Vad är konversationstranskription med flera kanaler diarization? (förhandsversion)
Kommentar
Den här funktionen är för närvarande i allmänt tillgänglig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och rekommenderas inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Konversationstranskription med flera kanaler är en tal-till-text-lösning som ger realtids- eller asynkron transkription av alla möten. Den här funktionen kombinerar taligenkänning, talaridentifiering och meningstillskrivning för att avgöra vem som sa vad och när i ett möte.
Viktigt!
Konversationstranskription med flera kanaler (förhandsversion) går i pension den 28 mars 2025. Mer information om hur du migrerar till andra tal till text-funktioner finns i Migrera bort från konversationstranskription med flera kanaler.
Migrera bort från konversationstranskription med flera kanaler
Konversationstranskription med flera kanaler (förhandsversion) går i pension den 28 mars 2025.
Om du vill fortsätta använda tal till text med diarisering använder du följande funktioner i stället:
- Tal till text i realtid med diarisering
- Snabb transkription med diarisering
- Batch-transkription med diarisering
Dessa tal till text-funktioner stöder endast diarisering för enkanalsljud. Multichannel-ljud som du använde med konversationstranskription med flera kanaler stöds inte.
Nyckelfunktioner
Du kanske tycker att följande funktioner i konversationstranskription är användbara:
- Tidsstämplar: Varje talaryttrande har en tidsstämpel, så att du enkelt kan hitta när en fras sades.
- Läsbara avskrifter: Avskrifter har formatering och skiljetecken läggs till automatiskt för att säkerställa att texten matchar vad som sades.
- Användarprofiler: Användarprofiler genereras genom att användarens röstexempel samlas in och skickas till signaturgenerering.
- Talaridentifiering: Talare identifieras med hjälp av användarprofiler och en talaridentifierare tilldelas var och en.
- Diarisering med flera talare: Bestäm vem som sa vad genom att syntetisera ljudströmmen med varje talaridentifierare.
- Transkription i realtid: Ge live-transkriptioner av vem som säger vad, och när, medan mötet äger rum.
- Asynkron transkription: Ge avskrifter med högre noggrannhet med hjälp av en ljudström med flera kanaler.
Kommentar
Även om konversationstranskription inte sätter någon gräns för antalet talare i rummet är den optimerad för 2–10 talare per session.
Användningsfall
För att göra möten inkluderande för alla, till exempel deltagare som är döva och hörselskadade, är det viktigt att ha transkription i realtid. Konversationstranskription i realtidsläge tar mötesljud och avgör vem som säger vad, vilket gör att alla mötesdeltagare kan följa avskriften och delta i mötet, utan fördröjning.
Mötesdeltagare kan fokusera på mötet och lämna anteckningar till konversationstranskription. Deltagarna kan aktivt delta i mötet och snabbt följa upp nästa steg med hjälp av avskriften i stället för att anteckna och eventuellt missa något under mötet.
Hur det fungerar
Följande diagram visar en översikt på hög nivå över hur funktionen fungerar.
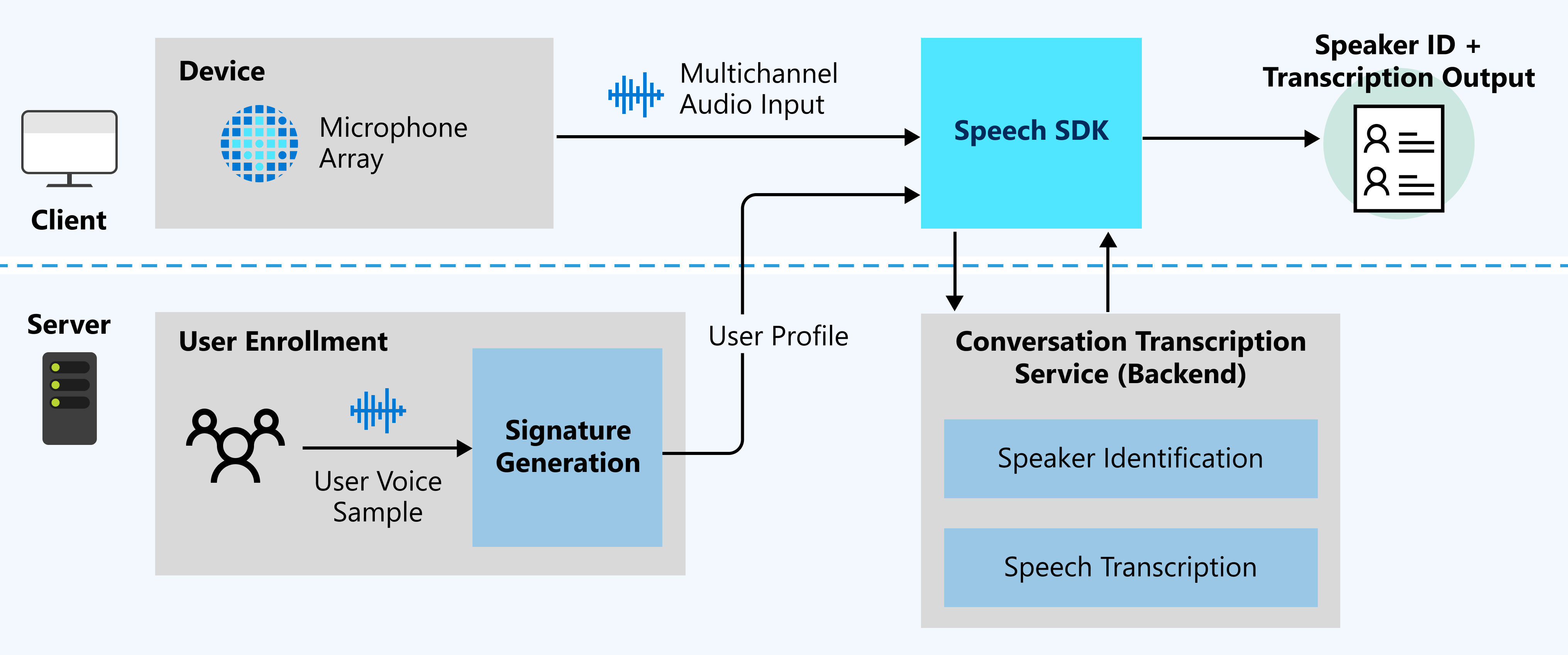
Förväntade indata
Konversationstranskription använder två typer av indata:
- Ljudström med flera kanaler: Information om specifikation och design finns i rekommendationer för mikrofonmatris.
- Exempel på användarröst: Konversationstranskription behöver användarprofiler före konversationen för talaridentifiering. Samla in ljudinspelningar från varje användare och skicka sedan inspelningarna till signaturgenereringstjänsten för att verifiera ljudet och generera användarprofiler.
Röstexempel för röstsignaturer krävs för talaridentifiering. Talare som inte har röstexempel identifieras som oidentifierade. Oidentifierade högtalare kan fortfarande särskiljas när egenskapen DifferentiateGuestSpeakers är aktiverad (se följande exempel). Transkriptionsutdata visar sedan talare som till exempel Guest_0 och Guest_1, i stället för att känna igen dem som förregistrerade specifika talarnamn.
config.SetProperty("DifferentiateGuestSpeakers", "true");
Realtid eller asynkron
Följande avsnitt innehåller mer information om transkriptionslägen som du kan välja.
Realtid
Ljuddata bearbetas live för att returnera talaridentifieraren och avskriften. Välj det här läget om ditt krav på transkriptionslösning är att ge mötesdeltagarna en liveavskriftsvy över deras pågående möte. Att till exempel skapa ett program för att göra möten mer tillgängliga för deltagare med hörselnedsättning eller dövhet är ett idealiskt användningsfall för transkription i realtid.
Asynkron
Ljuddata bearbetas i batch för att returnera talaridentifieraren och avskriften. Välj det här läget om kravet på transkriptionslösning är att ge högre noggrannhet, utan liveavskriftsvyn. Om du till exempel vill skapa ett program så att mötesdeltagarna enkelt kan komma ikapp missade möten använder du det asynkrona transkriptionsläget för att få resultat av transkription med hög noggrannhet.
Realtid plus asynkron
Ljuddata bearbetas live för att returnera talaridentifieraren och avskriften, och begär dessutom en avskrift med hög noggrannhet via asynkron bearbetning. Välj det här läget om programmet behöver transkribering i realtid och även kräver en högre noggrannhetsavskrift för användning efter att mötet har inträffat.
Stöd för språk och region
Konversationstranskription stöder för närvarande alla tal till textspråk i följande regioner: centralus, eastasia, eastus, westeurope.