Azure OpenAI på dina data
Använd den här artikeln om du vill lära dig mer om Azure OpenAI På dina data, vilket gör det enklare för utvecklare att ansluta, mata in och jorda sina företagsdata för att snabbt skapa personliga andrepiloter (förhandsversion). Det förbättrar användarförståelsen, påskyndar slutförande av uppgifter, förbättrar drifteffektiviteten och underlättar beslutsfattandet.
Vad är Azure OpenAI på dina data
Med Azure OpenAI On Your Data kan du köra avancerade AI-modeller som GPT-35-Turbo och GPT-4 på dina egna företagsdata utan att behöva träna eller finjustera modeller. Du kan chatta ovanpå och analysera dina data med större noggrannhet. Du kan ange källor som stöder svaren baserat på den senaste informationen som är tillgänglig i dina avsedda datakällor. Du kan komma åt Azure OpenAI På dina data med hjälp av ett REST-API, via SDK eller det webbaserade gränssnittet i Azure OpenAI Studio. Du kan också skapa en webbapp som ansluter till dina data för att aktivera en förbättrad chattlösning eller distribuera den direkt som andrepilot i Copilot Studio (förhandsversion).
Utveckla med Azure OpenAI på dina data
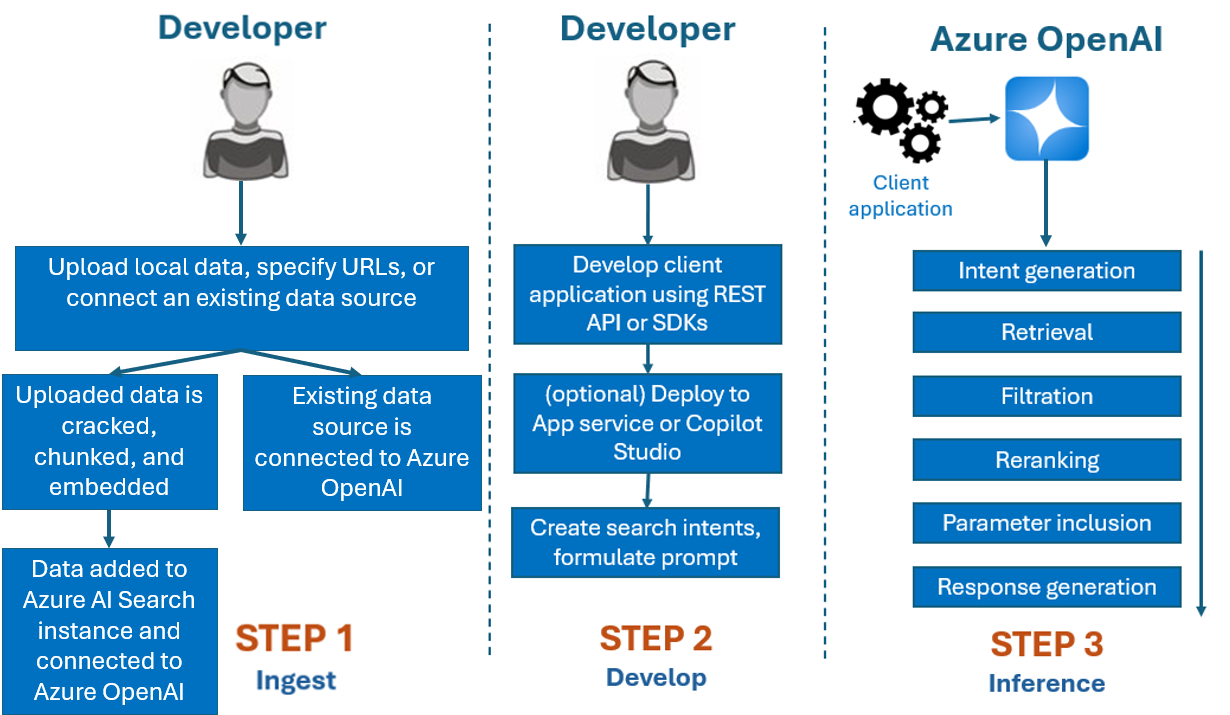
Den utvecklingsprocess som du använder med Azure OpenAI på dina data är vanligtvis:
Mata in: Ladda upp filer med antingen Azure OpenAI Studio eller inmatnings-API:et. Detta gör att dina data kan knäckas, segmenteras och bäddas in i en Azure AI Search-instans som kan användas av Azure OpenAI-modeller. Om du har en befintlig datakälla som stöds kan du även ansluta den direkt.
Utveckla: När du har provat Azure OpenAI På dina data börjar du utveckla ditt program med hjälp av det tillgängliga REST-API:et och SDK:erna, som är tillgängliga på flera språk. Den skapar uppmaningar och sökinsikter som ska skickas till Azure OpenAI-tjänsten.
Slutsatsdragning: När programmet har distribuerats i önskad miljö skickas uppmaningar till Azure OpenAI, som utför flera steg innan ett svar returneras:
Avsiktsgenerering: Tjänsten bestämmer avsikten med användarens uppmaning att fastställa ett korrekt svar.
Hämtning: Tjänsten hämtar relevanta delar av tillgängliga data från den anslutna datakällan genom att fråga den. Till exempel med hjälp av en semantisk sökning eller vektorsökning. Parametrar som strikthet och antal dokument som ska hämtas används för att påverka hämtningen.
Filtrering och omrankning: Sökresultat från hämtningssteget förbättras genom rangordning och filtrering av data för att förfina relevansen.
Svarsgenerering: Resulterande data skickas tillsammans med annan information som systemmeddelandet till LLM (Large Language Model) och svaret skickas tillbaka till programmet.
Kom igång genom att ansluta datakällan med Azure OpenAI Studio och börja ställa frågor och chatta om dina data.
Rollbaserade åtkomstkontroller i Azure (Azure RBAC) för att lägga till datakällor
Om du vill använda Azure OpenAI på dina data helt måste du ange en eller flera Azure RBAC-roller. Mer information finns i Använda Azure OpenAI på dina data på ett säkert sätt .
Dataformat och filtyper
Azure OpenAI On Your Data stöder följande filtyper:
.txt.md.html.docx.pptx.pdf
Det finns en uppladdningsgräns och det finns vissa varningar om dokumentstrukturen och hur den kan påverka kvaliteten på svar från modellen:
Om du konverterar data från ett format som inte stöds till ett format som stöds optimerar du kvaliteten på modellsvaret genom att säkerställa konverteringen:
- Leder inte till betydande dataförlust.
- Lägger inte till oväntat brus i dina data.
Om dina filer har särskild formatering, till exempel tabeller och kolumner eller punktpunkter, förbereder du dina data med det dataförberedelseskript som är tillgängligt på GitHub.
För dokument och datauppsättningar med lång text bör du använda det tillgängliga dataförberedelseskriptet. Skriptet delar upp data så att modellens svar är mer exakta. Det här skriptet stöder även skannade PDF-filer och bilder.
Datakällor som stöds
Du måste ansluta till en datakälla för att ladda upp dina data. När du vill använda dina data för att chatta med en Azure OpenAI-modell segmenteras dina data i ett sökindex så att relevanta data kan hittas baserat på användarfrågor.
Den integrerade vektordatabasen i vCore-baserade Azure Cosmos DB for MongoDB har inbyggt stöd för integrering med Azure OpenAI på dina data.
För vissa datakällor som att ladda upp filer från din lokala dator (förhandsversion) eller data som finns i ett bloblagringskonto (förhandsversion) används Azure AI Search. När du väljer följande datakällor matas dina data in i ett Azure AI Search-index.
| Data som matas in via Azure AI Search | beskrivning |
|---|---|
| Azure AI Search | Använd ett befintligt Azure AI Search-index med Azure OpenAI på dina data. |
| Ladda upp filer (förhandsversion) | Ladda upp filer från den lokala datorn som ska lagras i en Azure Blob Storage-databas och matas in i Azure AI Search. |
| URL/webbadress (förhandsversion) | Webbinnehåll från URL:erna lagras i Azure Blob Storage. |
| Azure Blob Storage (förhandsversion) | Ladda upp filer från Azure Blob Storage som ska matas in i ett Azure AI Search-index. |

- Azure AI Search
- Vector Database i Azure Cosmos DB för MongoDB
- Azure Blob Storage (förhandsversion)
- Ladda upp filer (förhandsversion)
- URL/webbadress (förhandsversion)
- Elasticsearch (förhandsversion)
- MongoDB Atlas (förhandsversion)
Du kanske vill överväga att använda ett Azure AI Search-index när du antingen vill:
- Anpassa processen för att skapa index.
- Återanvänd ett index som skapats tidigare genom att mata in data från andra datakällor.
Kommentar
- Om du vill använda ett befintligt index måste det ha minst ett sökbart fält.
- Ange alternativet CORS Allow Origin Type till
alloch alternativet Tillåtet ursprung till*.
Söktyper
Azure OpenAI På dina data innehåller följande söktyper som du kan använda när du lägger till din datakälla.
Vektorsökning med hjälp av Ada-inbäddningsmodeller som är tillgängliga i valda regioner
För att aktivera vektorsökning behöver du en befintlig inbäddningsmodell som distribuerats i din Azure OpenAI-resurs. Välj din inbäddningsdistribution när du ansluter dina data och välj sedan en av vektorsökningstyperna under Datahantering. Om du använder Azure AI Search som datakälla kontrollerar du att du har en vektorkolumn i indexet.
Om du använder ditt eget index kan du anpassa fältmappningen när du lägger till datakällan för att definiera de fält som mappas när du svarar på frågor. Om du vill anpassa fältmappning väljer du Använd anpassad fältmappning på sidan Datakälla när du lägger till datakällan.
Viktigt!
- Semantisk sökning omfattas av ytterligare priser. Du måste välja Grundläggande eller högre SKU för att aktivera semantisk sökning eller vektorsökning. Mer information finns i prisnivåskillnad och tjänstgränser .
- För att förbättra kvaliteten på svar på informationshämtningen och modellsvaret rekommenderar vi att du aktiverar semantisk sökning för följande datakällspråk: engelska, franska, spanska, portugisiska, italienska, tyska, kinesiska (zh), japanska, koreanska, ryska och arabiska.
| Sökalternativ | Hämtningstyp | Ytterligare priser? | Förmåner |
|---|---|---|---|
| nyckelord | Nyckelordssökning | Inga ytterligare priser. | Utför snabb och flexibel frågeparsing och matchning över sökbara fält med hjälp av termer eller fraser på alla språk som stöds, med eller utan operatorer. |
| semantisk | Semantisk sökning | Ytterligare priser för användning av semantisk sökning . | Förbättrar precisionen och relevansen för sökresultat med hjälp av en reranker (med AI-modeller) för att förstå den semantiska innebörden av frågetermer och dokument som returneras av den första sökrankningen |
| vektor | Vektorsökning | Ytterligare priser för ditt Azure OpenAI-konto från att anropa inbäddningsmodellen. | Gör att du kan hitta dokument som liknar en viss frågeindata baserat på vektorinbäddning av innehållet. |
| hybrid (vektor + nyckelord) | En hybrid av vektorsökning och nyckelordssökning | Ytterligare priser för ditt Azure OpenAI-konto från att anropa inbäddningsmodellen. | Utför likhetssökning över vektorfält med hjälp av vektorinbäddningar, samtidigt som det stöder flexibel frågeparsing och fulltextsökning över alfanumeriska fält med termfrågor. |
| hybrid (vektor + nyckelord) + semantisk | En hybrid av vektorsökning, semantisk sökning och nyckelordssökning. | Ytterligare priser för ditt Azure OpenAI-konto från att anropa inbäddningsmodellen och ytterligare priser för användning av semantisk sökning . | Använder vektorinbäddningar, språktolkning och flexibel frågeparsing för att skapa omfattande sökupplevelser och generativa AI-appar som kan hantera komplexa och olika scenarier för informationshämtning. |
Intelligent sökning
Azure OpenAI På dina data har intelligent sökning aktiverat för dina data. Semantisk sökning är aktiverat som standard om du har både semantisk sökning och nyckelordssökning. Om du har inbäddningsmodeller är intelligent sökning standard för hybrid - och semantisk sökning.
Åtkomstkontroll på dokumentnivå
Kommentar
Åtkomstkontroll på dokumentnivå stöds när du väljer Azure AI Search som datakälla.
Med Azure OpenAI På dina data kan du begränsa de dokument som kan användas som svar för olika användare med Säkerhetsfilter för Azure AI Search. När du aktiverar åtkomst på dokumentnivå trimmas sökresultaten som returneras från Azure AI Search och används för att generera ett svar baserat på användarens Microsoft Entra-gruppmedlemskap. Du kan bara aktivera åtkomst på dokumentnivå för befintliga Azure AI Search-index i Använda Azure OpenAI på dina data på ett säkert sätt för mer information.
Mappning av indexfält
Om du använder ditt eget index uppmanas du i Azure OpenAI Studio att definiera vilka fält som du vill mappa för att besvara frågor när du lägger till datakällan. Du kan ange flera fält för innehållsdata och inkludera alla fält som har text som hör till ditt användningsfall.

I det här exemplet ger fälten som mappas till Innehållsdata och Rubrik information till modellen för att besvara frågor. Rubrik används också för rubrikciteringstext. Fältet som mappas till Filnamn genererar källhänvisningsnamnen i svaret.
Genom att mappa dessa fält på rätt sätt ser du till att modellen har bättre svars- och källhänvisningskvalitet. Du kan även konfigurera den i API :et med hjälp av parametern fieldsMapping .
Sökfilter (API)
Om du vill implementera ytterligare värdebaserade kriterier för frågekörning kan du konfigurera ett sökfilter med hjälp av parametern filter i REST-API:et.
Hur data matas in i Azure AI-sökning
Från och med september 2024 bytte inmatnings-API:erna till integrerad vektorisering. Den här uppdateringen ändrar inte befintliga API-kontrakt. Integrerad vektorisering, ett nytt erbjudande för Azure AI Search, använder fördefinierade kunskaper för segmentering och inbäddning av indata. Azure OpenAI On Your Data Ingestion-tjänsten använder inte längre anpassade kunskaper. Efter migreringen till integrerad vektorisering har inmatningsprocessen genomgått vissa ändringar och därför skapas endast följande tillgångar:
{job-id}-index{job-id}-indexer, om ett schema per timme eller dagligen anges rensas indexeraren i slutet av inmatningsprocessen.{job-id}-datasource
Segmentcontainern är inte längre tillgänglig eftersom den här funktionen nu hanteras av Azure AI Search.
Dataanslutning
Du måste välja hur du vill autentisera anslutningen från Azure OpenAI, Azure AI Search och Azure Blob Storage. Du kan välja en systemtilldelad hanterad identitet eller en API-nyckel. Genom att välja API-nyckel som autentiseringstyp fyller systemet automatiskt i API-nyckeln så att du kan ansluta med dina Azure AI Search-, Azure OpenAI- och Azure Blob Storage-resurser. Genom att välja Systemtilldelad hanterad identitet baseras autentiseringen på den rolltilldelning du har. Systemtilldelad hanterad identitet väljs som standard för säkerhet.

När du väljer nästa knapp valideras konfigurationen automatiskt för att använda den valda autentiseringsmetoden. Om du får ett fel kan du läsa artikeln om rolltilldelningar för att uppdatera konfigurationen.
När du har korrigerat konfigurationen väljer du nästa gång för att verifiera och fortsätta. API-användare kan också konfigurera autentisering med tilldelad hanterad identitet och API-nycklar.









Distribuera till en copilot (förhandsversion), Teams-app (förhandsversion) eller webbapp
När du har anslutit Azure OpenAI till dina data kan du distribuera dem med knappen Distribuera till i Azure OpenAI Studio.

Detta ger dig flera alternativ för att distribuera din lösning.
Du kan distribuera till en andrepilot i Copilot Studio (förhandsversion) direkt från Azure OpenAI Studio, så att du kan använda konversationsupplevelser till olika kanaler som: Microsoft Teams, webbplatser, Dynamics 365 och andra Azure Bot Service-kanaler. Klientorganisationen som används i Azure OpenAI-tjänsten och Copilot Studio (förhandsversion) bör vara densamma. Mer information finns i Använda en anslutning till Azure OpenAI på dina data.
Kommentar
Distribution till en andrepilot i Copilot Studio (förhandsversion) är endast tillgängligt i amerikanska regioner.
Använda Azure OpenAI på dina data på ett säkert sätt
Du kan använda Azure OpenAI på dina data på ett säkert sätt genom att skydda data och resurser med rollbaserad åtkomstkontroll i Microsoft Entra-ID, virtuella nätverk och privata slutpunkter. Du kan också begränsa de dokument som kan användas som svar för olika användare med Säkerhetsfilter för Azure AI Search. Se Använda Azure OpenAI på dina data på ett säkert sätt.
Bästa praxis
Använd följande avsnitt för att lära dig hur du förbättrar kvaliteten på svar som ges av modellen.
Inmatningsparameter
När dina data matas in i Azure AI Search kan du ändra följande ytterligare inställningar i antingen studio- eller inmatnings-API:et.
Segmentstorlek (förhandsversion)
Azure OpenAI On Your Data bearbetar dina dokument genom att dela upp dem i segment innan de matas in. Segmentstorleken är den maximala storleken när det gäller antalet token för ett segment i sökindexet. Segmentstorlek och antalet hämtade dokument styr tillsammans hur mycket information (token) som ingår i uppmaningen som skickas till modellen. I allmänhet är segmentstorleken multiplicerad med antalet hämtade dokument det totala antalet token som skickas till modellen.
Ange segmentstorlek för ditt användningsfall
Standardstorleken för segment är 1 024 token. Men med tanke på att dina data är unika kan du hitta en annan segmentstorlek (till exempel 256, 512 eller 1 536 token) effektivare.
Om du justerar segmentstorleken kan du förbättra chattrobotens prestanda. Det krävs en del utvärderings- och fel för att hitta den optimala segmentstorleken, men börja med att tänka på vilken typ av datauppsättning du har. En mindre segmentstorlek är vanligtvis bättre för datauppsättningar med direkta fakta och mindre kontext, medan en större segmentstorlek kan vara fördelaktig för mer sammanhangsberoende information, även om det kan påverka hämtningsprestanda.
En liten segmentstorlek som 256 ger mer detaljerade segment. Den här storleken innebär också att modellen använder färre token för att generera sina utdata (såvida inte antalet hämtade dokument är mycket högt), vilket kan kosta mindre. Mindre segment innebär också att modellen inte behöver bearbeta och tolka långa delar av text, vilket minskar brus och distraktion. Den här kornigheten och fokuset utgör dock ett potentiellt problem. Viktig information kanske inte finns bland de mest hämtade segmenten, särskilt om antalet hämtade dokument är inställt på ett lågt värde som 3.
Dricks
Tänk på att ändring av segmentstorleken kräver att dina dokument matas in igen, så det är användbart att först justera körningsparametrar som strikthet och antalet hämtade dokument. Överväg att ändra segmentstorleken om du fortfarande inte får önskat resultat:
- Om du stöter på ett stort antal svar, till exempel "Jag vet inte" för frågor med svar som bör finnas i dina dokument, bör du överväga att minska segmentstorleken till 256 eller 512 för att förbättra kornigheten.
- Om chattroboten ger rätt information men saknar andra, vilket blir uppenbart i citaten, kan en ökning av segmentstorleken till 1 536 hjälpa till att samla in mer kontextuell information.
Körningsparametrar
Du kan ändra följande ytterligare inställningar i avsnittet Dataparametrar i Azure OpenAI Studio och API:et. Du behöver inte ange dina data igen när du uppdaterar dessa parametrar.
| Parameternamn | beskrivning |
|---|---|
| Begränsa svar på dina data | Den här flaggan konfigurerar chattrobotens metod för att hantera frågor som inte är relaterade till datakällan eller när sökdokumenten inte räcker till för ett fullständigt svar. När den här inställningen är inaktiverad kompletterar modellen sina svar med sina egna kunskaper utöver dina dokument. När den här inställningen är aktiverad försöker modellen bara förlita sig på dina dokument för svar. Det här är parametern inScope i API:et och inställd på true som standard. |
| Hämtade dokument | Den här parametern är ett heltal som kan anges till 3, 5, 10 eller 20 och styr antalet dokumentsegment som tillhandahålls till den stora språkmodellen för att formulera det slutliga svaret. Som standard är detta inställt på 5. Sökprocessen kan vara bullrig och ibland, på grund av segmentering, kan relevant information spridas över flera segment i sökindexet. Om du väljer ett topp-K-nummer, till exempel 5, ser du till att modellen kan extrahera relevant information, trots de inneboende begränsningarna för sökning och segmentering. Men att öka antalet för högt kan potentiellt distrahera modellen. Dessutom beror det maximala antalet dokument som kan användas effektivt på modellens version, eftersom var och en har olika kontextstorlek och kapacitet för att hantera dokument. Om du upptäcker att svar saknar viktig kontext kan du prova att öka den här parametern. Det här är parametern topNDocuments i API:et och är 5 som standard. |
| Strikthet | Avgör systemets aggressivitet vid filtrering av sökdokument baserat på deras likhetspoäng. Systemet frågar Azure Search eller andra dokumentlager och bestämmer sedan vilka dokument som ska tillhandahållas till stora språkmodeller som ChatGPT. Om du filtrerar bort irrelevanta dokument kan du avsevärt förbättra prestandan för chattroboten från slutpunkt till slutpunkt. Vissa dokument undantas från top-K-resultaten om de har låga likhetspoäng innan de vidarebefordras till modellen. Detta styrs av ett heltalsvärde mellan 1 och 5. Om det här värdet anges till 1 innebär det att systemet filtrerar dokument minimalt baserat på söklikhet i användarfrågan. Omvänt anger en inställning på 5 att systemet aggressivt filtrerar bort dokument och tillämpar ett mycket högt tröskelvärde för likhet. Om du upptäcker att chattroboten utelämnar relevant information sänker du filtrets strikthet (ange värdet närmare 1) för att inkludera fler dokument. Omvänt, om irrelevanta dokument distraherar svaren, öka tröskelvärdet (ange värdet närmare 5). Det här är parametern strictness i API:et och inställd på 3 som standard. |
Ej citerade referenser
Det är möjligt för modellen att returnera "TYPE":"UNCITED_REFERENCE" i stället "TYPE":CONTENT för i API:et för dokument som hämtas från datakällan, men som inte ingår i källhänvisning. Detta kan vara användbart för felsökning och du kan styra det här beteendet genom att ändra de strikta och hämtade dokumentkörningsparametrarna som beskrivs ovan.
Systemmeddelande
Du kan definiera ett systemmeddelande för att styra modellens svar när du använder Azure OpenAI på dina data. Med det här meddelandet kan du anpassa dina svar ovanpå rag-mönstret (hämtningsförhöjd generation) som Azure OpenAI On Your Data använder. Systemmeddelandet används utöver en intern basprompt för att tillhandahålla upplevelsen. För att stödja detta trunkerar vi systemmeddelandet efter ett visst antal token för att säkerställa att modellen kan svara på frågor med dina data. Om du definierar extra beteende utöver standardupplevelsen kontrollerar du att systemprompten är detaljerad och förklarar den exakta förväntade anpassningen.
När du har valt att lägga till din datauppsättning kan du använda avsnittet Systemmeddelande i Azure OpenAI Studio eller parametern role_information i API:et.

Potentiella användningsmönster
Definiera en roll
Du kan definiera en roll som du vill ha din assistent. Om du till exempel skapar en supportrobot kan du lägga till "Du är en supportassistent för expertincidenter som hjälper användarna att lösa nya problem".
Definiera vilken typ av data som hämtas
Du kan också lägga till den typ av data som du tillhandahåller till assistenten.
- Definiera ämnet eller omfånget för din datauppsättning, till exempel "finansiell rapport", "akademisk uppsats" eller "incidentrapport". För teknisk support kan du till exempel lägga till "Du besvarar frågor med hjälp av information från liknande incidenter i de hämtade dokumenten".
- Om dina data har vissa egenskaper kan du lägga till den här informationen i systemmeddelandet. Om dina dokument till exempel är på japanska kan du lägga till "Du hämtar japanska dokument och bör läsa dem noggrant på japanska och svara på japanska".
- Om dina dokument innehåller strukturerade data som tabeller från en finansiell rapport kan du också lägga till detta faktum i systemprompten. Om dina data till exempel har tabeller kan du lägga till "Du får data i form av tabeller som rör ekonomiska resultat och du bör läsa tabellen rad för rad för att utföra beräkningar för att besvara användarfrågor".
Definiera utdataformatet
Du kan också ändra modellens utdata genom att definiera ett systemmeddelande. Om du till exempel vill se till att assistentsvaren är på franska kan du lägga till en uppmaning som "Du är en AI-assistent som hjälper användare som förstår franska att hitta information. Användarfrågorna kan vara på engelska eller franska. Läs de hämtade dokumenten noggrant och besvara dem på franska. Översätt kunskapen från dokument till franska för att säkerställa att alla svar är på franska."
Bekräfta kritiskt beteende
Azure OpenAI On Your Data fungerar genom att skicka instruktioner till en stor språkmodell i form av uppmaningar för att besvara användarfrågor med dina data. Om det finns ett visst beteende som är kritiskt för programmet kan du upprepa beteendet i systemmeddelandet för att öka dess noggrannhet. Om du till exempel vill vägleda modellen att bara svara från dokument kan du lägga till "Svara endast med hämtade dokument och utan att använda dina kunskaper. Generera citat till hämtade dokument för varje anspråk i ditt svar. Om användarfrågan inte kan besvaras med hjälp av hämtade dokument förklarar du varför dokument är relevanta för användarfrågor. I vilket fall som helst, svara inte med dina egna kunskaper."
Prompt Engineering tricks
Det finns många knep inom snabbteknik som du kan försöka förbättra utdata. Ett exempel är en tankekedja där du kan lägga till "Låt oss tänka steg för steg om information i hämtade dokument för att besvara användarfrågor. Extrahera relevant kunskap till användarfrågor från dokument steg för steg och skapa ett svar nedifrån och upp från den extraherade informationen från relevanta dokument."
Kommentar
Systemmeddelandet används för att ändra hur GPT-assistenten svarar på en användarfråga baserat på hämtad dokumentation. Det påverkar inte hämtningsprocessen. Om du vill ge instruktioner för hämtningsprocessen är det bättre att ta med dem i frågorna. Systemmeddelandet är bara vägledning. Modellen kanske inte följer alla angivna instruktioner eftersom den har förberetts med vissa beteenden, till exempel objektivitet, och för att undvika kontroversiella uttalanden. Oväntat beteende kan inträffa om systemmeddelandet strider mot dessa beteenden.
Maximalt svar
Ange en gräns för antalet token per modellsvar. Den övre gränsen för Azure OpenAI På dina data är 1 500. Detta motsvarar inställningen av parametern max_tokens i API:et.
Begränsa svar på dina data
Det här alternativet uppmuntrar modellen att endast svara med dina data och är valt som standard. Om du avmarkerar det här alternativet kan modellen lättare använda sina interna kunskaper för att svara. Fastställ rätt val baserat på ditt användningsfall och scenario.
Interagera med modellen
Använd följande metoder för bästa resultat när du chattar med modellen.
Konversationshistorik
- Innan du startar en ny konversation (eller ställer en fråga som inte är relaterad till de tidigare) rensar du chatthistoriken.
- Att få olika svar för samma fråga mellan den första konversationssvängen och efterföljande svängar kan förväntas eftersom konversationshistoriken ändrar modellens aktuella tillstånd. Om du får felaktiga svar rapporterar du det som ett kvalitetsfel.
Modellsvar
Om du inte är nöjd med modellsvaret för en specifik fråga kan du prova att antingen göra frågan mer specifik eller mer allmän för att se hur modellen svarar och omrama frågan i enlighet med detta.
Tankekedjan har visat sig vara effektiv när det gäller att få modellen att producera önskade utdata för komplexa frågor/uppgifter.
Frågelängd
Undvik att ställa långa frågor och dela upp dem i flera frågor om möjligt. GPT-modellerna har gränser för hur många token de kan acceptera. Tokengränser räknas mot: användarfrågan, systemmeddelandet, hämtade sökdokument (segment), interna frågor, konversationshistoriken (om någon) och svaret. Om frågan överskrider tokengränsen trunkeras den.
Stöd för flera språk
För närvarande har nyckelordssökning och semantisk sökning i Azure OpenAI On Your Data stöd för frågor på samma språk som data i indexet. Om dina data till exempel finns på japanska måste indatafrågor också finnas på japanska. För hämtning av flerspråkiga dokument rekommenderar vi att du skapar indexet med Vector Search aktiverat.
För att förbättra kvaliteten på svar på informationshämtning och modell rekommenderar vi att du aktiverar semantisk sökning efter följande språk: engelska, franska, spanska, portugisiska, italienska, Tyskland, kinesiska(Zh), japanska, koreanska, ryska, arabiska
Vi rekommenderar att du använder ett systemmeddelande för att informera modellen om att dina data är på ett annat språk. Till exempel:
*"*Du är en AI-assistent som är utformad för att hjälpa användare att extrahera information från hämtade japanska dokument. Granska de japanska dokumenten noggrant innan du formulerar ett svar. Användarens fråga kommer att finnas på japanska, och du måste även ta svar på japanska."
Om du har dokument på flera språk rekommenderar vi att du skapar ett nytt index för varje språk och ansluter dem separat till Azure OpenAI.
Strömma data
Du kan skicka en strömningsbegäran med hjälp av parametern stream så att data kan skickas och tas emot stegvis, utan att vänta på hela API-svaret. Detta kan förbättra prestanda och användarupplevelse, särskilt för stora eller dynamiska data.
{
"stream": true,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"indexName": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure AI services?"
}
]
}
Konversationshistorik för bättre resultat
När du chattar med en modell kan en historik för chatten hjälpa modellen att returnera resultat av högre kvalitet. Du behöver inte inkludera context egenskapen för assistentmeddelandena i dina API-begäranden för bättre svarskvalitet. Exempel finns i API-referensdokumentationen .
Funktionsanrop
Med vissa Azure OpenAI-modeller kan du definiera verktyg och tool_choice parametrar för att aktivera funktionsanrop. Du kan konfigurera funktionsanrop via REST API /chat/completions. Om både tools och datakällor finns i begäran tillämpas följande princip.
- Om
tool_choiceärnoneignoreras verktygen och endast datakällorna används för att generera svaret. - Annars ignoreras datakällorna om
tool_choicede inte har angetts eller angetts somautoeller ett objekt, och svaret innehåller det valda funktionsnamnet och eventuella argument. Även om modellen beslutar att ingen funktion har valts ignoreras fortfarande datakällorna.
Om principen ovan inte uppfyller dina behov bör du överväga andra alternativ, till exempel promptflöde eller API för assistenter.
Uppskattning av tokenanvändning för Azure OpenAI på dina data
Azure OpenAI On Your Data Retrieval Augmented Generation (RAG) är en tjänst som utnyttjar både en söktjänst (till exempel Azure AI Search) och generering (Azure OpenAI-modeller) för att låta användarna få svar på sina frågor baserat på angivna data.
Som en del av den här RAG-pipelinen finns det tre steg på hög nivå:
Omformulera användarfrågan till en lista över sökinsikter. Detta görs genom att göra ett anrop till modellen med en uppmaning som innehåller instruktioner, användarfrågan och konversationshistorik. Nu ska vi kalla detta en avsiktsfråga.
För varje avsikt hämtas flera dokumentsegment från söktjänsten. När du har filtrerat bort irrelevanta segment baserat på det användardefinierade tröskelvärdet för strikthet och reranking/aggregering av segmenten baserat på intern logik väljs det användardefinierade antalet dokumentsegment.
Dessa dokumentsegment, tillsammans med användarfrågan, konversationshistorik, rollinformation och instruktioner skickas till modellen för att generera det slutliga modellsvaret. Nu ska vi anropa generationsprompten.
Totalt görs två anrop till modellen:
För bearbetning av avsikten: Tokenuppskattningen för avsiktsprompten innehåller de för användarfrågan, konversationshistoriken och instruktionerna som skickas till modellen för avsiktsgenerering.
För att generera svaret: Tokenuppskattningen för generationsprompten innehåller de för användarfrågan, konversationshistoriken, den hämtade listan över dokumentsegment, rollinformation och instruktionerna som skickas till den för generering.
Modellen genererade utdatatoken (både avsikter och svar) måste beaktas för total tokenuppskattning. Om du summerar alla fyra kolumnerna nedan får du de genomsnittliga totala token som används för att generera ett svar.
| Modell | Antal token för genereringsprompt | Antal token för avsiktsprompt | Antal svarstoken | Antal avsiktstoken |
|---|---|---|---|---|
| gpt-35-turbo-16k | 4297 | 1366 | 111 | 25 |
| gpt-4-0613 | 3997 | 1385 | 118 | 18 |
| gpt-4-1106-preview | 4538 | 811 | 119 | 27 |
| gpt-35-turbo-1106 | 4854 | 1372 | 110 | 26 |
Ovanstående tal baseras på testning av en datauppsättning med:
- 191 konversationer
- 250 frågor
- 10 genomsnittliga token per fråga
- 4 konversationsvändningar per konversation i genomsnitt
Och följande parametrar.
| Inställning | Värde |
|---|---|
| Antal hämtade dokument | 5 |
| Strikthet | 3 |
| Segmentstorlek | 1024 |
| Vill du begränsa svar till inmatade data? | Sant |
Dessa uppskattningar varierar beroende på de värden som anges för ovanstående parametrar. Om till exempel antalet hämtade dokument är inställt på 10 och striktheten är inställd på 1, ökar antalet token. Om returnerade svar inte är begränsade till inmatade data finns det färre instruktioner som ges till modellen och antalet token kommer att minska.
Uppskattningarna beror också på dokumentens art och de frågor som ställs. Om frågorna till exempel är öppna kommer svaren sannolikt att bli längre. På samma sätt skulle ett längre systemmeddelande bidra till en längre fråga som förbrukar fler token, och om konversationshistoriken är lång blir prompten längre.
| Modell | Maximalt antal token för systemmeddelande |
|---|---|
| GPT-35-0301 | 400 |
| GPT-35-0613-16K | 1000 |
| GPT-4-0613-8K | 400 |
| GPT-4-0613-32K | 2000 |
| GPT-35-turbo-0125 | 2000 |
| GPT-4-turbo-0409 | 4000 |
| GPT-4o | 4000 |
| GPT-4o-mini | 4000 |
Tabellen ovan visar det maximala antalet token som kan användas för systemmeddelandet. Mer information om hur du ser maximala token för modellsvaret finns i artikeln modeller. Dessutom använder följande även token:
Metaprompten: Om du begränsar svar från modellen till grunddatainnehållet (
inScope=Truei API:et) är det maximala antalet token högre. Annars (till exempel ominScope=False) är maxvärdet lägre. Det här talet är variabelt beroende på tokenlängden för användarens fråga och konversationshistorik. Den här uppskattningen inkluderar basprompten och frågan som skriver om prompter för hämtning.Användarfråga och historik: Variabel men begränsad till 2 000 token.
Hämtade dokument (segment): Antalet token som används av de hämtade dokumentsegmenten beror på flera faktorer. Den övre gränsen för detta är antalet hämtade dokumentsegment multiplicerat med segmentstorleken. Den trunkeras dock baserat på de token som är tillgängliga token för den specifika modell som används efter att resten av fälten har räknats.
20 % av de tillgängliga token är reserverade för modellsvaret. De återstående 80 % av tillgängliga token är metaprompten, användarfrågan och konversationshistoriken och systemmeddelandet. Den återstående tokenbudgeten används av de hämtade dokumentsegmenten.
För att beräkna antalet token som förbrukas av dina indata (till exempel din fråga, systemmeddelandet/rollinformationen) använder du följande kodexempel.
import tiktoken
class TokenEstimator(object):
GPT2_TOKENIZER = tiktoken.get_encoding("gpt2")
def estimate_tokens(self, text: str) -> int:
return len(self.GPT2_TOKENIZER.encode(text))
token_output = TokenEstimator.estimate_tokens(input_text)
Felsökning
Om du vill felsöka misslyckade åtgärder bör du alltid hålla utkik efter fel eller varningar som anges i API-svaret eller Azure OpenAI Studio. Här är några av de vanligaste felen och varningarna:
Misslyckade inmatningsjobb
Problem med kvotbegränsningar
Det gick inte att skapa ett index med namnet X i tjänst Y. Indexkvoten har överskridits för den här tjänsten. Du måste antingen ta bort oanvända index först, lägga till en fördröjning mellan begäranden om att skapa index eller uppgradera tjänsten för högre gränser.
Standardindexeringskvoten för X har överskridits för den här tjänsten. Du har för närvarande X-standardindexerare. Du måste antingen ta bort oanvända indexerare först, ändra indexeraren "executionMode" eller uppgradera tjänsten för högre gränser.
Lösning:
Uppgradera till en högre prisnivå eller ta bort oanvända tillgångar.
Problem med tidsgränser för förbearbetning
Det gick inte att köra färdigheten eftersom webb-API-begäran misslyckades
Det gick inte att köra färdigheten eftersom webb-API:ets kompetenssvar är ogiltigt
Lösning:
Dela upp indatadokumenten i mindre dokument och försök igen.
Problem med behörigheter
Den här begäran har inte behörighet att utföra den här åtgärden
Lösning:
Det innebär att lagringskontot inte är tillgängligt med de angivna autentiseringsuppgifterna. I det här fallet granskar du autentiseringsuppgifterna för lagringskontot som skickas till API:et och kontrollerar att lagringskontot inte är dolt bakom en privat slutpunkt (om en privat slutpunkt inte har konfigurerats för den här resursen).
503-fel när du skickar frågor med Azure AI Search
Varje användarmeddelande kan översättas till flera sökfrågor, som alla skickas till sökresursen parallellt. Detta kan ge begränsningsbeteende när antalet sökrepliker och partitioner är lågt. Det maximala antalet frågor per sekund som en enskild partition och en enskild replik kan stödja kanske inte räcker. I det här fallet bör du överväga att öka dina repliker och partitioner eller lägga till vilo-/återförsökslogik i ditt program. Mer information finns i dokumentationen för Azure AI Search.
Regional tillgänglighet och modellstöd
| Region | gpt-35-turbo-16k (0613) |
gpt-35-turbo (1106) |
gpt-4-32k (0613) |
gpt-4 (1106-preview) |
gpt-4 (0125-preview) |
gpt-4 (0613) |
gpt-4o** |
gpt-4 (turbo-2024-04-09) |
|---|---|---|---|---|---|---|---|---|
| Australien, östra | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Östra Kanada | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| East US | ✅ | ✅ | ✅ | |||||
| USA, östra 2 | ✅ | ✅ | ✅ | ✅ | ||||
| Centrala Frankrike | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Japan, östra | ✅ | |||||||
| USA, norra centrala | ✅ | ✅ | ✅ | |||||
| Norge, östra | ✅ | ✅ | ||||||
| USA, södra centrala | ✅ | ✅ | ||||||
| Indien, södra | ✅ | ✅ | ||||||
| Sverige, centrala | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Schweiz, norra | ✅ | ✅ | ✅ | |||||
| Södra Storbritannien | ✅ | ✅ | ✅ | ✅ | ||||
| Västra USA | ✅ | ✅ | ✅ |
**Det här är en textimplementering
Om din Azure OpenAI-resurs finns i en annan region kan du inte använda Azure OpenAI på dina data.