte redan är öppen.
Gå till Modeller + slutpunkter och välj den modell som du distribuerade enligt kraven.
Kopiera slutpunkts-URL:en och nyckeln.
Dricks
Om din modell har distribuerats med Microsoft Entra ID-stöd behöver du ingen nyckel.

I det här scenariot placerade vi både slutpunkts-URL:en och nyckeln i följande miljövariabler:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
När du har konfigurerat skapar du en klient för att ansluta till slutpunkten. I det här fallet arbetar vi med en modell för chattavslut, och därför importerar vi klassen AzureAIChatCompletionsModel.
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model="mistral-large-2407",
)
Dricks
För Azure OpenAI-modeller konfigurerar du klienten enligt beskrivningen i Använda Azure OpenAI-modeller.
Du kan använda följande kod för att skapa klienten om slutpunkten stöder Microsoft Entra-ID:
import os
from azure.identity import DefaultAzureCredential
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model_name="mistral-large-2407",
)
Kommentar
När du använder Microsoft Entra-ID kontrollerar du att slutpunkten har distribuerats med den autentiseringsmetoden och att du har de behörigheter som krävs för att anropa den.
Om du planerar att använda asynkront anrop är det bästa praxis att använda den asynkrona versionen för autentiseringsuppgifterna:
from azure.identity.aio import (
DefaultAzureCredential as DefaultAzureCredentialAsync,
)
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredentialAsync(),
model_name="mistral-large-2407",
)
Om slutpunkten betjänar en modell, till exempel med serverlösa API-slutpunkter, behöver du inte ange model_name parametern:
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
)
Använda modeller för chattavslut
Vi ska först använda modellen direkt.
ChatModels är instanser av LangChain Runnable, vilket innebär att de exponerar ett standardgränssnitt för att interagera med dem. För att helt enkelt anropa modellen kan vi skicka en lista med meddelanden till invoke metoden.
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="Translate the following from English into Italian"),
HumanMessage(content="hi!"),
]
model.invoke(messages)
Du kan också skapa åtgärder efter behov i det som kallas kedjor. Nu ska vi använda en promptmall för att översätta meningar:
from langchain_core.output_parsers import StrOutputParser
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
Som du kan se från promptmallen har den här kedjan en language och text indata. Nu ska vi skapa en utdataparser:
from langchain_core.prompts import ChatPromptTemplate
parser = StrOutputParser()
Nu kan vi kombinera mallen, modellen och utdataparsern ovanifrån med hjälp av pipe-operatorn (|):
chain = prompt_template | model | parser
Om du vill anropa kedjan identifierar du de indata som krävs och anger värden med hjälp av invoke metoden:
chain.invoke({"language": "italian", "text": "hi"})
'ciao'
Länka flera LLM:er tillsammans
Modeller som distribueras till Azure AI Foundry stöder Azure AI-modellinferens-API:et, som är standard för alla modeller. Länka flera LLM-åtgärder baserat på funktionerna i varje modell så att du kan optimera för rätt modell baserat på funktioner.
I följande exempel skapar vi två modellklienter, en är en producent och en annan är en verifierare. För att göra skillnaden tydlig använder vi en slutpunkt för flera modeller som Azure AI-modellens slutsatsdragningstjänst och därför skickar vi parametern model_name för att använda en Mistral-Large och en Mistral-Small modell, och citerar att det är mer komplext att producera innehåll än att verifiera det.
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
producer = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
)
verifier = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-small",
)
Dricks
Utforska modellkortet för var och en av modellerna för att förstå de bästa användningsfallen för varje modell.
Följande exempel genererar en dikt skriven av en urban poet:
from langchain_core.prompts import PromptTemplate
producer_template = PromptTemplate(
template="You are an urban poet, your job is to come up \
verses based on a given topic.\n\
Here is the topic you have been asked to generate a verse on:\n\
{topic}",
input_variables=["topic"],
)
verifier_template = PromptTemplate(
template="You are a verifier of poems, you are tasked\
to inspect the verses of poem. If they consist of violence and abusive language\
report it. Your response should be only one word either True or False.\n \
Here is the lyrics submitted to you:\n\
{input}",
input_variables=["input"],
)
Nu ska vi kedja bitarna:
chain = producer_template | producer | parser | verifier_template | verifier | parser
Den föregående kedjan returnerar endast utdata från steget verifier . Eftersom vi vill komma åt det mellanliggande resultatet som genereras av producer, i LangChain måste du använda ett RunnablePassthrough -objekt för att även mata ut det mellanliggande steget. Följande kod visar hur du gör det:
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
generate_poem = producer_template | producer | parser
verify_poem = verifier_template | verifier | parser
chain = generate_poem | RunnableParallel(poem=RunnablePassthrough(), verification=RunnablePassthrough() | verify_poem)
Om du vill anropa kedjan identifierar du de indata som krävs och anger värden med hjälp av invoke metoden:
chain.invoke({"topic": "living in a foreign country"})
{
"peom": "...",
"verification: "false"
}
Använda inbäddningsmodeller
På samma sätt skapar du en LLM-klient. Du kan ansluta till en inbäddningsmodell. I följande exempel ställer vi in miljövariabeln så att den nu pekar på en inbäddningsmodell:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Skapa sedan klienten:
from langchain_azure_ai.embeddings import AzureAIEmbeddingsModel
embed_model = AzureAIEmbeddingsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ['AZURE_INFERENCE_CREDENTIAL'],
model_name="text-embedding-3-large",
)
I följande exempel visas ett enkelt exempel med ett vektorlager i minnet:
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embed_model)
Nu ska vi lägga till några dokument:
from langchain_core.documents import Document
document_1 = Document(id="1", page_content="foo", metadata={"baz": "bar"})
document_2 = Document(id="2", page_content="thud", metadata={"bar": "baz"})
documents = [document_1, document_2]
vector_store.add_documents(documents=documents)
Nu ska vi söka efter likheter:
results = vector_store.similarity_search(query="thud",k=1)
for doc in results:
print(f"* {doc.page_content} [{doc.metadata}]")
Använda Azure OpenAI-modeller
Om du använder Azure OpenAI-tjänsten eller Azure AI-modellinferenstjänsten med OpenAI-modeller med langchain-azure-ai paket kan du behöva använda api_version parametern för att välja en specifik API-version. I följande exempel visas hur du ansluter till en Azure OpenAI-modelldistribution i Azure OpenAI-tjänsten:
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
llm = AzureAIChatCompletionsModel(
endpoint="https://<resource>.openai.azure.com/openai/deployments/<deployment-name>",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
api_version="2024-05-01-preview",
)
Viktigt!
Kontrollera vilken API-version som distributionen använder. Om du använder ett fel api_version eller en som inte stöds av modellen resulterar det i ett ResourceNotFound undantag.
Om distributionen finns i Azure AI Services kan du använda inferenstjänsten för Azure AI-modellen:
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
llm = AzureAIChatCompletionsModel(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="<model-name>",
api_version="2024-05-01-preview",
)
Felsökning och felsökning
Om du behöver felsöka ditt program och förstå de begäranden som skickas till modellerna i Azure AI Foundry kan du använda felsökningsfunktionerna i integreringen på följande sätt:
Konfigurera först loggning till den nivå som du är intresserad av:
import sys
import logging
# Acquire the logger for this client library. Use 'azure' to affect both
# 'azure.core` and `azure.ai.inference' libraries.
logger = logging.getLogger("azure")
# Set the desired logging level. logging.INFO or logging.DEBUG are good options.
logger.setLevel(logging.DEBUG)
# Direct logging output to stdout:
handler = logging.StreamHandler(stream=sys.stdout)
# Or direct logging output to a file:
# handler = logging.FileHandler(filename="sample.log")
logger.addHandler(handler)
# Optional: change the default logging format. Here we add a timestamp.
formatter = logging.Formatter("%(asctime)s:%(levelname)s:%(name)s:%(message)s")
handler.setFormatter(formatter)
Om du vill se nyttolasten för begäranden skickar du argumentet logging_enable=True till :client_kwargs
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
client_kwargs={"logging_enable": True},
)
Använd klienten som vanligt i koden.
Spårning
Du kan använda spårningsfunktionerna i Azure AI Foundry genom att skapa en spårningsguide. Loggar lagras i Azure Application Insights och kan när som helst frågas med azure monitor- eller Azure AI Foundry-portalen. Varje AI Hub har en Associerad Azure Application Insights.
Hämta din instrumentation anslutningssträng
Du kan konfigurera ditt program för att skicka telemetri till Azure Application Insights antingen genom att:
Använda anslutningssträng till Azure Application Insights direkt:
Gå till Azure AI Foundry-portalen och välj Spårning.
Välj Hantera datakälla. På den här skärmen kan du se den instans som är associerad med projektet.
Kopiera värdet vid Anslutningssträng och ange det till följande variabel:
import os application_insights_connection_string = "instrumentation...."
Använda Azure AI Foundry SDK och projektet anslutningssträng.
Kontrollera att paketet
azure-ai-projectsär installerat i din miljö.Gå till Azure AI Foundry-portalen.
Kopiera projektets anslutningssträng och ange följande kod:
from azure.ai.projects import AIProjectClient from azure.identity import DefaultAzureCredential project_client = AIProjectClient.from_connection_string( credential=DefaultAzureCredential(), conn_str="<your-project-connection-string>", ) application_insights_connection_string = project_client.telemetry.get_connection_string()
Konfigurera spårning för Azure AI Foundry
Följande kod skapar en spårning som är ansluten till Azure Application Insights bakom ett projekt i Azure AI Foundry. Observera att parametern enable_content_recording är inställd på True. Detta möjliggör insamling av indata och utdata för hela programmet samt mellanliggande steg. Det är användbart när du felsöker och skapar program, men du kanske vill inaktivera det i produktionsmiljöer. Den är standardinställningen för miljövariabeln AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED:
from langchain_azure_ai.callbacks.tracers import AzureAIInferenceTracer
tracer = AzureAIInferenceTracer(
connection_string=application_insights_connection_string,
enable_content_recording=True,
)
Om du vill konfigurera spårning med din kedja anger du värdekonfigurationen invoke i åtgärden som ett återanrop:
chain.invoke({"topic": "living in a foreign country"}, config={"callbacks": [tracer]})
Om du vill konfigurera själva kedjan för spårning använder du .with_config() metoden:
chain = chain.with_config({"callbacks": [tracer]})
Använd invoke() sedan metoden som vanligt:
chain.invoke({"topic": "living in a foreign country"})
Visa spårningar
Så här ser du spårningar:
Gå till Azure AI Foundry-portalen.
Gå till spårningsavsnittet .
Identifiera den spårning som du har skapat. Det kan ta några sekunder innan spårningen visas.
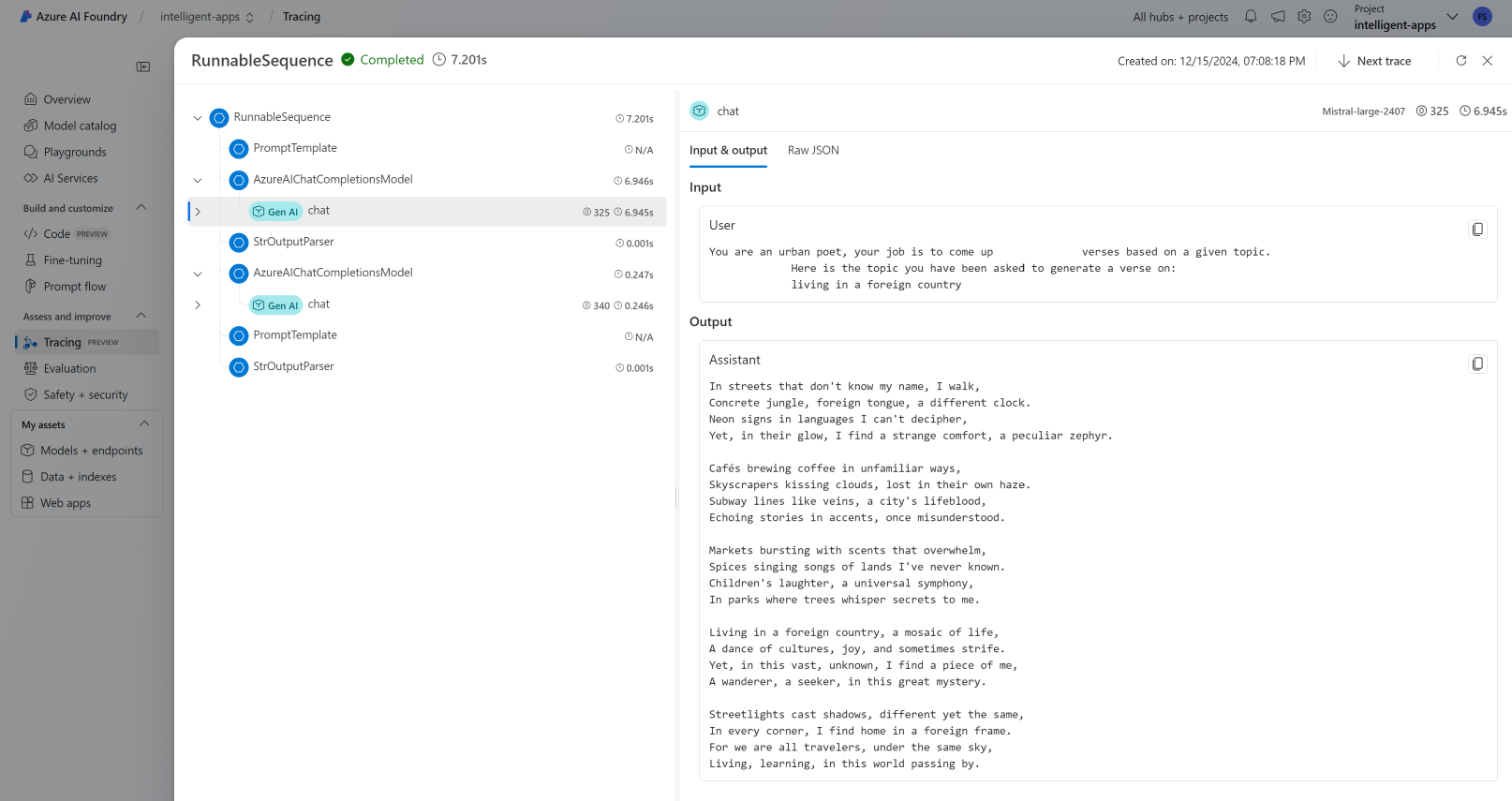

Läs mer om hur du visualiserar och hanterar spårningar.