Snabbstart: Använda groundedness-identifiering (förhandsversion)
Den här guiden visar hur du använder API:et för grundidentifiering. Den här funktionen identifierar och korrigerar automatiskt ogrundad text baserat på de angivna källdokumenten, vilket säkerställer att det genererade innehållet överensstämmer med faktiska eller avsedda referenser. Nedan utforskar vi flera vanliga scenarier som hjälper dig att förstå hur och när du ska använda dessa funktioner för att uppnå bästa möjliga resultat.
Förutsättningar
- En Azure-prenumeration – Skapa en kostnadsfritt
- När du har din Azure-prenumeration skapar du en Content Safety-resurs i Azure Portal för att hämta din nyckel och slutpunkt. Ange ett unikt namn för resursen, välj din prenumeration och välj en resursgrupp, region som stöds och prisnivån som stöds. Välj sedan Skapa.
- Det tar några minuter att distribuera resursen. När det är klart går du till den nya resursen. I den vänstra rutan under Resurshantering väljer du API-nycklar och slutpunkter. Kopiera ett av prenumerationsnyckelvärdena och slutpunkten till en tillfällig plats för senare användning.
- (Valfritt) Om du vill använda resonemangsfunktionen skapar du en Azure OpenAI Service-resurs med en GPT-modell distribuerad.
- cURL eller Python installerat.
Kontrollera grunderna utan resonemang
I det enkla fallet utan resonemangsfunktionen klassificerar API:et för grundsidentifiering det inskickade innehållet som true eller false.
Det här avsnittet går igenom en exempelbegäran med cURL. Klistra in kommandot nedan i en textredigerare och gör följande ändringar.
Ersätt
<endpoint>med slutpunkts-URL:en som är associerad med resursen.Ersätt
<your_subscription_key>med en av nycklarna för resursen.Alternativt kan du ersätta fälten
"query"eller"text"i brödtexten med din egen text som du vill analysera.curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \ --header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \ --header 'Content-Type: application/json' \ --data-raw '{ "domain": "Generic", "task": "QnA", "qna": { "query": "How much does she currently get paid per hour at the bank?" }, "text": "12/hour", "groundingSources": [ "I'm 21 years old and I need to make a decision about the next two years of my life. Within a week. I currently work for a bank that requires strict sales goals to meet. IF they aren't met three times (three months) you're canned. They pay me 10/hour and it's not unheard of to get a raise in 6ish months. The issue is, **I'm not a salesperson**. That's not my personality. I'm amazing at customer service, I have the most positive customer service \"reports\" done about me in the short time I've worked here. A coworker asked \"do you ask for people to fill these out? you have a ton\". That being said, I have a job opportunity at Chase Bank as a part time teller. What makes this decision so hard is that at my current job, I get 40 hours and Chase could only offer me 20 hours/week. Drive time to my current job is also 21 miles **one way** while Chase is literally 1.8 miles from my house, allowing me to go home for lunch. I do have an apartment and an awesome roommate that I know wont be late on his portion of rent, so paying bills with 20hours a week isn't the issue. It's the spending money and being broke all the time.\n\nI previously worked at Wal-Mart and took home just about 400 dollars every other week. So I know i can survive on this income. I just don't know whether I should go for Chase as I could definitely see myself having a career there. I'm a math major likely going to become an actuary, so Chase could provide excellent opportunities for me **eventually**." ], "reasoning": false }'
Öppna en kommandotolk och kör kommandot cURL.
Om du vill testa en sammanfattningsaktivitet i stället för en QnA-uppgift (frågesvar) använder du följande JSON-exempeltext:
{
"domain": "Medical",
"task": "Summarization",
"text": "Ms Johnson has been in the hospital after experiencing a stroke.",
"groundingSources": [
"Our patient, Ms. Johnson, presented with persistent fatigue, unexplained weight loss, and frequent night sweats. After a series of tests, she was diagnosed with Hodgkin’s lymphoma, a type of cancer that affects the lymphatic system. The diagnosis was confirmed through a lymph node biopsy revealing the presence of Reed-Sternberg cells, a characteristic of this disease. She was further staged using PET-CT scans. Her treatment plan includes chemotherapy and possibly radiation therapy, depending on her response to treatment. The medical team remains optimistic about her prognosis given the high cure rate of Hodgkin’s lymphoma."
],
"reasoning": false
}
Följande fält måste inkluderas i URL:en:
| Namn | Obligatoriskt | Beskrivning | Typ |
|---|---|---|---|
| API-version | Obligatoriskt | Det här är den API-version som ska användas. Den aktuella versionen är: api-version=2024-09-15-preview. Exempel: <endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview |
String |
Parametrarna i begärandetexten definieras i den här tabellen:
| Name | beskrivning | Typ |
|---|---|---|
| domän | (Valfritt) MEDICAL eller GENERIC. Standardvärde: GENERIC. |
Enum |
| uppgift | (Valfritt) Typ av aktivitet: QnA, Summarization. Standardvärde: Summarization. |
Enum |
| qna | (Valfritt) Innehåller QnA-data när aktivitetstypen är QnA. |
String |
- query |
(Valfritt) Detta representerar frågan i en QnA-uppgift. Teckengräns: 7 500. | String |
| text | (Krävs) DEN LLM-utdatatext som ska kontrolleras. Teckengräns: 7 500. | String |
| groundingSources | (Krävs) Använder en matris med jordningskällor för att verifiera AI-genererad text. Se Indatakrav för begränsningar. | Strängmatris |
| resonemang | (Valfritt) Anger om du vill använda resonemangsfunktionen. Standardvärdet är false. Om truebehöver du ta med din egen Azure OpenAI GPT4o (version 0513, 0806) för att ge en förklaring. Var försiktig: att använda resonemang ökar bearbetningstiden. |
Booleskt |
Tolka API-svaret
När du har skickat din begäran får du ett JSON-svar som återspeglar den groundedness-analys som utförts. Så här ser en typisk utdata ut:
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "12/hour."
}
]
}
JSON-objekten i utdata definieras här:
| Name | beskrivning | Typ |
|---|---|---|
| ungroundedDetected | Anger om texten uppvisar ogrundad text. | Booleskt |
| ungroundedPercentage | Anger andelen av texten som identifieras som ogrundad, uttryckt som ett tal mellan 0 och 1, där 0 anger inget ogrundat innehåll och 1 anger helt ogrundat innehåll. | Flyttal |
| ungroundedDetails | Ger insikter om ogrundat innehåll med specifika exempel och procentandelar. | Matris |
-text |
Den specifika text som är ojordad. | String |
Kontrollera grunderna i resonemanget
API:et för groundedness-identifiering ger möjlighet att inkludera resonemang i API-svaret. När resonemanget är aktiverat innehåller svaret ett "reasoning" fält som beskriver specifika instanser och förklaringar till eventuell upptäckt ogrundadhet.
Ansluta din egen GPT-distribution
Dricks
Vi stöder endast **Azure OpenAI GPT4o(0513, 0806 version) ** resurser och stöder inte andra GPT-typer. Du har flexibiliteten att distribuera dina Azure OpenAI GPT4o-resurser (0513, 0806-version) i valfri region. Men för att minimera potentiella svarstider och undvika geografiska datasekretess och riskproblem rekommenderar vi att du placerar dem i samma region som dina innehållssäkerhetsresurser. Omfattande information om datasekretess finns i riktlinjerna för data, sekretess och säkerhet för Azure OpenAI Service och Data, sekretess och säkerhet för Azure AI Content Safety.
Om du vill använda din Azure OpenAI GPT4o-resurs (0513, 0806-version) för att aktivera resonemangsfunktionen använder du Hanterad identitet för att ge innehållssäkerhetsresursen åtkomst till Azure OpenAI-resursen:
Aktivera hanterad identitet för Azure AI Content Safety.
Gå till din Azure AI Content Safety-instans i Azure Portal. Leta upp avsnittet Identitet under kategorin Inställningar . Aktivera den systemtilldelade hanterade identiteten. Den här åtgärden ger din Azure AI Content Safety-instans en identitet som kan identifieras och användas i Azure för åtkomst till andra resurser.
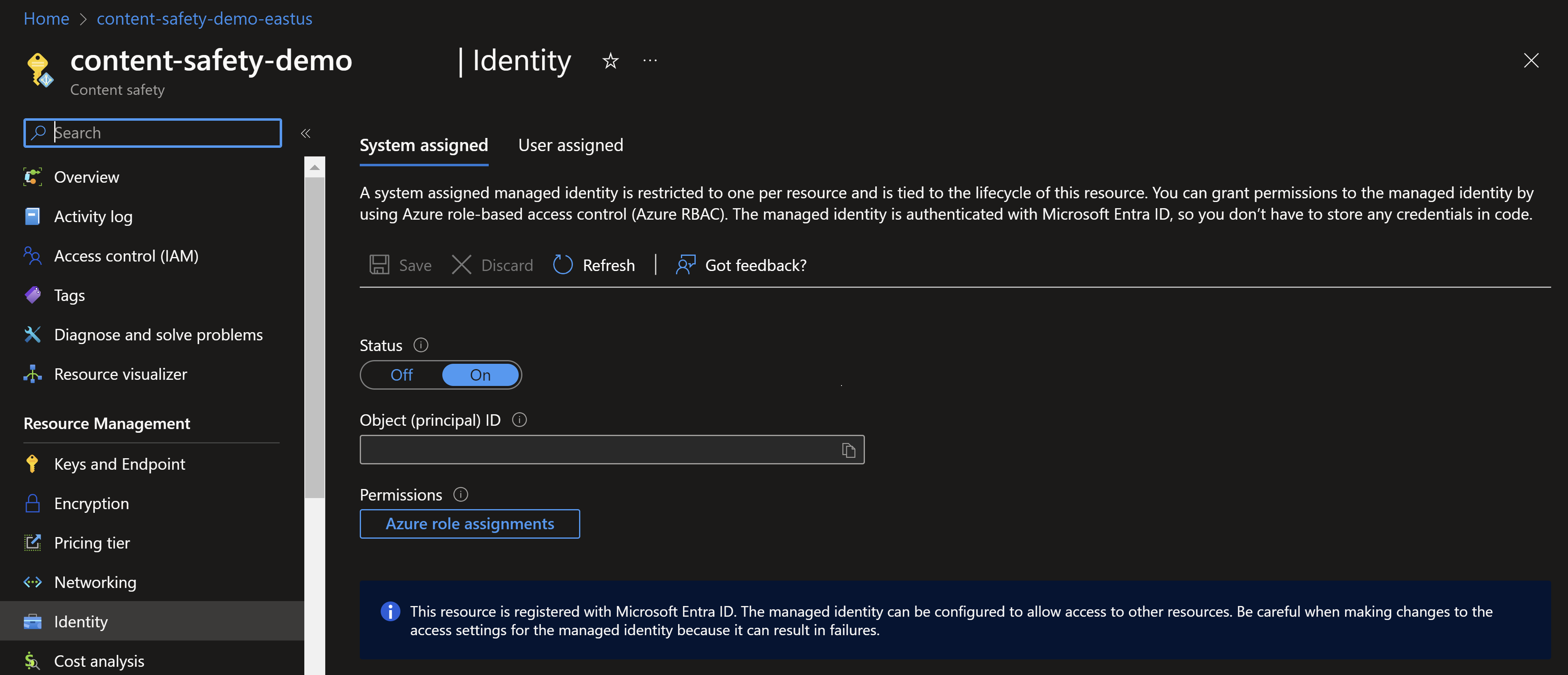
Tilldela rollen till hanterad identitet.
Gå till din Azure OpenAI-instans och välj Lägg till rolltilldelning för att starta processen med att tilldela en Azure OpenAI-roll till Azure AI Content Safety-identiteten.
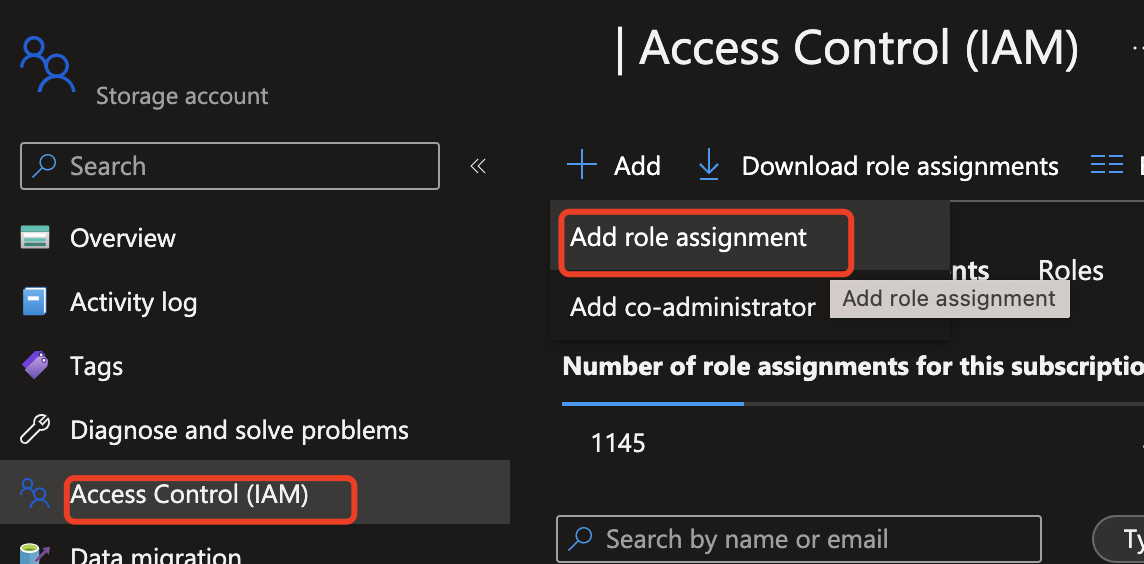
Välj rollen Användare eller Deltagare .
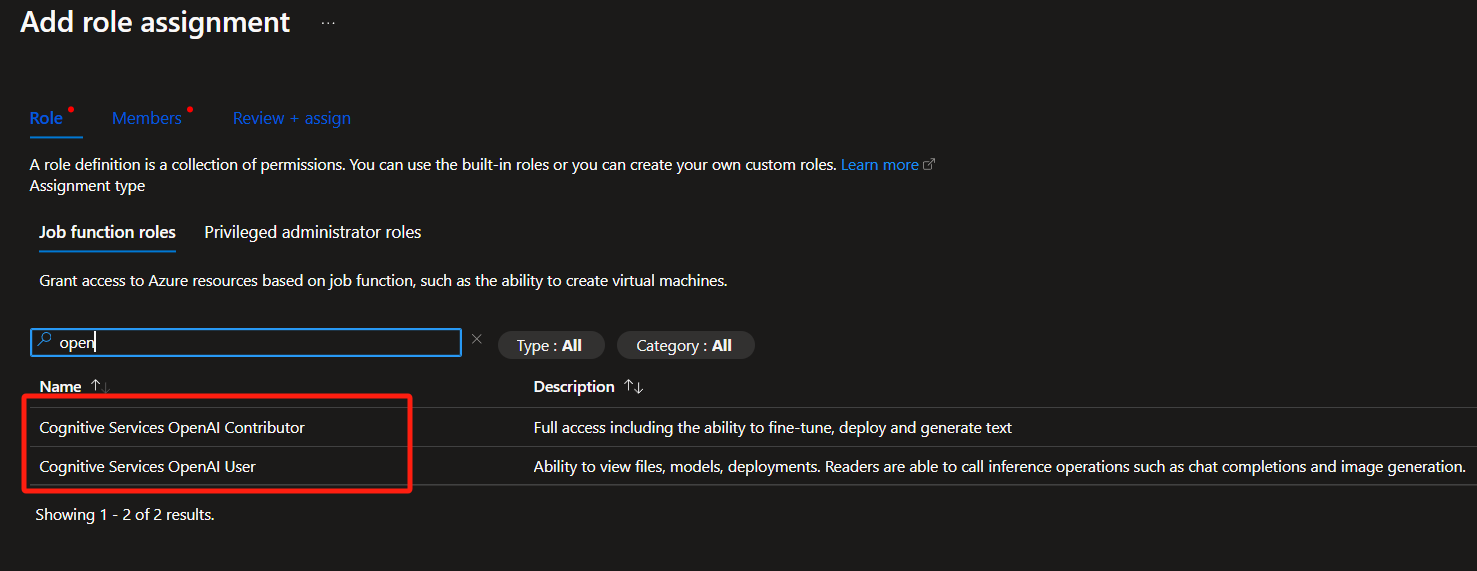


Gör API-begäran
I din begäran till API:et för groundedness-identifiering anger du "reasoning" brödtextparametern till trueoch anger de andra nödvändiga parametrarna:
{
"domain": "Medical",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"reasoning": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}
Det här avsnittet går igenom en exempelbegäran med cURL. Klistra in kommandot nedan i en textredigerare och gör följande ändringar.
Ersätt
<endpoint>med slutpunkts-URL:en som är associerad med din Azure AI Content Safety-resurs.Ersätt
<your_subscription_key>med en av nycklarna för resursen.Ersätt
<your_OpenAI_endpoint>med slutpunkts-URL:en som är associerad med din Azure OpenAI-resurs.Ersätt
<your_deployment_name>med namnet på din Azure OpenAI-distribution.Alternativt kan du ersätta fälten
"query"eller"text"i brödtexten med din egen text som du vill analysera.curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \ --header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \ --header 'Content-Type: application/json' \ --data-raw '{ "domain": "Generic", "task": "QnA", "qna": { "query": "How much does she currently get paid per hour at the bank?" }, "text": "12/hour", "groundingSources": [ "I'm 21 years old and I need to make a decision about the next two years of my life. Within a week. I currently work for a bank that requires strict sales goals to meet. If they aren't met three times (three months) you're canned. They pay me 10/hour and it's not unheard of to get a raise in 6ish months. The issue is, **I'm not a salesperson**. That's not my personality. I'm amazing at customer service, I have the most positive customer service \"reports\" done about me in the short time I've worked here. A coworker asked \"do you ask for people to fill these out? you have a ton\". That being said, I have a job opportunity at Chase Bank as a part time teller. What makes this decision so hard is that at my current job, I get 40 hours and Chase could only offer me 20 hours/week. Drive time to my current job is also 21 miles **one way** while Chase is literally 1.8 miles from my house, allowing me to go home for lunch. I do have an apartment and an awesome roommate that I know wont be late on his portion of rent, so paying bills with 20hours a week isn't the issue. It's the spending money and being broke all the time.\n\nI previously worked at Wal-Mart and took home just about 400 dollars every other week. So I know i can survive on this income. I just don't know whether I should go for Chase as I could definitely see myself having a career there. I'm a math major likely going to become an actuary, so Chase could provide excellent opportunities for me **eventually**." ], "reasoning": true, "llmResource": { "resourceType": "AzureOpenAI", "azureOpenAIEndpoint": "<your_OpenAI_endpoint>", "azureOpenAIDeploymentName": "<your_deployment_name>" }'Öppna en kommandotolk och kör kommandot cURL.
Parametrarna i begärandetexten definieras i den här tabellen:
| Name | beskrivning | Typ |
|---|---|---|
| domän | (Valfritt) MEDICAL eller GENERIC. Standardvärde: GENERIC. |
Enum |
| uppgift | (Valfritt) Typ av aktivitet: QnA, Summarization. Standardvärde: Summarization. |
Enum |
| qna | (Valfritt) Innehåller QnA-data när aktivitetstypen är QnA. |
String |
- query |
(Valfritt) Detta representerar frågan i en QnA-uppgift. Teckengräns: 7 500. | String |
| text | (Krävs) DEN LLM-utdatatext som ska kontrolleras. Teckengräns: 7 500. | String |
| groundingSources | (Krävs) Använder en matris med jordningskällor för att verifiera AI-genererad text. Se Indatakrav för begränsningar, | Strängmatris |
| resonemang | (Valfritt) Ange till trueanvänder tjänsten Azure OpenAI-resurser för att ge en förklaring. Var försiktig: att använda resonemang ökar bearbetningstiden och medför extra avgifter. |
Booleskt |
| llmResource | (Krävs) Om du vill använda din egen Azure OpenAI GPT4o-resurs (0513, 0806-version) för att aktivera resonemang lägger du till det här fältet och inkluderar underfälten för de resurser som används. | String |
- resourceType |
Anger vilken typ av resurs som används. För närvarande tillåter AzureOpenAIden bara . Vi stöder endast Azure OpenAI GPT4o-resurser (0513, 0806-version) och stöder inte andra GPT-typer. |
Enum |
- azureOpenAIEndpoint |
Din slutpunkts-URL för Azure OpenAI-tjänsten. | String |
- azureOpenAIDeploymentName |
Namnet på den specifika GPT-distribution som ska användas. | String |
Tolka API-svaret
När du har skickat din begäran får du ett JSON-svar som återspeglar den groundedness-analys som utförts. Så här ser en typisk utdata ut:
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "12/hour.",
"offset": {
"utf8": 0,
"utf16": 0,
"codePoint": 0
},
"length": {
"utf8": 8,
"utf16": 8,
"codePoint": 8
},
"reason": "None. The premise mentions a pay of \"10/hour\" but does not mention \"12/hour.\" It's neutral. "
}
]
}
JSON-objekten i utdata definieras här:
| Name | beskrivning | Typ |
|---|---|---|
| ungroundedDetected | Anger om texten uppvisar ogrundad text. | Booleskt |
| ungroundedPercentage | Anger andelen av texten som identifieras som ogrundad, uttryckt som ett tal mellan 0 och 1, där 0 anger inget ogrundat innehåll och 1 anger helt ogrundat innehåll. | Flyttal |
| ungroundedDetails | Ger insikter om ogrundat innehåll med specifika exempel och procentandelar. | Matris |
-text |
Den specifika text som är ojordad. | String |
-offset |
Ett objekt som beskriver positionen för den ogrundade texten i olika kodningar. | String |
- offset > utf8 |
Förskjutningspositionen för den ogrundade texten i UTF-8-kodning. | Integer |
- offset > utf16 |
Förskjutningspositionen för den ogrundade texten i UTF-16-kodning. | Integer |
- offset > codePoint |
Förskjutningspositionen för den ogrundade texten när det gäller Unicode-kodpunkter. | Integer |
-length |
Ett objekt som beskriver längden på den ogrundade texten i olika kodningar. (utf8, utf16, codePoint), liknande förskjutningen. | Objekt |
- length > utf8 |
Längden på den ogrundade texten i UTF-8-kodning. | Integer |
- length > utf16 |
Längden på den ogrundade texten i UTF-16-kodning. | Integer |
- length > codePoint |
Längden på den ogrundade texten när det gäller Unicode-kodpunkter. | Integer |
-reason |
Ger förklaringar till upptäckt ogrundadhet. | String |
Kontrollera grunderna med korrigeringsfunktionen
API:et för grundidentifiering innehåller en korrigeringsfunktion som automatiskt korrigerar eventuell upptäckt ogrundad text i texten baserat på de angivna grundkällorna. När korrigeringsfunktionen är aktiverad innehåller svaret ett "correction Text" fält som visar den korrigerade texten i linje med grundkällorna.
Ansluta din egen GPT-distribution
Dricks
För närvarande stöder korrigeringsfunktionen endast **Azure OpenAI GPT4o (0513, 0806 version) ** resurser. För att minimera svarstiden och följa riktlinjerna för datasekretess rekommenderar vi att du distribuerar din Azure OpenAI GPT4o (version 0513, 0806) i samma region som dina innehållssäkerhetsresurser. Mer information om datasekretess finns i riktlinjerna för data, sekretess och säkerhet för Azure OpenAI Service och Data, sekretess och säkerhet för Azure AI Content Safety.
Om du vill använda din Azure OpenAI GPT4o-resurs (0513, 0806-version) för att aktivera korrigeringsfunktionen använder du Hanterad identitet för att ge innehållssäkerhetsresursen åtkomst till Azure OpenAI-resursen. Följ stegen i det tidigare avsnittet för att konfigurera den hanterade identiteten.
Gör API-begäran
I din begäran till API:et för grundidentifiering anger du "correction" brödtextparametern till trueoch anger de andra nödvändiga parametrarna:
{
"domain": "Medical",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"correction": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}
Det här avsnittet visar en exempelbegäran med hjälp av cURL. Ersätt platshållarna efter behov:
- Ersätt
<endpoint>med resursens slutpunkts-URL. - Ersätt
<your_subscription_key>med din prenumerationsnyckel. - Du kan också ersätta fältet "text" med den text som du vill analysera.
curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \
--header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"domain": "Generic",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"correction": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}'
Parametrarna i begärandetexten definieras i den här tabellen:
| Name | beskrivning | Typ |
|---|---|---|
| domän | (Valfritt) MEDICAL eller GENERIC. Standardvärde: GENERIC. |
Enum |
| uppgift | (Valfritt) Typ av aktivitet: QnA, Summarization. Standardvärde: Summarization. |
Enum |
| qna | (Valfritt) Innehåller QnA-data när aktivitetstypen är QnA. |
String |
- query |
(Valfritt) Detta representerar frågan i en QnA-uppgift. Teckengräns: 7 500. | String |
| text | (Krävs) DEN LLM-utdatatext som ska kontrolleras. Teckengräns: 7 500. | String |
| groundingSources | (Krävs) Använder en matris med jordningskällor för att verifiera AI-genererad text. Se Indatakrav för begränsningar. | Strängmatris |
| rättelse | (Valfritt) Ange till trueanvänder tjänsten Azure OpenAI-resurser för att tillhandahålla den korrigerade texten, vilket säkerställer konsekvens med jordningskällorna. Var försiktig: att använda korrigering ökar bearbetningstiden och medför extra avgifter. |
Booleskt |
| llmResource | (Krävs) Om du vill använda din egen Azure OpenAI GPT4o-resurs (0513, 0806-version) för att aktivera resonemang lägger du till det här fältet och inkluderar underfälten för de resurser som används. | String |
- resourceType |
Anger vilken typ av resurs som används. För närvarande tillåter AzureOpenAIden bara . Vi stöder endast Azure OpenAI GPT4o-resurser (0513, 0806-version) och stöder inte andra GPT-typer. |
Enum |
- azureOpenAIEndpoint |
Din slutpunkts-URL för Azure OpenAI-tjänsten. | String |
- azureOpenAIDeploymentName |
Namnet på den specifika GPT-distribution som ska användas. | String |
Tolka API-svaret
Svaret innehåller ett "correction Text" fält som innehåller den korrigerade texten, vilket säkerställer konsekvens med de angivna jordningskällorna.
Korrigeringsfunktionen identifierar som Kevin inte är grundad eftersom den står i konflikt med jordningskällan Jane. API:et returnerar den korrigerade texten: "The patient name is Jane."
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "The patient name is Kevin"
}
],
"correction Text": "The patient name is Jane"
}
JSON-objekten i utdata definieras här:
| Name | beskrivning | Typ |
|---|---|---|
| ungroundedDetected | Anger om ogrundat innehåll har identifierats. | Booleskt |
| ungroundedPercentage | Andelen ogrundat innehåll i texten. | Flyttal |
| ungroundedDetails | Information om ogrundat innehåll, inklusive specifika textsegment. | Matris |
-text |
Den specifika text som är ojordad. | String |
-offset |
Ett objekt som beskriver positionen för den ogrundade texten i olika kodningar. | String |
- offset > utf8 |
Förskjutningspositionen för den ogrundade texten i UTF-8-kodning. | Integer |
- offset > utf16 |
Förskjutningspositionen för den ogrundade texten i UTF-16-kodning. | Integer |
-length |
Ett objekt som beskriver längden på den ogrundade texten i olika kodningar. (utf8, utf16, codePoint), liknande förskjutningen. | Objekt |
- length > utf8 |
Längden på den ogrundade texten i UTF-8-kodning. | Integer |
- length > utf16 |
Längden på den ogrundade texten i UTF-16-kodning. | Integer |
- length > codePoint |
Längden på den ogrundade texten när det gäller Unicode-kodpunkter. | Integer |
-correction Text |
Den korrigerade texten, vilket säkerställer konsekvens med jordningskällorna. | String |
Rensa resurser
Om du vill rensa och ta bort en Azure AI-tjänstprenumeration kan du ta bort resursen eller resursgruppen. Om du tar bort resursgruppen tas även alla andra resurser som är associerade med den bort.
Relaterat innehåll
- Begrepp för grundidentifiering
- Kombinera groundedness-identifiering med andra LLM-säkerhetsfunktioner som Prompt Shields.