Köra frågor mot CSV-filer
I den här artikeln får du lära dig hur du kör frågor mot en enskild CSV-fil med hjälp av en serverlös SQL-pool i Azure Synapse Analytics. CSV-filer kan ha olika format:
- Med och utan rubrikrad
- Komma- och tabbavgränsade värden
- Radslut i Windows- och Unix-format
- Värden som inte citeras och citeras och som inte kommer från tecken
Alla ovanstående variationer kommer att täckas nedan.
Snabbstartsexempel
OPENROWSET med funktionen kan du läsa innehållet i CSV-filen genom att ange URL:en till filen.
Läsa en csv-fil
Det enklaste sättet att se innehållet CSV i filen är att ange fil-URL för att OPENROWSET fungera, ange csv FORMAToch 2.0 PARSER_VERSION. Om filen är offentligt tillgänglig eller om din Microsoft Entra-identitet kan komma åt den här filen bör du kunna se innehållet i filen med hjälp av frågan som den som visas i följande exempel:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
Alternativet firstrow används för att hoppa över den första raden i CSV-filen som representerar huvudet i det här fallet. Kontrollera att du har åtkomst till den här filen. Om filen skyddas med SAS-nyckel eller anpassad identitet behöver du konfigurera autentiseringsuppgifter på servernivå för sql-inloggning.
Viktigt!
Om CSV-filen innehåller UTF-8 tecken kontrollerar du att du använder en UTF-8-databassortering (till exempel Latin1_General_100_CI_AS_SC_UTF8).
Ett matchningsfel mellan textkodning i filen och sortering kan orsaka oväntade konverteringsfel.
Du kan enkelt ändra standardsortering av den aktuella databasen med hjälp av följande T-SQL-instruktion: alter database current collate Latin1_General_100_CI_AI_SC_UTF8
Användning av datakälla
I föregående exempel används en fullständig sökväg till filen. Alternativt kan du skapa en extern datakälla med den plats som pekar på lagringens rotmapp:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
När du har skapat en datakälla kan du använda den datakällan och den relativa sökvägen till filen i OPENROWSET funktionen:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Om en datakälla skyddas med SAS-nyckel eller anpassad identitet kan du konfigurera datakällan med databasomfångsbegränsade autentiseringsuppgifter.
Ange uttryckligen schema
OPENROWSET gör att du uttryckligen kan ange vilka kolumner du vill läsa från filen med hjälp av WITH -satsen:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
Talen efter en datatyp i WITH -satsen representerar kolumnindex i CSV-filen.
Viktigt!
Om CSV-filen innehåller UTF-8-tecken kontrollerar du att du uttryckligen anger utf-8-sortering (till exempel Latin1_General_100_CI_AS_SC_UTF8) för alla kolumner i WITH -satsen eller anger viss UTF-8-sortering på databasnivå.
Matchningsfel mellan textkodning i filen och sortering kan orsaka oväntade konverteringsfel.
Du kan enkelt ändra standardsortering av den aktuella databasen med hjälp av följande T-SQL-instruktion: alter database current collate Latin1_General_100_CI_AI_SC_UTF8 Du kan enkelt ange sortering för kolumntyperna med hjälp av följande definition: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
I följande avsnitt kan du se hur du frågar efter olika typer av CSV-filer.
Förutsättningar
Det första steget är att skapa en databas där tabellerna skapas. Initiera sedan objekten genom att köra installationsskriptet på databasen. Det här installationsskriptet skapar datakällor, databasomfattningsautentiseringsuppgifter och externa filformat som används i dessa exempel.
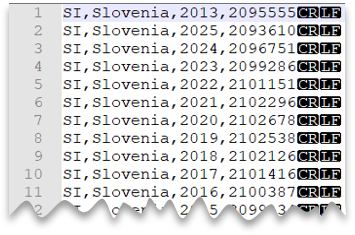
Ny rad i Windows-format
Följande fråga visar hur du läser en CSV-fil utan rubrikrad, med en ny rad i Windows-format och kommaavgränsade kolumner.
Förhandsgranskning av fil:
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
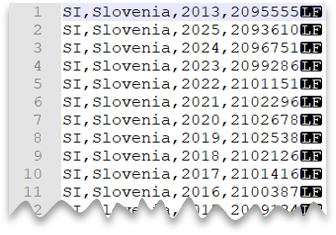
Ny linje i Unix-format
Följande fråga visar hur du läser en fil utan rubrikrad, med en ny rad i Unix-format och kommaavgränsade kolumner. Observera filens olika plats jämfört med de andra exemplen.
Förhandsgranskning av fil:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
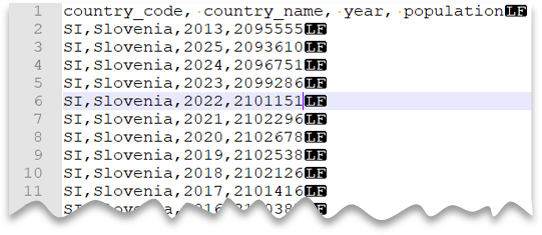
Rubrikraden
Följande fråga visar hur du läser en fil med en rubrikrad, med en ny rad i Unix-format och kommaavgränsade kolumner. Observera filens olika plats jämfört med de andra exemplen.
Förhandsgranskning av fil:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
Alternativet HEADER_ROW = TRUE resulterar i att kolumnnamn läss från rubrikraden i filen. Det är bra i utforskningssyfte när du inte är bekant med filinnehåll. Bästa prestanda finns i Avsnittet Använda lämpliga datatyper i Metodtips. Du kan också läsa mer om OPENROWSET-syntax här.
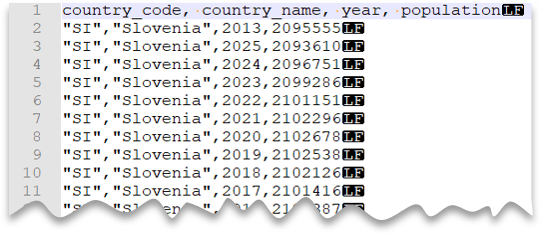
Anpassat citattecken
Följande fråga visar hur du läser en fil med en rubrikrad, med en ny rad i Unix-format, kommaavgränsade kolumner och citerade värden. Observera filens olika plats jämfört med de andra exemplen.
Förhandsgranskning av fil:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Kommentar
Den här frågan returnerar samma resultat om du utelämnade parametern FIELDQUOTE eftersom standardvärdet för FIELDQUOTE är ett dubbelcitat.
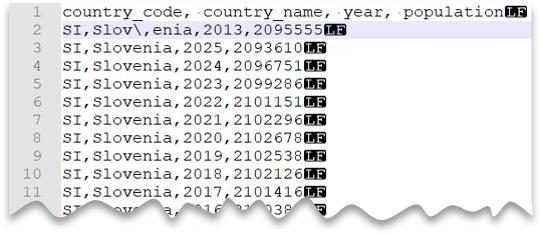
Escape-tecken
Följande fråga visar hur du läser en fil med en rubrikrad, med en ny rad i Unix-format, kommaavgränsade kolumner och ett escape-tecken som används för fältavgränsaren (kommatecken) i värden. Observera filens olika plats jämfört med de andra exemplen.
Förhandsgranskning av fil:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Kommentar
Den här frågan misslyckas om ESCAPECHAR inte anges eftersom kommatecknet i "Slov,enia" skulle behandlas som fältavgränsare i stället för en del av namnet på landet/regionen. "Slov,enia" skulle behandlas som två kolumner. Därför skulle den specifika raden ha en kolumn mer än de andra raderna och en kolumn mer än du definierade i WITH-satsen.
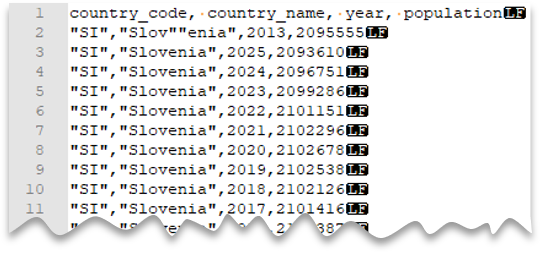
Escape-citattecken
Följande fråga visar hur du läser en fil med en rubrikrad, med en ny rad i Unix-format, kommaavgränsade kolumner och ett undantaget tecken för dubbla citattecken i värden. Observera filens olika plats jämfört med de andra exemplen.
Förhandsgranskning av fil:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Kommentar
Citattecknet måste vara undantaget med ett annat citattecken. Citattecken kan endast visas inom kolumnvärdet om värdet kapslas in med citattecken.
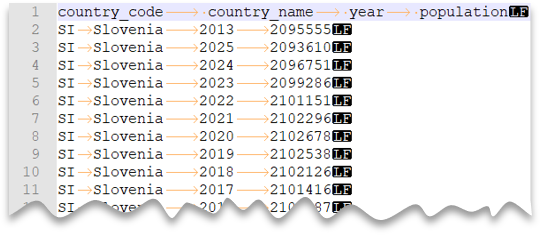
Tabbavgränsade filer
Följande fråga visar hur du läser en fil med en rubrikrad, med en ny rad i Unix-format och flikavgränsade kolumner. Observera filens olika plats jämfört med de andra exemplen.
Förhandsgranskning av fil:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Returnera en delmängd av kolumner
Hittills har du angett CSV-filschemat med hjälp av WITH och listat alla kolumner. Du kan bara ange kolumner som du faktiskt behöver i frågan med hjälp av ett ordningstal för varje kolumn som behövs. Du utelämnar även kolumner utan intresse.
Följande fråga returnerar antalet distinkta namn på land/region i en fil och anger endast de kolumner som behövs:
Kommentar
Ta en titt på WITH-satsen i frågan nedan och observera att det finns "2" (utan citattecken) i slutet av raden där du definierar kolumnen [country_name]. Det innebär att kolumnen [country_name] är den andra kolumnen i filen. Frågan ignorerar alla kolumner i filen förutom den andra.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Köra frågor mot tilläggsfiler
CSV-filerna som används i frågan bör inte ändras när frågan körs. I den långvariga frågan kan SQL-poolen försöka läsa igen, läsa delar av filerna eller till och med läsa filen flera gånger. Ändringar av filinnehållet skulle orsaka felaktiga resultat. Därför misslyckas SQL-poolen med frågan om den identifierar att ändringstiden för en fil ändras under frågekörningen.
I vissa scenarier kanske du vill läsa de filer som ständigt läggs till. Om du vill undvika frågefel på grund av filer som läggs till hela tiden kan du låta OPENROWSET funktionen ignorera potentiellt inkonsekventa läsningar med hjälp av inställningen ROWSET_OPTIONS .
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
Läsalternativet ALLOW_INCONSISTENT_READS inaktiverar tidskontrollen för filändring under frågelivscykeln och läser det som är tillgängligt i filen. I de tilläggsbara filerna uppdateras inte det befintliga innehållet och endast nya rader läggs till. Därför minimeras sannolikheten för felaktiga resultat jämfört med de uppdateringsbara filerna. Det här alternativet kan göra att du kan läsa de filer som ofta läggs till utan att hantera felen. I de flesta scenarier ignorerar SQL-poolen bara några rader som läggs till i filerna under frågekörningen.
Nästa steg
I nästa artiklar visas hur du: