Snabbstart: Skapa en objektdetektor med Custom Vision-webbplatsen
Den här snabbstarten förklarar hur du använder Custom Vision-webbplatsen för att skapa en objektidentifieringsmodell. När du har skapat en modell kan du testa den med nya avbildningar och integrera den i din egen app för bildigenkänning.
Förutsättningar
- En Azure-prenumeration. Du kan skapa ett kostnadsfritt konto.
- En uppsättning bilder som du kan träna din detektormodell med. Du kan använda uppsättningen med exempelbilder på GitHub. Eller så kan du välja dina egna bilder med hjälp av följande tips.
- En webbläsare som stöds.
Skapa Custom Vision-resurser
Om du vill använda Custom Vision-tjänsten måste du skapa tränings- och förutsägelseresurser för Custom Vision i Azure. I Azure Portal använder du sidan Skapa Custom Vision för att skapa både en träningsresurs och en förutsägelseresurs.
Skapa ett nytt projekt
Gå till Custom Vision-webbplatsen i webbläsaren. Logga in med samma konto som du använde för att logga in på Azure Portal.
Om du vill skapa ditt första projekt väljer du Nytt projekt. Dialogrutan Skapa nytt projekt visas.
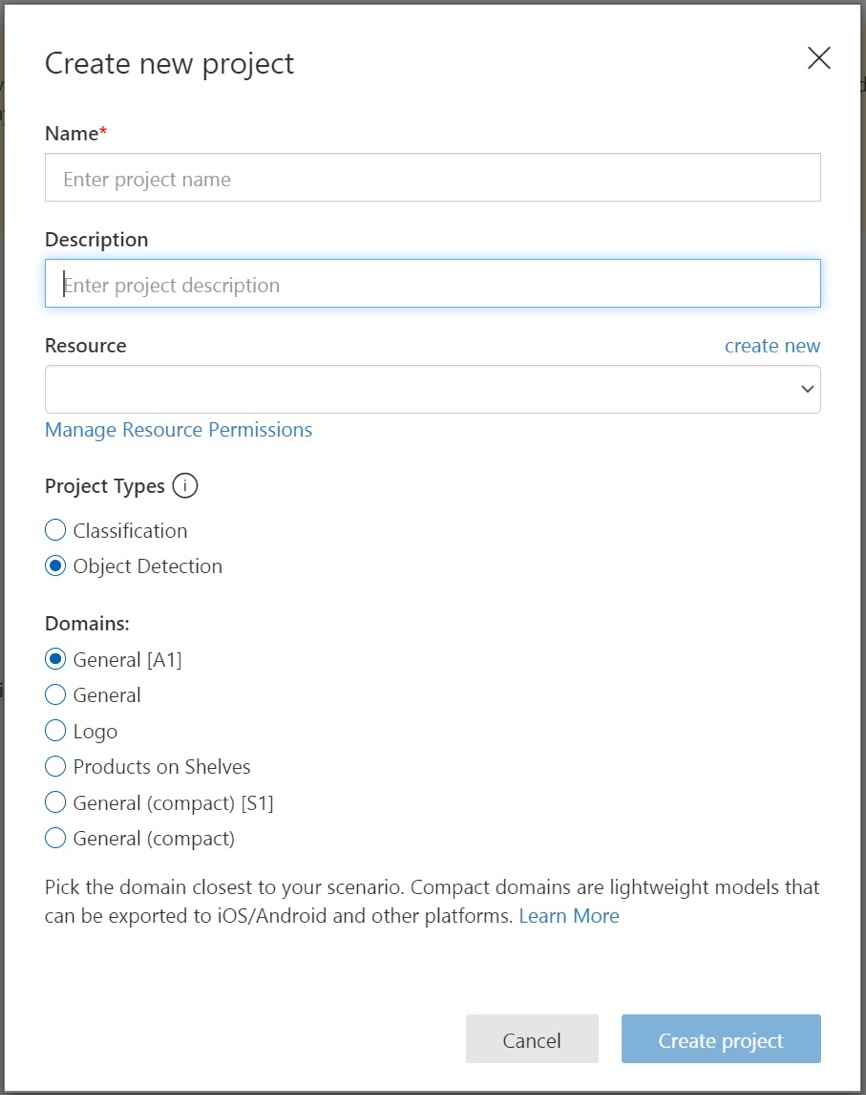
Ange ett namn och en beskrivning för projektet. Välj sedan din Custom Vision-träningsresurs. Om ditt inloggade konto är associerat med ett Azure-konto visar listrutan Resurs alla dina kompatibla Azure-resurser.
Kommentar
Om det inte finns någon tillgänglig resurs kontrollerar du att du har loggat in på customvision.ai med samma konto som du använde för att logga in på Azure Portal. Bekräfta också att du har valt samma katalog på Custom Vision-webbplatsen som katalogen i Azure Portal där dina Custom Vision-resurser finns. På båda webbplatserna kan du välja din katalog i listrutans kontomeny i det övre högra hörnet på skärmen.
Under Projekttyper väljer du Objektidentifiering.
Välj en av de tillgängliga domänerna. Varje domän optimerar detektorn för specifika typer av bilder, enligt beskrivningen i följande tabell. Du kan ändra domänen senare, om du vill.
Domän Syfte Allmänt Optimerad för ett brett spektrum av objektidentifieringsuppgifter. Om ingen av de andra domänerna är lämpliga eller om du är osäker på vilken domän du ska välja väljer du domänen Allmänt . Logotyp Optimerad för att hitta varumärkeslogotyper i bilder. Produkter på hyllor Optimerad för att identifiera och klassificera produkter på hyllor. Kompakta domäner Optimerad för begränsningarna för identifiering av objekt i realtid på mobila enheter. Modeller som genereras av kompakta domäner kan exporteras för att köras lokalt. Välj slutligen Skapa projekt.
Välj träningsbilder
Som minst bör du använda minst 30 bilder per tagg i den första träningsuppsättningen. Du bör också samla in några extra bilder för att testa din modell när den har tränats.
För att träna din modell effektivt använder du bilder med visuell variation. Välj bilder som varierar beroende på:
- kameravinkel
- belysning
- bakgrund
- visuellt format
- enskilda/grupperade ämnen
- storlek
- type
Se dessutom till att alla träningsbilder uppfyller följande kriterier:
- måste vara .jpg, .png, .bmp eller .gif format
- inte större än 6 MB i storlek (4 MB för förutsägelsebilder)
- inte mindre än 256 bildpunkter på den kortaste kanten. alla bilder som är kortare än 256 bildpunkter skalas automatiskt upp av Custom Vision-tjänsten
Ladda upp och tagga bilder
I det här avsnittet laddar du upp och taggar bilder manuellt för att träna detektorn.
Om du vill lägga till bilder väljer du Lägg till bilder och sedan Bläddra bland lokala filer. Välj Öppna för att ladda upp bilderna.
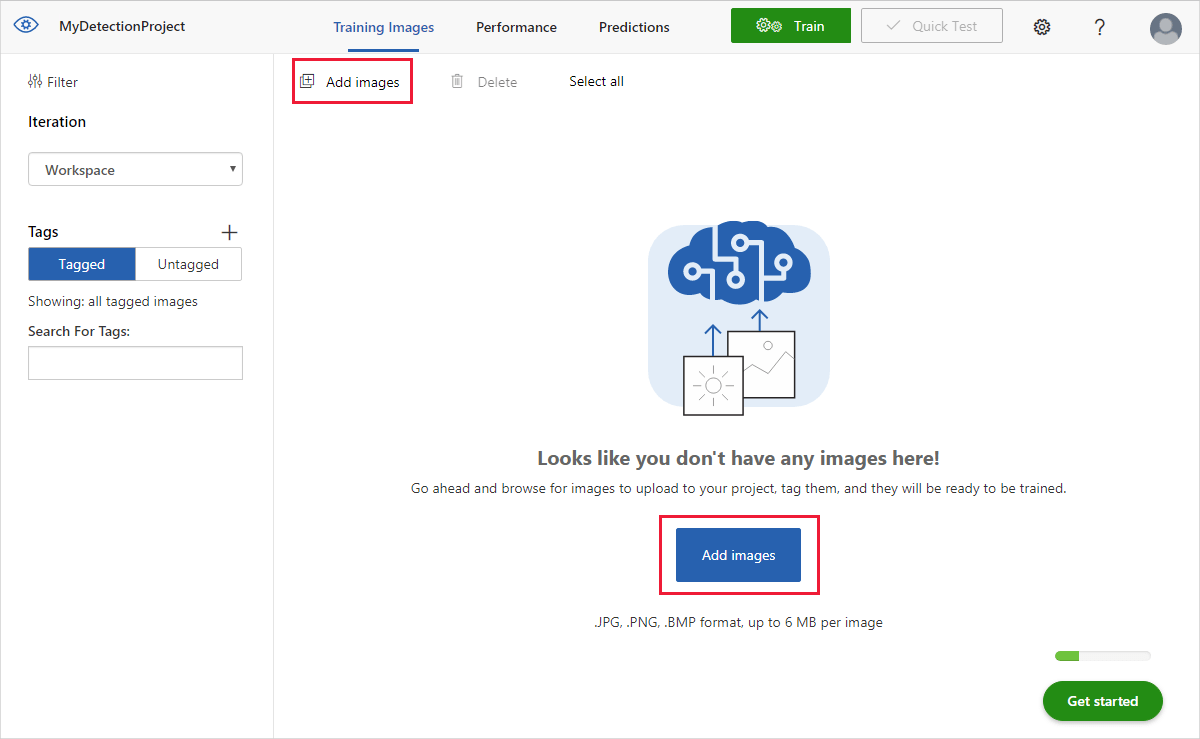
Du ser dina uppladdade bilder i avsnittet Untagged i användargränssnittet. Nästa steg är att tagga de objekt som du vill att detektorn ska lära sig känna igen manuellt. Välj den första bilden för att öppna dialogrutan taggning.
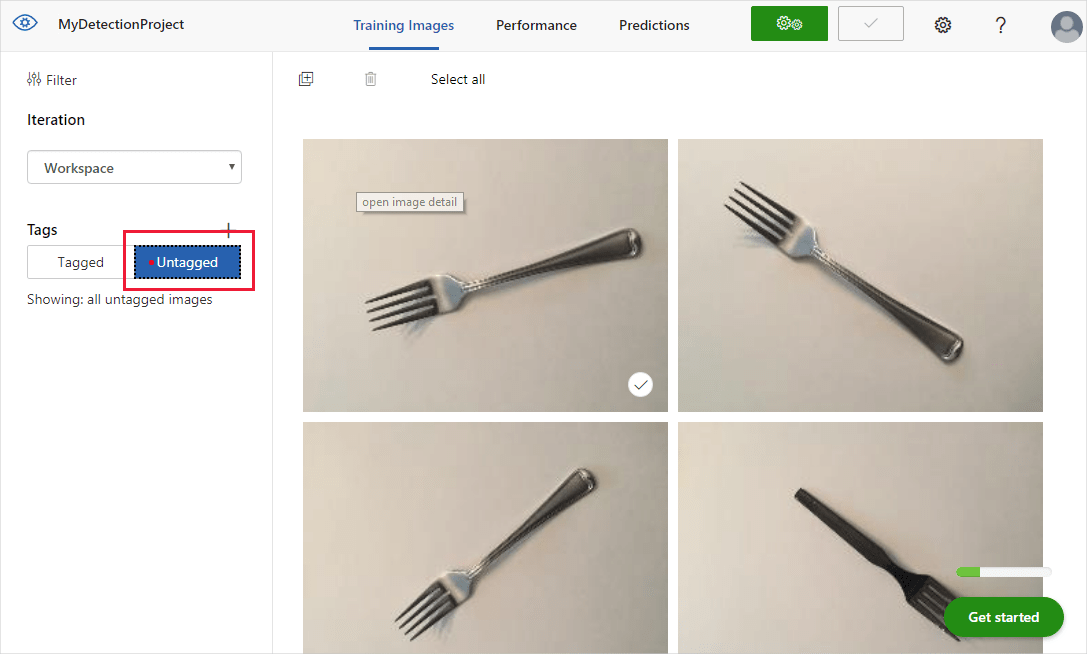
Markera och dra en rektangel runt objektet i bilden. Ange sedan ett nytt taggnamn med + knappen eller välj en befintlig tagg i listrutan. Det är viktigt att tagga varje instans av de objekt som du vill identifiera, eftersom detektorn använder det otaggade bakgrundsområdet som ett negativt exempel i träningen. När du är klar med taggningen väljer du pilen till höger för att spara taggarna och gå vidare till nästa bild.
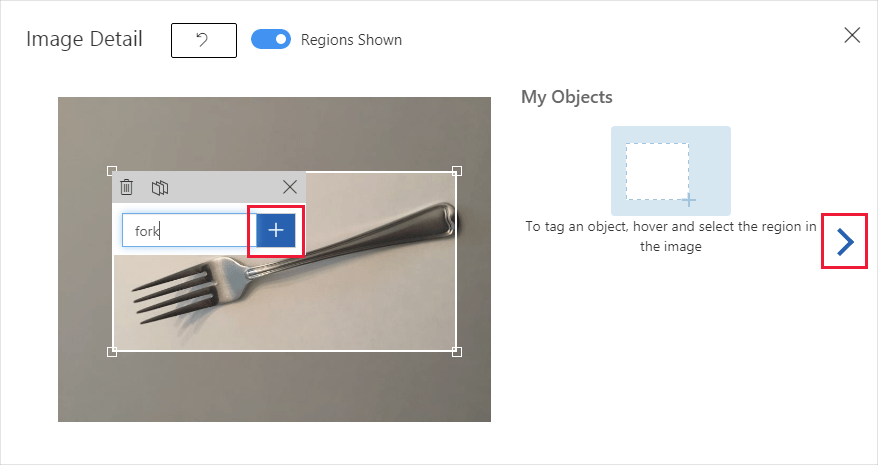
Om du vill ladda upp en annan uppsättning bilder går du tillbaka till toppen av det här avsnittet och upprepar stegen.
Träna detektorn
Om du vill träna detektormodellen väljer du knappen Träna . Detektorn använder alla aktuella bilder och deras taggar för att skapa en modell som identifierar varje taggat objekt. Den här processen kan ta flera minuter.

Träningsprocessen bör bara ta några minuter. Under den här tiden visas information om träningsprocessen på fliken Prestanda .
Utvärdera detektorn
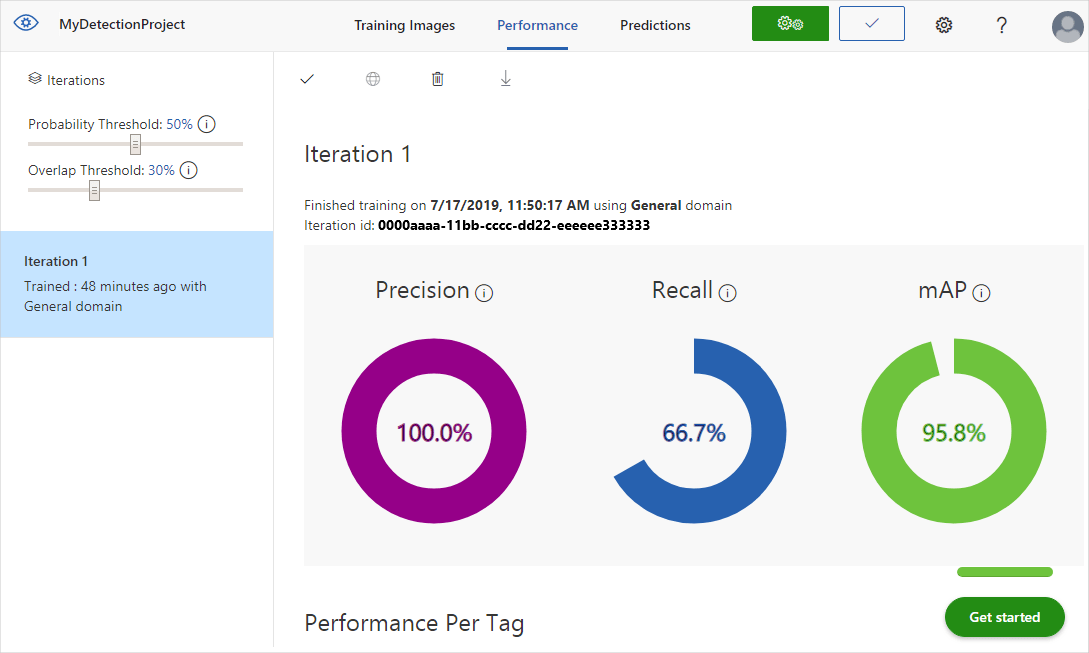
När träningen är klar beräknas och visas modellens prestanda. Custom Vision-tjänsten använder de bilder som du skickade för träning för att beräkna precision, träffsäkerhet och genomsnittlig genomsnittlig precision. Precision och träffsäkerhet är två olika mätningar av effektiviteten hos en detektor:
- Precision anger fraktionen av identifierade klassificeringar som var korrekta. Om modellen till exempel identifierade 100 bilder som hundar och 99 av dem faktiskt var av hundar, skulle precisionen vara 99 %.
- Recall anger den del av faktiska klassificeringar som har identifierats korrekt. Om det till exempel fanns 100 bilder av äpplen och modellen identifierade 80 som äpplen skulle återkallelsen vara 80 %.
- Genomsnittlig genomsnittlig precision är det genomsnittliga värdet för den genomsnittliga precisionen (AP). AP är området under precisions-/återkallningskurvan (precision ritad mot återkallande för varje förutsägelse som görs).
Sannolikhetströskel
Observera skjutreglaget Sannolikhetströskel i den vänstra rutan på fliken Prestanda. Detta är den förtroendenivå som en förutsägelse måste ha för att anses vara korrekt (i syfte att beräkna precision och återkallande).
När du tolkar förutsägelseanrop med ett tröskelvärde med hög sannolikhet tenderar de att returnera resultat med hög precision på bekostnad av återkallelse – de identifierade klassificeringarna är korrekta, men många förblir oupptäckta. Ett tröskelvärde med låg sannolikhet gör motsatsen – de flesta av de faktiska klassificeringarna identifieras, men det finns fler falska positiva identifieringar inom den uppsättningen. Med detta i åtanke bör du ange sannolikhetströskeln enligt projektets specifika behov. När du senare får förutsägelseresultat på klientsidan bör du använda samma tröskelvärde för sannolikhet som du använde här.
Tröskelvärde för överlappning
Skjutreglaget Överlappningströskel handlar om hur korrekt en objektförutsägelse måste anses vara korrekt i träningen. Den anger den minsta tillåtna överlappningen mellan det förutsagda objektets avgränsningsruta och den faktiska användarangivna avgränsningsrutan. Om avgränsningsrutorna inte överlappar i den här utsträckningen anses förutsägelsen inte vara korrekt.
Hantera utbildnings-iterationer
Varje gång du tränar din detektor skapar du en ny iteration med sina egna uppdaterade prestandamått. Du kan visa alla dina iterationer i den vänstra rutan på fliken Prestanda . I den vänstra rutan hittar du även knappen Ta bort , som du kan använda för att ta bort en iteration om den är föråldrad. När du tar bort en iteration tar du bort alla bilder som är unikt associerade med den.
Mer information om hur du kommer åt dina tränade modeller programmatiskt finns i Använda din modell med förutsägelse-API:et.
Gå vidare
I den här snabbstarten har du lärt dig hur du skapar och tränar en objektidentifieringsmodell med hjälp av Custom Vision-webbplatsen. Härnäst får du mer information om den iterativa processen för att förbättra din modell.
En översikt finns i Vad är Custom Vision?