Azure OpenAI-lagrade slutföranden och destillation (förhandsversion)
Med lagrade slutföranden kan du samla in konversationshistoriken från chattsessioner som ska användas som datauppsättningar för utvärderingar och finjustering.
Stöd för lagrade slutföranden
API-stöd
Supporten lades först till i 2024-10-01-preview
Distributionstyp
För närvarande stöder endast Standard modelldistributioner lagrade slutföranden.
Tillgänglighet för modell och region
| Region | o1-preview, 2024-09-12 | o1-mini, 2024-09-12 | gpt-4o, 2024-08-06 | gpt-4o, 2024-05-13 | gpt-4o-mini, 2024-07-18 |
|---|---|---|---|---|---|
| Sverige, centrala | ✅ | ✅ | ✅ | ✅ | ✅ |
| Norra centrala USA | - | - | ✅ | - | - |
| USA, östra 2 | - | - | ✅ | - | - |
Konfigurera lagrade slutföranden
Om du vill aktivera lagrade slutföranden för Azure OpenAI-distributionen anger du parametern store till True. Använd parametern metadata för att utöka datamängden för lagrad slutförande med ytterligare information.
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2024-10-01-preview"
)
completion = client.chat.completions.create(
model="gpt-4o", # replace with model deployment name
store= True,
metadata = {
"user": "admin",
"category": "docs-test",
},
messages=[
{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."},
{"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random subsets of data), boosting (sequentially training models to correct previous errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree focusing on correcting the errors of previous trees. These methods often achieve better performance than single models by reducing overfitting and variance while capturing different aspects of the data."}
]
)
print(completion.choices[0].message)
När lagrade slutföranden har aktiverats för en Azure OpenAI-distribution börjar de visas i Azure AI Foundry-portalen i fönstret Lagrade slutföranden .

Destillering
Med destillation kan du omvandla dina lagrade slutföranden till en finjusteringsdatauppsättning. Ett vanligt användningsfall är att använda lagrade slutföranden med en större kraftfullare modell för en viss uppgift och sedan använda lagrade slutföranden för att träna en mindre modell på högkvalitativa exempel på modellinteraktioner.
Destillation kräver minst 10 lagrade slutföranden, men vi rekommenderar att du tillhandahåller hundratals till tusentals lagrade kompletteringar för bästa resultat.
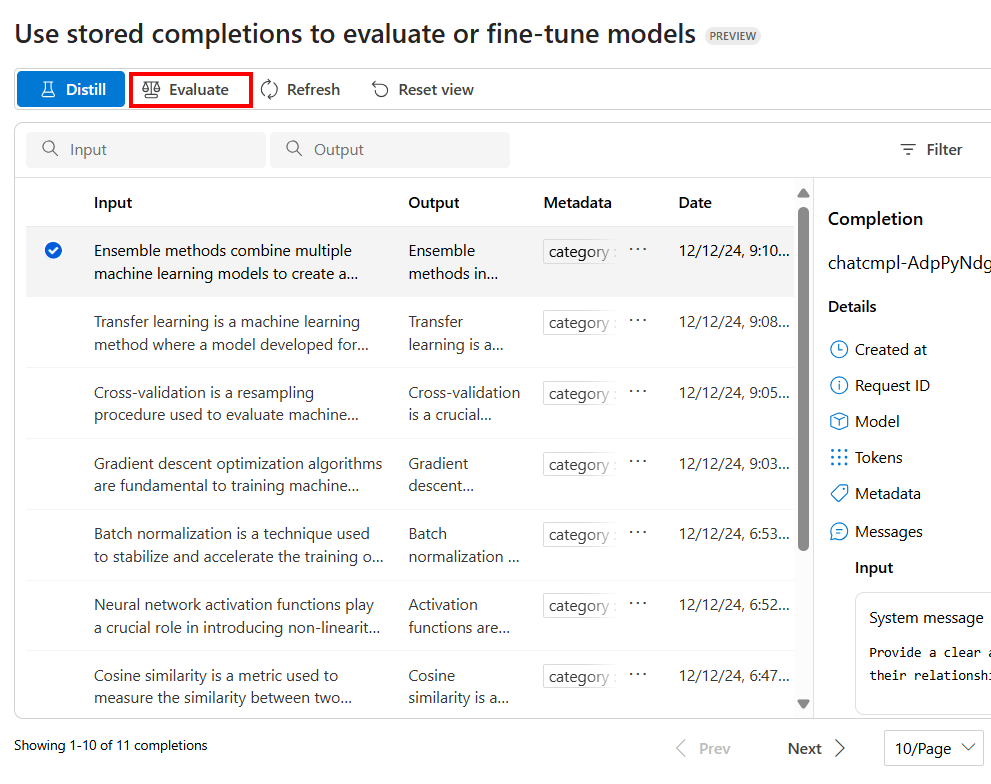
I fönstret Lagrade slutföranden i Azure AI Foundry-portalen använder du filteralternativen för att välja de slutföranden som du vill träna din modell med.
Börja destillationen genom att välja Destillera
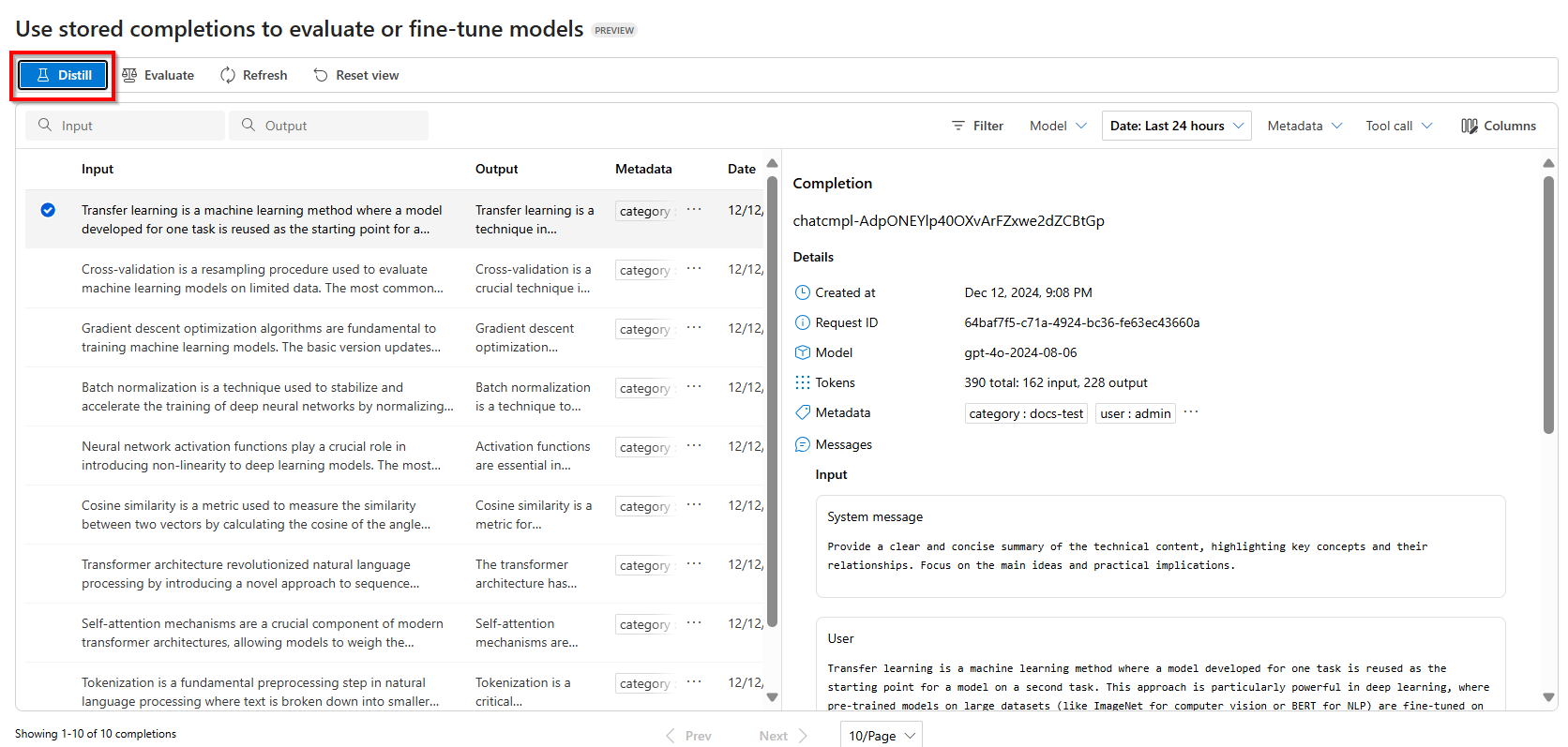
Välj vilken modell du vill finjustera med din lagrade slutförandedatauppsättning.
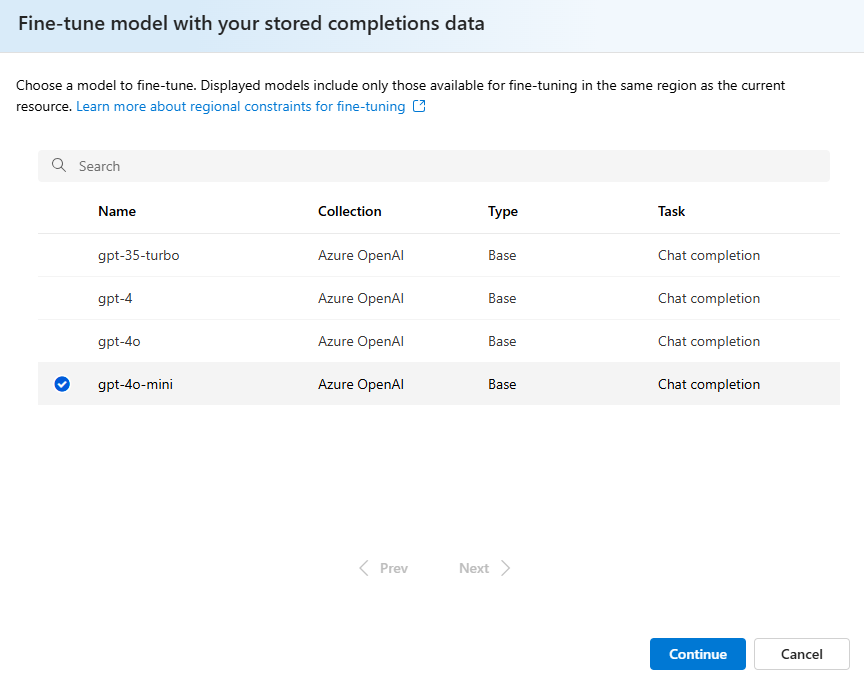
Bekräfta vilken version av modellen du vill finjustera:
En
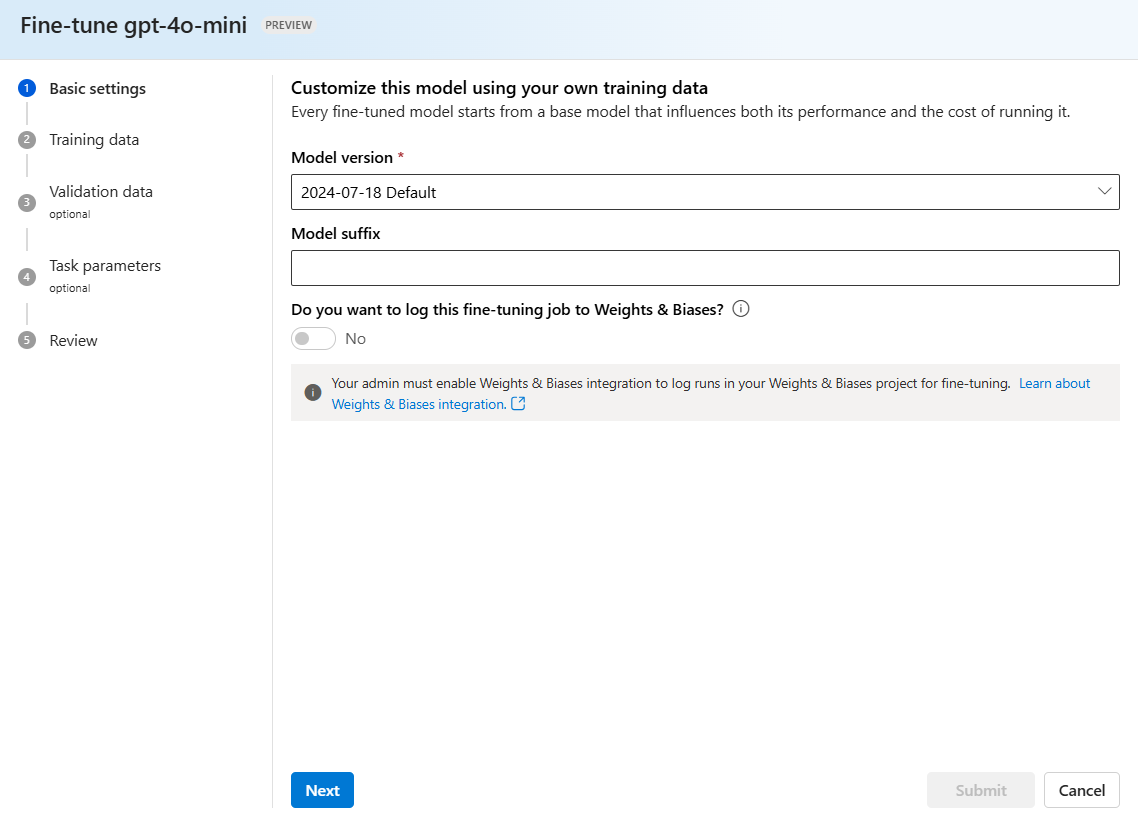
.jsonlfil med ett slumpmässigt genererat namn skapas som en träningsdatauppsättning från dina lagrade slutföranden. Välj filen >Nästa.Kommentar
Det går inte att komma åt träningsfiler för lagrad slutförande destillation direkt och kan inte exporteras externt/laddas ned.




Resten av stegen motsvarar de typiska finjusteringsstegen för Azure OpenAI. Mer information finns i vår vägledning för att komma igång med finjustering.
Utvärdering
Utvärderingen av stora språkmodeller är ett viktigt steg för att mäta deras prestanda i olika uppgifter och dimensioner. Detta är särskilt viktigt för finjusterade modeller, där bedömning av prestandavinster (eller förluster) från träning är avgörande. Noggranna utvärderingar kan hjälpa dig att förstå hur olika versioner av modellen kan påverka ditt program eller scenario.
Lagrade slutföranden kan användas som en datauppsättning för att köra utvärderingar.
I fönstret Lagrade slutföranden i Azure AI Foundry-portalen använder du filteralternativen för att välja de slutföranden som du vill ska ingå i din utvärderingsdatauppsättning.
Om du vill konfigurera utvärderingen väljer du Utvärdera
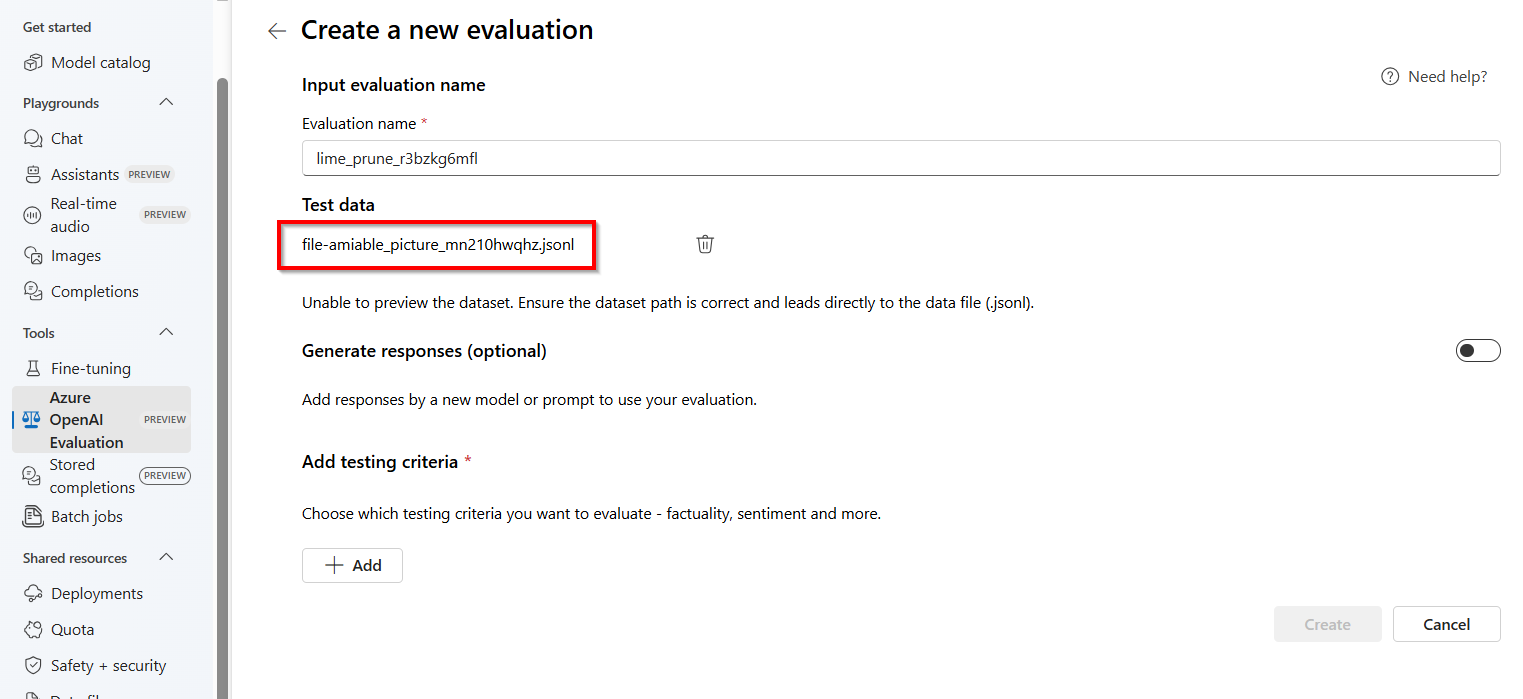
Då startas fönstret Utvärderingar med en fördefinierad
.jsonlfil med ett slumpmässigt genererat namn som skapas som en utvärderingsdatauppsättning från dina lagrade slutföranden.Kommentar
Lagrade utvärderingsdatafiler för slutförande kan inte nås direkt och kan inte exporteras externt/laddas ned.


Mer information om utvärdering finns i Komma igång med utvärderingar
Felsökning
Behöver jag särskilda behörigheter för att använda lagrade slutföranden?
Åtkomst till lagrade slutföranden styrs via två DataActions:
Microsoft.CognitiveServices/accounts/OpenAI/stored-completions/readMicrosoft.CognitiveServices/accounts/OpenAI/stored-completions/action
Som standard Cognitive Services OpenAI Contributor har åtkomst till båda dessa behörigheter:

Hur gör jag för att ta bort lagrade data?
Data kan tas bort genom att ta bort den associerade Azure OpenAI-resursen. Om du bara vill ta bort lagrade slutförandedata måste du öppna ett ärende med kundsupport.
Hur mycket lagrade slutförandedata kan jag lagra?
Du kan lagra högst 10 GB data.
Kan jag förhindra att lagrade slutföranden någonsin aktiveras i en prenumeration?
Du måste öppna ett ärende med kundsupport för att inaktivera lagrade slutföranden på prenumerationsnivå.
TypeError: Completions.create() fick ett oväntat argument "store"
Det här felet uppstår när du kör en äldre version av OpenAI-klientbiblioteket som föregår den lagrade slutförandefunktionen som släpps. Kör pip install openai --upgrade.