Märka dina yttranden i Language Studio
När du har skapat ett schema för projektet bör du lägga till träningsyttranden i projektet. Yttrandena bör likna vad användarna kommer att använda när de interagerar med projektet. När du lägger till ett yttrande måste du tilldela vilken avsikt det tillhör. När yttrandet har lagts till etiketterar du orden i ditt yttrande som du vill extrahera som entiteter.
Dataetiketter är ett viktigt steg i utvecklingslivscykeln. Dessa data används i nästa steg när du tränar din modell så att din modell kan lära sig av etiketterade data. Om du redan har etiketterade yttranden kan du importera dem direkt till projektet, men du måste se till att dina data följer det godkända dataformatet. Mer information om hur du importerar etiketterade data till projektet finns i Skapa projekt . Märkta data informerar modellen om hur text tolkas och används för träning och utvärdering.
Förutsättningar
Innan du kan märka dina data behöver du:
- Ett projekt har skapats.
Mer information finns i livscykeln för projektutveckling.
Riktlinjer för dataetiketter
När du har skapat schemat och skapat projektet måste du märka dina data. Det är viktigt att märka dina data så att din modell vet vilka ord och meningar som ska associeras med avsikterna och entiteterna i projektet. Du vill lägga tid på att märka dina yttranden – introducera och förfina de data som ska användas för att träna dina modeller.
När du lägger till yttranden och etiketterar dem bör du tänka på följande:
Maskininlärningsmodellerna generaliseras baserat på de märkta exempel som du anger. Ju fler exempel du anger, desto fler datapunkter måste modellen göra bättre generaliseringar.
Precisionen, konsekvensen och fullständigheten i dina märkta data är viktiga faktorer för att fastställa modellprestanda.
- Etikett exakt: Etikettera varje avsikt och entitet till rätt typ alltid. Inkludera bara det du vill ska klassificeras och extraheras, undvik onödiga data i etiketterna.
- Etikett konsekvent: Samma entitet bör ha samma etikett i alla yttranden.
- Etikett helt: Ange olika yttranden för varje avsikt. Märk alla instanser av entiteten i alla dina yttranden.
Tydligt etikettyttranden
Se till att de begrepp som dina entiteter refererar till är väldefinierade och separerbara. Kontrollera om du enkelt kan fastställa skillnaderna på ett tillförlitligt sätt. Om du inte kan det kan den här bristen på skillnad tyda på att den inlärda komponenten också kommer att ha problem.
Om det finns en likhet mellan entiteter kontrollerar du att det finns någon aspekt av dina data som ger en signal om skillnaden mellan dem.
Om du till exempel har skapat en modell för att boka flyg kan en användare använda ett yttrande som "Jag vill ha ett flyg från Boston till Seattle". Ursprungsstaden och målstaden för sådana yttranden förväntas vara liknande. En signal för att särskilja ursprungsstaden kan vara att ordet från ofta föregår det.
Se till att du märker alla instanser av varje entitet i både tränings- och testdata. En metod är att använda sökfunktionen för att hitta alla instanser av ett ord eller en fras i dina data för att kontrollera om de är korrekt märkta.
Märka testdata för entiteter som inte har någon inlärd komponent och även för de entiteter som gör det. Den här metoden hjälper till att säkerställa att dina utvärderingsmått är korrekta.
För flerspråkiga projekt ökar tillägget av yttranden på andra språk modellens prestanda på dessa språk, men undvik att duplicera data över alla språk som du vill stödja. För att till exempel förbättra en kalenderrobots prestanda med användare kan en utvecklare lägga till exempel främst på engelska, och några på spanska eller franska också. De kan lägga till yttranden som:
- "Ställ in ett möte med Matt och Kevini morgon kl . 12.00." (Engelska)
- "Svara som preliminärt till veckouppdateringsmötet." (Engelska)
- "Cancelar mi próxima reunión." (Spanska)
Så här etiketterar du dina yttranden
Använd följande steg för att märka dina yttranden:
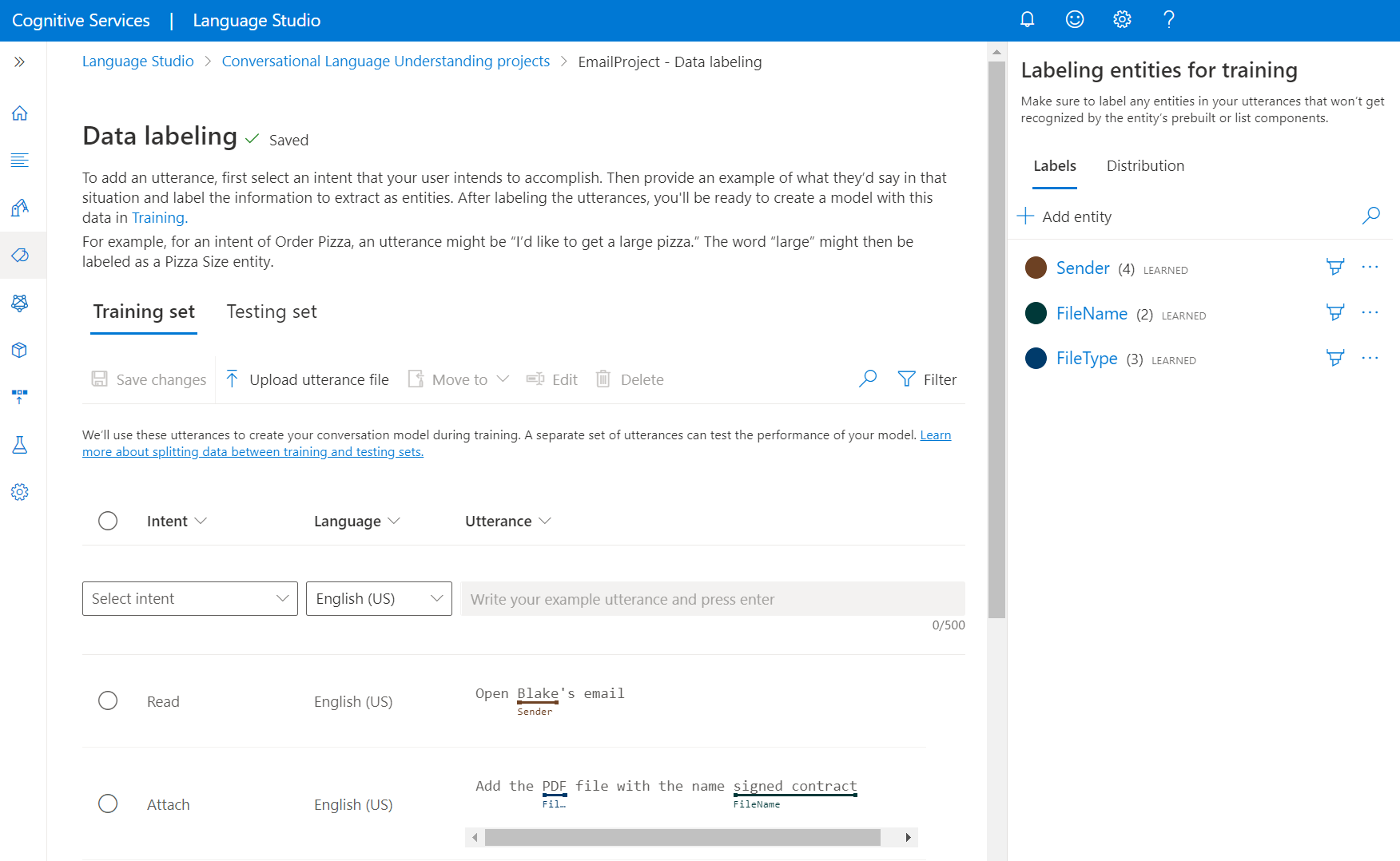
Gå till projektsidan i Language Studio.
På menyn till vänster väljer du Dataetiketter. På den här sidan kan du börja lägga till ditt yttrande och märka dem. Du kan också ladda upp ditt yttrande direkt genom att klicka på Ladda upp yttrandefil från den översta menyn och se till att det följer det godkända formatet.
Från de översta pivoterna kan du ändra vyn till träningsuppsättning eller testuppsättning. Läs mer om tränings- och testuppsättningar och hur de används för modellträning och utvärdering.
Dricks
Om du planerar att använda Dela upp testuppsättningen automatiskt från delning av träningsdata lägger du till alla dina yttranden i träningsuppsättningen.
I listrutan Välj avsikt väljer du en av avsikterna, språket för yttrandet (för flerspråkiga projekt) och själva yttrandet. Tryck på returknappen i textrutan för yttrandet för att lägga till yttrandet.
Du har två alternativ för att märka entiteter i ett yttrande:
Alternativ Description Etikett med hjälp av en pensel Välj penselikonen bredvid en entitet i den högra rutan och markera sedan texten i det yttrande som du vill märka. Etikett med infogad meny Markera ordet som du vill märka som en entitet så visas en meny. Välj den entitet som du vill märka dessa ord med. I den högra rutan under pivoten Etiketter hittar du alla entitetstyper i projektet och antalet märkta instanser per var och en.
Under pivoten Distribution kan du visa fördelningen mellan tränings- och testuppsättningar. Du har två alternativ för att visa:
- Totalt antal instanser per märkt entitet där du kan visa antalet alla märkta instanser av en viss entitet.
- Unika yttranden per märkt entitet där varje yttrande räknas om det innehåller minst en märkt instans av den här entiteten.
- Yttranden per avsikt där du kan visa antal yttranden per avsikt.


Kommentar
List- och fördefinierade komponenter visas inte på dataetikettsidan, och alla etiketter här gäller endast för den inlärda komponenten.
Så här tar du bort en etikett:
- Från ditt yttrande väljer du den entitet som du vill ta bort en etikett från.
- Bläddra igenom menyn som visas och välj Ta bort etikett.
Så här tar du bort en entitet:
- Välj den entitet som du vill redigera i fönstret till höger.
- Välj de tre punkterna bredvid entiteten och välj det alternativ som du vill använda i den nedrullningsbara menyn.
Föreslå yttranden med Azure OpenAI
I CLU använder du Azure OpenAI för att föreslå yttranden för att lägga till i projektet med GPT-modeller. Du måste först få åtkomst och skapa en resurs i Azure OpenAI. Sedan måste du skapa en distribution för GPT-modellerna. Följ de nödvändiga stegen här.
Innan du kommer igång är funktionen föreslå yttranden endast tillgänglig om språkresursen finns i följande regioner:
- USA, östra
- USA, södra centrala
- Västeuropa
På sidan Dataetiketter:
- Välj knappen Föreslå yttranden. Ett fönster öppnas till höger där du uppmanas att välja din Azure OpenAI-resurs och distribution.
- När du väljer en Azure OpenAI-resurs väljer du Anslut, vilket gör att språkresursen kan ha direkt åtkomst till din Azure OpenAI-resurs. Den tilldelar din Språkresurs rollen
Cognitive Services Userför din Azure OpenAI-resurs, vilket gör att din aktuella Språkresurs kan ha åtkomst till Azure OpenAI:s tjänst. Om anslutningen misslyckas följer du de här stegen nedan för att lägga till rätt roll i Azure OpenAI-resursen manuellt. - När resursen är ansluten väljer du distributionen. Den rekommenderade modellen för Azure OpenAI-distributionen är
text-davinci-002. - Välj den avsikt som du vill få förslag på. Kontrollera att avsikten du har valt har minst 5 sparade yttranden som ska aktiveras för yttrandeförslag. Förslagen från Azure OpenAI baseras på de senaste yttrandena som du har lagt till för den avsikten.
- Välj Generera yttranden. När det är klart visas de föreslagna yttrandena med en prickad linje runt den, med anteckningen Genererad av AI. Dessa förslag måste godkännas eller avvisas. Om du godkänner ett förslag läggs det bara till i projektet, som om du hade lagt till det själv. Om du avvisar det tas förslaget bort helt. Endast accepterade yttranden kommer att ingå i projektet och användas för träning eller testning. Du kan acceptera eller avvisa genom att klicka på den gröna kontrollen eller de röda avbrutna knapparna bredvid varje yttrande. Du kan också använda knapparna
Accept allochReject alli verktygsfältet.

Om du använder den här funktionen debiteras din Azure OpenAI-resurs för ett liknande antal token som de föreslagna yttranden som genereras. Information om prissättningen för Azure OpenAI finns här.
Lägga till nödvändiga konfigurationer i Azure OpenAI-resursen
Om det inte går att ansluta språkresursen till en Azure OpenAI-resurs följer du dessa steg:
Aktivera identitetshantering för språkresursen med hjälp av följande alternativ:
Språkresursen måste ha identitetshantering för att aktivera den med hjälp av Azure Portal:
- Gå till språkresursen
- I den vänstra menyn går du till avsnittet Resurshantering och väljer Identitet
- Från fliken Systemtilldelat ser du till att ange Status till På
När du har aktiverat hanterad identitet tilldelar du rollen Cognitive Services User till din Azure OpenAI-resurs med hjälp av den hanterade identiteten för språkresursen.
- Logga in på Azure Portal och gå till din Azure OpenAI-resurs.
- Välj fliken Åtkomstkontroll (IAM) till vänster.
- Välj Lägg till lägg till > rolltilldelning.
- Välj "Jobbfunktionsroller" och klicka på Nästa.
- Välj
Cognitive Services Useri listan över roller och klicka på Nästa. - Välj Tilldela åtkomst till "Hanterad identitet" och välj "Välj medlemmar".
- Under "Hanterad identitet" väljer du "Språk".
- Sök efter din resurs och välj den. Välj sedan knappen Välj nedan och slutför sedan processen.
- Granska informationen och välj Granska + Tilldela.

Efter några minuter uppdaterar du Language Studio så att du kan ansluta till Azure OpenAI.
Nästa steg
- Train Model (Träningsmodell)