Snabbstart: Kom igång med hjälp av Azure OpenAI-ljudgenerering
Modellerna gpt-4o-audio-preview och gpt-4o-mini-audio-preview introducerar ljudmodaliteten i det befintliga /chat/completions API:et. Ljudmodellen utökar potentialen för AI-program i text- och röstbaserade interaktioner och ljudanalys. Metoder som stöds i gpt-4o-audio-preview och gpt-4o-mini-audio-preview modeller är: text, ljud och text + ljud.
Här är en tabell över de metoder som stöds med exempel på användningsfall:
| Modalitetsindata | Modalitetsutdata | Exempel på användningsfall |
|---|---|---|
| Text | Text + ljud | Text till tal, ljudboksgenerering |
| Ljud | Text + ljud | Ljudranskription, ljudboksgenerering |
| Ljud | Text | Ljudavskrift |
| Text + ljud | Text + ljud | Ljudboksgenerering |
| Text + ljud | Text | Ljudavskrift |
Genom att använda funktioner för ljudgenerering kan du uppnå mer dynamiska och interaktiva AI-program. Modeller som stöder ljudindata och utdata gör att du kan generera talade ljudsvar till uppmaningar och använda ljudindata för att fråga modellen.
Modeller som stöds
gpt-4o-audio-preview Endast för närvarande och gpt-4o-mini-audio-preview version: 2024-12-17 stöder ljudgenerering.
Mer information om regiontillgänglighet finns i dokumentationen för modeller och versioner.
För närvarande stöds följande röster för ljud ut: Alloy, Echo och Shimmer.
Den maximala ljudfilstorleken är 20 MB.
Kommentar
Realtids-API:et använder samma underliggande GPT-4o-ljudmodell som API:et för slutföranden, men är optimerat för ljudinteraktioner med låg latens i realtid.
API-stöd
Stöd för ljudavslut lades först till i API-version 2025-01-01-preview.
Distribuera en modell för ljudgenerering
Så här distribuerar gpt-4o-mini-audio-preview du modellen i Azure AI Foundry-portalen:
- Gå till sidan Azure OpenAI Service i Azure AI Foundry-portalen. Kontrollera att du är inloggad med Azure-prenumerationen som har din Azure OpenAI Service-resurs och den distribuerade
gpt-4o-mini-audio-previewmodellen. - Välj chattlekplatsen under Lekplatser i den vänstra rutan.
- Välj + Skapa ny distribution>Från basmodeller för att öppna distributionsfönstret.
- Sök efter och välj
gpt-4o-mini-audio-previewmodellen och välj sedan Distribuera till vald resurs. - I distributionsguiden väljer du
2024-12-17modellversionen. - Följ guiden för att slutföra distributionen av modellen.
Nu när du har en distribution av modellen kan du interagera med den gpt-4o-mini-audio-preview i Azure AI Foundry-portalens API för chattlekplats eller slutförande av chattar.
Använda GPT-4o-ljudgenerering
Om du vill chatta med din distribuerade gpt-4o-mini-audio-preview modell i Chattlekplatsenför Azure AI Foundry-portalen följer du dessa steg:
Gå till sidan Azure OpenAI Service i Azure AI Foundry-portalen. Kontrollera att du är inloggad med Azure-prenumerationen som har din Azure OpenAI Service-resurs och den distribuerade
gpt-4o-mini-audio-previewmodellen.Välj Chattlekplats under Resurslekplats i den vänstra rutan.
Välj din distribuerade
gpt-4o-mini-audio-previewmodell i listrutan Distribution .Börja chatta med modellen och lyssna på ljudsvaren.
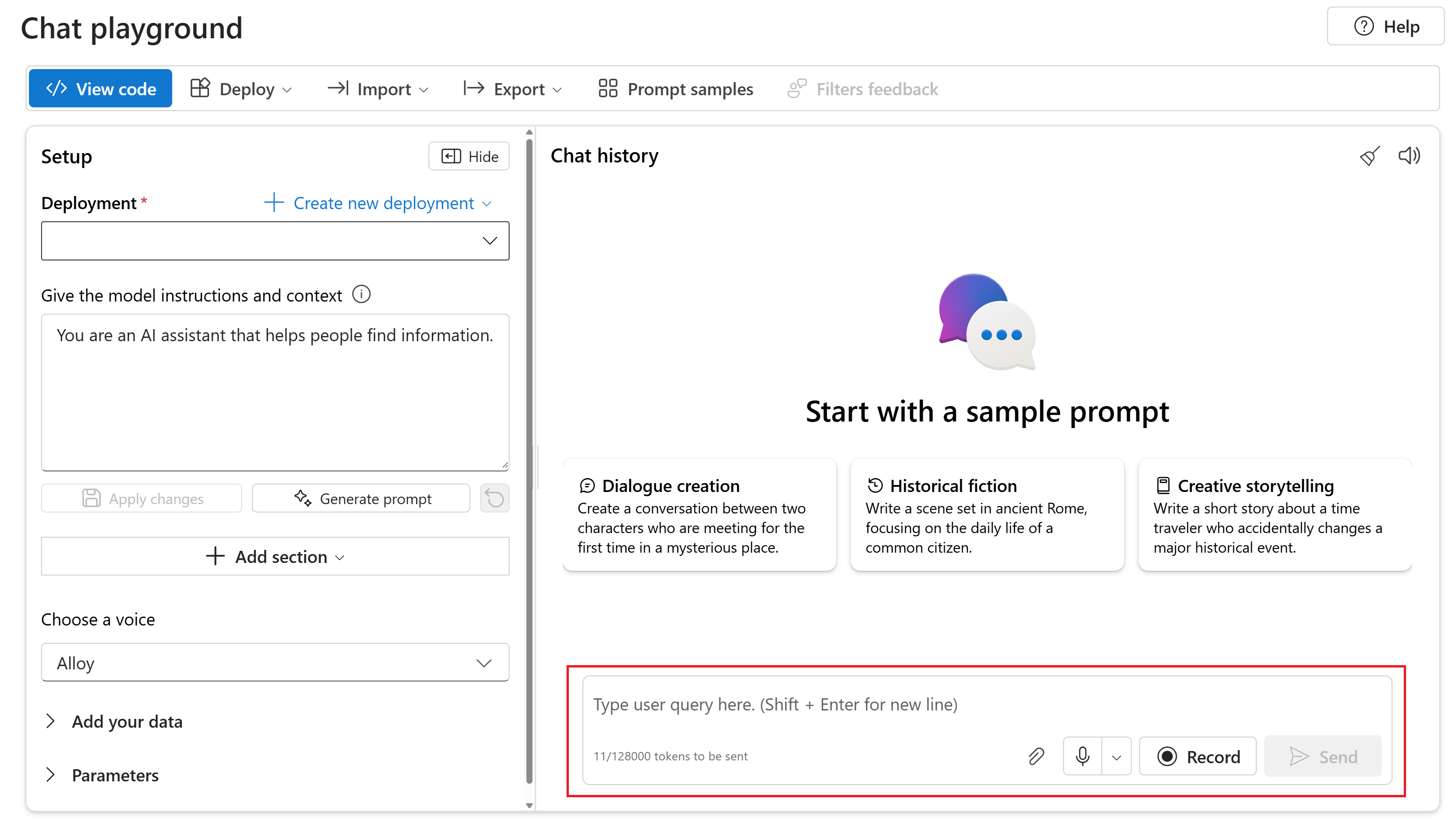
Du kan:
- Spela in ljudprompter.
- Bifoga ljudfiler i chatten.
- Ange textprompter.

Referensdokumentation Bibliotek källkodspaket | (npm)Exempel | |
Modellerna gpt-4o-audio-preview och gpt-4o-mini-audio-preview introducerar ljudmodaliteten i det befintliga /chat/completions API:et. Ljudmodellen utökar potentialen för AI-program i text- och röstbaserade interaktioner och ljudanalys. Metoder som stöds i gpt-4o-audio-preview och gpt-4o-mini-audio-preview modeller är: text, ljud och text + ljud.
Här är en tabell över de metoder som stöds med exempel på användningsfall:
| Modalitetsindata | Modalitetsutdata | Exempel på användningsfall |
|---|---|---|
| Text | Text + ljud | Text till tal, ljudboksgenerering |
| Ljud | Text + ljud | Ljudranskription, ljudboksgenerering |
| Ljud | Text | Ljudavskrift |
| Text + ljud | Text + ljud | Ljudboksgenerering |
| Text + ljud | Text | Ljudavskrift |
Genom att använda funktioner för ljudgenerering kan du uppnå mer dynamiska och interaktiva AI-program. Modeller som stöder ljudindata och utdata gör att du kan generera talade ljudsvar till uppmaningar och använda ljudindata för att fråga modellen.
Modeller som stöds
gpt-4o-audio-preview Endast för närvarande och gpt-4o-mini-audio-preview version: 2024-12-17 stöder ljudgenerering.
Mer information om regiontillgänglighet finns i dokumentationen för modeller och versioner.
För närvarande stöds följande röster för ljud ut: Alloy, Echo och Shimmer.
Den maximala ljudfilstorleken är 20 MB.
Kommentar
Realtids-API:et använder samma underliggande GPT-4o-ljudmodell som API:et för slutföranden, men är optimerat för ljudinteraktioner med låg latens i realtid.
API-stöd
Stöd för ljudavslut lades först till i API-version 2025-01-01-preview.
Förutsättningar
- En Azure-prenumeration – Skapa en kostnadsfritt
- Node.js LTS- eller ESM-stöd.
- En Azure OpenAI-resurs som skapats i en av de regioner som stöds. Mer information om regiontillgänglighet finns i dokumentationen för modeller och versioner.
- Sedan måste du distribuera en
gpt-4o-mini-audio-previewmodell med din Azure OpenAI-resurs. Mer information finns i Skapa en resurs och distribuera en modell med Azure OpenAI.
Krav för Microsoft Entra-ID
För den rekommenderade nyckellösa autentiseringen med Microsoft Entra-ID måste du:
- Installera Azure CLI som används för nyckellös autentisering med Microsoft Entra-ID.
-
Cognitive Services UserTilldela rollen till ditt användarkonto. Du kan tilldela roller i Azure Portal under Åtkomstkontroll (IAM)>Lägg till rolltilldelning.
Konfigurera
Skapa en ny mapp
audio-completions-quickstartsom ska innehålla programmet och öppna Visual Studio Code i mappen med följande kommando:mkdir audio-completions-quickstart && code audio-completions-quickstartpackage.jsonSkapa med följande kommando:npm init -ypackage.jsonUppdatera till ECMAScript med följande kommando:npm pkg set type=moduleInstallera OpenAI-klientbiblioteket för JavaScript med:
npm install openaiFör den rekommenderade nyckellösa autentiseringen med Microsoft Entra-ID installerar du
@azure/identitypaketet med:npm install @azure/identity
Hämta resursinformation
Du måste hämta följande information för att autentisera ditt program med din Azure OpenAI-resurs:
| Variabelnamn | Värde |
|---|---|
AZURE_OPENAI_ENDPOINT |
Det här värdet finns i avsnittet Nycklar och slutpunkter när du undersöker din resurs från Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Det här värdet motsvarar det anpassade namn som du valde för distributionen när du distribuerade en modell. Det här värdet finns under Resurshanteringsmodelldistributioner> i Azure Portal. |
OPENAI_API_VERSION |
Läs mer om API-versioner. |
Läs mer om nyckellös autentisering och inställning av miljövariabler.
Varning
Om du vill använda den rekommenderade nyckellösa autentiseringen med SDK:t kontrollerar du att AZURE_OPENAI_API_KEY miljövariabeln inte har angetts.
Generera ljud från textinmatning
to-audio.jsSkapa filen med följande kod:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Logga in på Azure med följande kommando:
az loginKör JavaScript-filen.
node to-audio.js
Vänta en stund för att få svaret.
Utdata för ljudgenerering från textinmatning
Skriptet genererar en ljudfil med namnet dog.wav i samma katalog som skriptet. Ljudfilen innehåller det talade svaret på uppmaningen: "Är en golden retriever en bra familjehund?"
Generera ljud och text från ljudinmatning
from-audio.jsSkapa filen med följande kod:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Logga in på Azure med följande kommando:
az loginKör JavaScript-filen.
node from-audio.js
Vänta en stund för att få svaret.
Utdata för ljud- och textgenerering från ljudinmatning
Skriptet genererar en avskrift av sammanfattningen av talade ljudindata. Den genererar också en ljudfil med namnet analysis.wav i samma katalog som skriptet. Ljudfilen innehåller det talade svaret på uppmaningen.
Generera ljud och använda chattar med flera svängar
multi-turn.jsSkapa filen med följande kod:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: { id: response.choices[0].message.audio.id } }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Logga in på Azure med följande kommando:
az loginKör JavaScript-filen.
node multi-turn.js
Vänta en stund för att få svaret.
Utdata för chattar med flera svängar
Skriptet genererar en avskrift av sammanfattningen av talade ljudindata. Sedan gör det en chatt i flera svängar för att kort sammanfatta de talade ljudindata.
Paketexempel för bibliotekskällkod | |
Modellerna gpt-4o-audio-preview och gpt-4o-mini-audio-preview introducerar ljudmodaliteten i det befintliga /chat/completions API:et. Ljudmodellen utökar potentialen för AI-program i text- och röstbaserade interaktioner och ljudanalys. Metoder som stöds i gpt-4o-audio-preview och gpt-4o-mini-audio-preview modeller är: text, ljud och text + ljud.
Här är en tabell över de metoder som stöds med exempel på användningsfall:
| Modalitetsindata | Modalitetsutdata | Exempel på användningsfall |
|---|---|---|
| Text | Text + ljud | Text till tal, ljudboksgenerering |
| Ljud | Text + ljud | Ljudranskription, ljudboksgenerering |
| Ljud | Text | Ljudavskrift |
| Text + ljud | Text + ljud | Ljudboksgenerering |
| Text + ljud | Text | Ljudavskrift |
Genom att använda funktioner för ljudgenerering kan du uppnå mer dynamiska och interaktiva AI-program. Modeller som stöder ljudindata och utdata gör att du kan generera talade ljudsvar till uppmaningar och använda ljudindata för att fråga modellen.
Modeller som stöds
gpt-4o-audio-preview Endast för närvarande och gpt-4o-mini-audio-preview version: 2024-12-17 stöder ljudgenerering.
Mer information om regiontillgänglighet finns i dokumentationen för modeller och versioner.
För närvarande stöds följande röster för ljud ut: Alloy, Echo och Shimmer.
Den maximala ljudfilstorleken är 20 MB.
Kommentar
Realtids-API:et använder samma underliggande GPT-4o-ljudmodell som API:et för slutföranden, men är optimerat för ljudinteraktioner med låg latens i realtid.
API-stöd
Stöd för ljudavslut lades först till i API-version 2025-01-01-preview.
Använd den här guiden för att komma igång med att generera ljud med Azure OpenAI SDK för Python.
Förutsättningar
- En Azure-prenumeration. Skapa en kostnadsfritt.
- Python 3.8 eller senare version. Vi rekommenderar att du använder Python 3.10 eller senare, men minst Python 3.8 krävs. Om du inte har en lämplig version av Python installerad kan du följa anvisningarna i VS Code Python-självstudien för det enklaste sättet att installera Python på operativsystemet.
- En Azure OpenAI-resurs som skapats i en av de regioner som stöds. Mer information om regiontillgänglighet finns i dokumentationen för modeller och versioner.
- Sedan måste du distribuera en
gpt-4o-mini-audio-previewmodell med din Azure OpenAI-resurs. Mer information finns i Skapa en resurs och distribuera en modell med Azure OpenAI.
Krav för Microsoft Entra-ID
För den rekommenderade nyckellösa autentiseringen med Microsoft Entra-ID måste du:
- Installera Azure CLI som används för nyckellös autentisering med Microsoft Entra-ID.
-
Cognitive Services UserTilldela rollen till ditt användarkonto. Du kan tilldela roller i Azure Portal under Åtkomstkontroll (IAM)>Lägg till rolltilldelning.
Konfigurera
Skapa en ny mapp
audio-completions-quickstartsom ska innehålla programmet och öppna Visual Studio Code i mappen med följande kommando:mkdir audio-completions-quickstart && code audio-completions-quickstartSkapa en virtuell miljö. Om du redan har Python 3.10 eller senare installerat kan du skapa en virtuell miljö med hjälp av följande kommandon:
När du aktiverar Python-miljön innebär det att när du kör
pythonellerpipfrån kommandoraden använder du sedan Python-tolken.venvsom finns i mappen för ditt program. Du kan användadeactivatekommandot för att avsluta den virtuella python-miljön och senare återaktivera den när det behövs.Dricks
Vi rekommenderar att du skapar och aktiverar en ny Python-miljö som ska användas för att installera de paket som du behöver för den här självstudien. Installera inte paket i din globala Python-installation. Du bör alltid använda en virtuell miljö eller conda-miljö när du installerar Python-paket, annars kan du avbryta den globala installationen av Python.
Installera OpenAI-klientbiblioteket för Python med:
pip install openaiFör den rekommenderade nyckellösa autentiseringen med Microsoft Entra-ID installerar du
azure-identitypaketet med:pip install azure-identity
Hämta resursinformation
Du måste hämta följande information för att autentisera ditt program med din Azure OpenAI-resurs:
| Variabelnamn | Värde |
|---|---|
AZURE_OPENAI_ENDPOINT |
Det här värdet finns i avsnittet Nycklar och slutpunkter när du undersöker din resurs från Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Det här värdet motsvarar det anpassade namn som du valde för distributionen när du distribuerade en modell. Det här värdet finns under Resurshanteringsmodelldistributioner> i Azure Portal. |
OPENAI_API_VERSION |
Läs mer om API-versioner. |
Läs mer om nyckellös autentisering och inställning av miljövariabler.
Generera ljud från textinmatning
to-audio.pySkapa filen med följande kod:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Make the audio chat completions request completion=client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": "Is a golden retriever a good family dog?" } ] ) print(completion.choices[0]) # Write the output audio data to a file wav_bytes=base64.b64decode(completion.choices[0].message.audio.data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Kör Python-filen.
python to-audio.py
Vänta en stund för att få svaret.
Utdata för ljudgenerering från textinmatning
Skriptet genererar en ljudfil med namnet dog.wav i samma katalog som skriptet. Ljudfilen innehåller det talade svaret på uppmaningen: "Är en golden retriever en bra familjehund?"
Generera ljud och text från ljudinmatning
from-audio.pySkapa filen med följande kod:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Make the audio chat completions request completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] ) print(completion.choices[0].message.audio.transcript) # Write the output audio data to a file wav_bytes = base64.b64decode(completion.choices[0].message.audio.data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Kör Python-filen.
python from-audio.py
Vänta en stund för att få svaret.
Utdata för ljud- och textgenerering från ljudinmatning
Skriptet genererar en avskrift av sammanfattningen av talade ljudindata. Den genererar också en ljudfil med namnet analysis.wav i samma katalog som skriptet. Ljudfilen innehåller det talade svaret på uppmaningen.
Generera ljud och använda chattar med flera svängar
multi-turn.pySkapa filen med följande kod:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] # Get the first turn's response completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=messages ) print("Get the first turn's response:") print(completion.choices[0].message.audio.transcript) print("Add a history message referencing the first turn's audio by ID:") print(completion.choices[0].message.audio.id) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.choices[0].message.audio.id } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) # Send the follow-up request with the accumulated messages completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", messages=messages ) print("Very briefly, summarize the favorability.") print(completion.choices[0].message.content)Kör Python-filen.
python multi-turn.py
Vänta en stund för att få svaret.
Utdata för chattar med flera svängar
Skriptet genererar en avskrift av sammanfattningen av talade ljudindata. Sedan gör det en chatt i flera svängar för att kort sammanfatta de talade ljudindata.
Modellerna gpt-4o-audio-preview och gpt-4o-mini-audio-preview introducerar ljudmodaliteten i det befintliga /chat/completions API:et. Ljudmodellen utökar potentialen för AI-program i text- och röstbaserade interaktioner och ljudanalys. Metoder som stöds i gpt-4o-audio-preview och gpt-4o-mini-audio-preview modeller är: text, ljud och text + ljud.
Här är en tabell över de metoder som stöds med exempel på användningsfall:
| Modalitetsindata | Modalitetsutdata | Exempel på användningsfall |
|---|---|---|
| Text | Text + ljud | Text till tal, ljudboksgenerering |
| Ljud | Text + ljud | Ljudranskription, ljudboksgenerering |
| Ljud | Text | Ljudavskrift |
| Text + ljud | Text + ljud | Ljudboksgenerering |
| Text + ljud | Text | Ljudavskrift |
Genom att använda funktioner för ljudgenerering kan du uppnå mer dynamiska och interaktiva AI-program. Modeller som stöder ljudindata och utdata gör att du kan generera talade ljudsvar till uppmaningar och använda ljudindata för att fråga modellen.
Modeller som stöds
gpt-4o-audio-preview Endast för närvarande och gpt-4o-mini-audio-preview version: 2024-12-17 stöder ljudgenerering.
Mer information om regiontillgänglighet finns i dokumentationen för modeller och versioner.
För närvarande stöds följande röster för ljud ut: Alloy, Echo och Shimmer.
Den maximala ljudfilstorleken är 20 MB.
Kommentar
Realtids-API:et använder samma underliggande GPT-4o-ljudmodell som API:et för slutföranden, men är optimerat för ljudinteraktioner med låg latens i realtid.
API-stöd
Stöd för ljudavslut lades först till i API-version 2025-01-01-preview.
Förutsättningar
- En Azure-prenumeration. Skapa en kostnadsfritt.
- Python 3.8 eller senare version. Vi rekommenderar att du använder Python 3.10 eller senare, men minst Python 3.8 krävs. Om du inte har en lämplig version av Python installerad kan du följa anvisningarna i VS Code Python-självstudien för det enklaste sättet att installera Python på operativsystemet.
- En Azure OpenAI-resurs som skapats i en av de regioner som stöds. Mer information om regiontillgänglighet finns i dokumentationen för modeller och versioner.
- Sedan måste du distribuera en
gpt-4o-mini-audio-previewmodell med din Azure OpenAI-resurs. Mer information finns i Skapa en resurs och distribuera en modell med Azure OpenAI.
Krav för Microsoft Entra-ID
För den rekommenderade nyckellösa autentiseringen med Microsoft Entra-ID måste du:
- Installera Azure CLI som används för nyckellös autentisering med Microsoft Entra-ID.
-
Cognitive Services UserTilldela rollen till ditt användarkonto. Du kan tilldela roller i Azure Portal under Åtkomstkontroll (IAM)>Lägg till rolltilldelning.
Konfigurera
Skapa en ny mapp
audio-completions-quickstartsom ska innehålla programmet och öppna Visual Studio Code i mappen med följande kommando:mkdir audio-completions-quickstart && code audio-completions-quickstartSkapa en virtuell miljö. Om du redan har Python 3.10 eller senare installerat kan du skapa en virtuell miljö med hjälp av följande kommandon:
När du aktiverar Python-miljön innebär det att när du kör
pythonellerpipfrån kommandoraden använder du sedan Python-tolken.venvsom finns i mappen för ditt program. Du kan användadeactivatekommandot för att avsluta den virtuella python-miljön och senare återaktivera den när det behövs.Dricks
Vi rekommenderar att du skapar och aktiverar en ny Python-miljö som ska användas för att installera de paket som du behöver för den här självstudien. Installera inte paket i din globala Python-installation. Du bör alltid använda en virtuell miljö eller conda-miljö när du installerar Python-paket, annars kan du avbryta den globala installationen av Python.
Installera OpenAI-klientbiblioteket för Python med:
pip install openaiFör den rekommenderade nyckellösa autentiseringen med Microsoft Entra-ID installerar du
azure-identitypaketet med:pip install azure-identity
Hämta resursinformation
Du måste hämta följande information för att autentisera ditt program med din Azure OpenAI-resurs:
| Variabelnamn | Värde |
|---|---|
AZURE_OPENAI_ENDPOINT |
Det här värdet finns i avsnittet Nycklar och slutpunkter när du undersöker din resurs från Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Det här värdet motsvarar det anpassade namn som du valde för distributionen när du distribuerade en modell. Det här värdet finns under Resurshanteringsmodelldistributioner> i Azure Portal. |
OPENAI_API_VERSION |
Läs mer om API-versioner. |
Läs mer om nyckellös autentisering och inställning av miljövariabler.
Generera ljud från textinmatning
to-audio.pySkapa filen med följande kod:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Is a golden retriever a good family dog?" } ] } ] } # Make the audio chat completions request completion = requests.post(url, headers=headers, json=body) audio_data = completion.json()['choices'][0]['message']['audio']['data'] # Write the output audio data to a file wav_bytes = base64.b64decode(audio_data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Kör Python-filen.
python to-audio.py
Vänta en stund för att få svaret.
Utdata för ljudgenerering från textinmatning
Skriptet genererar en ljudfil med namnet dog.wav i samma katalog som skriptet. Ljudfilen innehåller det talade svaret på uppmaningen: "Är en golden retriever en bra familjehund?"
Generera ljud och text från ljudinmatning
from-audio.pySkapa filen med följande kod:import requests import base64 import os from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] } completion = requests.post(url, headers=headers, json=body) print(completion.json()['choices'][0]['message']['audio']['transcript']) # Write the output audio data to a file audio_data = completion.json()['choices'][0]['message']['audio']['data'] wav_bytes = base64.b64decode(audio_data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Kör Python-filen.
python from-audio.py
Vänta en stund för att få svaret.
Utdata för ljud- och textgenerering från ljudinmatning
Skriptet genererar en avskrift av sammanfattningen av talade ljudindata. Den genererar också en ljudfil med namnet analysis.wav i samma katalog som skriptet. Ljudfilen innehåller det talade svaret på uppmaningen.
Generera ljud och använda chattar med flera svängar
multi-turn.pySkapa filen med följande kod:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": messages } # Get the first turn's response, including generated audio completion = requests.post(url, headers=headers, json=body) print("Get the first turn's response:") print(completion.json()['choices'][0]['message']['audio']['transcript']) print("Add a history message referencing the first turn's audio by ID:") print(completion.json()['choices'][0]['message']['audio']['id']) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.json()['choices'][0]['message']['audio']['id'] } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) body = { "model": "gpt-4o-mini-audio-preview", "messages": messages } # Send the follow-up request with the accumulated messages completion = requests.post(url, headers=headers, json=body) print("Very briefly, summarize the favorability.") print(completion.json()['choices'][0]['message']['content'])Kör Python-filen.
python multi-turn.py
Vänta en stund för att få svaret.
Utdata för chattar med flera svängar
Skriptet genererar en avskrift av sammanfattningen av talade ljudindata. Sedan gör det en chatt i flera svängar för att kort sammanfatta de talade ljudindata.
Referensdokumentation Bibliotek källkodspaket | (npm)Exempel | |
Modellerna gpt-4o-audio-preview och gpt-4o-mini-audio-preview introducerar ljudmodaliteten i det befintliga /chat/completions API:et. Ljudmodellen utökar potentialen för AI-program i text- och röstbaserade interaktioner och ljudanalys. Metoder som stöds i gpt-4o-audio-preview och gpt-4o-mini-audio-preview modeller är: text, ljud och text + ljud.
Här är en tabell över de metoder som stöds med exempel på användningsfall:
| Modalitetsindata | Modalitetsutdata | Exempel på användningsfall |
|---|---|---|
| Text | Text + ljud | Text till tal, ljudboksgenerering |
| Ljud | Text + ljud | Ljudranskription, ljudboksgenerering |
| Ljud | Text | Ljudavskrift |
| Text + ljud | Text + ljud | Ljudboksgenerering |
| Text + ljud | Text | Ljudavskrift |
Genom att använda funktioner för ljudgenerering kan du uppnå mer dynamiska och interaktiva AI-program. Modeller som stöder ljudindata och utdata gör att du kan generera talade ljudsvar till uppmaningar och använda ljudindata för att fråga modellen.
Modeller som stöds
gpt-4o-audio-preview Endast för närvarande och gpt-4o-mini-audio-preview version: 2024-12-17 stöder ljudgenerering.
Mer information om regiontillgänglighet finns i dokumentationen för modeller och versioner.
För närvarande stöds följande röster för ljud ut: Alloy, Echo och Shimmer.
Den maximala ljudfilstorleken är 20 MB.
Kommentar
Realtids-API:et använder samma underliggande GPT-4o-ljudmodell som API:et för slutföranden, men är optimerat för ljudinteraktioner med låg latens i realtid.
API-stöd
Stöd för ljudavslut lades först till i API-version 2025-01-01-preview.
Förutsättningar
- En Azure-prenumeration – Skapa en kostnadsfritt
- Node.js LTS- eller ESM-stöd.
- TypeScript installerat globalt.
- En Azure OpenAI-resurs som skapats i en av de regioner som stöds. Mer information om regiontillgänglighet finns i dokumentationen för modeller och versioner.
- Sedan måste du distribuera en
gpt-4o-mini-audio-previewmodell med din Azure OpenAI-resurs. Mer information finns i Skapa en resurs och distribuera en modell med Azure OpenAI.
Krav för Microsoft Entra-ID
För den rekommenderade nyckellösa autentiseringen med Microsoft Entra-ID måste du:
- Installera Azure CLI som används för nyckellös autentisering med Microsoft Entra-ID.
-
Cognitive Services UserTilldela rollen till ditt användarkonto. Du kan tilldela roller i Azure Portal under Åtkomstkontroll (IAM)>Lägg till rolltilldelning.
Konfigurera
Skapa en ny mapp
audio-completions-quickstartsom ska innehålla programmet och öppna Visual Studio Code i mappen med följande kommando:mkdir audio-completions-quickstart && code audio-completions-quickstartpackage.jsonSkapa med följande kommando:npm init -ypackage.jsonUppdatera till ECMAScript med följande kommando:npm pkg set type=moduleInstallera OpenAI-klientbiblioteket för JavaScript med:
npm install openaiFör den rekommenderade nyckellösa autentiseringen med Microsoft Entra-ID installerar du
@azure/identitypaketet med:npm install @azure/identity
Hämta resursinformation
Du måste hämta följande information för att autentisera ditt program med din Azure OpenAI-resurs:
| Variabelnamn | Värde |
|---|---|
AZURE_OPENAI_ENDPOINT |
Det här värdet finns i avsnittet Nycklar och slutpunkter när du undersöker din resurs från Azure Portal. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Det här värdet motsvarar det anpassade namn som du valde för distributionen när du distribuerade en modell. Det här värdet finns under Resurshanteringsmodelldistributioner> i Azure Portal. |
OPENAI_API_VERSION |
Läs mer om API-versioner. |
Läs mer om nyckellös autentisering och inställning av miljövariabler.
Varning
Om du vill använda den rekommenderade nyckellösa autentiseringen med SDK:t kontrollerar du att AZURE_OPENAI_API_KEY miljövariabeln inte har angetts.
Generera ljud från textinmatning
to-audio.tsSkapa filen med följande kod:import { writeFileSync } from "node:fs"; import { AzureOpenAI } from "openai/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };tsconfig.jsonSkapa filen för att transpilera TypeScript-koden och kopiera följande kod för ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpilera från TypeScript till JavaScript.
tscLogga in på Azure med följande kommando:
az loginKör koden med följande kommando:
node to-audio.js
Vänta en stund för att få svaret.
Utdata för ljudgenerering från textinmatning
Skriptet genererar en ljudfil med namnet dog.wav i samma katalog som skriptet. Ljudfilen innehåller det talade svaret på uppmaningen: "Är en golden retriever en bra familjehund?"
Generera ljud och text från ljudinmatning
from-audio.tsSkapa filen med följande kod:import { AzureOpenAI } from "openai"; import { writeFileSync } from "node:fs"; import { promises as fs } from 'fs'; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync("analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" }); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };tsconfig.jsonSkapa filen för att transpilera TypeScript-koden och kopiera följande kod för ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpilera från TypeScript till JavaScript.
tscLogga in på Azure med följande kommando:
az loginKör koden med följande kommando:
node from-audio.js
Vänta en stund för att få svaret.
Utdata för ljud- och textgenerering från ljudinmatning
Skriptet genererar en avskrift av sammanfattningen av talade ljudindata. Den genererar också en ljudfil med namnet analysis.wav i samma katalog som skriptet. Ljudfilen innehåller det talade svaret på uppmaningen.
Generera ljud och använda chattar med flera svängar
multi-turn.tsSkapa filen med följande kod:import { AzureOpenAI } from "openai/index.mjs"; import { promises as fs } from 'fs'; import { ChatCompletionMessageParam } from "openai/resources/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages: ChatCompletionMessageParam[] = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: response.choices[0].message.audio ? { id: response.choices[0].message.audio.id } : undefined }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };tsconfig.jsonSkapa filen för att transpilera TypeScript-koden och kopiera följande kod för ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpilera från TypeScript till JavaScript.
tscLogga in på Azure med följande kommando:
az loginKör koden med följande kommando:
node multi-turn.js
Vänta en stund för att få svaret.
Utdata för chattar med flera svängar
Skriptet genererar en avskrift av sammanfattningen av talade ljudindata. Sedan gör det en chatt i flera svängar för att kort sammanfatta de talade ljudindata.
Rensa resurser
Om du vill rensa och ta bort en Azure OpenAI-resurs kan du ta bort resursen. Innan du tar bort resursen måste du först ta bort alla distribuerade modeller.
Relaterat innehåll
- Läs mer om distributionstyper för Azure OpenAI.
- Läs mer om Azure OpenAI-kvoter och -gränser.