Testigenkänningskvalitet för en anpassad talmodell
Du kan kontrollera igenkänningskvaliteten för en anpassad talmodell i Speech Studio. Du kan spela upp uppladdat ljud och avgöra om det angivna igenkänningsresultatet är korrekt. När ett test har skapats kan du se hur en modell transkriberade ljuddatauppsättningen eller jämför resultat från två modeller sida vid sida.
Modelltestning sida vid sida är användbart för att verifiera vilken taligenkänningsmodell som är bäst för ett program. Ett objektivt mått på noggrannhet, som kräver indata för transkriptionsdatamängder, finns i Testa modellen kvantitativt.
Viktigt!
Vid testning utför systemet en transkription. Detta är viktigt att tänka på eftersom priserna varierar beroende på tjänsterbjudande och prenumerationsnivå. Se alltid den officiella prissättningen för Azure AI-tjänster för den senaste informationen.
Skapa test
Följ de här anvisningarna för att skapa ett test:
Logga in på Speech Studio.
Gå till Anpassat tal i Speech Studio>och välj projektnamnet i listan.
Välj Testmodeller>Skapa nytt test.
Välj Inspektera kvalitet (endast ljuddata)>Nästa.
Välj en ljuddatauppsättning som du vill använda för testning och välj sedan Nästa. Om det inte finns några tillgängliga datauppsättningar avbryter du installationen och går sedan till menyn Taldatauppsättningar för att ladda upp datauppsättningar.
Välj en eller två modeller för att utvärdera och jämföra noggrannhet.
Ange testnamnet och beskrivningen och välj sedan Nästa.
Granska inställningarna och välj sedan Spara och stäng.
Använd kommandot för spx csr evaluation create att skapa ett test. Skapa begärandeparametrarna enligt följande instruktioner:
- Ange parametern
projecttill ID för ett befintligt projekt. Den här parametern rekommenderas så att du även kan visa testet i Speech Studio. Du kan köraspx csr project listkommandot för att hämta tillgängliga projekt. - Ange den obligatoriska
model1parametern till ID för en modell som du vill testa. - Ange den obligatoriska
model2parametern till ID för en annan modell som du vill testa. Om du inte vill jämföra två modeller använder du samma modell för bådemodel1ochmodel2. - Ange den obligatoriska
datasetparametern till ID för en datauppsättning som du vill använda för testet. - Ange parametern
language, annars anger Speech CLI "en-US" som standard. Den här parametern bör vara språkvarianten för datamängdens innehåll. Språkvarianten kan inte ändras senare. Parametern Speech CLIlanguagemotsvararlocaleegenskapen i JSON-begäran och -svaret. - Ange den obligatoriska
nameparametern. Den här parametern är namnet som visas i Speech Studio. Parametern Speech CLInamemotsvarardisplayNameegenskapen i JSON-begäran och -svaret.
Här är ett exempel på ett Speech CLI-kommando som skapar ett test:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 13fb305e-09ad-4bce-b3a1-938c9124dda3 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Inspection" --description "My Inspection Description"
Du bör få en svarstext i följande format:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Egenskapen på den översta nivån self i svarstexten är utvärderingens URI. Använd den här URI:n för att få information om projektet och testresultaten. Du använder också den här URI:n för att uppdatera eller ta bort utvärderingen.
Kör följande kommando för speech CLI-hjälp med utvärderingar:
spx help csr evaluation
Om du vill skapa ett test använder du den Evaluations_Create åtgärden för REST API för tal till text. Skapa begärandetexten enligt följande instruktioner:
projectAnge egenskapen till URI för ett befintligt projekt. Den här egenskapen rekommenderas så att du även kan visa testet i Speech Studio. Du kan göra en Projects_List begäran om att få tillgängliga projekt.- Ange den obligatoriska
model1egenskapen till URI:n för en modell som du vill testa. - Ange den obligatoriska
model2egenskapen till URI:n för en annan modell som du vill testa. Om du inte vill jämföra två modeller använder du samma modell för bådemodel1ochmodel2. - Ange den obligatoriska
datasetegenskapen till URI för en datauppsättning som du vill använda för testet. - Ange den obligatoriska
localeegenskapen. Den här egenskapen bör vara språkvarianten för datamängdens innehåll. Språkvarianten kan inte ändras senare. - Ange den obligatoriska
displayNameegenskapen. Den här egenskapen är det namn som visas i Speech Studio.
Gör en HTTP POST-begäran med hjälp av URI:n enligt följande exempel. Ersätt YourSubscriptionKey med din Speech-resursnyckel, ersätt YourServiceRegion med resursregionen Speech och ange egenskaperna för begärandetexten enligt beskrivningen ovan.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Inspection",
"description": "My Inspection Description",
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
Du bör få en svarstext i följande format:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Egenskapen på den översta nivån self i svarstexten är utvärderingens URI. Använd den här URI:n för att få information om utvärderingens projekt och testresultat. Du använder också den här URI:n för att uppdatera eller ta bort utvärderingen.
Hämta testresultat
Du bör få testresultaten och inspektera ljuddatauppsättningarna jämfört med transkriptionsresultat för varje modell.
Följ dessa steg för att få testresultat:
- Logga in på Speech Studio.
- Välj Anpassat tal> Projektnamnet >Testmodeller.
- Välj länken efter testnamn.
- När testet är klart bör du se resultat som innehåller WER-numret för varje testad modell, enligt statusuppsättningen Lyckades.
På den här sidan visas alla yttranden i datamängden och igenkänningsresultaten, tillsammans med transkriptionen från den skickade datamängden. Du kan växla mellan olika feltyper, till exempel infogning, borttagning och ersättning. Genom att lyssna på ljudet och jämföra igenkänningsresultaten i varje kolumn kan du bestämma vilken modell som uppfyller dina behov och avgöra var mer träning och förbättringar krävs.
Använd kommandot för spx csr evaluation status att hämta testresultat. Skapa begärandeparametrarna enligt följande instruktioner:
- Ange den obligatoriska
evaluationparametern till ID:t för utvärderingen som du vill få testresultat.
Här är ett exempel på ett Speech CLI-kommando som hämtar testresultat:
spx csr evaluation status --api-version v3.2 --evaluation 9c06d5b1-213f-4a16-9069-bc86efacdaac
Modellerna, ljuddatauppsättningen, transkriptionerna och mer information returneras i svarstexten.
Du bör få en svarstext i följande format:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Kör följande kommando för speech CLI-hjälp med utvärderingar:
spx help csr evaluation
Om du vill få testresultat börjar du med att använda Evaluations_Get-åtgärden för REST-API:et Tal till text.
Gör en HTTP GET-begäran med hjälp av URI:n enligt följande exempel. Ersätt YourEvaluationId med ditt utvärderings-ID, ersätt YourSubscriptionKey med din Speech-resursnyckel och ersätt YourServiceRegion med din Speech-resursregion.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
Modellerna, ljuddatauppsättningen, transkriptionerna och mer information returneras i svarstexten.
Du bör få en svarstext i följande format:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Jämför transkription med ljud
Du kan inspektera transkriptionsutdata av varje modell som testats, mot datauppsättningen för ljudindata. Om du har inkluderat två modeller i testet kan du jämföra deras transkriptionskvalitet sida vid sida.
Så här granskar du kvaliteten på transkriptioner:
- Logga in på Speech Studio.
- Välj Anpassat tal> Projektnamnet >Testmodeller.
- Välj länken efter testnamn.
- Spela upp en ljudfil medan du läser motsvarande transkription av en modell.
Om testdatauppsättningen innehåller flera ljudfiler visas flera rader i tabellen. Om du har inkluderat två modeller i testet visas transkriptioner i kolumner sida vid sida. Transkriptionsskillnader mellan modeller visas i blått textteckensnitt.
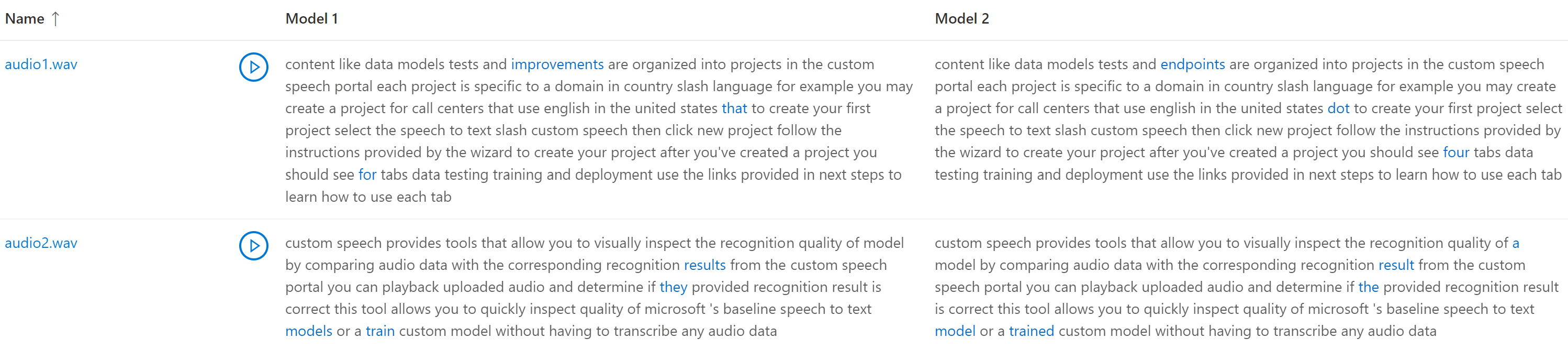
Ljudtestdatauppsättningen, transkriptionerna och modellerna som testats returneras i testresultaten. Om bara en modell har testats model1 matchar model2värdet och värdet transcription1 matchar transcription2.
Så här granskar du kvaliteten på transkriptioner:
- Ladda ned datauppsättningen för ljudtest, såvida du inte redan har en kopia.
- Ladda ned utdatatranskriptionerna.
- Spela upp en ljudfil medan du läser motsvarande transkription av en modell.
Om du jämför kvalitet mellan två modeller bör du vara särskilt uppmärksam på skillnaderna mellan varje modells transkriptioner.
Ljudtestdatauppsättningen, transkriptionerna och modellerna som testats returneras i testresultaten. Om bara en modell har testats model1 matchar model2värdet och värdet transcription1 matchar transcription2.
Så här granskar du kvaliteten på transkriptioner:
- Ladda ned datauppsättningen för ljudtest, såvida du inte redan har en kopia.
- Ladda ned utdatatranskriptionerna.
- Spela upp en ljudfil medan du läser motsvarande transkription av en modell.
Om du jämför kvalitet mellan två modeller bör du vara särskilt uppmärksam på skillnaderna mellan varje modells transkriptioner.